






下面将介绍如何使用 YOLOv11 对行人进行目标实时跟踪,如果你想对车辆或者其他的目标进行跟踪,你只需要将对应的数据集换成你自己构建的数据集训练模型即可。
如果你还没有安装深度学习的环境,可以去看看我之前写的 pytorch-GPU版本安装。废话少说,直接开始。 建议所有的文件路径不要出现中文!!!
1.数据集准备
本次实验使用的数据集为开源数据集 CrowdHuman Dataset,下载完成会得到:
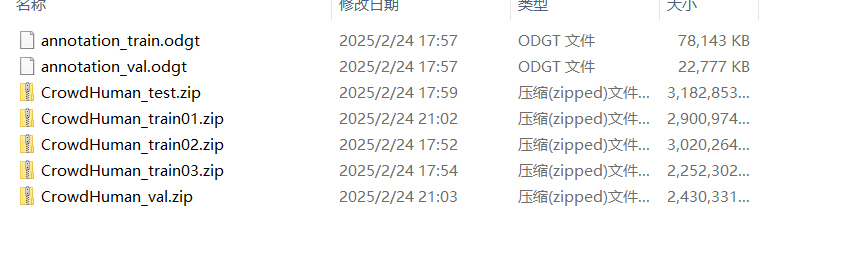
其中前两个 odgt 为官方给出的标签,五个压缩包是图片,其中三个 train 每个包含 5000 张图片,共计 15000 张。val 是用来每轮训练完成后验证模型性能,test是测试最终训练完成的模型,但是官网没有给出对应的标签。
1.1 数据集处理
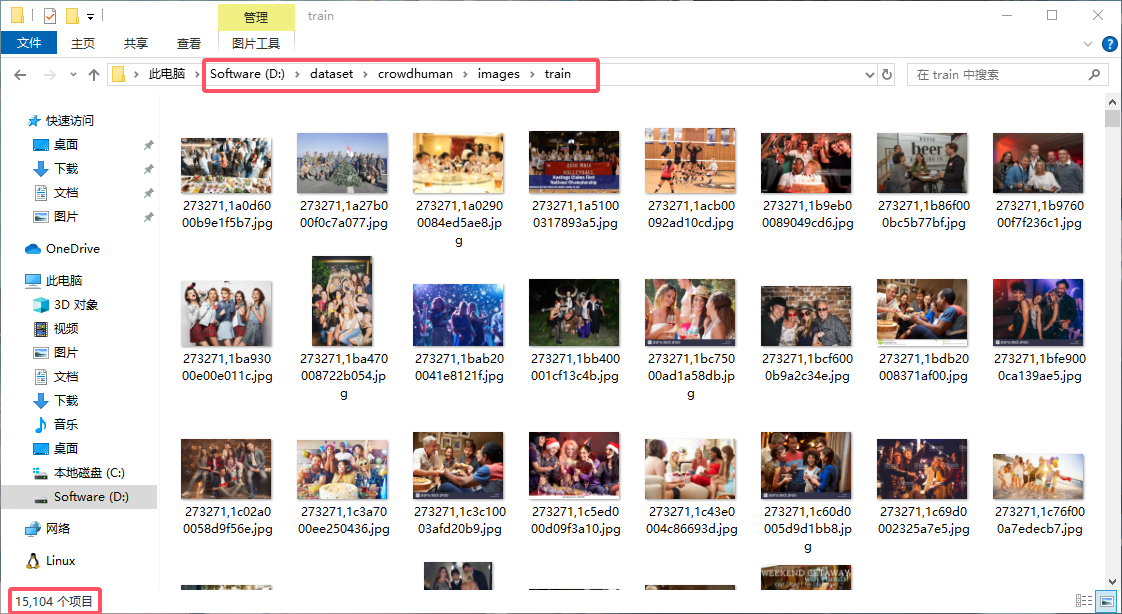
1. 将三个 train 中的5000 张图片放在同一个文件夹:
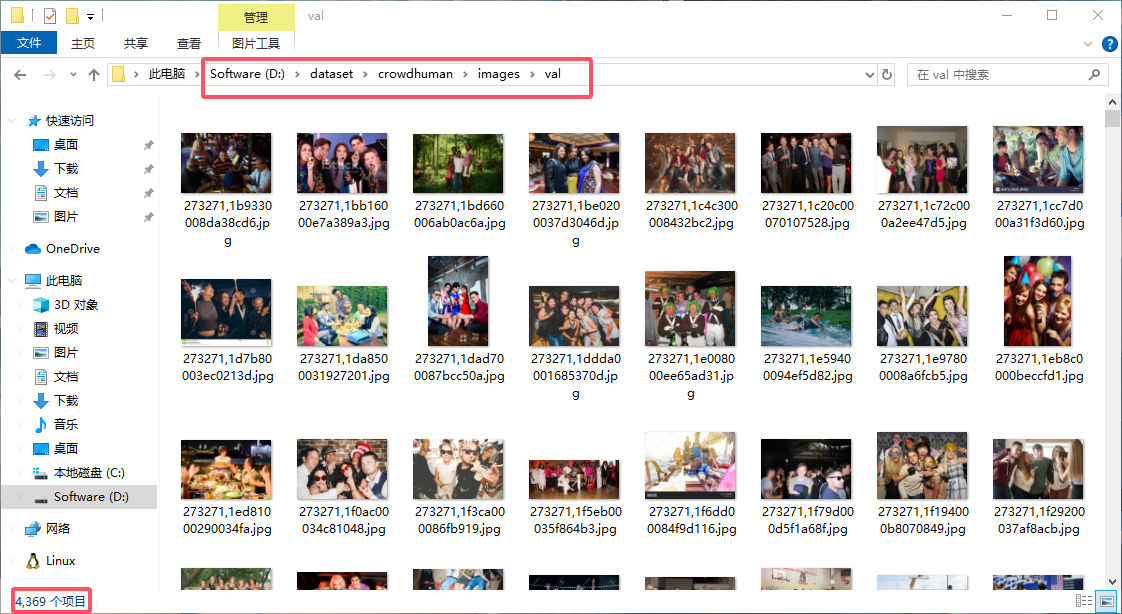
2. val 单独做一个文件夹
1.2标签
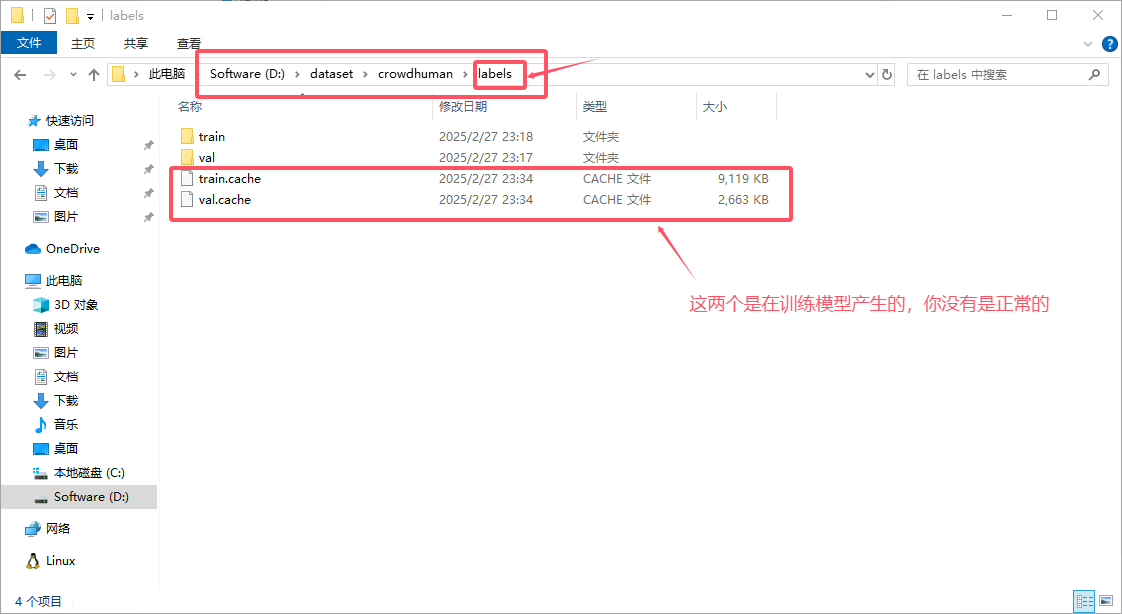
对于标签,可以找找其他人的转换脚本,利用 odgt 获取标签,YOLO 使用的 txt 文件。你最终会得到如下:
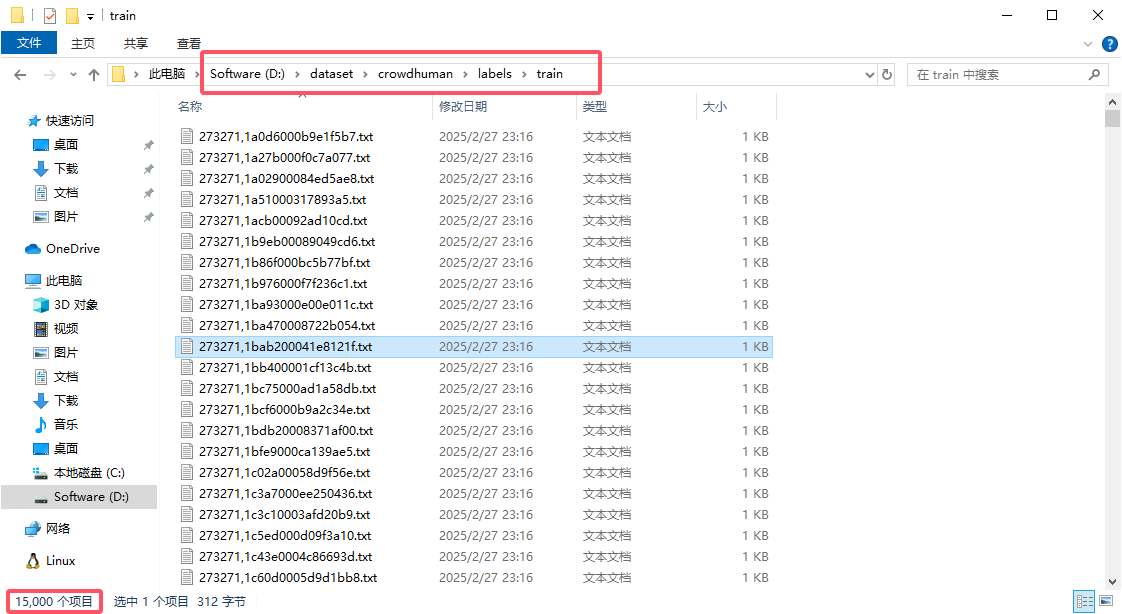
验证集也是一样。
1.3 数据集存放位置
注意图片和标签的存放,建议仿照我路径形式存放,我将它们一同放在一个文件名为 crowdhuman,不然在训练模型是容易出现文件找不到的情况。image 和 labels 下都有 train 和 val。
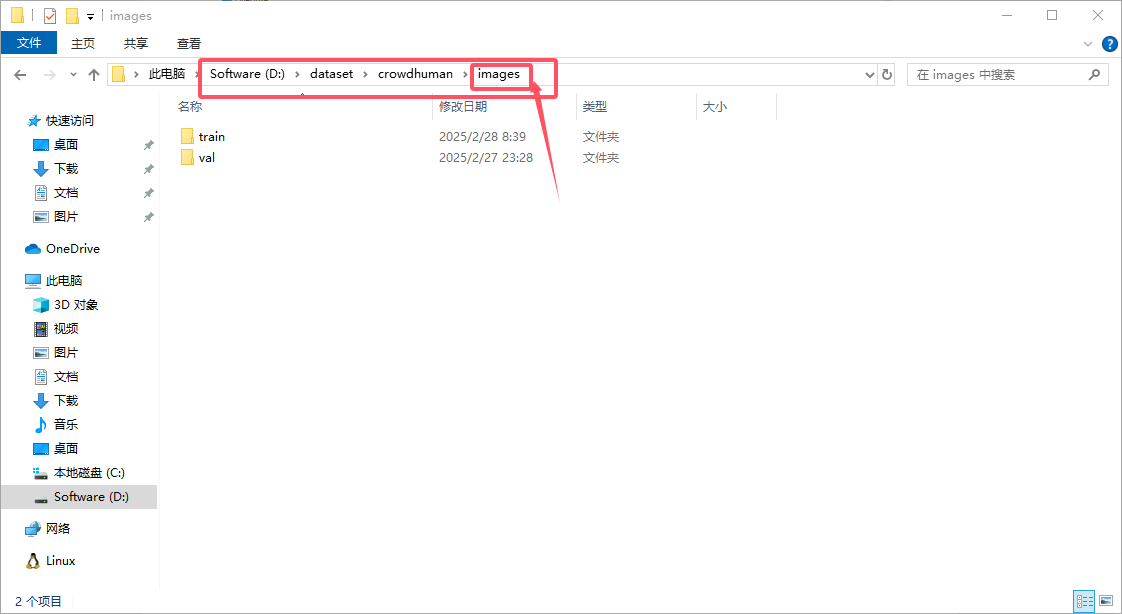
对于自己构建的数据集,我也建议是这样存放。至此数据集构建完成。
2.克隆YOLOv11项目
下载 YOLOv11项目 后打开,我使用的是pycharm。打开后会看见如下界面:
部分文件和脚本是我已经写好的,需要用到的后面我会分享我写的源代码。
2.1 使用自己构建的数据集训练模型
2.1.1 下载项目所需的环境
在终端输入 pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple 即可。
我是已经下载好了的,只需要耐心等待即可。
2.1.2 配置必要文件
找到 ultralytics/cfg/datasets/ 这个目录下的配置文件,设置训练集和验证集的路径。我使用的是VOC.yaml 文件,我建议你把这个文件复制一份,然后使用这个复制文件。注意严格按照种类顺序来写,不然在预测是会发现种类预测不对。
