







[AAAI 2024] HDMixer: Hierarchical Dependency with Extendable Patch for Multivariate Time Series Forecasting
研究背景与动机
文章介绍了多变量时间序列预测的研究背景,指出了现有方法在处理此类问题时存在的局限性。多变量时间序列预测在多个领域如金融、气象、医疗等都有重要应用。传统的预测方法往往忽略了时间序列之间的相互依赖性,且难以处理长序列数据。
文章还提到了Length-fixed patch方法的局限性,即其无法适应不同时间序列的特点,导致模型性能受限。这为研究提供了动机,即需要一种新的方法来更好地捕捉多变量时间序列之间的复杂依赖关系。
模型和方法
作者认为,通过Length-Extendable Patcher (LEP) 可以自适应地扩展时间序列的长度,并结合Hierarchical Dependency Explorer (HDE) 来捕捉不同层次的时间依赖性,从而提高预测的准确性。
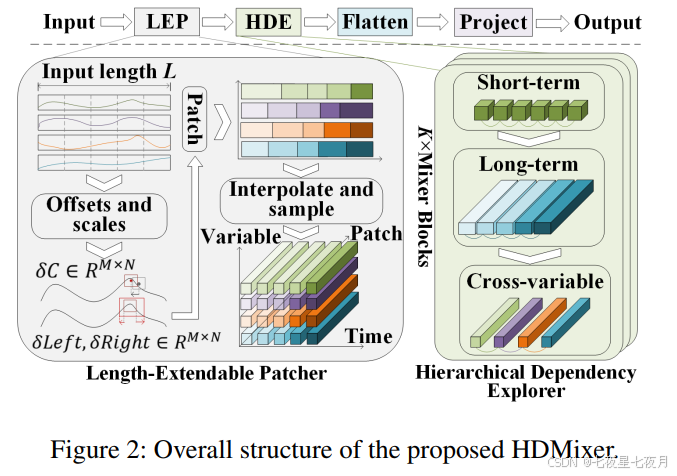
Length-Extendable Patcher (LEP)
LEP 的设计目的是为了克服传统固定长度 patch 方法在处理时间序列数据时的局限性。固定长度的 patches 可能会丢失重要的边界信息,如完整的峰值或周期。因此,LEP 的设计理念是自适应地调整 patch 长度,以保留更多的语义信息。
LEP的大概思路如下:
- 这一部分的目的是将原始时间序列分割成具有可变长度的 patches,以更好地捕捉时间序列中的局部特征。
- 与传统的固定长度 patch 方法不同,LEP 通过学习得到的偏移量和扩展长度来动态调整 patch 的大小。
- 通过 bi-linear 插值方法来处理非整数索引的采样问题,保证了模型的可微性。
为了确保 LEP 生成的 patches 能够提供有用的信息,文章引入了 Patch Entropy Loss。这个损失函数基于近似熵来衡量不同 patch 方法的复杂性差异。
LEP 的主要优势在于其能够自适应地生成 patches,从而保留了时间序列中的边界信息,减少了信息丢失,并提高了模型的预测性能。
通过这种方式,LEP 为多变量时间序列预测提供了一种更加灵活和有效的数据预处理方法。
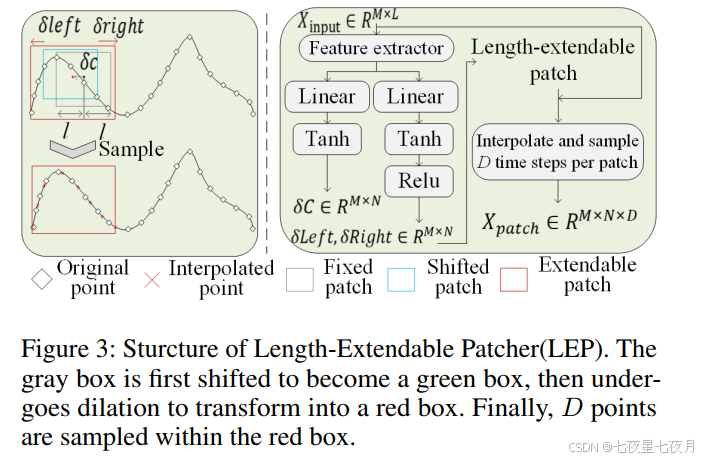
Hierarchical Dependency Explorer (HDE)
HDE 的设计理念是利用纯多层感知机 (MLP) 结构来有效捕捉时间序列数据中的长期依赖、短期依赖以及变量间的交互。它的目的是为了提高模型在多变量时间序列预测中的表现。
HDE的大概思路如下:
- HDE 是模型的核心部分,用于探索和捕捉时间序列中的多尺度依赖关系。
- 它由多个 HDMixer 块组成,每个块通过多层感知机 (MLP) 来分别处理短期依赖、长期依赖和变量间的交互。
- HDMixer 块的设计允许模型在不同的时间尺度上捕捉依赖关系,同时保持参数数量的可控性。
HDE 的主要优势包括:捕捉多尺度依赖:通过不同的 MLP 层,HDE 能够捕捉到时间序列数据中的多尺度依赖关系。参数效率:由于参数共享和层归一化,HDE 在保持模型复杂性的同时,提高了参数的效率。泛化能力:HDE 的设计使得模型具有良好的泛化能力,能够适应不同的时间序列数据。
代码
# Cell
from typing import Callable, Optional
import torch
from torch import nn
from torch import Tensor
import torch.nn.functional as F
import numpy as np
from layers.PatchTST_layers import *
from layers.RevIN import RevIN
from layers.box_coder1D import *
import math
def generate_pairs(n):
pairs = []
for i in range(n):
for j in range(n):
if i != j:
pairs.append([i, j])
return np.array(pairs)
def cal_PSI(x, r):
#[bs x nvars x patch_len x patch_num]
x = x.permute(0,1,3,2)
batch, n_vars, patch_num, patch_len = x.shape
x = x.reshape(batch*n_vars, patch_num, patch_len)
