










贝叶斯滤波,状态估计,频率学派,一系列统称,
粒子滤波是贝叶斯滤波的特例(实现方式)、粒子耗散问题(不能解决)、FastSLAM
一、贝叶斯滤波
1.数学概念
2.特性
- 估计的是概率分布,不是具体数值;
极大似然估计、极大后验估计
- 是一大类方法的统称;
- 是一个抽象的表达形式——对于不同问题有不同的实现方式(卡尔曼家族、粒子滤波);
- 迭代估计形式
3.贝叶斯估计
b e l ( x t ) = p ( x t ∣ z 1 : t , u 1 : t ) = η p ( z t ∣ x t ) b e l ‾ ( x t ) = η p ( z t ∣ x t ) ∫ p ( x t ∣ x t − 1 , u t ) p ( x t − 1 ∣ z 1 : t − 1 , u 1 : t − 1 ) d x t − 1 (1-1) bel(x_t)=p(x_t|z_{1:t},u_{1:t})=\eta p(z_t|x_t)\overline{bel}(x_t)=\eta p(z_t|x_t)\begin{aligned} \int p(x_t|x_{t-1},u_t)p(x_{t-1}|z_{1:t-1,}u_{1:t-1}) \mathrm{d} x_{t-1} \end{aligned}\tag{1-1} bel(xt)=p(xt∣z1:t,u1:t)=ηp(zt∣xt)bel(xt)=ηp(zt∣xt)∫p(xt∣xt−1,ut)p(xt−1∣z1:t−1,u1:t−1)dxt−1(1-1)
- b e l ( x t ) bel(x_t) bel(xt)是后验概率——观测更新
- b e l ‾ ( x t ) \overline{bel}(x_t) bel(xt)是预测分布——运动预测
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VeK4rrJl-1658240908390)(C:\Users\13611\AppData\Roaming\Typora\typora-user-images\image-20220719162830611.png)]](https://img-blog.csdnimg.cn/7fc611852e504a3da6a12a8ea967c0b3.png#pic_center)
功能:已知状态量t-1时刻的概率分布,在给定t时刻的观测数据 ( z t , u t ) (z_t,u_t) (zt,ut)的情况下估计出状态量在t时刻的概率分布
4.推导
- 目标:在已知 p ( x t − 1 ∣ z 1 : t − 1 , u 1 : t − 1 ) 、 u t 、 z t p(x_{t-1}|z_{1:t-1,}u_{1:t-1})、u_t、z_t p(xt−1∣z1:t−1,u1:t−1)、ut、zt的情况下,得到 p ( x t ∣ z 1 : t , u 1 : t ) p(x_t|z_{1:t},u_{1:t}) p(xt∣z1:t,u1:t)的表达式。
