







3DGS-Enhancer
1 背景
标题:3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors
作者:Xi Liu, Chaoyi Zhou, Siyu Huang机构:School of Computing Clemson University
原文链接:https://arxiv.org/abs/2410.16266
代码链接:https://github.com/xiliu8006/3DGS-Enhancer
官方主页:https://xiliu8006.github.io/3DGS-Enhancer-project
3DGS-Enhancer它应用视频扩散的视图一致性先验并用轨迹插帧方法来增强无界场景的 3DGS 表达
具有卓越的重建性能和高保真渲染结果
2 摘要
新型视角合成旨在从多张输入图像或视频中生成新的场景视图。最近的进展,如3D高斯splatting(3DGS),在生成具有高效流程的逼真渲染方面取得了显著成功。然而,在稀疏输入视图等具有挑战性的设置下生成高质量的新视角仍然困难重重,因为这些区域信息不足(under-sampled areas欠采样区),通常会导致明显的伪影(noticeable artifacts)。本文介绍了一种名为3DGS-Enhancer的新管道,用于增强3DGS表示的质量。我们利用2D视频扩散先验来解决具有挑战性的3D视角一致性问题,将其重新表述为视频生成过程中的时间一致性问题。3DGS-Enhancer恢复了渲染新视角的视角一致的潜在特征,并通过空间-时间解码器将它们与输入视图集成。增强后的视图随后用于微调初始3DGS模型,大幅提高了其渲染性能。在大规模无边界场景数据集上的广泛实验表明,3DGS-Enhancer相比最先进方法提供了更优的重建性能和高保真度渲染结果。
3 介绍
新型视角合成(NVS)在计算机视觉和图形学领域已有数十年的历史,目标是从多个输入图像或视频中生成场景的新视角。最近,3D高斯点绘(3DGS)在生成高度逼真的渲染方面表现出色,且具有高效的渲染流程。然而,远离现有视角生成高质量的新视角仍然是一个巨大的挑战,尤其是在稀疏视角设置下,由于采样不足区域的信息不足。如图1所示,当只有三个输入视角时,会出现明显的椭球状和空洞伪影。由于实践中这些常见的低质量渲染结果,增强3DGS以确保其在现实世界应用中的可行性变得至关重要。

