






随着人工智能应用在我们的日常生活中变得越来越普遍,目前存在的挑战是如何在不同的生产环境中部署最新的人工智能模型。模型和部署环境的组合爆炸给训练和推理部署带来了巨大的挑战。此外,目前落地的模型也提出了更多的要求,例如减少软件依赖、全面的模型覆盖、利用新硬件进行加速、减少内存占用,以及更强的可扩展性。 —《机器学习编译》陈天奇
文章目录
深度学习推理部署框架 TensorRT
1. 概述
TensorRT是Nvidia为了加速基于自家GPU的模型推理而设计的。可以将我们训练好的模型分解再进行融合,融合后的模型具有高度的集合度。 [NVIDIA Deep Learning TensorRT Documentation]
2. 优化方式
- 算子融合(层与张量融合):简单来说就是通过融合一些op或者去掉一些多余op来优化GPU显存和带宽的使用
- 量化:量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,可以显著提升模型推理速度并保持高的精度
- 内核自动调整:根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
- 动态张量显存:显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,更大限度减少显存占用,并高效地为张量重复利用内存
- 多流执行:使用CUDA中的stream技术,最大化实现并行操作
在实际应用中,他人简单总结的TensorRT的加速效果:
-
SSD检测模型,加速3倍(Caffe)
-
CenterNet检测模型,加速3-5倍(Pytorch)
-
LSTM、Transformer(细op),加速0.5倍-1倍(TensorFlow)
-
resnet系列的分类模型,加速3倍左右(Keras)
-
GAN、分割模型系列比较大的模型,加速7-20倍左右(Pytorch)
(官网公布的性能基准网络:ResNet-50、SSD ResNet-34、3D-UNet、RNN-T、BERT、DLRM)
3. pytorch转tensorrt并完成推理
3.1 安装所需要的库
pip install onnx
pip install onnxscript
3.2 .pth模型转换到.onnx模型
from model import resnet18 # model中定义了resnet网络结构
model = resnet18(num_classes=1000)
model.load_state_dict(torch.load(self.weights, map_location='cpu'),strict=False)
model.eval()
onnx_path = "./model.onnx"
print("Converting pytorch model to {}".format(onnx_path))
x = torch.randn(1, 3, 224, 224) # 转onnx模型时给定随机输入
torch.onnx.export(
model, # 需要导出的模型
x, # 示例输入
onnx_path, # 输出文件名
export_params=True, # 导出训练好的参数
opset_version=12, # ONNX opset 版本
do_constant_folding=True, # 优化常量折叠
input_names=['input'], # 输入名称
output_names=['output'], # 输出名称
dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}} # 动态轴, 输入动态尺寸设置,此处为batch_size可变
)
print("Successfully converted to onnx model.")
3.3 检查.onnx模型
3.3.1 onnx.checker.check_model:帮助确保 ONNX 模型的结构和语义符合 ONNX 标准
model_onnx = onnx.load(onnx_path) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
3.3.2 onnxruntime:确保模型结果的正确性
import torch
import onnxruntime as ort
import numpy as np
onnx_file_path = './model.onnx'
model = yolov5()
model.eval()
#使用 PyTorch 进行推理
input_tensor = torch.randn(1, 3, 640, 640)
with torch.no_grad():
pytorch_output = model(input_tensor)
#使用 ONNX Runtime 进行推理
ort_session = ort.InferenceSession(onnx_file_path)
input_data = np.random.randn(1, 3, 640, 640).astype(np.float32)
onnx_inputs = {ort_session.get_inputs()[0].name: input_data}
onnx_output = ort_session.run(None, onnx_inputs)
#比较 PyTorch 和 ONNX Runtime 的输出
pytorch_output_np = pytorch_output.numpy()
try:
np.testing.assert_allclose(pytorch_output_np, onnx_output[0], rtol=1e-3, atol=1e-5)
print("Outputs are close!")
except AssertionError as e:
print("Outputs differ:", e)
3.3.3 可视化onnx模型(使用Netron工具)
https://netron.app/
Netron 是一个强大的工具,用于可视化和分析神经网络模型。它支持多种深度学习框架,包括 ONNX、TensorFlow、Keras、Caffe、PyTorch 和 MXNet 等。使用 Netron,可以查看模型的结构、参数和配置,帮助发现模型中的问题并改进模型的设计。
3.4 onnx到tensorrt
3.4.1 方法一:使用trtexec工具进行转换(推荐)
3.4.1.2 trtexec工具安装
需要源码安装,pip安装的没有该工具。orin的jetpack自带cuda,cudnn,tensorrt!!!不用自己装!!