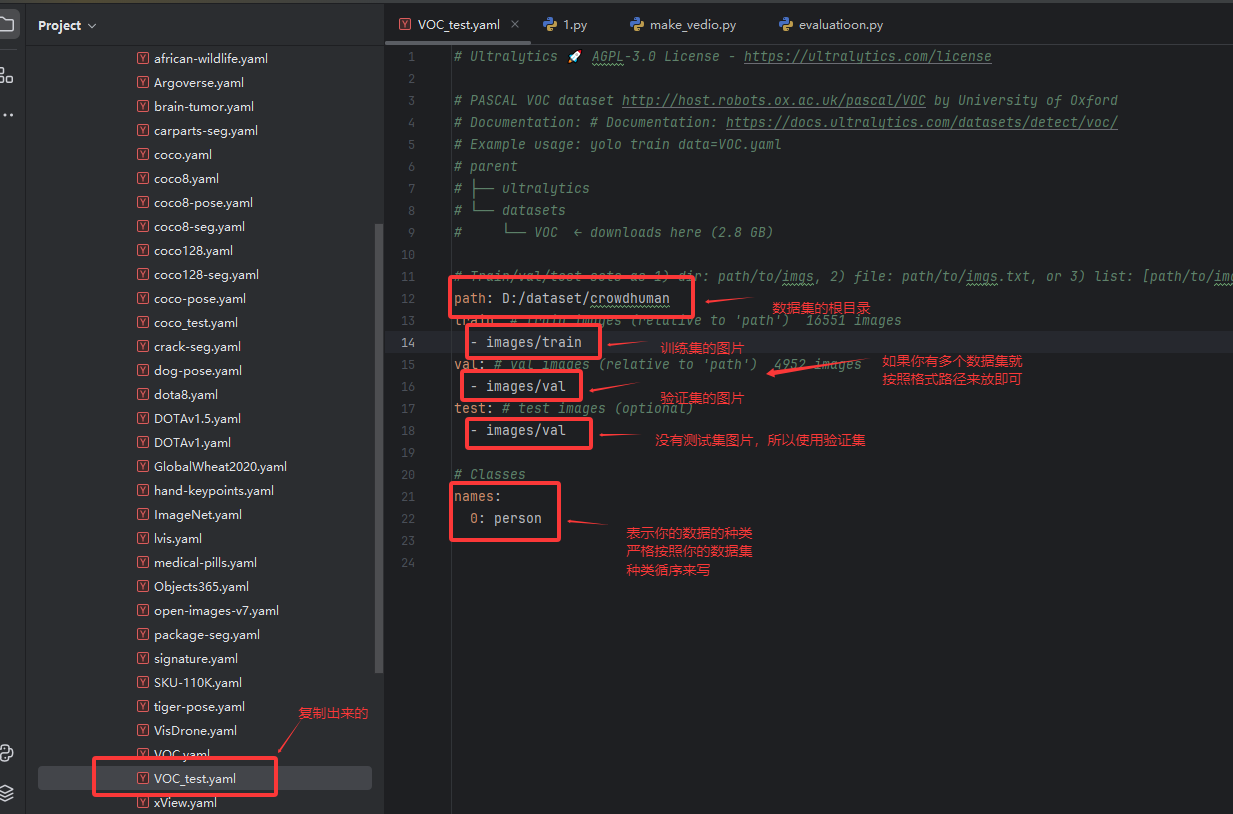
2.1.3 训练模型
首先需要下载预训练权重,在 预训练权重 下载。
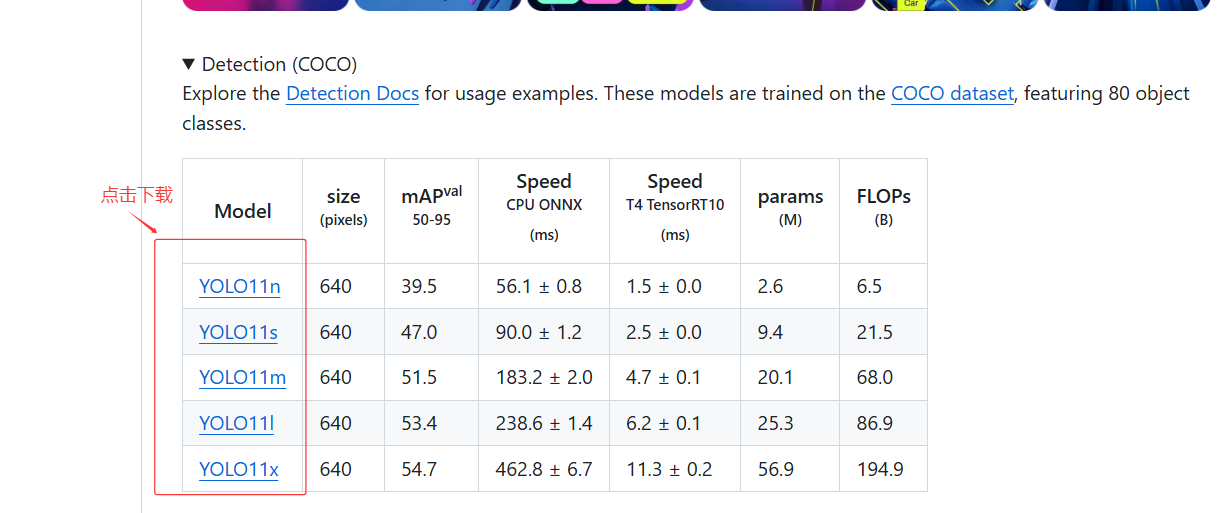
我建议在 YOLOv11 项目下建一个文件夹命名为 weights,方便管理,我使用的是 s 模型。
然后在终端输入:
yolo task=detect mode=train model=weights/yolo11s.pt data=ultralytics/cfg/datasets/VOC_test.yaml batch=32 epochs=100 imgsz=640 workers=0 device=0 cache=True 即可开始训练,其中 model=weights/yolo11s.pt 为刚刚下载的预训练权重路径,data=ultralytics/cfg/datasets/VOC_test.yaml 是 2.1.2 节配置必要文件。batch=32 是每次输入模型的图片大小,显示小的可以降低以免爆显存。epochs=100 是训练次数, imgsz=640 图像尺寸大小,workers=0 我建议设置为0,否则可能会报错, device=0 设备名称,cache=True 启用缓存。更多参数详见物体检测 -Ultralytics YOLO 文档。
开始训练模型,我使用的是 4060Ti 16G,训练时长约为 1 天多。
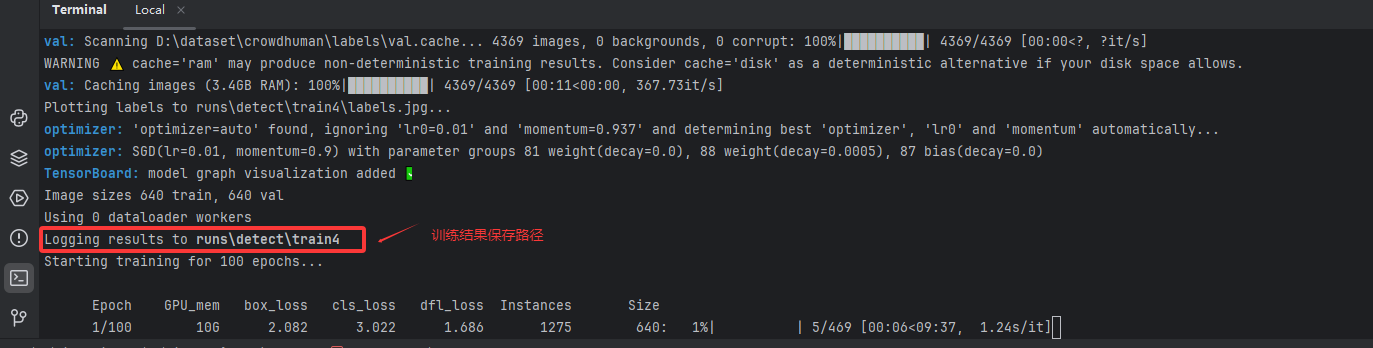
训练完成后,你最终会得到如下:
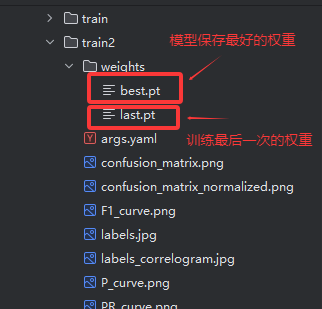
PS:可中断模型训练,再次训练时需要将权重更换成 model=runs/detect/train/weights/last.pt 在加上 resume=True 即可,其他参数不变。
2.1.4 验证模型(可选)
在终端输入:
yolo task=detect mode=val model=runs/detect/train2/weights/best.pt data=ultralytics/cfg/datasets/VOC_test.yaml device=0 plots=True workers=0 即可进行验证。

至此,你已经完成了 YOLOv11 的训练以及验证,下面就可使用训练好的权重进行目标跟踪。
3. 使用训练好的模型进行实时跟踪
PS: 再 ultralytics/trackers 在这个文件下有跟踪源代码,有需要的可以看看。