据我们所知,很少有先前的研究专门关注于旨在提高NVS渲染质量的增强方法。大多数现有的NVS增强工作集中在将额外的几何约束(如深度和法线)纳入3D重建过程中,以填补观察到的和未观察到的区域之间的差距。例如,DNGaussian对辐射场的几何形状应用了硬软深度正则化。然而,这些方法严重依赖于附加约束的有效性,并且往往对噪声敏感。另一类工作利用生成先验来规范NVS流程。例如,ReconFusion 通过为未观察到的区域合成几何和纹理来增强神经辐射场(NeRFs)。尽管它可以生成照片级真实感的新视角,但在生成的视角远离输入视角时,视角一致性仍然是一个挑战。
在这项工作中,我们利用2D生成先验,例如潜在扩散模型(LDMs),来增强3DGS表示。LDM已经在各种图像生成和恢复任务中展示了强大而稳健的生成能力。然而,主要挑战在于生成的2D图像之间较差的3D视角一致性,这极大地阻碍了需要高度精确视角一致性的3DGS训练过程。尽管已经做出了一些努力,比如使用Score Distillation Sampling(SDS)损失从预训练的扩散模型中提炼优化目标,但这种方法无法生成允许渲染高保真图像的3D表示。
潜在扩散模型(Latent Diffusion Models, LDMs)是一类生成模型,它们结合了扩散模型的概念和潜在变量模型的优点。扩散模型是一种逐步添加噪声到数据中的生成模型,然后学习逆过程——即从噪声数据中逐步恢复原始数据的过程。潜在扩散模型通过首先将数据映射到一个较低维度的潜在空间,然后在这个潜在空间中执行扩散过程,从而提高了效率和效果。这种方法不仅减少了计算成本,还使得模型能够处理更高分辨率和更复杂的图像。
论文链接:High-Resolution Image Synthesis with Latent Diffusion Models
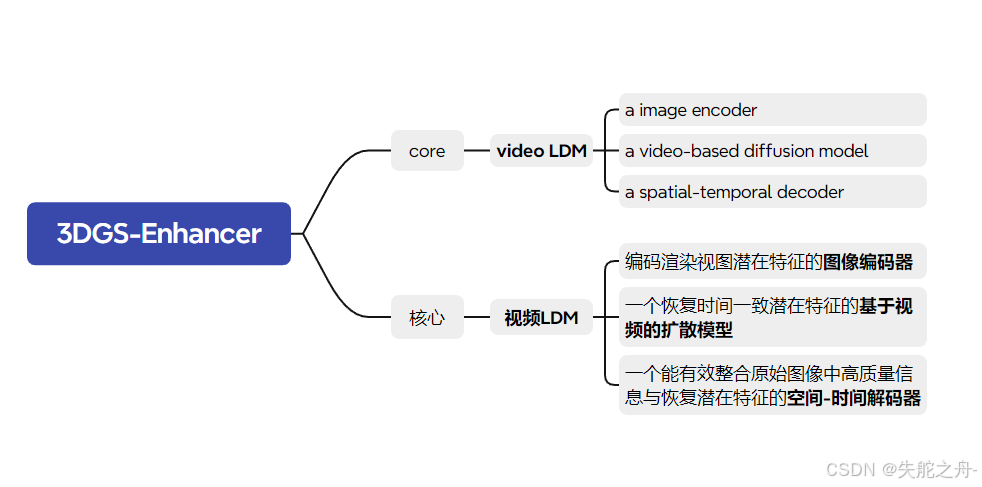
受到多视角图像之间视觉一致性和视频帧之间时间一致性类比的启发,我们提出将具有挑战性的3D一致性问题重新表述为视频生成中实现时间一致性的较易任务,这样就可以利用强大的视频扩散模型来恢复高质量且视角一致的图像。我们提出了一种新颖的3DGS增强管道,称为3DGS-Enhancer。3DGS-Enhancer的核心是一个视频LDM,包括一个编码渲染视图潜在特征的图像编码器、一个恢复时间一致潜在特征的基于视频的扩散模型以及一个能有效整合原始渲染图像中高质量信息与恢复的潜在特征的空间-时间解码器。初始的3DGS模型将通过这些增强的视图进行微调,以提高其渲染性能。所提出的3DGS-Enhancer可以无需轨迹地从稀疏视角重建无界场景,并为两个已知视角之间的不可见区域生成自然的3D表示。同期的工作V3D也利用了潜在视频扩散模型从单个图像生成对象级别的3DGS模型。相比之下,我们的3DGS-Enhancer专注于增强任何现有的3DGS模型,因此可以应用于更广泛的场景,例如无界的户外场景。
