







1.主要工作:
- 介绍了一个包含以RAD表示形式的雷达数据及其对应的各种对象类别注释的新颖数据集。
- 提出了一种自动标注方法,该方法在RAD数据的所有维度和笛卡尔形式上生成真实标签。
- 提出了一种新的雷达目标检测模型。我们的模型采用了基于ResNet 的主干网络。在对雷达数据进行系统探索后,得到了最终形式的主干网络。受YOLO头部的启发,我们提出了一种新的双重检测头部,分别在RAD数据和笛卡尔坐标数据上进行3D检测和2D检测。
2.自制数据集标注过程:
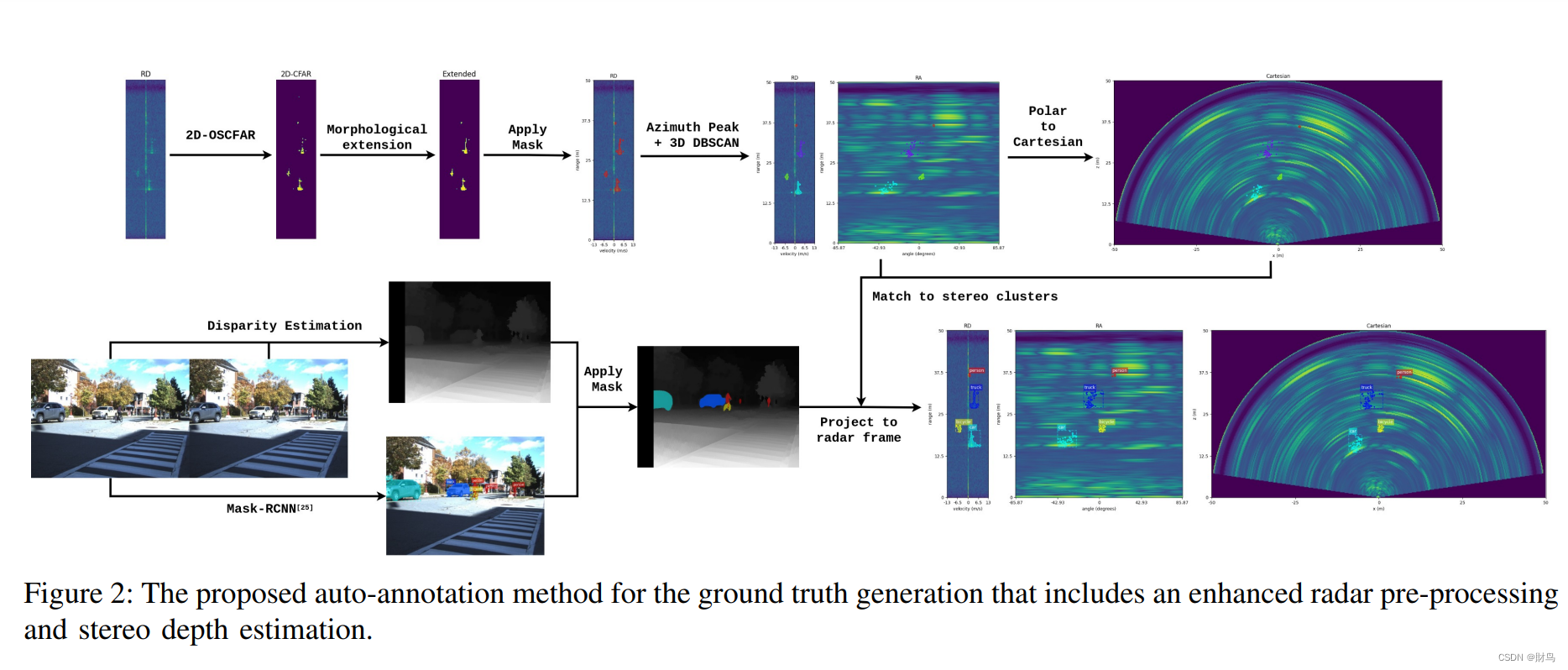
从 RAD 频谱中提取雷达实例:然而,对仅有雷达实例进行分类是一个具有挑战性的任务。在这项研究中,我们依靠立体视觉来进行类别标注。整个过程描述如下。首先,使用 OpenCV4 中的半全局块匹配算法从经过矫正的立体图像对生成视差图。然后,在左侧图像上应用预训练的 Mask-RCNN 模型,以提取实例级分割掩模。预测掩模然后投影到视差图上。最后,使用三角测量,生成带有预测类别的实例级点云输出。然后,使用在 III-A 中获得的投影矩阵将点云实例转换为雷达框架。
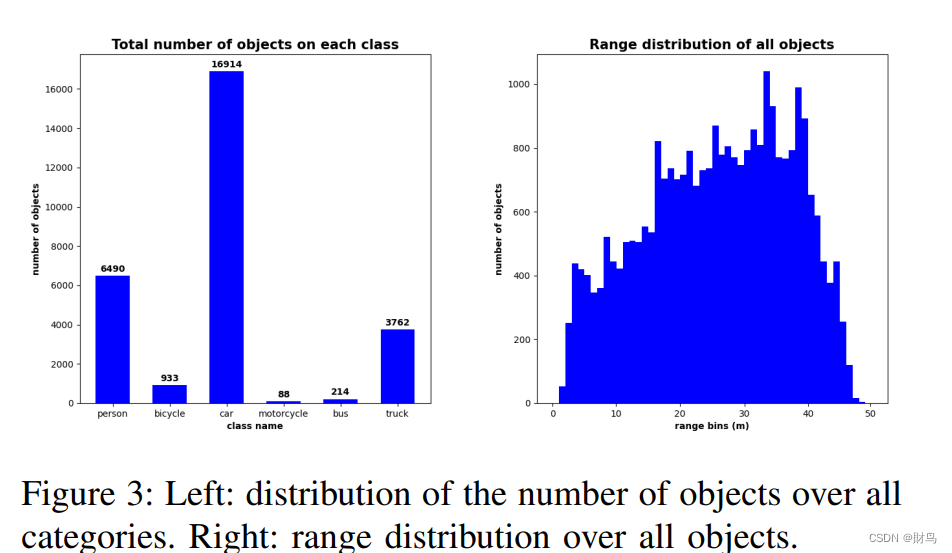
自动注释方法是使用获得的雷达和立体实例开发的。图2展示了整个过程的流程图。使用此方法,我们可以检索数据集中大约75%的所有对象的注释。多种因素可能导致注释中的错误,例如由于传感器噪声而导致的雷达实例提取中的错误,立体相机深度估计中的错误以及Mask-RCNN [25]预测中的错误。此外,由于立体相机的视野(FOV)明显小于雷达的视野,因此有一定数量的对象未被标记。为解决这些问题,在自动注释过程之后进行手动更正以生成数据集。下面是数据集信息:
3.RADDET:
A. Global Normalization of the Input
模型的原始输入是一个大小为(256,256,64)的雷达距离-方位-多普勒张量,以复数形式表示。与传统雷达数字信号处理一样,首先提取原始输入的幅值并对其取对数。为了归一化输入,在整个数据集Ddataset上搜索均值Vmean和方差Vvariance的值。然后,每个输入张量都被归一化为下面的公式:
