







ICLR 2023
1 intro
1.1 motivation
- 之前用Transformer预测时间序列的工作,大多集中在建模时间维度的关系上。
- 利用时间维度的自注意力机制,建立不同时间步之间的关系
- 而在多元时间序列预测中,各个变量之间的关系也很重要。
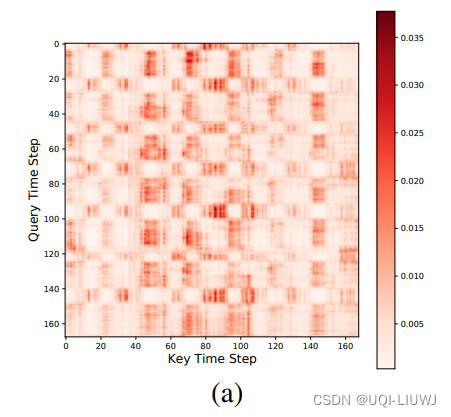
- 之前的模型,主要是将每个时间步的多元变量压缩成一个embedding,再进行时间维度的attention。
- 这种方法的问题是缺少对不同变量之间关系的建模,直接每个时间步融合的方式显然太粗糙了
- 之前的模型,主要是将每个时间步的多元变量压缩成一个embedding,再进行时间维度的attention。
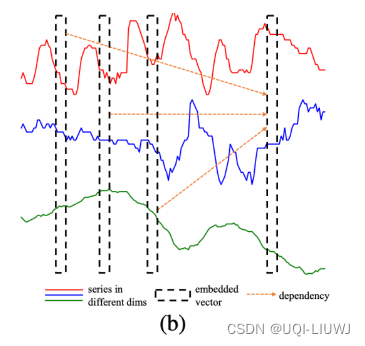
- 同时论文通过观察时间序列的attention map,发现时间序列数据的attention feature是分块的
- ——>将时间维度切成patch,而不是一个一个时刻,可能是更好的解决方法
1.2 论文思路
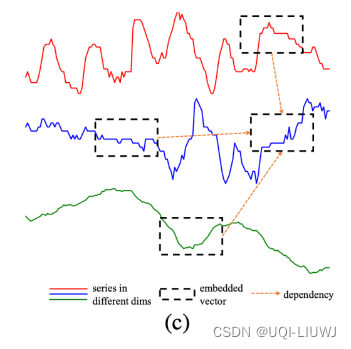
- 对Transformer在多元时间序列预测的应用中进行了改造
- 将多元时间序列转换成patch
- 增加了变量维度之间的attention
2 模型
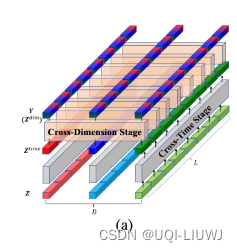
2.1 Dimension-Segment-Wise Embedding
- 将时间序列按照不同的长度分成patch:
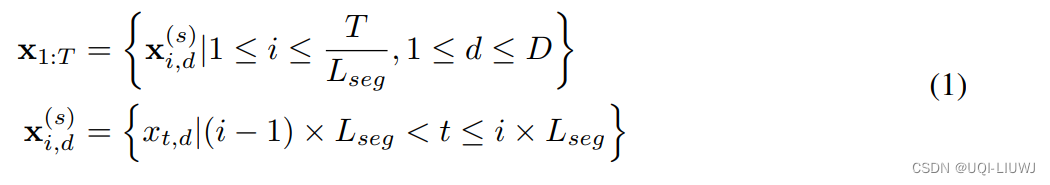
