







背景
近年来,采用三维和二维数据的应用层出不穷,它们都需要将三维模型与二维图像进行匹配。大型定位识别系统可以估算出照片拍摄的位置。在全球定位系统可能失灵的情况下,地理定位系统可以进行地点识别,对自动驾驶非常有用。此外,法医警察也可以利用该系统破案或防止袭击。
本文的目标是总结利用深度学习方法将二维图像到三维点云进行配准的方法。
整个文章系列将介绍LCD、2D-3D MatchNet、三元损失函数、VGG-Net、图神经网络等内容。

1 引言
1.1 问题定义
近年来,增强现实应用不断涌现。这类应用需要将三维模型与二维图像进行匹配。同样,大规模位置识别系统可能需要定位拍摄 2D 图像的准确位置。为此,必须对二维和三维数据进行注册或对齐。如果不能确保被对齐的二维和三维数据是同一现实的相同表现形式,即它们之间存在匹配关系,则无法执行此类操作。因此,在通过 2D-3D 注册对齐匹配对之前,有必要完成 2D-3D 匹配任务。
寻找在图像patch和点云patch上执行2D-3D匹配的稳健描述符的问题可以表述如下:
设
I
∈
R
W
×
H
×
3
I \in \mathbb{R}^{W \times H \times 3}
I∈RW×H×3为大小为
W
×
H
W \times H
W×H 的彩色图像patch,在RGB空间中表示。
设
P
∈
R
N
×
6
P \in \mathbb{R}^{N \times 6}
P∈RN×6 为包含N个点的彩色点云patch,其中每个点包括其位置数据
(
x
,
y
,
z
)
∈
R
3
(x, y, z) \in \mathbb{R}^3
(x,y,z)∈R3 和RGB信息。
需要注意的是,虽然图像数据是有结构的,其中的像素必须保持有序,但点云体积是无序坐标的集合。对于N个点的点云,数据集中有
N
!
N!
N!种可能的排列方式。然而,由于点云的结构保持不变,因此其顺序是无关紧要的。

一个进行2D-3D匹配的模型希望找到两个映射
f
:
R
W
×
H
×
3
→
D
f: \mathbb{R}^{W \times H \times 3} \to D
f:RW×H×3→D 和
g
:
R
N
×
6
→
D
g: \mathbb{R}^{N \times 6} \to D
g:RN×6→D 以便图像和点云数据都可以通过共享空间
D
⊆
R
D
D \subseteq \mathbb{R}^D
D⊆RD中的向量
embeddings
\text{embeddings}
embeddings来表示,其中
D
D
D是跨领域空间的维数。函数
f
f
f 和
g
g
g 可以通过神经网络建模。
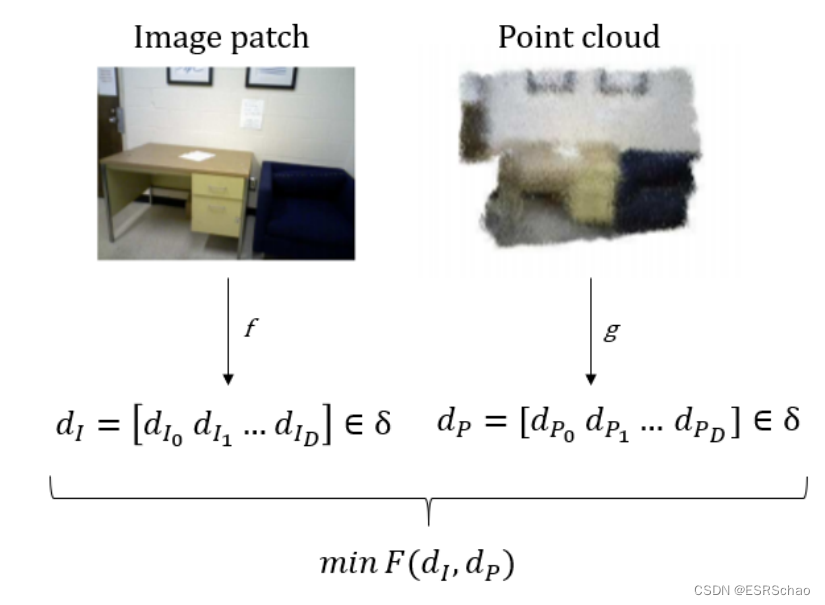
对于描述图像和点云
I
,
P
I, P
I,P 组成的一对的每对特征匹配对
(
d
I
,
d
P
)
∈
D
(d_I, d_P) \in D
(dI,dP)∈D,其目标是通过距离函数
F
F
F最小化它们之间的距离,使得
F
(
d
I
,
d
P
)
F(d_I, d_P)
F(dI,dP) 达到最小。
针对这一问题本文将着重介绍两种方法——LCD和2D-3D MatchNet。
1.2 LCD: Learned Cross-Domain Descriptors
[1] Quang-Hieu Pham, Mikaela Angelina Uy, Binh-Son Hua, Duc Thanh Nguyen, Gemma
Roig, and Sai-Kit Yeung. LCD: Learned cross-domain descriptors for 2D-3D matching.
