








| sklearn.preprocessing.Binarizer(threshold=0.0, copy=True) |
根据阈值,进行特征二值化映射
threshold:阈值,默认是0,大于阈值映射为1,小于阈值映射为0;在稀疏矩阵中,该阈值参数一般不会小于0
copy:当二值化前的输入是scipy的csr格式时,二值化后的输出是否在内存中占用原位置(default True是新开辟位置存储)
import numpy as np
from scipy.sparse import csr_matrix
from sklearn import preprocessing
arr = np.array([[0,1,0,-1,0],[1,1,0,-2,0],[-2,0,-5,0,0]])
print('初始矩阵:\n',arr)
print(' ')
b = csr_matrix(arr)
print('初始矩阵的的csr格式存储:\n',b.data)
print(' ')
print('csr格式存储的id:\n',id(b))
print('--------------------------------')
binarizer = preprocessing.Binarizer(copy=False).fit(b)
print(binarizer.transform(b))
#csr格式存储的二值化结果:元组————取1的元素在原始矩阵中的位置
print('csr格式存储二值化后copr=False的id:\n',id(binarizer.transform(b)))
print(' ')
binarizerT = preprocessing.Binarizer().fit(b)
#Binarizer参数copy默认值True
#检测"初始矩阵的csr格式存储数组"二值化变换后,"新生成数组"在内存里新开辟空间的地址
print(binarizerT.transform(b))
print('csr格式存储二值化后copr=True的id:\n',id(binarizerT.transform(b)))
print('--------------------------------')
print(arr)
print(' ')
print('初始矩阵二值化后的矩阵:\n',binarizer.transform(b).toarray())
| sklearn.preprocessing.FunctionTransformer(func=None, inverse_func=None, validate=True, accept_sparse=False, pass_y=’deprecated’, kw_args=None, inv_kw_args=None) |
用自定义预处理函数,进行特征映射(如log变换)
func:变换函数,default None表示乘单位变换数组
inverse_func:逆变换函数,作用等同于该类的方法inverse_transform
validate:布尔值,检测带转换数组是否有NaN/infinity值等异常;默认True,即进行输入数组异常检测,若无异常会将原数组转化为2D NumPy或稀疏矩阵,否则报异常
accept_sparse:布尔值,是否接收稀疏矩阵输入;默认False,即输入时稀疏矩阵报异常
pass_y:布尔值,是否也对y进行同样转换;默认False
kw_args:额外的要传给func的关键字参数
inv_kw_args:额外的要传给inverse_func的关键字参数
import numpy as np
from sklearn.preprocessing import FunctionTransformer
transformer = FunctionTransformer(np.log1p) #log(1+p)
X = np.array([[0, 1], [2, 3]])
print('初始数组:\n',X)
print(' ')
print('函数映射转换后的数组:\n',transformer.transform(X))
| sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True) |
对缺失值进行填充映射
missing_values:对缺失位置进行表示的占位符标识,取值整数或者默认的”NaN”(np.nan)
strategy:对缺失位置的填充策略,’mean’/’median’/’most_frequent’用选定axis轴向数据均值/中位数/众数填充
axis:填充缺失值的方向,默认取值0,表示沿着columns方向;1表示沿着rows方向
verbose:控制填充过程的信息输出,取值整数或0,默认0表示不输出
copy:填充后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是非浮点型/稀疏矩阵表示/特殊格式CSR及CSC格式存储情况,无论copy取值是什么都原地替换
import numpy as np
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
X=[[1, 2], [np.nan, 3], [7, 6]]
print('X:\n',X)
print(' ')
imp.fit(X)
print('对X本身进行mean填充:\n',imp.transform(X))
print('--------------------------------')
Y=[[np.nan, 2], [6, np.nan], [7, 6]]
print('另一个数组Y:\n',Y)
print(' ')
print('利用从X上学到的数据统计结果,对Y进行mean填充:\n',imp.transform(Y)) 
import scipy.sparse as sp
X = sp.csc_matrix([[1, 2], [0, 3], [7, 6]])
print('csr格式存储的初始数组X:\n',X) #csr格式默认数组里取0的元素是缺失值
print(' ')
imp = Imputer(missing_values=0, strategy='mean', axis=0)
imp.fit(X)
print('对X本身进行mean填充:\n',imp.transform(X))
print('--------------------------------')
X_test = sp.csc_matrix([[0, 2], [6, 0], [7, 6]])
print('另一个csr格式存储的数组X_tes:\n',X_test)
print(' ')
print('利用从X上学到的数据统计结果,对X_test进行mean填充:\n',imp.transform(X_test)) 
| sklearn.preprocessing.KernelCenterer |
Let K(x, z) be a kernel defined by phi(x)^T phi(z), where phi is a function mapping x to a Hilbert space. KernelCenterer centers (i.e., normalize to have zero mean) the data without explicitly computing phi(x). It is equivalent to centering phi(x) with sklearn.preprocessing.StandardScaler(with_std=False).