p ( x t ∣ z 1 : t , u 1 : t ) = p ( z t ∣ x t , z 1 : t − 1 , u 1 : t ) p ( x t ∣ z 1 : t − 1 , u 1 : t ) p ( z t ∣ z 1 : t − 1 , u 1 : t ) = η p ( z t ∣ x t , z 1 : t − 1 , u 1 : t ) p ( x t ∣ z 1 : t − 1 , u 1 : t ) p(x_t|z_{1:t},u_{1:t})=\frac{p(z_t|x_t,z_{1:t-1},u_{1:t})p(x_t|z_{1:t-1},u_{1:t})}{p(z_t|z_{1:t-1,u_{1:t}})}\\ \\=\eta p(z_t|x_t,z_{1:t-1},u_{1:t})p(x_t|z_{1:t-1},u_{1:t}) p(xt∣z1:t,u1:t)=p(zt∣z1:t−1,u1:t)p(zt∣xt,z1:t−1,u1:t)p(xt∣z1:t−1,u1:t)=ηp(zt∣xt,z1:t−1,u1:t)p(xt∣z1:t−1,u1:t)
其中:
p ( z t ∣ x t , z 1 : t − 1 , u 1 : t ) = p ( z t ∣ x t ) p(z_t|x_t,z_{1:t-1},u_{1:t})=p(z_t|x_t) p(zt∣xt,z1:t−1,u1:t)=p(zt∣xt)
p ( x t ∣ z 1 : t − 1 , u 1 : t ) = ∫ p ( x t ∣ x t − 1 , z 1 : t − 1 , u 1 : t ) p ( x t − 1 ∣ z 1 : t − 1 , u 1 : t ) d x t − 1 p(x_t|z_{1:t-1},u_{1:t})= \begin{aligned} \int p(x_t|x_{t-1},z_{1:t-1},u_{1:t})p(x_{t-1}|z_{1:t-1},u_{1:t})\mathrm{d} x_{t-1} \end{aligned} p(xt∣z1:t−1,u1:t)=∫p(xt∣xt−1,z1:t−1,u1:t)p(xt−1∣z1:t−1,u1:t)dxt−1
p ( x t ∣ x t − 1 , z 1 : t − 1 , u 1 : t ) = p ( x t ∣ x t − 1 , u t ) p(x_t|x_{t-1},z_{1:t-1},u_{1:t})=p(x_t|x_{t-1},u_t) p(xt∣xt−1,z1:t−1,u1:t)=p(xt∣xt−1,ut)
p ( x t − 1 ∣ z 1 : t − 1 , u 1 : t ) = p ( x t − 1 ∣ z 1 : t − 1 , u 1 : t − 1 ) p(x_{t-1}|z_{1:t-1},u_{1:t})=p(x_{t-1}|z_{1:t-1,}u_{1:t-1}) p(xt−1∣z1:t−1,u1:t)=p(xt−1∣z1:t−1,u1:t−1)
令:
b e l ( x t ) = p ( x t ∣ z 1 : t , u 1 : t ) bel(x_t)=p(x_{t}|z_{1:t},u_{1:t}) bel(xt)=p(xt∣z1:t,u1:t)表示 x t x_t xt的后验概率分布
b e l ‾ ( x t ) = p ( x t ∣ z 1 : t , u 1 : t ) \overline{bel}(x_t)=p(x_{t}|z_{1:t},u_{1:t}) bel(xt)=p(xt∣z1:t,u1:t)表示 x t x_t xt的预测(proposal)概率分布
则:
b e l ( x t ) = η p ( z t ∣ x t ) b e l ‾ ( x t ) bel(x_t)=\eta p(z_t|x_t)\overline{bel}(x_t) bel(xt)=ηp(zt∣xt)bel(xt)