-
把 JetPack 安装的TensorRT的路径添加到~/.bashrc里
-
dpkg -L libnvinfer8找到 tensorrt的动态链接库文件位置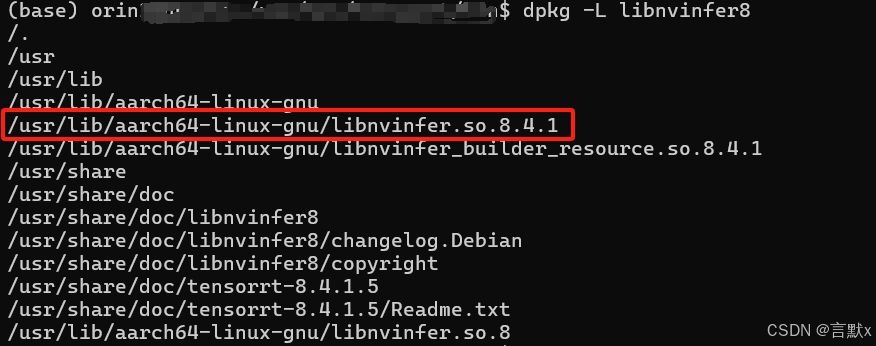
-
find /usr -name 'trtexec'找到trtexec工具包的位置

-
把上面找到的两个路径添加到~/.bashrc中
export LD_LIBRARY_PATH=/usr/lib/aarch64-linux-gnu:$LD_LIBRARY_PATH export PATH=$PATH:/usr/src/tensorrt/bin -
source ~/.bashrc使配置生效
自己装的流程:
选择合适版本
TensorRT Download | NVIDIA Developer 根据系统、CUDA版本、Ubuntu版本下载对应的tensorrt(tar文件)
安装
# 解压安装包
tar -xzvf TensorRT-8.2.5.1.Ubuntu-20.04.aarch64-gnu.cuda-11.4.cudnn8.2.tar.gz
vim ~/.bashrc
# 在~/.bashrc中添加以下内容
export LD_LIBRARY_PATH="/home/xxx/TensorRT-8.2.5.1/lib":$LD_LIBRARY_PATH
export PATH=$PATH:/home/xxx/TensorRT-8.2.5.1/bin
source ~/.bashrc
cd TensorRT-8.2.5.1/python
python3 -m pip install tensorrt-8.2.5.1-cp38-none-linux_aarch64.whl #cp3x选择对应的python版本
trtexec --help #验证安装是否成功
可参考官方网站 Installation Guide :: NVIDIA Deep Learning TensorRT Documentation
3.4.1.3 模型转换
trtexec --onnx=model.onnx --minShapes=image_input:1x3x224x224 --optShapes=image_input:1x3x224x224 --maxShapes=image_input:4x3x224x224 --saveEngine=model.trt --int8
参数解释可参考网站 Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
转换成功的打印信息:
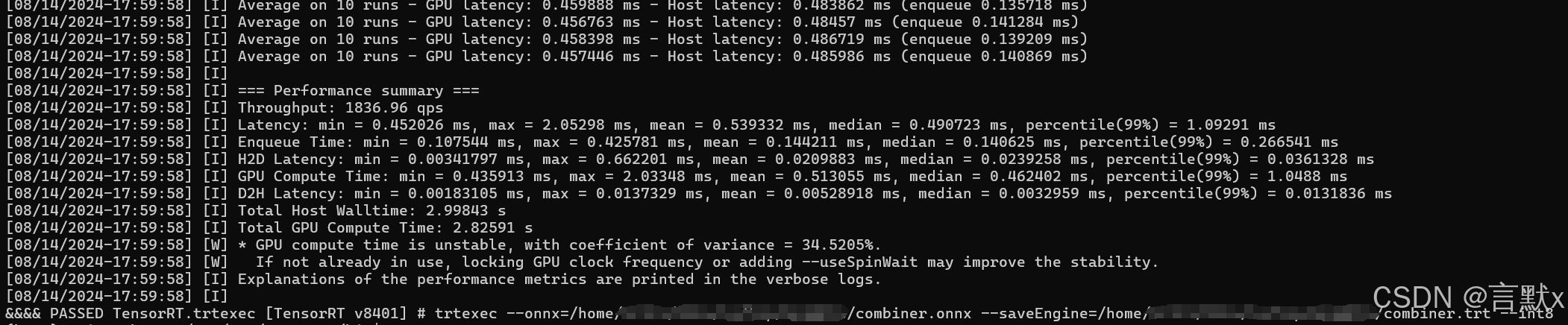
3.4.2 方法二:解析onnx模型序列化生成engine并保存
解析网络 ->考虑优化选项(批处理大小,工作空间大小,混合精度以及动态形状上的边界,这些选项是在TensorRT构建步骤中选择和指定的) -> 构建并序列化 TensorRT 引擎
下面代码是基于tensorrt8.x版本实现的
engine = None # 加这句避免返回删除的engine
#定义显式batch
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
# 1. 创建构建器、网络对象、onnx解析器
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network,trt.OnnxParser(network, TRT_LOGGER) as parser :
config = builder.create_builder_config()
# 2. 解析 ONNX 文件
print(f'Loading ONNX file from path {onnx_path}...')