| sklearn.preprocessing.LabelBinarizer(neg_label=0, pos_label=1, sparse_output=False) |
类别标签one-hot转换
neg_label:指明必须编码的负类标签.取值整数,默认0
pos_label:指明必须编码的正类标签.取值整数,默认1
sparse_output:是否将二值编码后的数组以csr格式返回.布尔值,默认False
from sklearn import preprocessing
lb = preprocessing.LabelBinarizer()
a=[1, 2, 6, 4, 2]
print('初始数组:\n',a)
print(' ')
lb.fit(a)
print('初始数组包含的所有类别:\n',lb.classes_)
print(' ')
print('对初始数组进行one-hot转换后的数组:\n',lb.transform(a)) #每一行表示原来数组的一个数
print('--------------------------------')
b=[1, 6]
print('另外一个数组:\n',b)
print('对另一数组按初始数组类别编码方式,进行one-hot转换后的数组:\n',lb.transform(b))
lb = preprocessing.LabelBinarizer()
lb.fit_transform(['yes', 'no', 'no', 'yes'])
import numpy as np
td=np.array([[0, 1, 1], [1, 0, 0]])
print('二维测试数组:\n',td)
print('二维测试数组的类别:\n',lb.classes_)
print('对新来数组转化效果:\n',lb.transform([0, 1, 2, 1]))
| sklearn.preprocessing.LabelEncoder |
用0到n-1对具有n个类别的特征列编码
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
LE=[1, 2, 2, 6]
print('初始数组:\n',LE)
print(' ')
le.fit(LE)
print('查看初始数组的类别:\n',le.classes_)
print(' ')
print('对初始数组编码转换:\n',le.transform(LE))
print('--------------------------------')
AN=[1, 1, 2, 6]
print('测试数组:\n',AN)
print(' ')
tan=le.transform(AN)
print('对测试数组利用初始数组的编码方案进行转换:\n',tan)
print(' ')
print('对转换后的测试数组利用逆变换:\n',le.inverse_transform(tan))
#tan中不能出现超出{1,2,6}范围的数,否则由于编码时没存在会报错
le = preprocessing.LabelEncoder()
ini=["paris", "paris", "tokyo", "amsterdam"]
print('查看初始数组:\n',ini)
print(' ')
le.fit(ini)
print('查看初始数组的类别:\n',list(le.classes_)) #按类别名称首字母在字母表中的顺序编码
print(' ')
print('对初始数组编码结构:\n',le.transform(ini))
print('--------------------------------')
an=["tokyo", "tokyo", "paris"]
print('查看测试数组:\n',an)
print(' ')
ant=le.transform(an)
print('对另一测试数组的编码:\n',ant)
print(' ')
print('对测试数组编码后求逆:\n',list(le.inverse_transform(ant)))
| sklearn.preprocessing.MultiLabelBinarizer(classes=None, sparse_output=False) |
多类别标签数组,按”维度&位置”进行二值化编码
classes:按顺序给定的类别标签
sparse_output:输出是二值数组时,是否转化成CSR格式,布尔值,默认False是不转化
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
t=[(1, 2), (3,)]
print('查看初始数组:\n',t)
print(' ')
mlb.fit(t)
print('查看初始数组有多少类:\n',mlb.classes_)
print(' ')
print('按多标签出现维度&位置对初始数组编码:\n',mlb.transform(t))