- 公式(1)表示按照Lseg的长度来切分时间序列成patch
- 论文假设时间序列长度T是可以被Lseg整除的
- 然后使用线性映射得到patch的embedding,再加上相应的位置编码,得到每个patch的输入表征
- 经过embedding之后,得到了多元时间序列的表征
- 每个
都是一段单变量时间序列
- 每个

2.2 Two-Stage Attention Layer
- 两阶段的attention:第一阶段在时间维度进行attention,第二阶段在多变量之间进行attention
- 输入先过一层时间维度attention,独立的进行每个序列时序上的建模
- 然后再输入到一层空间维度attention,对齐不同变量各个时间步的编码
2.2.1 时间维度attention
时间序列的每一个dimension分别进行 multi-head attention(和别的work没有太大的区别)
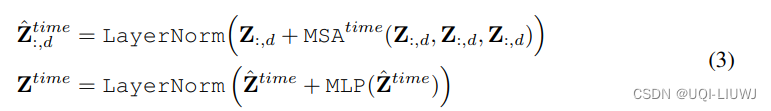
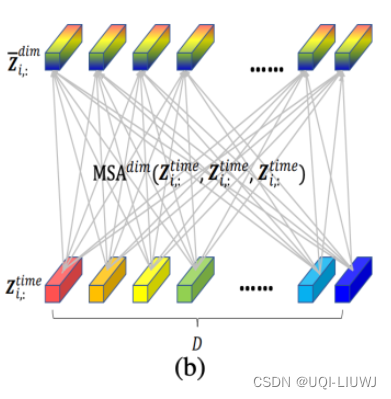
2.2.3 空间维度attention
- 对齐不同变量的各个时间步
- 每一个时刻,在变量维度做self-attention
- 但是直接变量对变量进行self-attention会导致运算复杂度较高
- 因此本文提出了使用路由的方式——增加几个中间向量
- 将变量各个时间步的信息先利用一层attention汇聚到中间向量上
- 再利用中间向量和原序列做self-attention
- 中间向量可以看成是一种路由,先对输入信息做个聚类,再进一步分发,起到了降低运算量的作用