是下一阶段骨干网络的输入。
B. RadarResNet
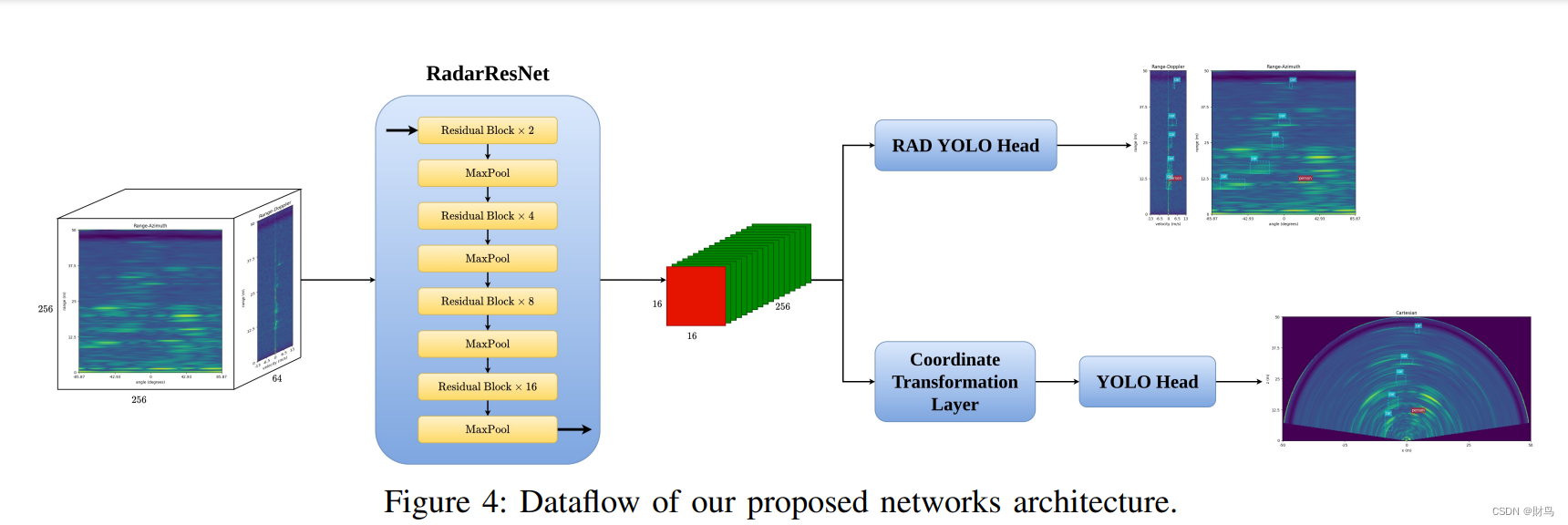
C. Dual Detection Head
3D检测头:由于我们的3D检测头的输出是3D边界框,因此对传统的YOLO Head进行了一些修改以适应我们的任务。首先,第三维度的输出大小,即多普勒维度,使用与其他维度相同的步幅计算。在我们的情况下,多普勒轴的输出大小为4。其次,3D头处理特征图为(16, 16, 4 × num_of_anchors × (7 + num_of_classes)),其中7代表物体性和3D框信息。3D框信息包括3D中心点[x,y,z]和尺寸[w,h,d]。最后,将原始检测输出重塑为最终输出格式(16, 16, 4, num_of_anchors, 7+num_of_classes),然后再输入非极大值抑制(NMS)中。其他操作,如框位置计算和解释,都采用与YOLO相同的形式。为方便起见,我们将3D检测头命名为RAD YOLO Head。
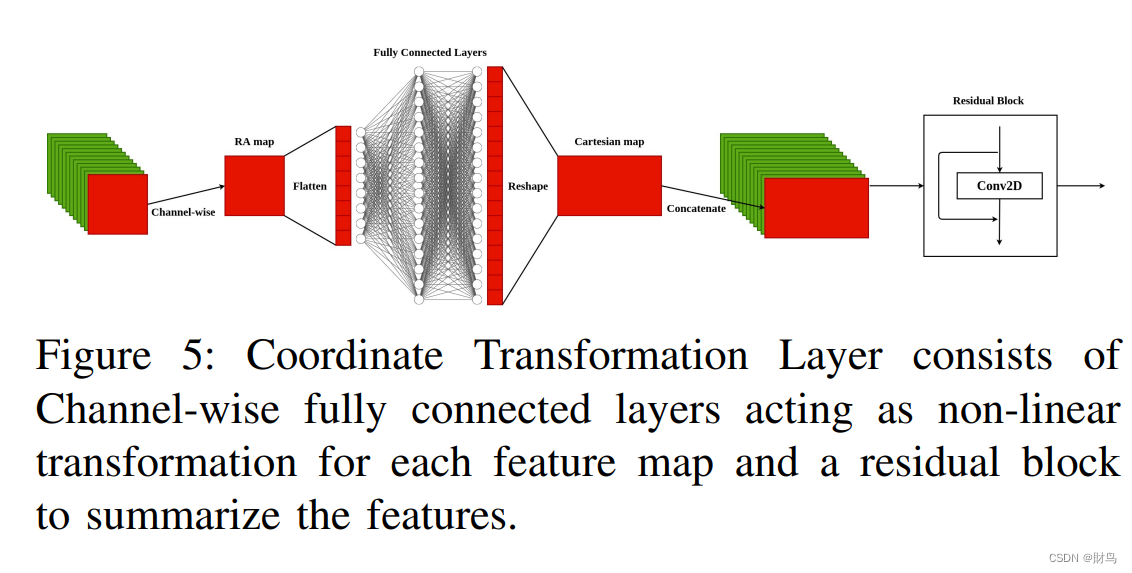
2D检测头:2D检测头由两部分组成;一个坐标变换层,将特征图从极坐标表示转换为笛卡尔形式(用神经网络代替了传统的坐标变换)和一个经典的YOLO Head。坐标变换层的结构如图5所示:
传统上,从距离和方位域[r,θ]到由[x,z]表示的笛卡尔宽度和深度域的坐标变换由以下公式表示。
这种非线性变换可以使笛卡尔形式的宽度维度输入大小加倍。 我们的坐标变换层受传统方法启发。输入特征图为[r,θ]格式,大小为(16, 16, 256)。它们可以被解释为具有(16, 16)形状的256个RA特征图。每个RA特征图分别馈送到两个全连接层进行非线性变换。然后将这些特征的输出重塑为(32, 16),并连接起来构建大小为(32, 16, 256)的笛卡尔特征图。最后,由于它们是低级特征图,因此会构建一个基于ResNet [8]中基础残差块相同结构的残差块进行后处理。转换后的输出直接输入到2D盒子预测的YOLO Head中。