assert os.path.exists(onnx_path), f'cannot find {onnx_path}'
with open(onnx_path, 'rb') as fr:
if not parser.parse(fr.read()):
print ('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print (parser.get_error(error))
assert False
# 3. 设置优化配置
assert opt_batch >= 1, "invalid optimum batch size:{}".format(opt_batch)
assert max_batch >= opt_batch, "invalid max batch size:{}".format(max_batch)
# builder.max_batch_size = max_batch
profile = builder.create_optimization_profile() # 创建一个优化配置文件
profile.set_shape("input", (1, c, h, w), # 设置输入张量的最小、优化和最大形状,"input" 是输入张量的名称
(opt_batch, c, h, w),
(max_batch, c, h, w))
config.add_optimization_profile(profile) # 将配置文件添加到构建配置中
# 4. 设置workspace
config.max_workspace_size = 1 << 34 # 16G
# 5. 设置精度模式
if self.data_type == 'int8':
config.set_flag(trt.BuilderFlag.INT8) # Network-Level Control of Precision
calibration_images = 'quat_img'
cache_file = "./calibration.cache"
config.int8_calibrator = Calibrator(1,1, h, w,calibration_images ,cache_file) # INT8 模式需要校准过程来确保精度,这里需要自己配置校准器
print("Quantizing to INT8")
elif self.data_type == 'fp16':
config.set_flag(trt.BuilderFlag.FP16)
print("Quantizing to FP16")
else:
print("TF32")
# 6. 构建和保存 TensorRT 引擎
print("Start to build Engine")
plan = builder.build_serialized_network(network, config) # 序列化网络
with open(trt_model_path, "wb") as fw: #保存成trt
fw.write(plan)
print("Saving trt model")
tensorRT支持用EXPLICIT_BATCH和IMPLICIT_BATCH两种方式来指定网络。EXPLICIT_BATCH下(NCHW),所有的维度都可以是动态的,好处是,可以在batch维度上进行操控,比如改变batch大小、进行batch Normalization等。IMPLICIT_BATCH(CHW)在早期的TensorRT版本中使用。
3.4.3 精度控制
“推理 (Inference) 通常比训练 (Training) 需要的数值精度低。训练过程中需要更高的精度来计算梯度和优化模型参数,而推理阶段则可以使用较低的精度以提高计算速度和减少内存占用,而不会显著影响模型的准确性。”
Tensorrt 支持的精度模式:TF32(默认启用的混合精度模式)、FP32、FP16、INT8
降低精度可分为网络级和层级精度控制。方法一 trtexec工具转换通过参数配置实现--fp16/--int8。方法二 在构建器配置中设置flag通知tensorrt可以选择低精度的实现,有TF32(默认)、FP16、INT8三种精度选择,其中TF32和FP16使用简单config.set_flag(trt.BuilderFlag.FP16),而INT8相对复杂。注意即使精度flag被使能,engine的input/output bindings仍默认为FP32。对于Orin上的DLA(深度学习加速器),用不同的舍入模式对量化机制进行了更新。
3.5 tensorrt模型推理
3.5.1 导入相关库
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
3.5.2 加载推理引擎
# 加载模型
trt_logger = trt.Logger(trt.Logger.WARNING)
with open(trt_path, "rb") as f, trt.Runtime(trt_logger) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
# 构建上下文管理器
context = engine.create_execution_context()
stream = cuda.Stream()
context.set_optimization_profile_async(0, stream.handle)
3.5.3 为每个输入/输出张量分配内存
(每个张量创建一个页锁定的内存缓冲区,并在设备上分配相应的内存)
3.5.3.1获取输入/输出shape
这里注意不同的tensort版本获取方式不一样,目前我使用过的是tensorrt-8.4.5和tensorrt-10.3
-
tensorrt-8.4.5
