






目录
一、神经网络的表示

输入特征
?
1
、
?
2
、
?
3
,它们被竖直地堆叠起来,这叫做神经网络的
输入层
。它包 含了神经网络的输入;然后这里有另外一层我们称之为隐藏层,最后一层只由一个结点构成,而这个只 有一个结点的层被称为
输出层,它负责产生预测值。
隐藏层:在一个神经网络中,当你使用监督学习训练它的时候,训练集包含了输入?也包含了目标输出?,所以术语隐藏层的含义是在训练集中,这些中间结点的准确值我们是不知道到的,也就是说你看不见它们在训练集中应具有的值。
注意一下下图中的几个表示符号:

双层神经网络结构如下:

二、神经网络的计算与输出
神经网络的计算的计算这里主要用逻辑回归。逻辑回归的计算有两个步骤,首先你按步骤计算出z
,然后在第二 步中你以 sigmoid
函数为激活函数计算z
(得出a),一个神经网络只是这样子做了好多次重复计算。注意这里用到的是sigmoid
函数,后面会提到用其他的激活函数。

注意使用向量化计算

三、激活函数
前面用到的都是 sigmoid 激活函数,但有时其他的激活函数效果会更好。
更通常的情况下,使用不同的函数g(![z^{[1]}](https://latex.csdn.net/eq?z%5E%7B%5B1%5D%7D) )
,g可以是除了
)
,g可以是除了
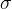 函数意外的非线性函 数。tanh 函数或者双曲正切函数是总体上都优于
函数的激活函数。所以基本不使用
函数了,只不过在二分类问题中,输出层y的值是0或1,所以想要
函数意外的非线性函 数。tanh 函数或者双曲正切函数是总体上都优于
函数的激活函数。所以基本不使用
函数了,只不过在二分类问题中,输出层y的值是0或1,所以想要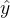 的值解与0和1之间,所以需要用到
激活函数。
的值解与0和1之间,所以需要用到
激活函数。
a = tanh(z)的值域是位于+1和-1 之间,
其均值是更接近0而不是0.5,效果更好。
a=tanh(z)=

sigmoid
函数和
tanh
函数两者共同的缺点是,在z特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于 0
,导致降低梯度下降的速度。
四、修正线性单元的函数(ReLu)
图示是上图左下角那个,公式:a=max(0,z),要z是正值的情况下,导数恒等于 1,当z是负值的时候,导数恒等于 0。
选择激活函数的经验法则:如果输出是 0、1 值(二分类问题),则输出层选择函数,然后其它的所有单元都选择 Relu 函数。如果在隐藏层上不确定使用哪个激活函数,那么通常会 使用 Relu 激活函数。有时,也会使用 tanh 激活函数,但 Relu 的一个优点是:当z是负值的 时候,导数等于 0。但是,如果不确定哪一个激活函数效果更好,可以把它们都试试,然 后在验证集或者发展集上进行评价。然后看哪一种表现的更好,就去使用它。
另一个版本的
Relu
被称为 Leaky Relu(公式:a=max(0.01z,z),这里的常数0.01可以选择不同的参数值):当z
是负值时,这个函数的值不是等于
0,而是轻微的倾
斜,在实际中 Leaky ReLu 使用的并不多,但效果通常好于Relu激活函数。
几种激活函数的对比:Relu和Leaky Relu在z区间变动很大时斜率都会远大于 0,在实践中,使用 ReLu 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。sigmoid 和tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 Relu 和 Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。(同时应该注意到的是,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性, 而 Leaky ReLu 不会有这问题)。z在 ReLu 的梯度一半都是 0,但是,有足够的隐藏层使得 z 值大于 0,所以对大多数的训练数据来说学习过程仍然可以很快。
五、不选用线性函数
明如果你在隐 藏层用线性激活函数,在输出层用 sigmoid
函数,那么这个模型的复杂度和没有任何隐藏层的标准 Logistic 回归是一样的,或仅仅只是输 入特征x的线性组合。
不能在隐藏层用线性激活函数,可以用
ReLU
或者
tanh
或者
leaky ReLU 或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层;除了这种情况,会在隐层用线性函数的,除了一些特殊情况,比如与压缩有关的,那方面在这里将不深入讨论。在这之外,在隐层使用线性激活函数非常少见。
六、激活函数的导数
igmoid activation function


Tanh activation function



Rectified Linear Unit (ReLU)


Leaky linear unit (Leaky ReLU)
















 6723
6723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