D. Loss Functions
YOLO Head的输出通常分为三个任务,即框回归、物体性预测和分类。总的损失函数如下:
对于训练物体性预测损失Lobj,应用Focal Loss;对于分类损失Lclass,我们使用交叉熵[28]作为损失函数。Lbox,采用的是 Mean Squared Error (MSE) 损失函数在训练过程中,我们发现框损失很容易占据总损失值。 因此,我们为框损失设置了另一个系数β = 0.1。
4.Experiments
- 首先,我们探索了几种流行的骨干网络,即VGG [16]和ResNet [8]。
- 接下来,我们探索了在提取边界框之前使用的自注意力和通道级多层感知器(MLP)等层。 在来自文献的各种自我关注提议中,我们选择了两个,即SAGAN [29]和SAUNet [30],用于我们的实验。
- 由于我们的检测头共享同一骨干网络,因此我们训练骨干网络以及3D检测头(RAD YOLO head),因为它比2D检测头更复杂。
- 在对3D检测头进行微调后,在训练2D检测头之前,我们冻结了骨干网络层。
- 以下部分显示了对3D检测头和2D检测头上不同骨干网络的比较。我们在实验中使用的超参数定义如下:批量大小设置为3; 初始学习率为0.0001; 每经过60K个预热步骤后,学习率会随着每10K步的学习而衰减0.96; 物体性阈值为0.5; 3D和2D检测头的NMS阈值分别为0.1和0.3; 优化器设置为Adam ,选择平均精度作为度量标准。所有实验都在RTX 2080Ti GPU和TensorFlow API上进行。
A. Backbone Model Search
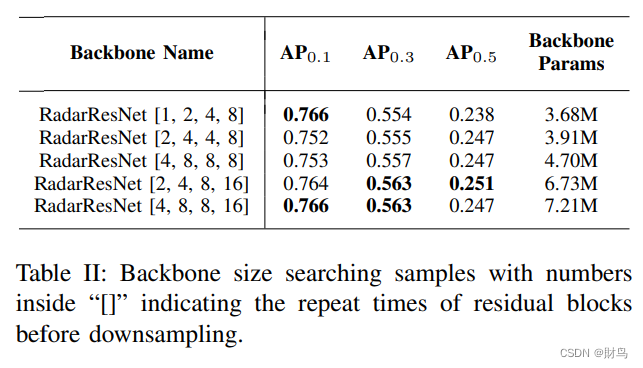
在对整个训练集进行训练之前,我们使用训练数据的一小部分设置了一个框架,以找到我们骨干网络的适当输出大小。在VGG [16]和ResNet [8]上进行了多次尝试,尝试不同的输出大小,例如(8,8),(16,16)和(32,32)。我们发现使用大小(16,16)在3D检测任务中提供了最高的性能。