#行数和初始建模数组的行数一样;列数和类别数一样,列的每个位置对应一个类别
#1出现的位置表示,测试数组中的某行元素,属于某个列对应的类别
print('--------------------------------')
at=[[3,2,3],[1,2,1]]
print('查看测试数组:\n',at)
print(' ')
print('按对初始数组的编码规则,对测试数组编码:\n',mlb.transform(at))
st=[set(['sci-fi', 'thriller']), set(['comedy'])]
print(mlb.fit_transform(st))
print(mlb.classes_)
| sklearn.preprocessing.MaxAbsScaler(copy=True) |
对”每个特征列”:分别提取”该列绝对值最大的值”,再对该特征列除”该绝对值最大的值”进行比例缩放
copy:布尔值,默认True,表示转换后的数组再开辟一块新的内存存放
可调用属性:
scale_:取值和特征列维度一致,每个特征的缩放尺度
max_abs_:取值和特征列维度一致,每个特征列的绝对值最大的值
n_samples_seen_:标准化处理的样本数
| sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1), copy=True) |
给定一个取值范围,将”每个特征列”都转化到该范围
feature_range:要转化的特征取值范围,取值格式是元组(min,max),默认值(0,1)
copy:布尔值,默认True,表示转换后的数组再开辟一块新的内存存放
import numpy as np
from sklearn.preprocessing import MinMaxScaler
data = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
print(data)
print(' ')
scaler = MinMaxScaler()
scaler.fit(data)
print(scaler.data_max_) #data_max_返回每个特征列的最大取值
print(' ')
print(scaler.data_min_) #data_min_返回每个特征列的最小取值
print(' ')
print(scaler.transform(data))
print(' ')
print(scaler.transform([[2, 2]]))
| sklearn.preprocessing.Normalizer(norm=’l2’, copy=True) |
对数据样本(数据表每行)进行归一化转化
norm:归一化度量标准,’l1’是l1范数,’l2’是l2范数,默认是’l2’
copy:布尔值,默认True,表示转换后的数组再开辟一块新的内存存放
import numpy as np
from sklearn.preprocessing import Normalizer
X = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
print(X)
print(' ')
normalizer = Normalizer().fit(X)
print(normalizer.transform(X))
print(' ')
print(normalizer.transform([[-1., 1., 0.]]))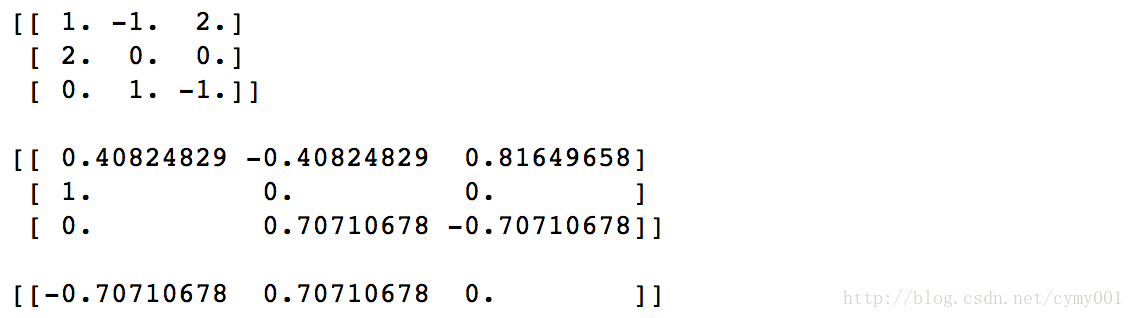
| sklearn.preprocessing.OneHotEncoder(n_values=’auto’, categorical_features=’all’, dtype=, sparse=True, handle_unknown=’error’) |
对分类特征进行独热向量编码
n_values:每个特征的不同取值数量,默认’auto’表示从训练数据中自动确认;也可以给定每个特征列的具有多少个不同特征取值类别的数组;更暴力的办法是给定一个整数,每个特征列的不同取值类别数都等于该值
categorical_features:指定那些特征列是类别型特征,对类别型特征独热,非类别型特征会自动补到矩阵右侧.可通过数组索引指定,默认’All’表示所有特征都看成类别型的
dtype:指定编码后输出的numpy数组数据类型,默认np.float
sparse:指定返回稀疏矩阵还是数组,默认True,即返回稀疏矩阵
handle_unknown:如果在变换过程中出现未知的分类特征,是否报异常.取值可以是字符,’error’或’ignore’
import numpy as np
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
oh=np.array([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
