






前言
本来想试一下,用D435i相机实时跑一下稠密建图,但是最终执行时一直出现了一个报错(核心已转储)。
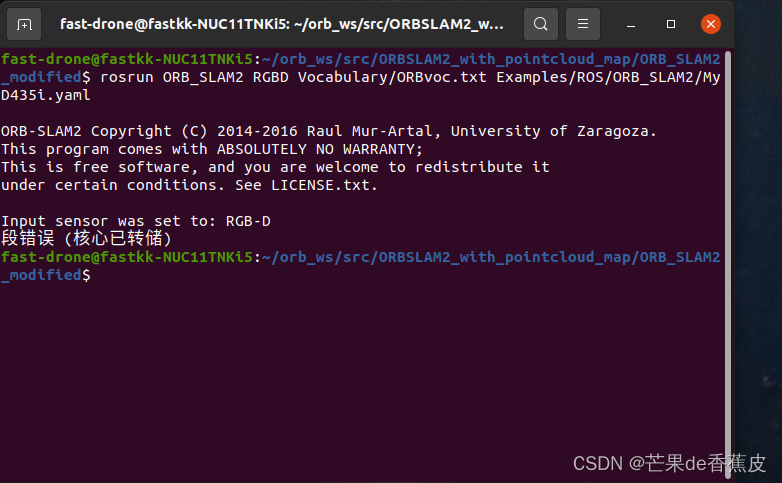
网上也有很多人出现了这种错误,我尝试了各种办法,最后还是没有解决。我的版本是:
Ubuntu20.04 + ROS noetic + PCL1.10 + opencv4.2
我觉得我报错的原因就是版本不匹配,orb-slam2可能是针对open3.4编译的,而我的ROS Noetic用的是opencv4.2,虽然按照网上的,下载了opencv3.4,修改了CMakeLists,成功编译了但还是没什么用,不知道是不是pcl的原因,可能pcl1.7版本更合适一些,反正最后没法解决搁置了。(这里求大佬指教)
于是我选了另外一种方案,用D435i相机先录制得到一个数据集,然后再去稠密建图。
realsense驱动安装
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-key F6E65AC044F831AC80A06380C8B3A55A6F3EFCDE || sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-key F6E65AC044F831AC80A06380C8B3A55A6F3EFCDE
sudo add-apt-repository "deb https://librealsense.intel.com/Debian/apt-repo $(lsb_release -cs) main" -u
sudo apt-get install librealsense2-dkms
sudo apt-get install librealsense2-utils
sudo apt-get install librealsense2-dev
sudo apt-get install librealsense2-dbg测试:
realsense-viewer注意测试时左上角显示的USB必须是3.x,如果是2.x,可能是USB线是2.0的,或者插在了2.0的USB口上(3.0的线和口都是蓝色的)