# Generate all possible pairs of patch_num indices within each batch
pairs = generate_pairs(patch_num)
# Calculate absolute differences between pairs of sequences
abs_diffs = torch.abs(x[:, pairs[:, 0], :] - x[:, pairs[:, 1], :])
# Find the maximum absolute difference for each pair of sequences
max_abs_diffs = torch.max(abs_diffs, dim=-1).values
max_abs_diffs = max_abs_diffs.reshape(-1,patch_num,patch_num-1)
# Count the number of pairs with max absolute difference less than r
c = torch.log(1+torch.mean((max_abs_diffs < r).float(),dim=-1))
psi = torch.mean(c,dim=-1)
return psi
def cal_PaEn(lfp,lep,r,lambda_):
psi_lfp = cal_PSI(lfp,r)
psi_lep = cal_PSI(lep,r)
psi_diff = psi_lfp - psi_lep
lep = lep.permute(0,1,3,2)
batch, n_vars, patch_num, patch_len = lep.shape
lep = lep.reshape(batch*n_vars, patch_num, patch_len)
sum_x = torch.sum(lep, dim=[-2,-1])
PaEN_loss = torch.mean(sum_x*psi_diff)*lambda_ # update parameters with REINFORCE
return PaEN_loss
class Model(nn.Module):
def __init__(self, configs, max_seq_len:Optional[int]=1024, d_k:Optional[int]=None, d_v:Optional[int]=None, norm:str='BatchNorm', attn_dropout:float=0.,
act:str="gelu", key_padding_mask:bool='auto',padding_var:Optional[int]=None, attn_mask:Optional[Tensor]=None, res_attention:bool=False,
pre_norm:bool=False, store_attn:bool=False, pe:str='zeros', learn_pe:bool=True, pretrain_head:bool=False, head_type = 'flatten', verbose:bool=False, **kwargs):
super().__init__()
# load parameters
c_in = configs.enc_in
self.seq_len=context_window = configs.seq_len
target_window = configs.pred_len
n_layers = configs.e_layers
n_heads = configs.n_heads
d_model = configs.d_model
d_ff = configs.d_ff
dropout = configs.dropout
fc_dropout = configs.fc_dropout
head_dropout = configs.head_dropout
individual = configs.individual
patch_len = configs.patch_len
stride = configs.stride
padding_patch = configs.padding_patch
revin = configs.revin
affine = configs.affine
subtract_last = configs.subtract_last
decomposition = configs.decomposition
kernel_size = configs.kernel_size
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