因此,我们首先将我们的骨干网络的输出大小固定为(16,16,256)。基于此,计算出通道扩展块和下采样块的总数分别为2和4。为了使基于图像的骨干网络适应这种结构,我们使用适当的通道扩展率和下采样率修改了每个网络。在VGG中,我们将前三个块的通道扩展率设置为1,并在第一个块中删除了池化层。在单元测试期间,我们还发现以最大池化层而非残差块进行下采样可以显着提高性能。然后,我们按照图4所示制定了RadarResNet。但是,对于类似ResNet的架构,在涉及不同任务时,残差块的重复次数会有所不同。因此,我们在整个训练集上训练了各种大小的RadarResNet以找到最佳模型。表II显示了骨干网络大小探索过程的一些示例。我们最终确定了每个最大池化层之前重复次数为2、4、8、16的RadarResNet。
B. Detection Head Comparisons
对不同骨干网络在3D和2D检测任务中进行系统比较的结果进行总结,除了使用的模型之外,还对自注意力层进行了探索,并发现它们在目标检测中具有很大潜力。作者在RadarResNet上分别使用了SAGAN和SAUNet来研究自注意力层的影响,并通过实验表明,自注意力层的性能并不比RadarResNet更好。此外,作者还使用了通道多层感知器(MLP)来构建另一个基线模型,即RadarResNet+MLP。表格I显示了不同骨干网络在不同检测头上的表现,包括精度和推理时间。实验结果表明,在RAD YOLO Head任务中,RadarResNet优于其他骨干网络。可能原因是残差块在雷达物体检测中的性能优于顺序卷积层,因为在处理过程中,原始输入信号被放大。同时表格I也显示,最大池化层比步幅卷积层更适合于该任务。对于2D YOLO Head任务,虽然RadarResNet + SA(SAUNet)表现略微更好,但RadarResNet的总体精度更高,推理速度也更快。这进一步证明了图像自注意力层可能不适用于雷达信号的检测任务。















 9539
9539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