1. 行人数据集准备以及获取跟踪数据
行人视频数据集可在 MOT Challenge 下载,本次实验我选用 MOT17数据集。
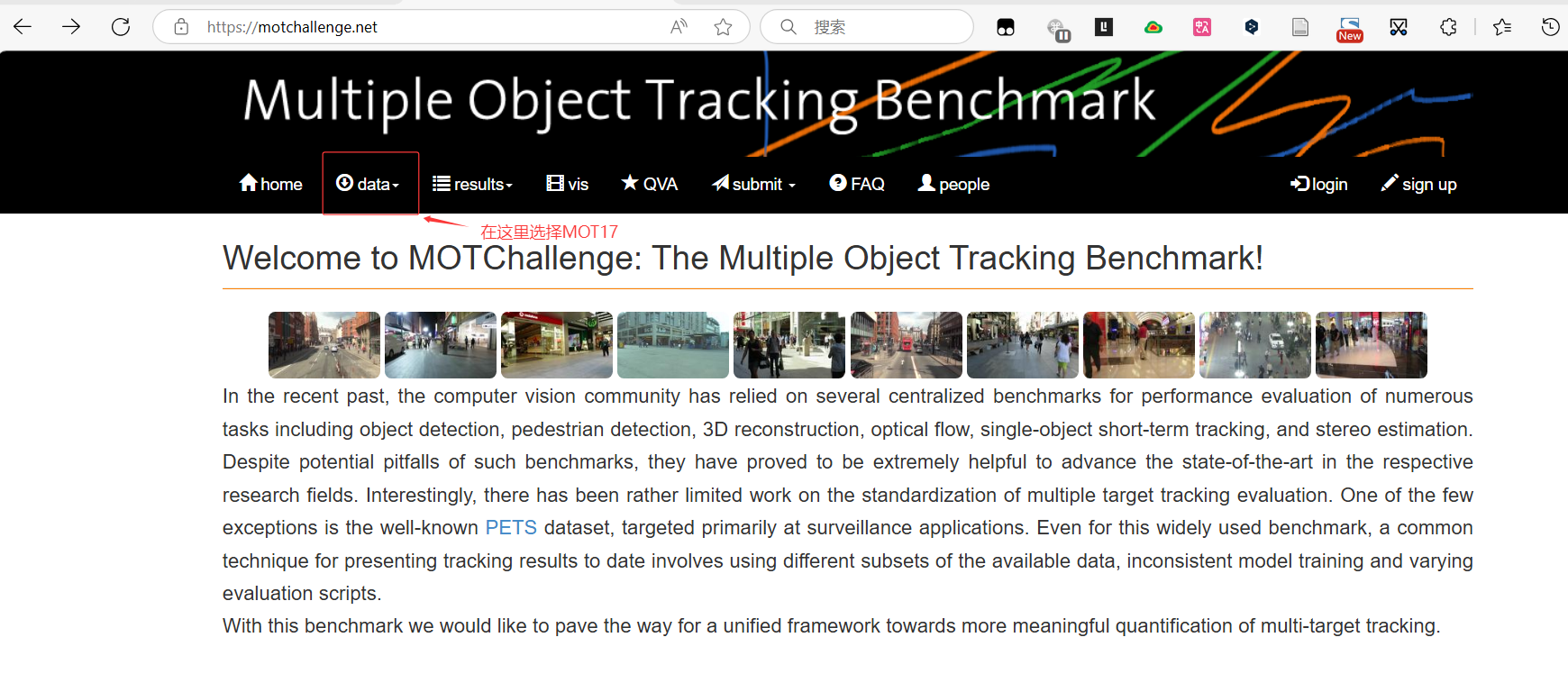
下载完成后,你会得到如下数据:

其中 test 是需要进行测试的,官方不提供真实轨迹,而 train 是官方提供了真实轨迹的数据集,用于在模型训练时学习目标的运动轨迹,简称半值训练。所以我们使用 train 中的数据集来进行试验。
值得注意的是视频参数,否则合成后视频无法播放,视频参数在 seqinfo.ini 中。
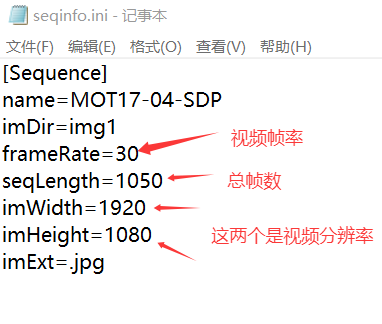
使用如下代码将 train 中的图片合成视频。你只需要修改图片路径以及视频参数即可。我合成的视频为 FRCNN 结尾的。你需要将路径更换成你的数据路径,以及保存路径。
import cv2
import os
# 视频输出设置
output_video_path = r"D:\ultralytics-main\video\MOT17-train\MOT17-02.mp4"
video_writer = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*"mp4v"), 30, (1920, 1080))
# 图像路径和文件排序
images_path = r"D:\dataset\MOT-data\MOT17\train\MOT17-02-FRCNN\img1"
images_list = os.listdir(images_path)
images_list.sort() # 确保图像按顺序排序
# 遍历所有图像并写入视频
for image_name in images_list:
image = cv2.imread(os.path.join(images_path, image_name)) # 读取图像
if image is None:
print(f"无法读取图像 {image_name}, 跳过")
continue
# 写入视频
video_writer.write(image)
# 显示图像(调整显示大小为720p)
show = cv2.resize(image, (1280, 720))
cv2.imshow("test", show)
# 等待10毫秒并检查是否按下了"q"键退出
if cv2.waitKey(1) == ord('q'):
break
# 释放资源
cv2.destroyAllWindows()
video_writer.release()