In AAAI Conference on Artificial Intelligence, 2020.
在LCD的工作中,提出了一种基于深度学习的学习2D-3D本地跨领域描述符的方法。该方法基于两个联合训练的自编码器。此外,公开了一个2D-3D对应关系的数据集。
1.2.1 网络架构
LCD采用基于双分支自编码器的架构,通过三个损失进行训练。其中两个损失分别用于训练每个分支。一个分支被训练为将输入图像patch编码成向量embeddings,而另一个自编码器对输入点云patch执行相同的操作。最终,采用三元损失以最小化两个分支之间的差异,使得生成的embeddings在2D和3D数据之间共享相似性。
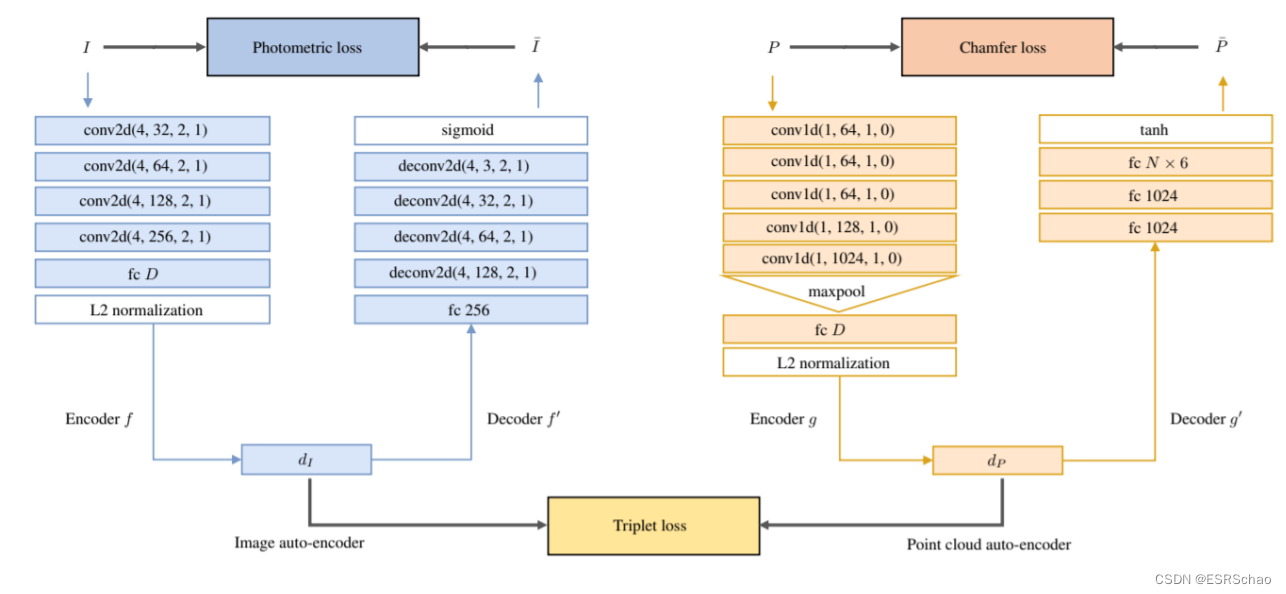
2D分支
2D分支能够将输入图像数据编码成具有固定大小的embeddings,该过程在编码器中完成。它接受大小为64 × 64的图像patch作为输入,通过一系列的2D卷积操作并使用ReLU激活进行前向传播。在最后,一个全连接层将计算得到的特征映射转换为大小为D的单维向量,然后进行L2归一化。为了解码生成的embeddings并获取原始图像,向量被输入到一个解码器架构中,通过一系列的反卷积操作并使用ReLU进行数据传播。
点云自编码器
点云自编码器具有类似的行为。点云描述符是通过PointNet架构创建的,该架构将输入的3D数据转化为大小为D的1D向量。原始点云可以通过解码器中的全连接层进行恢复。
1.2.2 损失函数
对图像自编码器的训练通过光度损失(Photometric loss)来实现,该损失计算输入图像与解码器输出的重构图像之间的均方误差。在下面给出的公式中, i i i表示输入图像的每个像素。
L m s e = 1 W × H ∑ i = 1 W × H ∣ ∣ I i − I ˉ i ∣ ∣ 2 L_{mse} = \frac{1}{W \times H} \sum_{i=1}^{W \times H} ||I_i - \bar{I}_i||^2 Lmse=W×H1i=1∑W×H∣∣Ii−Iˉi∣∣2
点云自编码器通过Chamfer损失进行训练,该损失基于Chamfer距离:
L c h a m f e r = max ( 1 ∣ P ∣ ∑ p ∈ P min q ∈ P ˉ ∥ p − q ∥ 2 , 1 ∣ P ˉ ∣ ∑ p ∈ P ˉ min q ∈ P ∥ p − q ∥ 2 ) L_{chamfer} = \max \left( \frac{1}{|P|} \sum_{p \in P} \min_{q \in \bar{P}} \|p - q\|^2, \frac{1}{|\bar{P}|} \sum_{p \in \bar{P}} \min_{q \in P} \|p - q\|^2 \right) Lchamfer=max ∣P∣1p∈P∑q∈Pˉmin∥p−q∥2,∣Pˉ∣1p∈Pˉ∑q∈Pmin∥p−q∥2