b e l ‾ ( x t ) = ∫ p ( x t ∣ x t − 1 , u t ) p ( x t − 1 ∣ z 1 : t − 1 , u 1 : t − 1 ) d x t − 1 \overline{bel}(x_t)= \begin{aligned} \int p(x_t|x_{t-1},u_t)p(x_{t-1}|z_{1:t-1,}u_{1:t-1}) \mathrm{d} x_{t-1} \end{aligned} bel(xt)=∫p(xt∣xt−1,ut)p(xt−1∣z1:t−1,u1:t−1)dxt−1
2.粒子滤波
粒子滤波用一系列通过后验概率分布随机采样的状态粒子近似表示后验概率分布,采样得到的状态粒子点的疏密程度与该区域后验概率分布大小成正比,也就是说状态粒子点的枢密程度简介反映了后验概率分布的大小。这样粒子就可以直接参与系统的非线性变换,并利用运动和观测进行重新采样以调整状态粒子点的疏密程度。
粒子算法是一种基于遗传进化的算法,粒子经过运动和观测过程的筛选后,粒子点将逐渐集中到后验概率高的区域。
1.特性
- 贝叶斯估计器的一种实现方式
- 能处理非线性情况
- 能处理多峰分布的情况——全局定位
- 用系列粒子近似概率分布
- 非参滤波器
2.推导
$ X={ {(x_ti,w_ti)|i=1,2,…,n} } $
x t i x_t^i xti表示一个状态的假设——机器人位姿
w t i w_t^i wti表示假设的权重——跟地图的匹配度
流程
-
用粒子进行状态传播: x t i x_{t}^i xti~ p ( x t ∣ u t , x t − 1 i ) p(x_t|u_t,x_{t-1}^i) p(xt∣ut,xt−1i)
-
评估每个粒子的权重: w t i = η p ( z t ∣ x t ) w_{t}^i=\eta p(z_t|x_t) wti=ηp(zt∣xt)
-
根据权重进行重采样:以 w t i w_{t}^i wti的概率接受 x t i x_{t}^i xti,权重清零
①状态传播
传播模型:
b
e
l
‾
(
x
t
)
=
∫
p
(
x
t
∣
x
t
−
1
,
u
t
)
p
(
x
t
−
1
∣
z
1
:
t
−
1
,
u
1
:
t
−
1
)
d
x
t
−
1
\overline{bel}(x_t)= \begin{aligned} \int p(x_t|x_{t-1},u_t)p(x_{t-1}|z_{1:t-1,}u_{1:t-1}) \mathrm{d} x_{t-1} \end{aligned}
bel(xt)=∫p(xt∣xt−1,ut)p(xt−1∣z1:t−1,u1:t−1)dxt−1
已知t-1时刻的概率分布(粒子分布):
p
(
x
t
−
1
∣
z
1
:
t
−
1
,
u
1
:
t
−
1
)
=
(
x
t
−
1
i
,
w
t
−
1
i
)
∣
i
=
1
,
2
,
.
.
.
,
n
p(x_{t-1}|z_{1:t-1,}u_{1:t-1}) ={{(x_{t-1}^i,w_{t-1}^i)|i=1,2,...,n}}
p(xt−1∣z1:t−1,u1:t−1)=(xt−1i,wt−1i)∣i=1,2,...,n
根据数据
u
t
u_t
ut预测t-1时刻的概率分布(粒子分布):
x
t
i
∽
p
(
x
t
∣
u
t
,
x
t
−
1
i
)
i