然后再运行如下代码,使用的是 bytetrack 算法进行跟踪,你可以通过修改配置文件来更换跟踪算法,你需要将路径更换成你的数据路径:
from ultralytics import YOLO
import cv2
import numpy as np
import pandas as pd
import os
# 全局轨迹存储字典 {track_id: [(x1,y1), (x2,y2), ...]}
trajectory_data = {}
# ------------------------- 优化工具函数 -------------------------
def get_bbox_coords(box):
"""安全获取检测框坐标(兼容CPU/GPU张量)"""
xyxy = box.xyxy.squeeze()
if xyxy.is_cuda: # 处理GPU张量
xyxy = xyxy.cpu()
return xyxy.numpy().astype(int) # 返回整数坐标 [x1,y1,x2,y2]
def smooth_trajectory(trajectory, window_size=5):
"""轨迹平滑(移动平均滤波)"""
if len(trajectory) < window_size:
return trajectory
smoothed = []
for i in range(len(trajectory)):
start = max(0, i - window_size // 2)
end = min(len(trajectory), i + window_size // 2 + 1)
avg_x = np.mean([p[0] for p in trajectory[start:end]])
avg_y = np.mean([p[1] for p in trajectory[start:end]])
smoothed.append((int(avg_x), int(avg_y)))
return smoothed
def save_trajectories_to_csv(save=True, directory=None):
"""保存轨迹数据到CSV文件,并处理文件名冲突"""
if not save:
print("csv保存已取消")
return
path_save_csv = os.path.dirname(directory) # 获取目录路径
file_name = os.path.splitext(os.path.basename(directory))[0] # 获取文件名,不包含扩展名
# 创建 DataFrame
df = pd.DataFrame([