光度损失和Chamfer损失分别用于训练自编码器以生成用于表示图像patch点云的向量embeddings。然而,为了确保这些embeddings之间存在相似性,以便在测试应用中正确识别图像和点云embeddings的正匹配,需要共享相似性。为了强制执行这种相似性,两个自编码器在同一时间联合训练,使用Triplet loss:
L t r i p l e t = max ( F ( d a , d p ) − F ( d a , d n ) + m , 0 ) L_{triplet} = \max \left( F(d_a, d_p) - F(d_a, d_n) + m, 0 \right) Ltriplet=max(F(da,dp)−F(da,dn)+m,0)
其中,m是一个边距参数,F是距离函数(定义为欧氏距离)。在训练时,损失的组合计算如下:
L = α ⋅ L m s e + β ⋅ L c h a m f e r + γ ⋅ L t r i p l e t L = \alpha \cdot L_{mse} + \beta \cdot L_{chamfer} + \gamma \cdot L_{triplet} L=α⋅Lmse+β⋅Lchamfer+γ⋅Ltriplet
这意味着在训练阶段的每个批次计算中,使用权重 α = β = γ = 1 \alpha = \beta = \gamma = 1 α=β=γ=1 计算方程式 L L L。
2. Triplet loss
2D-3D配准中的Triplet Loss
大多数最先进的2D-3D配准深度学习技术在其不同变体中使用了Triplet Loss,因此,探索这种损失机制的工作原理以及它在当前任务中的用处可能是有趣的。
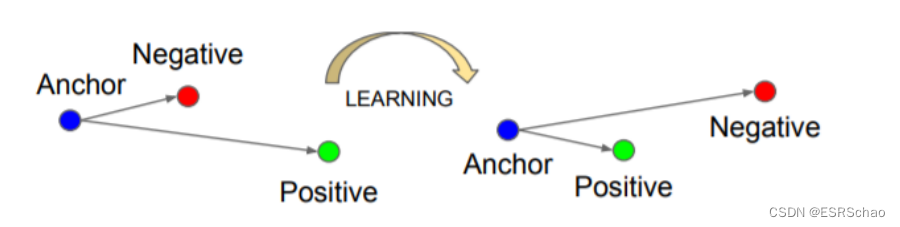
Triplet Loss首次在面部识别任务中被引入,它被用作通过孪生网络生成面部描述符的新方法。在监督学习中,通常存在固定数量的类别。然而,有时问题需要网络能够处理可变数量的类别。例如,在2D-3D配准任务中,每个图像点云匹配对都会成为一个唯一的类别。
在这项工作的背景下,想法是创建由图像锚点
x
a
I
x_a^I
xaI、其匹配点云(正点云)
x
M
+
x^+_M
xM+ 和数据库中的非匹配点云
x
M
−
x^-_M
xM− 组成的三元组。这些三元组以给定大小的批次输入到网络中,该网络为每个三元组的三个元素生成向量
embeddings
\text{embeddings}
embeddings。然后,为每个三元组创建的描述符被评估在Triplet Loss函数中。该函数确保匹配的图像-
point cloud
\text{point cloud}
point cloud对的
embeddings
\text{embeddings}
embeddings在
embeddings
\text{embeddings}