=
1
,
2
,
.
.
.
.
,
n
x_{t}^i \backsim p(x_t|u_t,x_{t-1}^i)\\ i=1,2,....,n
xti∽p(xt∣ut,xt−1i)i=1,2,....,n

②权重评估
- 无法知道机器人位姿的实际分布
- 从机器人的预测分布进行采样,联合权重一起近似机器人的后验概率分布
- 权重用来评估实际的预测分布和实际分布的差,差越大,权重越小
- 权重的定义
w = b e l ( x t ) b e l ‾ ( x t ) w=\frac{bel(x_t)}{\overline{bel}(x_t)} w=bel(xt)bel(xt)
对于某个粒子:
b
e
l
(
x
t
)
=
η
p
(
z
t
∣
x
t
)
p
(
x
t
∣
x
t
−
1
,
u
t
)
b
e
l
(
x
t
)
b
e
l
‾
(
x
t
)
=
p
(
x
t
∣
x
t
−
1
,
u
t
)
b
e
l
(
x
t
)
bel(x_t)=\eta p(z_t|x_t)p(x_t|x_{t-1},u_t)bel(x_t) \\ \overline{bel}(x_t)= p(x_t|x_{t-1},u_t)bel(x_t)
bel(xt)=ηp(zt∣xt)p(xt∣xt−1,ut)bel(xt)bel(xt)=p(xt∣xt−1,ut)bel(xt)
因此权重为:
w
=
η
p
(
z
t
∣
x
t
)
p
(
x
t
∣
x
t
−
1
,
u
t
)
b
e
l
(
x
t
)
p
(
x
t
∣
x
t
−
1
,
u
t
)
b
e
l
(
x
t
)
=
η
p
(
z
t
∣
x
t
)
w=\frac{\eta p(z_t|x_t)p(x_t|x_{t-1},u_t)bel(x_t)}{p(x_t|x_{t-1},u_t)bel(x_t)}\\ \\ =\eta p(z_t|x_t)
w=p(xt∣xt−1,ut)bel(xt)ηp(zt∣xt)p(xt∣xt−1,ut)bel(xt)=ηp(zt∣xt)
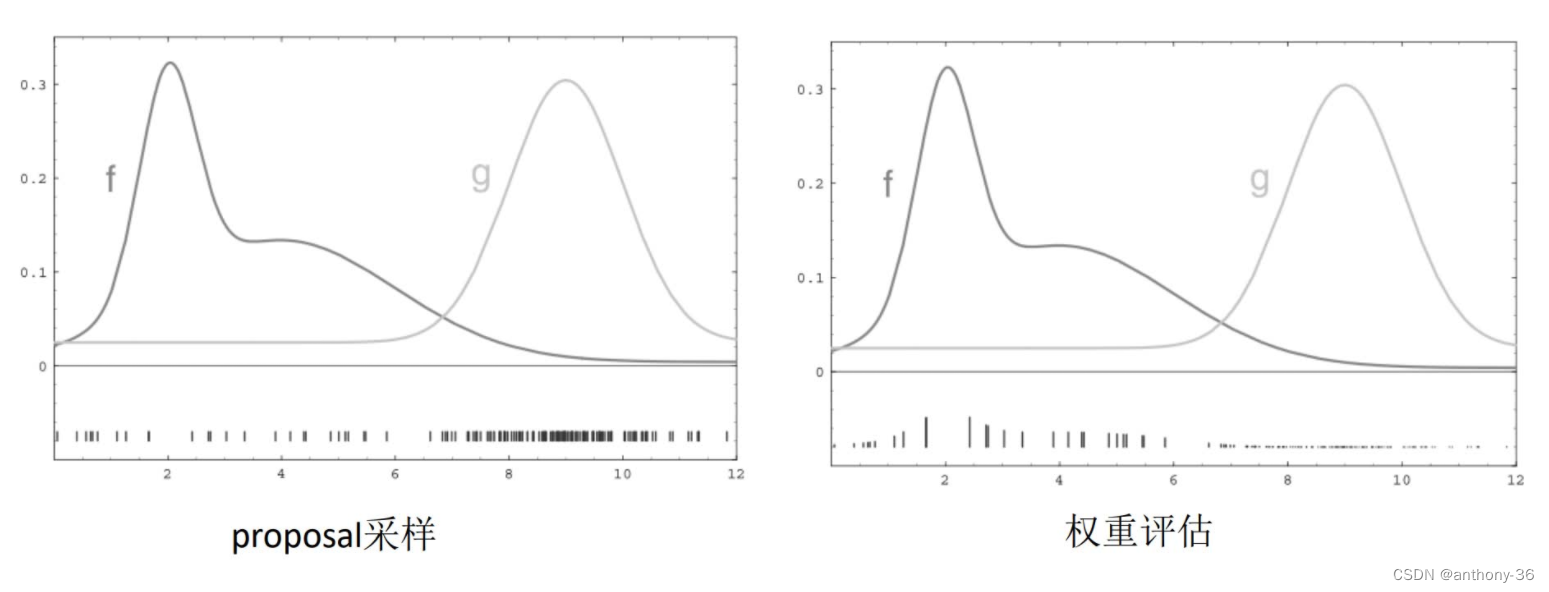
③重采样
- 到目前为止,新的粒子群是根据proposal分布进行采样的,并且用观测模型计算权重,而最终的目的是用粒子群来近似后验概率分布
- 对粒子群进行重采样,对于某一个粒子 x i x_i xi来说,以 w i w_i wi的概率接受这个粒子
- 生成一个随机数,根据其落在的区间决定接受的粒子,重复N次。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UVZCqYsu-1658240908391)(C:/Users/13611/AppData/Roaming/Typora/typora-user-images/image-20220719222650272.png)]](https://img-blog.csdnimg.cn/d1136f72bc634031b7cd329eabb994c8.png#pic_center)
3.算法流程

4.存在的问题
- 粒子耗散问题——粒子多样性的丧失
- 维数灾难
- 当proposal比较差的时候,需要用很多的粒子才能较好的表示机器人的后验概率分布。
















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











