







LLMs包含大量的模型参数,进行完整参数调整可能成本很高。PEFT(Parameter-Efficient Fine-Tuning,参数高效微调 ) 技术旨在通过最小化微调参数的数量和计算复杂度,提高预训练模型在新任务上的性能,降低LLM的微调成本。LoRA(Low-Rank Adaptation) 是PEFT一种常见技术。
1. LoRA原理:
LoRA的核心思想是通过 低秩分解 来近似更新模型中的大参数矩阵。在微调过程中,原始的预训练模型参数被冻结,而通过引入两个小矩阵(A和B)来近似更新大矩阵。这种方法可以显著减少需要训练的参数量。
总结:将全参数微调理解成“冻住的预训练权重” + “微调过程中产生的权重更新”
更简单地说:LoRA 认为微调不是调整参数, 而是学习参数的变化
全量微调是参数由 W W W 变成 W ′ W' W′ 以适应新任务,而Lora将微调视为 W ′ = W + Δ W W'=W+\Delta W W′=W+ΔW, Δ W \Delta W ΔW是指参数的变化,Lora旨在学习这种变化。
Lora的核心思想介绍完毕,那么Lora是通过什么方式学习参数变化的?为什么这样可以减低微调成本?Low-Rank的低秩是什么意思?这是自然会产生的疑问,首先我们来介绍一些背景知识,即什么是秩。
2. 背景知识介绍
矩阵的线性独立性:是线性代数中的一个基本概念,用于表示矩阵的列向量或行向量是否能够通过其他向量的线性组合来表示,简单来说,它描述了一个矩阵中各列(或行)之间是否存在冗余。
下面介绍什么是秩:用于描述矩阵中线性独立的行或列的数量,表示矩阵的“复杂度”或“信息量”,秩越大,矩阵的信息量越大。


3. Lora中的低秩是什么意思?
1)许多工作已经表明,深度学习的矩阵往往是过参数化的。
2)特征的内在维度指的是在深度学习中的真实或潜在的低维结构或信息的维度。它表示特征中存在的有效信息的维度,与特征的实际维度可能不同,这个内在维度指的是我们解决一个问题实际上需要的参数空间的维度,对模型的微调通常调整的也是这些低秩的内在维度。
3)现在许多工作认为,预训练模型拥有极小的内在维度(instrisic dimension),即存在一个极低维度的参数,微调它和在全参数空间中微调能起到相同的效果。(《Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning》)
因此,矩阵可以以线性依赖的形式包含一定程度的“重复信息”(低秩),即全参数微调中的增量权重可能也存在冗余的信息,因此我们并不需要用完整的 d*d 尺寸来表示它。我们可以使用因式分解来利用这个想法,用两个较小的矩阵(A,B)来表示一个大矩阵(W)。这种因式分解的想法使 LoRA 能够占用如此小的内存占用空间. 这种学习变化矩阵因素的想法依赖于一个核心假设,即大型语言模型中的权重矩阵具有很大的线性依赖性。
4. Lora实现

下面是一个示意图:
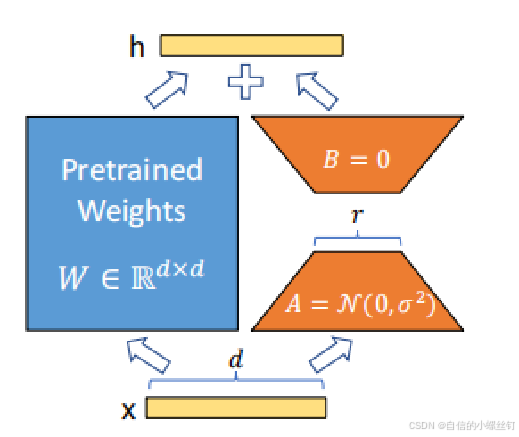
Lora微调中的参数:
- 秩 (Rank, r): 秩决定了每个更新矩阵的维度,也就是低秩分解矩阵 A 和 B 的维度。更高的秩意味着更多的参数和更复杂的模型,而较低的秩则减少了计算量和存储需求,但可能导致模型的表达能力降低。(通常情况下,r 的取值范围在 1 到 128 之间。对于大多数任务,较小的 r 值(如 4、8 或 16) 已经能够取得较好的效果)
- lora_alpha: 是一个缩放因子,用于调整低秩矩阵的影响力。它可以理解为对低秩矩阵 A 和 B 的更新幅度进行放大或缩小。如果
lora_alpha较大,低秩矩阵的影响会更大,可能会对原始模型的权重产生较大的影响,适应任务的效果会更明显。 - lora_target: 指示需要应用低秩适应(LoRA)模块的特定网络层或模块
4. Lora一般用在哪些参数上
现在有一种说法是:LoRA通常在模型微调时被用于Transformer模型的注意力机制中,尤其是在Q和V矩阵中。(为什么?我还没搞懂,待看论文后回答)
5. Lora的优势
- 参数高效:仅需训练少量参数即可实现模型的微调。
- 保持模型性能:在减少参数量的同时,能够有效提升模型在新任务上的表现。
- 推理延迟低:训练完成后,LoRA参数可以与原始模型参数合并,不会引入额外的推理延迟。
6. Lora的变体
以下是基于LoRA的几种变体及其改进点:
-
LoRA+(LoRA Plus): LoRA 的增强版本,主要通过为矩阵 A 和 B 引入不同的学习率改进Lora,其中矩阵 B 的学习率设置为矩阵 A 的 16 倍。这种策略可以显著提高训练效率,同时提升模型精度(约 2%),并将训练时间缩短 2 倍。
(前提:原始 LoRA 中,矩阵 A 和 B 使用相同的学习率进行更新。该方法认为当模型的宽度(即嵌入维度)较大时,这种单一学习率的设置会导致微调效果不佳。) -
QLoRA(Quantized LoRA): QLoRA 是 LoRA 的量化版本,主要通过对低秩矩阵进行量化,从而显著降低存储和计算成本。这使得模型在显存受限的环境中运行更加高效。
-
AdaLoRA(Adaptive LoRA):AdaLoRA 是 LoRA 的自适应版本,它支持动态调整秩,可根据任务和数据的复杂度动态调整低秩矩阵的秩,避免了固定秩带来的限制。

















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