embeddings空间中彼此接近并与其他聚类分离。因此,给定一个三元组元组的Triplet Loss函数返回的值会在锚点图像和正点云互相远离而负点云靠近时很高。相反,如果图像锚点和正点云的描述符彼此接近且与负点云的
embeddings
\text{embeddings}
embeddings远离,则该值会很低。
数学上,
embeddings
\text{embeddings}
embeddings由
f
(
x
)
∈
R
n
f(x) \in \mathbb{R}^n
f(x)∈Rn 表示,其中函数
f
f
f 生成一个n维的单位范数描述符(
∥
f
(
x
)
∥
2
=
1
\lVert f(x) \rVert_2 = 1
∥f(x)∥2=1),从输入结构(可以是图像patch或点云)
x
x
x 中生成。Triplet Loss 强制这些
embeddings
\text{embeddings}
embeddings之间的距离满足
d
pos
<
d
neg
→
d
(
f
(
x
a
I
)
,
f
(
x
M
+
)
)
≪
d
(
f
(
x
a
I
)
,
f
(
x
M
−
)
)
d_{\text{pos}} < d_{\text{neg}} \rightarrow d(f(x_a^I), f(x^+_M)) \ll d(f(x_a^I), f(x^-_M))
dpos<dneg→d(f(xaI),f(xM+))≪d(f(xaI),f(xM−))。如果在正负对之间强制使用边距
α
\alpha
α 并且使用欧氏距离进行距离计算,则条件变为:
∥
f
(
x
a
I
)
−
f
(
x
M
+
)
∥
2
2
+
α
<
∥
f
(
x
a
I
)
−
f
(
x
M
−
)
∥
2
2
\lVert f(x_a^I) - f(x^+_M) \rVert_2^2 + \alpha < \lVert f(x_a^I) - f(x^-_M) \rVert_2^2
∥f(xaI)−f(xM+)∥22+α<∥f(xaI)−f(xM−)∥22
∀
(
f
(
x
a
I
)
,
f
(
x
M
+
)
,
f
(
x
M
−
)
)
∈
T
\forall (f(x_a^I), f(x^+_M), f(x^-_M)) \in \mathbb T
∀(f(xaI),f(xM+),f(xM−))∈T
其中
T
\mathbb T
T 是数据集中所有可能的三元组组合的集合,数据集的大小为
N
N
N。
要最小化的损失函数是:
L
=
∑
i
N
[
∥
f
(
x
a
I
)
−
f
(
x
M
+
)
∥
2
2
−
∥
f
(
x
a
I
)
−
f
(
x
M
−
)
∥
2
2
+
α
]
+
L = \sum_{i}^N \left[ \lVert f(x_a^I) - f(x^+_M) \rVert_2^2 - \lVert f(x_a^I) - f(x^-_M) \rVert_2^2 + \alpha \right]_+