{'track_id': tid, 'x': x, 'y': y, 'frame': idx}
for tid in trajectory_data
for idx, (x, y) in enumerate(trajectory_data[tid])
])
# 设定文件名
file_path = os.path.join(path_save_csv, f"{file_name}.csv")
# 检查文件是否存在,若存在则修改文件名
#i = 1
while os.path.exists(file_path):
file_path = os.path.join(path_save_csv, f"{file_name}.csv")
# i += 1
# 保存 DataFrame 到 CSV
df.to_csv(file_path, index=False)
print(f"轨迹数据已保存至 {file_path}")
# ------------------------- 核心逻辑 -------------------------
def update_and_draw_trajectory(frame, track, max_history=20, smooth_window=5):
"""
优化后的轨迹更新与绘制函数
Args:
smooth_window: 轨迹平滑窗口大小 (设为0禁用平滑)
"""
track_id = track.id.item()
x_left_vertex, y_left_vertex, _, _ = get_bbox_coords(track)
bbox_center = track.xywh.squeeze().cpu().numpy()
x_center, y_center = int(bbox_center[0]), int(bbox_center[1])
# 更新轨迹数据
if track_id not in trajectory_data:
trajectory_data[track_id] = []
trajectory_data[track_id].append((x_center, y_center))
# 限制历史长度
if len(trajectory_data[track_id]) > max_history:
trajectory_data[track_id].pop(0)
# 轨迹平滑处理
trajectory = trajectory_data[track_id]
if smooth_window > 0:
trajectory = smooth_trajectory(trajectory, smooth_window)