# Get binding indices input_binding_index = engine.get_binding_index('input') output_binding_indices = [engine.get_binding_index(name) for name in ['output', '4586']] # 名称可通过查看onnx图确定 # Get shapes i_shape = engine.get_binding_shape(input_binding_index) output_shapes = [engine.get_binding_shape(index) for index in output_binding_indices] # 动态尺寸需要添加(以batch维度为动态为例) input_shape = (batch_size,) + input_shape[1:] output_shapes = [(batch_size,) + shape[1:] for shape in output_shapes] -
tensorrt-10.3
ishape_tensor_mode = engine.get_tensor_mode("input") if ishape_tensor_mode == trt.TensorIOMode.INPUT: ishape = engine.get_tensor_shape("input") # 动态尺寸需要对动态维度设置 ishape[0] = 1 output_names = ['output', '4586'] # 名称可通过查看onnx图确定 output_shapes = [] for o_n in output_names: if ishape_tensor_mode == trt.TensorIOMode.OUTPUT: oshape = engine.get_tensor_shape(o_n) output_shapes.append(oshape)
3.5.3.2 设置输入形状和输入/输出张量的地址
#set input shapes,如果输入是动态维度每次都要set一下模型输入的shape
# 8.x版本
context.set_binding_shape(input_binding_indice, input_shape)
# 10.x版本
if context.set_input_shape("input", ishape):
print(f"Input shape set successfully to {ishape}")
else:
print(f"Failed to set input shape to {ishape}")
# 为输入输出申请内存并设置内存地址(设置内存地址是10.x版本加的)
h_input = cuda.pagelocked_empty(trt.volume(ishape), dtype=np.float32)
d_input = cuda.mem_alloc(h_input.nbytes)
h_outputs = [cuda.pagelocked_empty(trt.volume(oshape), dtype=np.float32) for oshape in output_shapes]
d_outputs = [cuda.mem_alloc(h_output.nbytes) for h_output in h_outputs]
# 下面的在tensorrt-10.x版本需要,在tensorrt-8.x版本不需要
context.set_tensor_address("input", int(d_input)) # input buffer
for index, d_output in zip(output_names, d_outputs): # 适应多输出
context.set_tensor_address(index, int(d_output)) #output buffer
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#working-with-int8)
如果不是多输出,则仿照单输入构造即可
3.5.4 推理
python推理接收numpy格式的数据输入
# 拷贝数据到输入
h_input[:image.size] = image.flatten()
# 将输入从主机(CPU)传输到设备(GPU)内存
cuda.memcpy_htod_async(d_input, h_input, stream)
# 流同步
stream.synchronize()
# 运行推理(8.x版本)
bindings = [int(d_input)] + [int(d_output) for d_output in d_outputs]
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
#10.x版本运行推理:context.execute_async_v3(stream_handle=stream.handle)
# 将输出从设备(GPU)内存传输到主机(CPU)内存
for h_output, d_output in zip(h_outputs, d_outputs):
cuda.memcpy_dtoh_async(h_output, d_output, stream)
# 流同步
stream.synchronize()
# 获取所需输出
output = torch.from_numpy(h_outputs[0].reshape(output_shapes[0]))
4. 可能遇到的问题
4.1 多输入
ir_features = torch.randn(1, 768, device=device)
rgb_features = torch.randn(1, 768, device=device)
torch.onnx.export(
combiner_img,
(ir_features, rgb_features),
"combiner_img.onnx",
export_params=True,
opset_version=12,
do_constant_folding=True,
input_names=['ir_features', 'rgb_features'],
output_names=['image_output'],
)
print("Successfully converted combiner_img to onnx model.")