print(oh)
print(' ')
enc.fit(oh)
#三组列,第一组0/1两类,第二组0/1/2三类,第三组0/1/2/3四类
print(enc.transform(oh).toarray())
print(' ')
print(enc.transform([[0, 1, 3]]).toarray())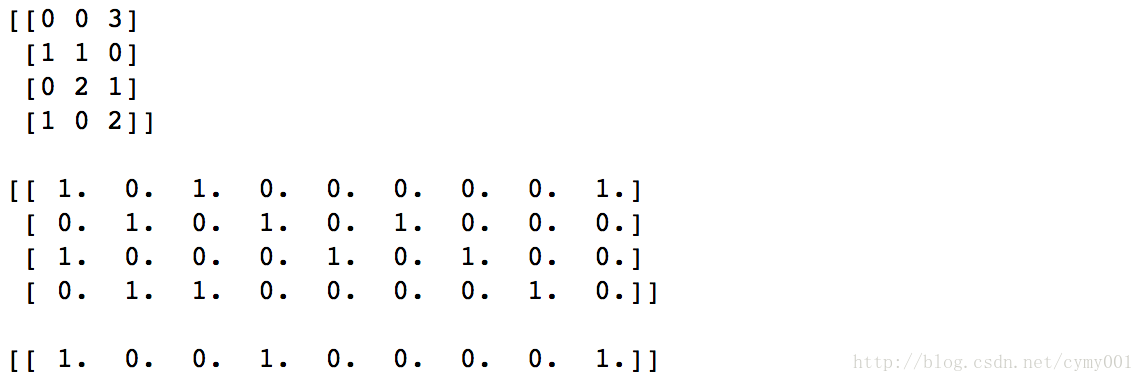
enc = preprocessing.OneHotEncoder(n_values=[2, 3, 4])
oha=np.array([[1, 2, 3], [0, 2, 0]])
print(oha)
print(' ')
enc.fit(oha)
#三组列,第一组2类,第二组3类,第三组4类
print(enc.transform([[1, 0, 0]]).toarray())
| sklearn.preprocessing.PolynomialFeatures(degree=2, interaction_only=False, include_bias=True) |
生成多项式特征或组合特征矩阵
degree:不同特征形成的组合多项式特征最高次数
interaction_only:只利用不同特征的组合特征,布尔值,默认取值False是包含单一特征变换
include_bias:是否包含常特征项,布尔值,默认取值True是包含
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
X = np.arange(6).reshape(3, 2)
print(X)
print(' ')
poly = PolynomialFeatures(2)
print(poly.fit_transform(X)) #1,x1,x2,x1^2,x1x2,x2^2
print(' ')
poly = PolynomialFeatures(interaction_only=True) #1,x1,x2,x1x2
print(poly.fit_transform(X))
| sklearn.preprocessing.QuantileTransformer(n_quantiles=1000, output_distribution=’uniform’, ignore_implicit_zeros=False, subsample=100000, random_state=None, copy=True) |
将数据分布根据其分位数转换成均匀/正态分布
首先单独将每列特征转化为均匀分布或正态分布,对于一个给定的特征,该转换倾向于加大数据的高频取值作用,减少边界异常点的影响(低于或高于拟合范围的特征数据被划归为边界值).利用累计密度函数对原始特征进行映射.该变换是非线性的,它可能会扭曲在相同尺度下测量的变量之间的线性相关性,但可对不同的尺度变量进行比较.
n_quantiles:要计算的分位数,即离散累计密度函数的份数
output_distribution:将数据转换的目标边缘分布,’uniform’/’normal’是均匀/正态分布,默认是’uniform’
ignore_implicit_zeros:计算分位数时是否忽略稀疏条目
subsample:用于估计分位数的采样样本量,默认样本量1e5,针对相同数组的稀疏/稠密存储格式会得到不同结果
random_state:随机种子
copy:缩放后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是numpy.array,无论copy取值是什么都原地替换
import numpy as np
from sklearn.preprocessing import QuantileTransformer
rng = np.random.RandomState(0)
X = np.sort(rng.normal(loc=0.5, scale=0.25, size=(10, 1)), axis=0)
print(X)
print(' ')
qt = QuantileTransformer(n_quantiles=10, random_state=0)
print(qt.fit_transform(X)) 
| sklearn.preprocessing.RobustScaler(with_centering=True, with_scaling=True, quantile_range=(25.0, 75.0), copy=True) |
根据分位数缩放数据
该缩放器对离群点表现稳健,即移除了中位数和数据原有尺度的影响.计算训练集中样本的相关统计量(分位数),对每个特征(或每个样本,根据选定的轴向)分别居中及缩放.通过消除均值和方差将数据集进行标准化,会受到离群点的影响(离群点对均值和方差的计算有影响).而通过中位数和四分位进行标准化受到的影响会减小,进而得到较好的结果.