# 绘制轨迹线
if len(trajectory) >= 2:
for i in range(1, len(trajectory)):
cv2.line(frame, trajectory[i - 1], trajectory[i],
(0, 255, 0), 2, cv2.LINE_AA)
# 绘制ID标签
cv2.putText(frame, f"ID: {track_id}", (x_left_vertex, y_left_vertex),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
# 检查存储的轨迹数据
#print(f"Track ID: {track_id}, Trajectory: {trajectory_data[track_id]}")
def main():
# 初始化模型(使用自定义训练权重)
#model = YOLO('runs/detect/train/weights/best.pt')
model = YOLO(r'D:\ultralytics-main\runs\detect\train2\weights\best.pt')
# 视频输入设置
cap = cv2.VideoCapture(r'D:\ultralytics-main\video\MOT17-train\MOT17-02.mp4')
tracker_config = r"ultralytics/cfg/trackers/bytetrack.yaml"
path_save_txt = r'D:\ultralytics-main\save_track_inf\MOT17-train\MOT17-02.txt'
# 性能优化参数
#imgsz = [1920, 1080] 960 # 输入分辨率(可下调至320加速)
imgsz = 960
show_display = True # 是否实时显示
frame_count = 1
while cap.isOpened():
ret, frame = cap.read()
if not ret: break
# 跟踪推理(优化性能)
results = model.track(
source=frame,
tracker=tracker_config,
imgsz=imgsz, # 控制分辨率
persist=True,
conf=0.1,
verbose=False
)
# 处理检测结果
if results[0].boxes.id is not None:
for box in results[0].boxes:
# 优化坐标获取
x1, y1, x2, y2 = get_bbox_coords(box)