DL3DV(Deep Learning 3D Vision)是指一系列基于深度学习的3D视觉技术及其相关数据集。特别是提到的DL3DV-10K,这是一个大规模的多视图场景数据集,旨在促进神经视图合成(Neural View Synthesis, NVS)领域的研究和发展。DL3DV-10K数据集包含了超过10,000个高质量视频,每个视频都经过了人工标注场景关键点和复杂程度,并提供了相机姿态、NeRF估计深度、点云和3D网格等信息。
在实验中,我们基于DL3DV生成了数百个无界场景的大规模数据集,每个场景包含低质量和高质量图像对,以全面评估新探究的3DGS增强问题。实证结果表明,所提出的3DGS-Enhancer方法在各种具有挑战性的场景上实现了优越的重建性能,产生了更加鲜明和生动的渲染结果。代码和生成的数据集将公开提供。本文的贡献总结如下。
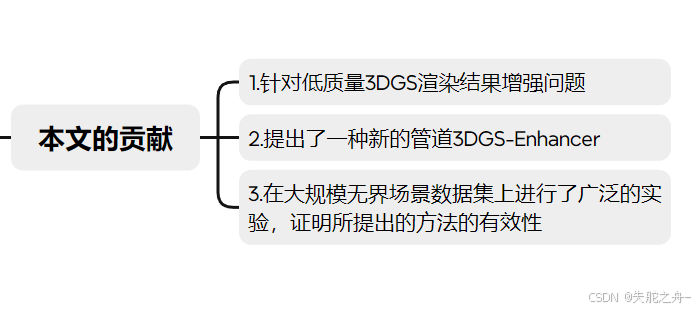
1.据我们所知,这是第一项针对实际3DGS应用中广泛存在的低质量3DGS渲染结果增强问题的研究。
2.我们提出了一种新的管道3DGS-Enhancer,用于解决3DGS增强问题。3DGS-Enhancer将3D一致性图像恢复任务重新表述为时间一致性视频生成,从而可以利用强大的视频LDMs来生成既高质量又3D一致的图像。同时,还设计了新的3DGS微调策略,以有效地将增强的视图与原始3DGS表示整合。
3.我们在大规模无界场景数据集上进行了广泛的实验,以证明所提出的方法相较于现有的最先进的少样本NVS方法的有效性。
4 3dgs初步研究
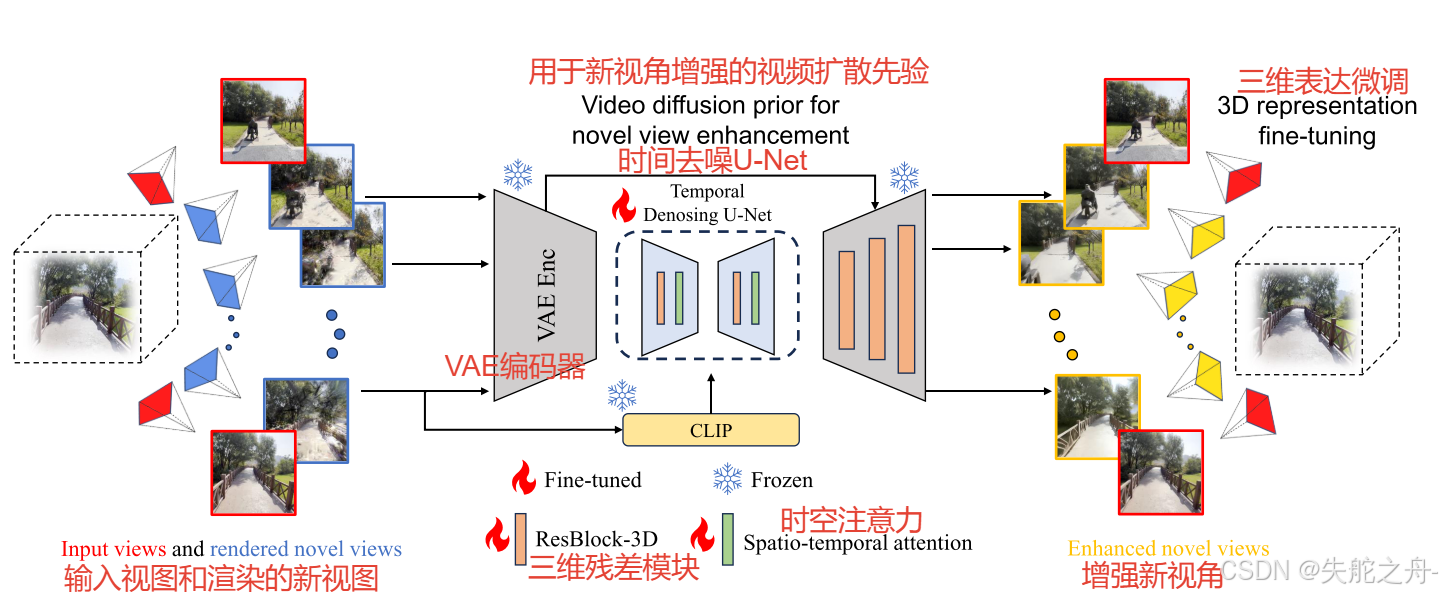
这个图片所提出的3DGS-Enhancer框架用于3DGS表示增强的概览。我们在大规模新型视角合成数据集上学习2D视频扩散先验,以增强从3DGS模型在新场景中渲染的新视角。随后,增强的视图与输入视图共同微调3DGS模型。


















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