4.2 多输出
若在转tensorrt引擎时未处理多输出,则在推理时需要为每个输出张量分配内存,要不会报下面类似的错误以及输出紊乱(2.1和2.2已为多输出申请内存)。
TRT] [E] IExecutionContext::enqueueV3: Error Code 3: API Usage Error (Parameter check failed, condition: mContext.profileObliviousBindings.at(profileObliviousIndex) || getPtrOrNull(mOutputAllocators, profileObliviousIndex). Neither address or allocator is set for output tensor onnx::Sigmoid_4586. Call setOutputTensorAddress, setTensorAddress or setOutputAllocator before enqueue/execute.)
4.3 pytorch网络推理用的是函数,而不是模型实例
将函数封装成模型
import torch
import torch.nn as nn
class ImgModelWrapper(nn.Module):
def __init__(self, model):
super(ImgModelWrapper, self).__init__()
self.model = model
def forward(self, pixel_values):
image_features = self.model.encode_image(pixel_values)
return image_features
class TxtModelWrapper(nn.Module):
def __init__(self, model):
super(TxtModelWrapper, self).__init__()
self.model = model
def forward(self, label_input):
text_features = self.model.encode_text(label_input)
return text_features
5 模型输出差异
[TensorRT/tools/Polygraphy at master · NVIDIA/TensorRT (github.com)] Polygraphy是一系列小工具合集,可以查看模型转换的精度折损
6 缺点
-
优化后的模型与特定GPU绑定
-
高版本的TensorRT依赖高版本的CUDA,而高版本的CUDA依赖高版本的驱动。TensorRT的版本与CUDA还有cudnn版本密切相关
-
推理优化闭源(但提供了较多工具帮助调试,比如ONNX GraphSurgeon、Polygraphy、PyTorch-Quantization)
工具 基本功能 ONNX GraphSurgeon 可以修改导出的ONNX模型,增加或者剪掉某些节点,修改名字或者维度等等 Polygraphy 各种小工具的集合,例如比较ONNX和trt模型的精度,观察trt模型每层的输出等等,主要用来debug一些模型的信息 PyTorch-Quantization 可以在Pytorch训练或者推理的时候加入模拟量化操作,从而提升量化模型的精度和速度,并且支持量化训练后的模型导出ONNX和TRT
7. DLA(Deep Learning Accelerator )
DLA是一款针对深度学习的固定功能加速器引擎,旨在对卷积神经网络进行全硬件加速,支持卷积、反卷积、激活、池化、批量归一化等各种层,不支持Explicit Quantization。
运行时的一般限制
- 支持的最大批量大小为4096。DLA的批量大小是除CHW维度以外的所有索引维度的乘积。例如如果输入维度为NPQRS,则有效批量大小为N*P
- 不支持动态尺寸,因此对于通配符维度,配置文件的min、max、opt值必须相等
参考文档:
12. TensorRT 和 DLA(Deep Learning Accelerator) - NVIDIA 技术博客
Deep Learning Accelerator (DLA) | NVIDIA Developer
其它针对深度学习模型优化、部署和推理的工具和框架
1. TVM
1.1 概述
TVM是由华盛顿大学在读博士陈天奇等人提出的深度学习自动代码生成方法,是开源的机器学习编译器框架,用于 CPU、GPU 和机器学习加速器,它的目标是让机器学习工程师在任何硬件后端优化和高效运行计算。在开源,多平台上是优势。
[TVM 和模型优化的概述 — TVM 文档 (daobook.github.io)]
1.2 步骤

- 从 tensorflow、PyTorch 或onnx 等框架导入模型(model)
- 翻译成Relay。Relay是TVM的高级模型语言,应用graph-level优化模型
- 张量表达。有预先定义的常见张量算子的模板
- 搜索最佳调度
- 选择最佳配置进行模型编译
- 低层次中间表示,到硬件平台的目标编译器中(最后的代码生成阶段)
- 编译成机器码
1.3 优化策略
图优化:算子融合、Layout Transform
张量优化:矩阵乘法、调度算法、搜索空间
2. NCNN
侧重于移动和嵌入式设备,优化 ARM 架构。是一个为手机端极致优化的高性能神经网络前向计算框架。
其它
[https://www.nvidia.com/en-us/on-demand/NVIDIA]有很多新的技术或者即将开源的技术(未来的半年内)绝大部分都会在这里展示出来

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