L=i∑N[∥f(xaI)−f(xM+)∥22−∥f(xaI)−f(xM−)∥22+α]+
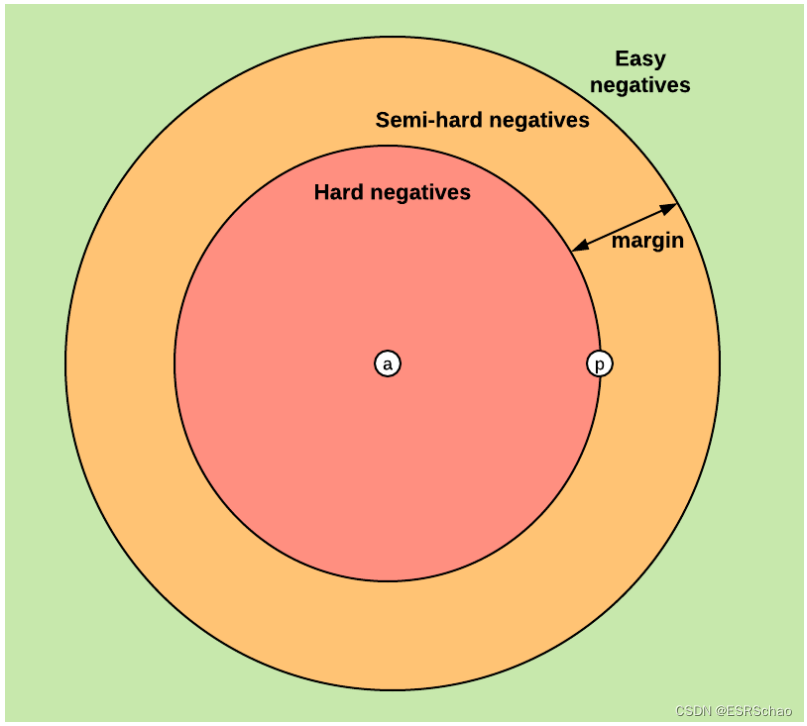
基于损失的定义,在训练期间可以构建三种不同的三元组类别:
• 简单三元组Easy triplets:损失值为0的三元组。
• 困难三元组Hard triplets:负点云
embeddings
\text{embeddings}
embeddings在
embeddings
\text{embeddings}
embeddings空间中比正点云描述符更接近图像锚点的三元组。
• 半困难三元组Semi-hard triplets:负点云
embeddings
\text{embeddings}
embeddings在
embeddings
\text{embeddings}
embeddings空间中不比正点云描述符更接近图像锚点,但仍有正的损失值。
根据负点云描述符相对于锚点和正描述符的位置,上述类别可以扩展到负例:困难负例、半困难负例和简单负例。注意,改变边距α的值将影响负例的分类。较高的值将为半困难负例提供更多空间,而较低的值将使困难负例和简单负例之间的边界变得很薄,减少半困难负例的数量。
然后,根据定义,
embeddings
\text{embeddings}
embeddings空间可以分为三个子区域,每个三元组对应一个区域:
如前所述,如果生成并将
T
\mathbb T
T中的所有可能的三元组馈送到网络进行训练,由于许多简单三元组的损失为0,训练期间的收敛速度将很慢。损失越高,在反向传播期间对网络权重的修正就越大。因此,应该避免简单三元组以获得最佳的训练过程。
有两种建立三元组(三元组挖掘)的策略:
- Offline triplet mining:所有三元组都在离线环境中构建,例如在每个时期的开始。计算整个数据集的 embeddings \text{embeddings} embeddings,然后创建所有可能的三元组组合。然后,进行评估以选择半困难和困难三元组,这些将是用于训练的三元组。这种方法不太高效。
- Offline triplet mining:三元组是在训练期间即时构建的,由每个批次的数据组成。为大小为B的图像-点云对批次生成
embeddings
\text{embeddings}
embeddings。计算批次中图像描述符和点云描述符的所有可能组合之间的距离,得到大小为B×B的距离矩阵。每个图像中的正点云,即批次中的匹配点云,已知,因为它与图像一起被转发。然而,仍然需要获取负点云描述符以完成三元组。有两种方法可以实现:
- 随机选择:从批次中随机选择一个与正点云不同的随机点云描述符。
- 困难选择:选择与锚点图像描述符相对距离较大的点云描述符以完成三元组。

















 8612
8612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