录制视频:
设置 Depth Stream 以及 Color Stream 的图像分辨率和采集帧率,图像分辨率为640 × 480。
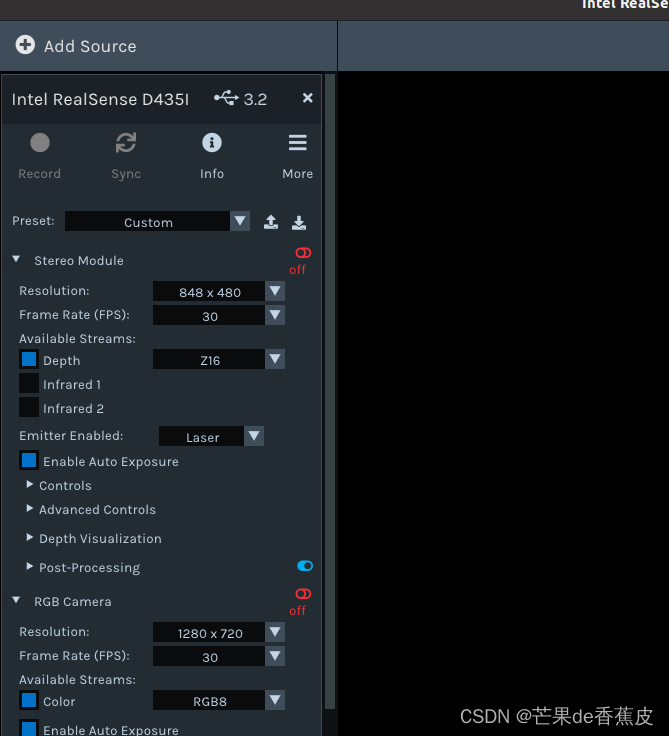
点击左上Record按钮可以录制,再点击stop会停止并保存,首次执行会报错弹出一个窗口,修改一下保存数据集的路径就行。
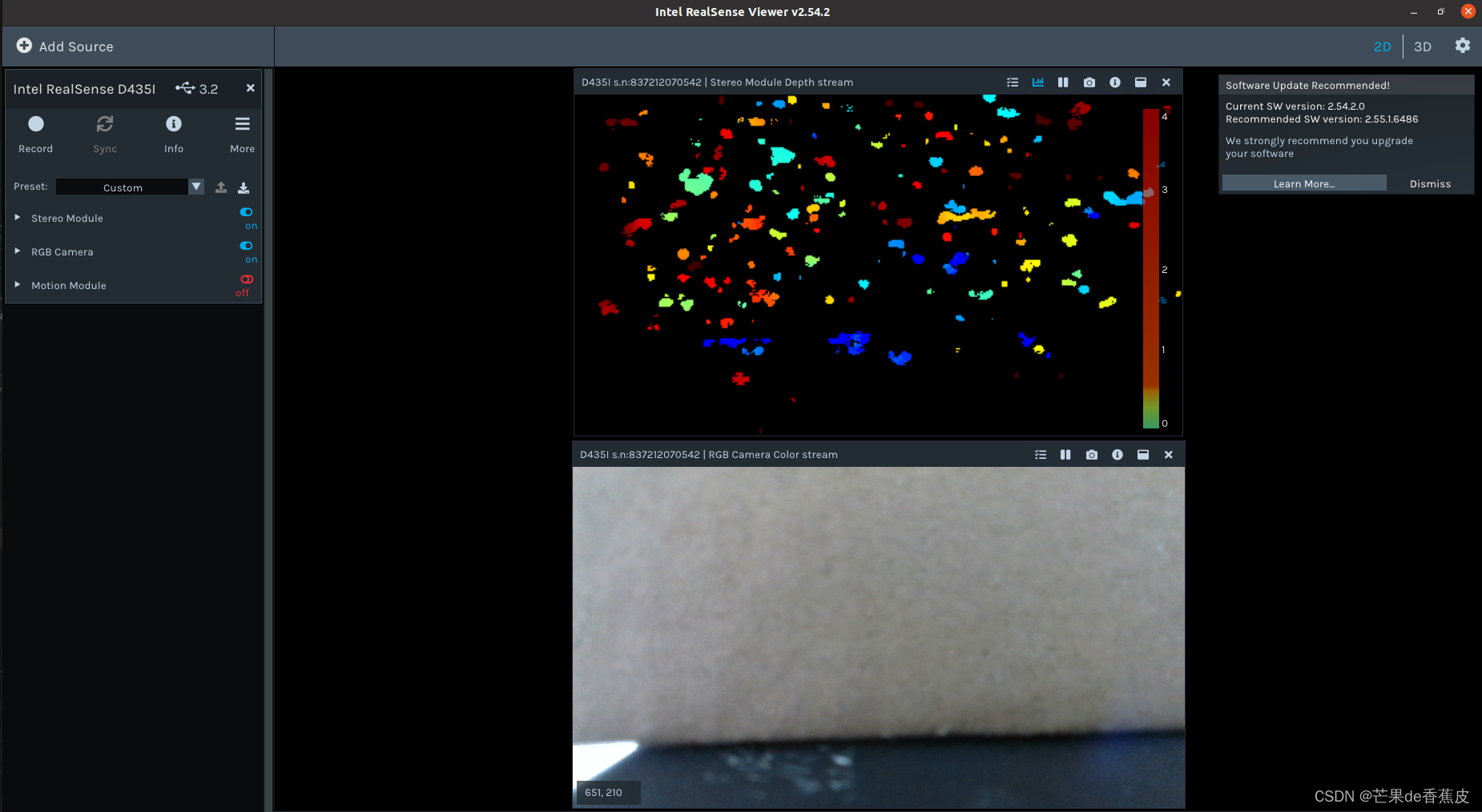
提取图片
得到数据集是一个.bag文件,新建一个文件,将数据集放进去,新建一个room文件和ax.py。
把自己数据集的名字和路径修改一下。
#ax.py
import roslib
import rosbag
import rospy
import cv2
import os
from sensor_msgs.msg import Image
from cv_bridge import CvBridge
from cv_bridge import CvBridgeError
rgb = '/home/fast-drone/movies/room/rgb/' #rgb path
depth = '/home/fast-drone/movies/room/depth/' #depth path
bridge = CvBridge()
file_handle1 = open('/home/fast-drone/movies/room/depth.txt', 'w')
file_handle2 = open('/home/fast-drone/movies/room/rgb.txt', 'w')
#修改数据集和路径和名字
with rosbag.Bag('/home/fast-drone/movies/20240515_095915.bag', 'r') as bag:
for topic,msg,t in bag.read_messages():
if topic == "/device_0/sensor_0/Depth_0/image/data": #depth topic
cv_image = bridge.imgmsg_to_cv2(msg)