_, _, w, h = box.xywh.squeeze().cpu().numpy()
# 绘制检测框
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
track_id = box.id.item()
confidence = box.conf.item()
consider_obj, category, visibility = 1, 1, 1
with open(path_save_txt, 'a') as file:
file.write(f"{frame_count},{track_id},{x1},{y1},{w},{h},{confidence},{consider_obj},{category},{visibility}\n")
# 更新轨迹(启用平滑,窗口大小=5)
update_and_draw_trajectory(frame, box, smooth_window=0)
frame_count = frame_count + 1
# 显示结果
if show_display:
#cv2.namedWindow('Object Tracking', cv2.WINDOW_NORMAL) # 允许手动调整窗口尺寸
cv2.namedWindow('Object Tracking')
cv2.imshow('Object Tracking', frame)
is_pause = cv2.waitKey(1)
if is_pause == ord('q'):
break
elif is_pause == ord(' '):
cv2.waitKey(0)
# 释放资源并保存轨迹
cap.release()
if show_display:
cv2.destroyAllWindows()
save_trajectories_to_csv(False, path_save_txt) # 保存轨迹数据
print(f"MOT2D数据格式保存至:{path_save_txt}")
if __name__ == "__main__":
main()PS: bytetrack 算法 原文链接,推荐大家可以去看看。
你会得到一个 txt 文件,如图:
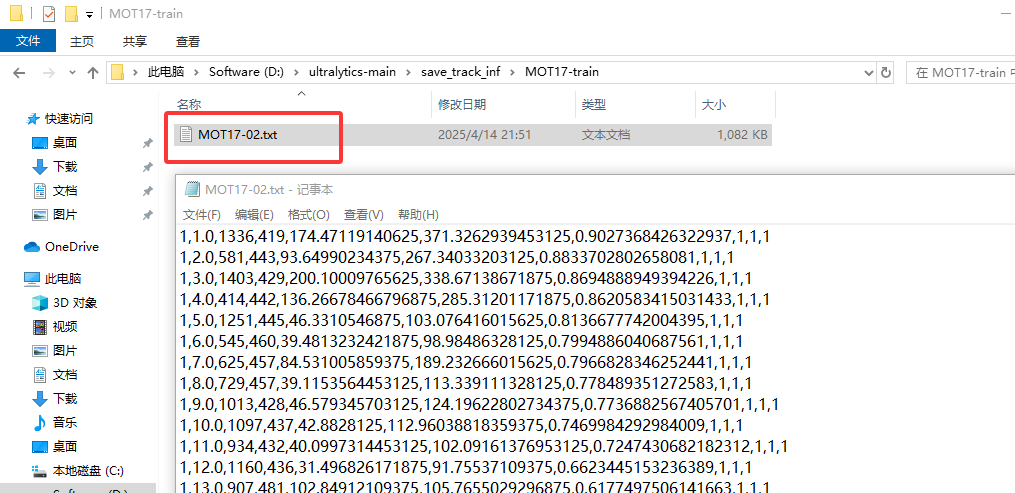
它们分别表示:第 1 个代表第几帧,第 2 个值为目标运动轨迹的ID号,第 3 个到第 6 个数代表物体框的左上角坐标及长宽,第 7 个值置信度,第 8 9 10 表示 3D 的坐标,由于我们做的是 2D ,所以 3D 的坐标均为设置为 1.