with_centering:缩放器scaler作用前将数据居中,会破坏数组的稀疏性
with_scaling:将数据缩放到四分位数范围
quantile_range:计算scale_时用的分位数范围
copy:布尔值,默认True,表示转换后的数组再开辟一块新的内存存放
可调用属性:
center_:训练集中每个特征的中值
scale_:训练集中每个特征的四分位数取值范围
| sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True) |
该缩放器通过消除均值和方差对特征进行标准化
通过计算训练集上样本的相关统计量,单独对每个特征进行居中和缩放.
数据集的标准化是许多机器学习估计器的共同要求:如某个特征分布跟标准正态分布差异很大,学习器表现可能会很糟糕.如,学习算法的目标函数中使用的许多元素都假定所有特征都以0为中心并具有同阶的方差(如支持向量机的RBF核或线性模型的L1和L2正则化项).如果某特征的方差数量级远大于其他特征,该特征可能会支配目标函数,使估计器无法按照预期,正确地学习其他特征.
copy:缩放后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是非浮点型/稀疏矩阵表示/特殊格式CSR及CSC格式存储情况,无论copy取值是什么都原地替换
with_mean:布尔值,默认True,表示在缩放前先进行居中.该操作作用于稀疏矩阵时,会破坏矩阵的稀疏存储,加大内存占用报异常
with_std:布尔值,默认True,表示用标准差进行缩放
可调用属性:
scale_:取值是和特征同维度的数组.每个特征相对缩放量
mean_:取值是和特征同维度的数组.训练集中每个特征的均值
var_:取值是和特征同维度的数组.训练集中每个特征的方差
n_samples_seen_:估计器处理的样本数
import numpy as np
from sklearn.preprocessing import StandardScaler
data = np.array([[0, 0], [0, 0], [1, 1], [1, 1]])
print(data)
print(' ')
scaler = StandardScaler()
scaler.fit(data)
print(scaler.scale_)
print(scaler.mean_)
print(' ')
print(scaler.transform(data))
print(' ')
print(scaler.transform([[2, 2]]))
| sklearn.preprocessing.add_dummy_feature(X, value=1.0) |
增加一个哑特征列当做截距项,返回数据表是在原数据表的第一列加了一列
X:要添加哑特征了的数据表
value:哑特征列系数
import numpy as np
from sklearn.preprocessing import add_dummy_feature
adf=np.array([[0, 1], [1, 0]])
print(adf)
print(' ')
print(add_dummy_feature(adf,3))
| sklearn.preprocessing.binarize(X, threshold=0.0, copy=True) |
对特征数组用阈值进行二值化转换
X:要进行二值化的数据表
threshold:阈值,大于该阈值取1,小于该阈值取0,默认取值0
copy:二值化后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是numpy.array/scipy.sparse CSR/CSC存储情况且axis=1,无论copy取值是什么都原地替换
import numpy as np
from sklearn.preprocessing import binarize
X = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
print(X)
print(' ')
print(preprocessing.binarize(X,threshold=1.1))
| sklearn.preprocessing.label_binarize(y, classes, neg_label=0, pos_label=1, sparse_output=False) |
在多分类情形,利用one-vs-all框架,根据给定的标签组,对数据进行二值化转变
y:待编码的数组
classes:给定的二值化编码要参考的标签组
neg_label:指明必须编码的负类标签.取值整数,默认0
pos_label:指明必须编码的正类标签.取值整数,默认1
sparse_output:是否将二值编码后的数组以csr格式返回.布尔值,默认False
from sklearn.preprocessing import label_binarize
lb=[1, 6]
print(lb)
print(' ')
print(label_binarize(lb, classes=[1, 2, 4, 6]))
| sklearn.preprocessing.maxabs_scale(X, axis=0, copy=True) |
在不破坏稀疏性前提下,将每个数据行/列分别缩放到[-1,1]
X:缩放器要处理的数据表
axis:缩放的方向,axis=0表示按特征列分别缩放,axis=1表示按每个样本分别缩放
copy:缩放后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是numpy.array,无论copy取值是什么都原地替换
| sklearn.preprocessing.minmax_scale(X, feature_range=(0, 1), axis=0, copy=True) |
根据给定的范围,对数据行/列进行缩放
X:缩放器要处理的数据表