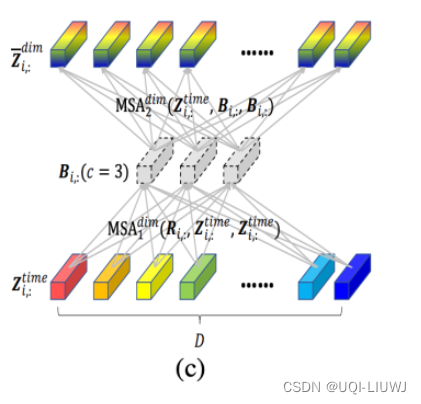
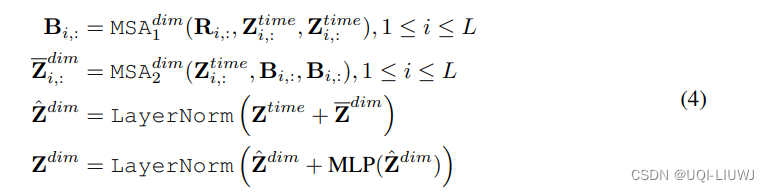
(c是一个常数)是一个可学习的中间向量
是序列和中间向量进行self-attention后的结果,这个结果会和序列再次做self-attention,得到最终的变量间信息交互的编码结果
- 因此本文提出了使用路由的方式——增加几个中间向量
2.3 层次encoder-decoder
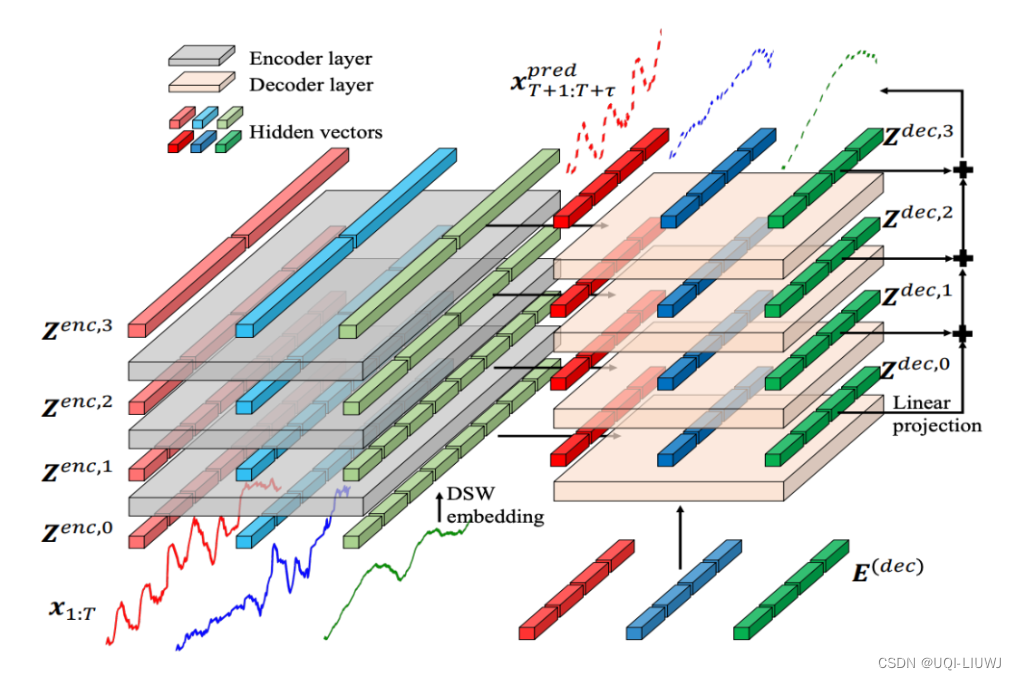
2.3.1 encoder
- 基于上面提到的两阶段attention网络,对输入进行了不同尺寸的patch生成
- 序列从上到下被分成了2个、4个、8个等不同的patch,每层的每个patch所包含的窗口长度不同
- 模型的输入最开始是细粒度patch,随着层数增加逐渐聚合成更粗粒度的patch
- ——>让模型从不同的粒度提取信息
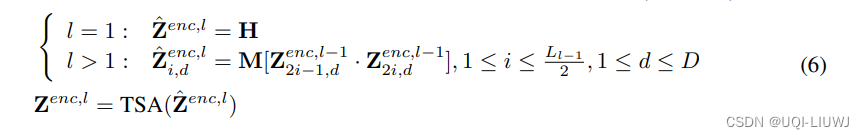
一个TSA就是一个时间+空间attention层
2.3.2 decoder
- 不同的层先分别利用TSA预测
- 然后将各层预测结果相加

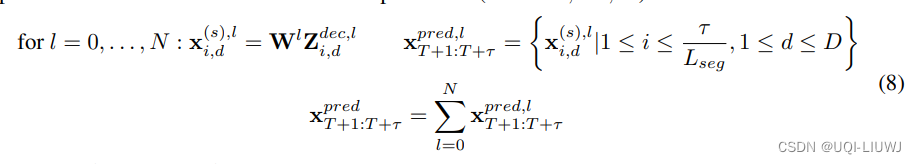
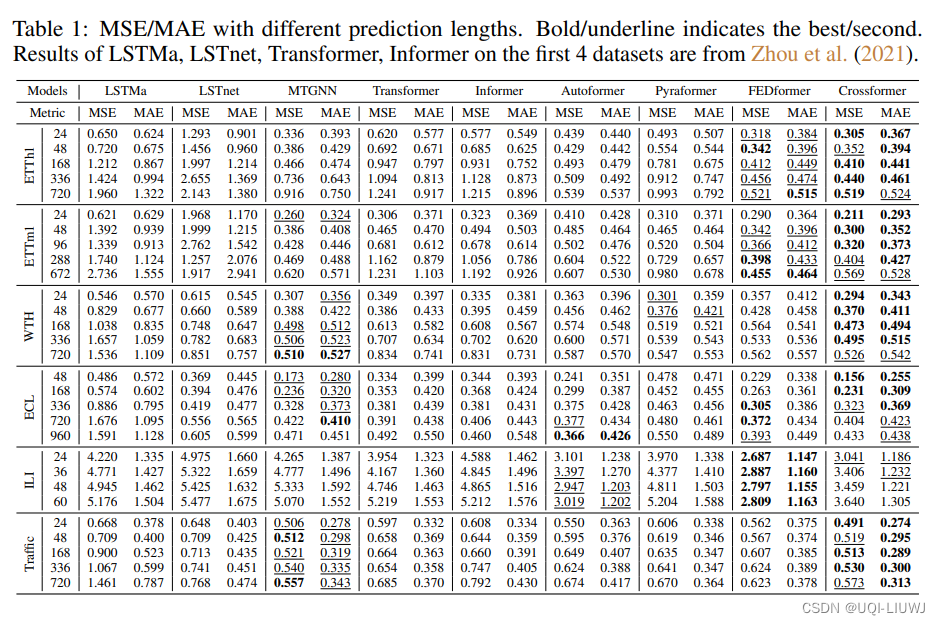
3 实验结果
















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