2. 评价跟踪性能
克隆项目 Easier_To_Use_TrackEval ,下载完成后你打开项目,你会看到:
这里需要注意一下,环境使用 scipy==1.4.1 numpy==1.18.1,numpy不能使用 2.x 版本,会出现兼容性问题。
下面就是分别设置真实轨迹和跟踪轨迹。
2.2.1 真实路径文件(gt)配置:
真实轨迹放置存放位置:
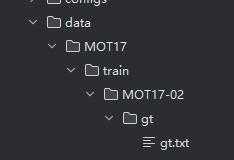
具体配置信息可在如下图片找到并修改:
详细路径配置可看我配置的,建议仿照我的:
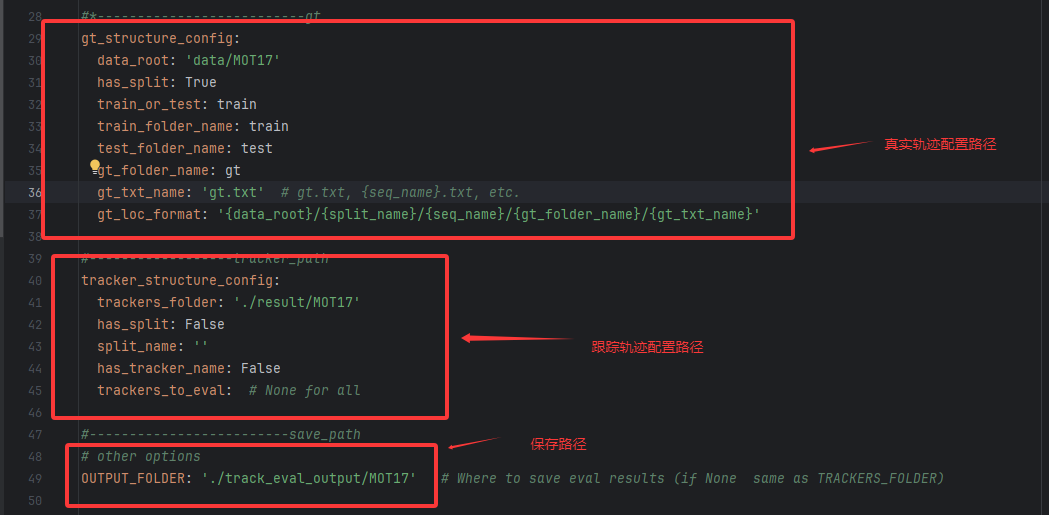
2.2.2 跟踪路径文件track)配置:
把你刚刚得到的跟踪文件放到如下图所示的文件:
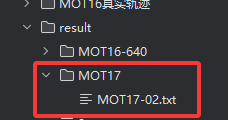
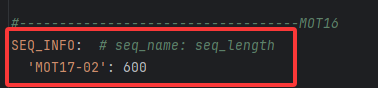
注意文件命名必须与如下图红色方框相同, 即与 SEQ_INFO 下的信息相同:
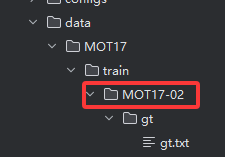
如果你有多个,按照这个方法放置文件,记得修改SEQ_INFO。
然后在终端输入 python scripts\run_custom_dataset.py --config_path configs\mytest2.yaml
mytest2 是你刚刚配置好的文件。

你会得到如下的指标:

每个指标表示什么,可在网上找找。
至此,你已经完成了如何使用YOLOv11 进行目标实时跟踪,并获取跟踪性能。
在最后如果本博客对你有所帮助,请你在写论文或者其他什么需要引用参考文献的文章,希望你能引用本次所有开源项目的作者的论文,谢谢你的配合。再次感谢所有开源项目的作者!!!
这个是我几个月前做的,很多细节忘记了,写得不是很好,请多多包涵。
PS:值得一提的是,这个评价算法有可能会得出负数,比如使用 byte track 作者的开源项目:bytetrack 得到的跟踪结果,个人猜测是在设计评价算法时方法不同导致,有大佬知道的可以在评论区留言,目前byte track作者的开源项目源代码我还不是很懂。
一个简单的演示视频

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