timestr = "%.6f" % msg.header.stamp.to_sec() #depth time stamp
image_name = timestr+ ".png"
path = "depth/" + image_name
file_handle1.write(timestr + " " + path + '\n')
cv2.imwrite(depth + image_name, cv_image)
if topic == "/device_0/sensor_1/Color_0/image/data": #rgb topic
cv_image = bridge.imgmsg_to_cv2(msg,"bgr8")
timestr = "%.6f" % msg.header.stamp.to_sec() #rgb time stamp
image_name = timestr+ ".png"
path = "rgb/" + image_name
file_handle2.write(timestr + " " + path + '\n')
cv2.imwrite(rgb + image_name, cv_image)
file_handle1.close()
file_handle2.close()
进入room文件, 新建文件depth , rgb , associate.py , depth.txt , rgb.txt
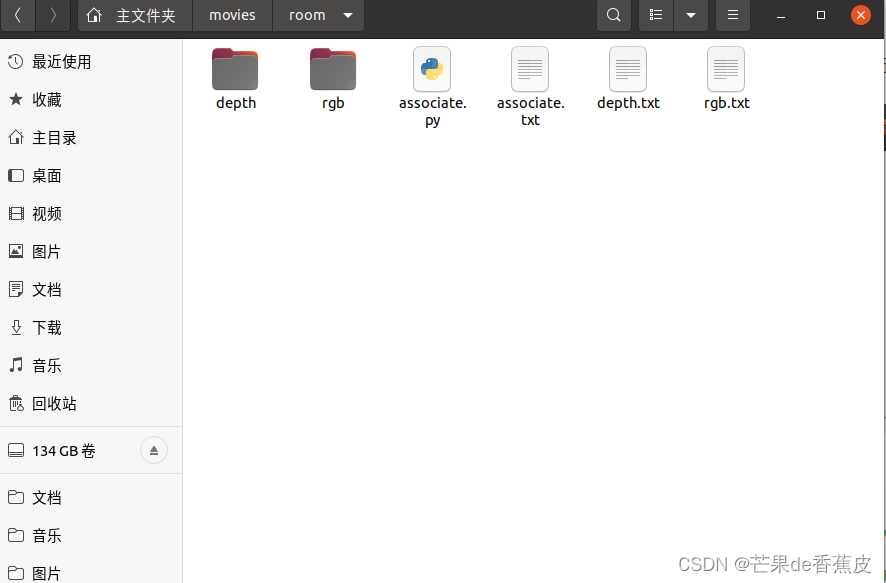
"""
The RealSense provides the color and depth images in an un-synchronized way. This means that the set of time stamps from the color images do not intersect with those of the depth images. Therefore, we need some way of associating color images to depth images.
