







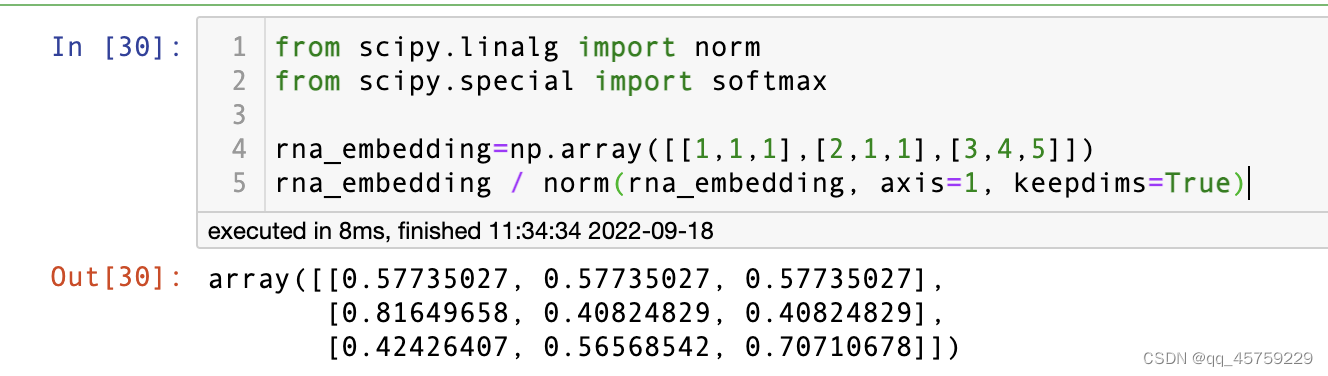
将矩阵每行进行L2标准化
实现1
from scipy.linalg import norm
from scipy.special import softmax
rna_embedding=np.array([[1,1,1],[2,1,1],[3,4,5]])
rna_embedding / norm(rna_embedding, axis=1, keepdims=True)
结果如下
实现2
from sklearn.preprocessing import Normalizer
norm2 = Normalizer(norm='l2')
norm2.fit_transform(rna_embedding)
## 按行标准化
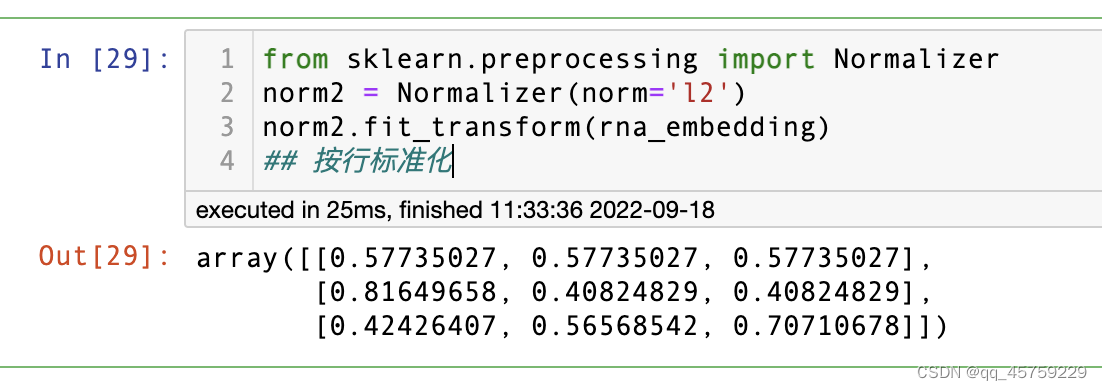 可以看到这个结果是一致的
可以看到这个结果是一致的















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