feature_range:要将数据转换的目标范围
axis:缩放的方向,axis=0表示按特征列分别缩放,axis=1表示按每个样本分别缩放
copy:缩放后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是numpy.array,无论copy取值是什么都原地替换
| sklearn.preprocessing.normalize(X, norm=’l2’, axis=1, copy=True, return_norm=False) |
将给定的数据在指定向量方向上缩放到单位范数
X:要进行缩放的数据表
norm:按’l1’/’l2’范数度量进行缩放,默认’l2’
axis:沿着哪个轴进行缩放,axis=1是对每个样本行进行缩放,axis=0是对每个特征列进行缩放
copy:缩放后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是numpy.array/scipy.sparse CSR存储情况且axis=1,无论copy取值是什么都原地替换
return_norm:是否返回计算范数.布尔值,默认False
import numpy as np
from sklearn.preprocessing import normalize
X = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
print(X)
print(' ')
X_normalized = normalize(X, norm='l2',return_norm=True)
X_normalized
| sklearn.preprocessing.quantile_transform(X, axis=0, n_quantiles=1000, output_distribution=’uniform’, ignore_implicit_zeros=False, subsample=100000, random_state=None, copy=False) |
将数据分布根据其分位数转换成均匀/正态分布
首先单独将每列特征转化为均匀分布或正态分布,对于一个给定的特征,该转换倾向于加大数据的高频取值作用,减少边界异常点的影响(低于或高于拟合范围的特征数据被划归为边界值).利用累计密度函数对原始特征进行映射.该变换是非线性的,它可能会扭曲在相同尺度下测量的变量之间的线性相关性,但可对不同的尺度变量进行比较.
X:要转换的数据表
axis:指定对哪个轴计算均值和标准差,0表示沿着纵轴特征方向,1表示沿着横轴样本方向
n_quantiles:要计算的分位数,即离散累计密度函数的份数
output_distribution:将数据转换的目标边缘分布,’uniform’/’normal’是均匀/正态分布,默认是’uniform’
ignore_implicit_zeros:计算分位数时是否忽略稀疏条目
subsample:用于估计分位数的采样样本量,默认样本量1e5,针对相同数组的稀疏/稠密存储格式会得到不同结果
random_state:随机种子
copy:缩放后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是numpy.array,无论copy取值是什么都原地替换
import numpy as np
from sklearn.preprocessing import quantile_transform
rng = np.random.RandomState(0)
X = np.sort(rng.normal(loc=0.5, scale=0.25, size=(10, 1)), axis=0)
print(X)
print(' ')
qt=quantile_transform(X, n_quantiles=10, random_state=0)
print(qt)
print(' ')
| sklearn.preprocessing.robust_scale(X, axis=0, with_centering=True, with_scaling=True, quantile_range=(25.0, 75.0), copy=True) |
根据分位数缩放数据
X:要处理的数据表
axis:指定沿着哪个轴计算中位数和分位数,0表示沿着纵轴特征方向,1表示沿着横轴样本方向
with_centering:布尔值,默认True,表示缩放器作用前将数据居中
with_scaling:布尔值,默认True,表示将数据缩放到unit variance(or unit standard deviation)范围
quantile_range:取值格式元组,计算scale_时用的分位数范围
copy:缩放后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是numpy.array/scipy.sparse CSR存储情况且axis=1,无论copy取值是什么都原地替换
| sklearn.preprocessing.scale(X, axis=0, with_mean=True, with_std=True, copy=True) |
根据指定轴向将数据居中和按标准差缩放
X:要进行居中和缩放的数据表
axis:指定沿着哪个轴计算均值和标准差,0表示沿着纵轴特征方向,1表示沿着横轴样本方向
with_mean:布尔值,默认True,表示在缩放前先进行居中
with_std:布尔值,默认True,表示用标准差进行缩放
copy:缩放后的数组是否直接在内存里原地存放,布尔值,默认True是原地替换.对变换前矩阵,如果是numpy.array/scipy.sparse CSR存储情况且axis=1,无论copy取值是什么都原地替换















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