For this purpose, you can use the ''associate.py'' script. It reads the time stamps from the rgb.txt file and the depth.txt file, and joins them by finding the best matches.
"""
#associate.py
import argparse
import sys
import os
import numpy
def read_file_list(filename):
"""
Reads a trajectory from a text file.
File format:
The file format is "stamp d1 d2 d3 ...", where stamp denotes the time stamp (to be matched)
and "d1 d2 d3.." is arbitary data (e.g., a 3D position and 3D orientation) associated to this timestamp.
Input:
filename -- File name
Output:
dict -- dictionary of (stamp,data) tuples
"""
file = open(filename)
data = file.read()
lines = data.replace(",", " ").replace("\t", " ").split("\n")
list = [[v.strip() for v in line.split(" ") if v.strip() != ""] for line in lines if
len(line) > 0 and line[0] != "#"]
list = [(float(l[0]), l[1:]) for l in list if len(l) > 1]
return dict(list)
def associate(first_list, second_list, offset, max_difference):
"""
Associate two dictionaries of (stamp,data). As the time stamps never match exactly, we aim
to find the closest match for every input tuple.
Input:
first_list -- first dictionary of (stamp,data) tuples
second_list -- second dictionary of (stamp,data) tuples
offset -- time offset between both dictionaries (e.g., to model the delay between the sensors)
max_difference -- search radius for candidate generation
Output:
matches -- list of matched tuples ((stamp1,data1),(stamp2,data2))
"""
first_keys = list(first_list.keys())
second_keys = list(second_list.keys())
potential_matches = [(abs(a - (b + offset)), a, b)
for a in first_keys
for b in second_keys
if abs(a - (b + offset)) < max_difference]
potential_matches.sort()
matches = []
for diff, a, b in potential_matches:
if a in first_keys and b in second_keys:
first_keys.remove(a)
second_keys.remove(b)
matches.append((a, b))
matches.sort()
return matches
if __name__ == '__main__':
# parse command line
parser = argparse.ArgumentParser(description='''
This script takes two data files with timestamps and associates them
''')
parser.add_argument('first_file', help='first text file (format: timestamp data)')
parser.add_argument('second_file', help='second text file (format: timestamp data)')
parser.add_argument('--first_only', help='only output associated lines from first file', action='store_true')
parser.add_argument('--offset', help='time offset added to the timestamps of the second file (default: 0.0)',
default=0.0)
parser.add_argument('--max_difference',
help='maximally allowed time difference for matching entries (default: 0.02)', default=0.02)
args = parser.parse_args()
first_list = read_file_list(args.first_file)
second_list = read_file_list(args.second_file)
matches = associate(first_list, second_list, float(args.offset), float(args.max_difference))
if args.first_only:
for a, b in matches:
print("%f %s" % (a, " ".join(first_list[a])))
else:
for a, b in matches:
print("%f %s %f %s" % (a, " ".join(first_list[a]), b - float(args.offset), " ".join(second_list[b])))
返回上一文件,打开一个终端,执行
python ax.py执行后,room/depth 和room/rgb会提取到图片
然后执行
python associate.py rgb.txt depth.txt > associate.txt
会生成一个 associate.txt
替换
用room里的数据集替换掉ORB_SLAM2_modified里的官方数据集。
最终得到的稠密点云效果感觉不是很好,准备修改一下我的相机内参再试试
已解决(5.17)
确实是相机内参的问题,调试过后,再重新跑了一下就可以了,效果还可以。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









