







1 概述
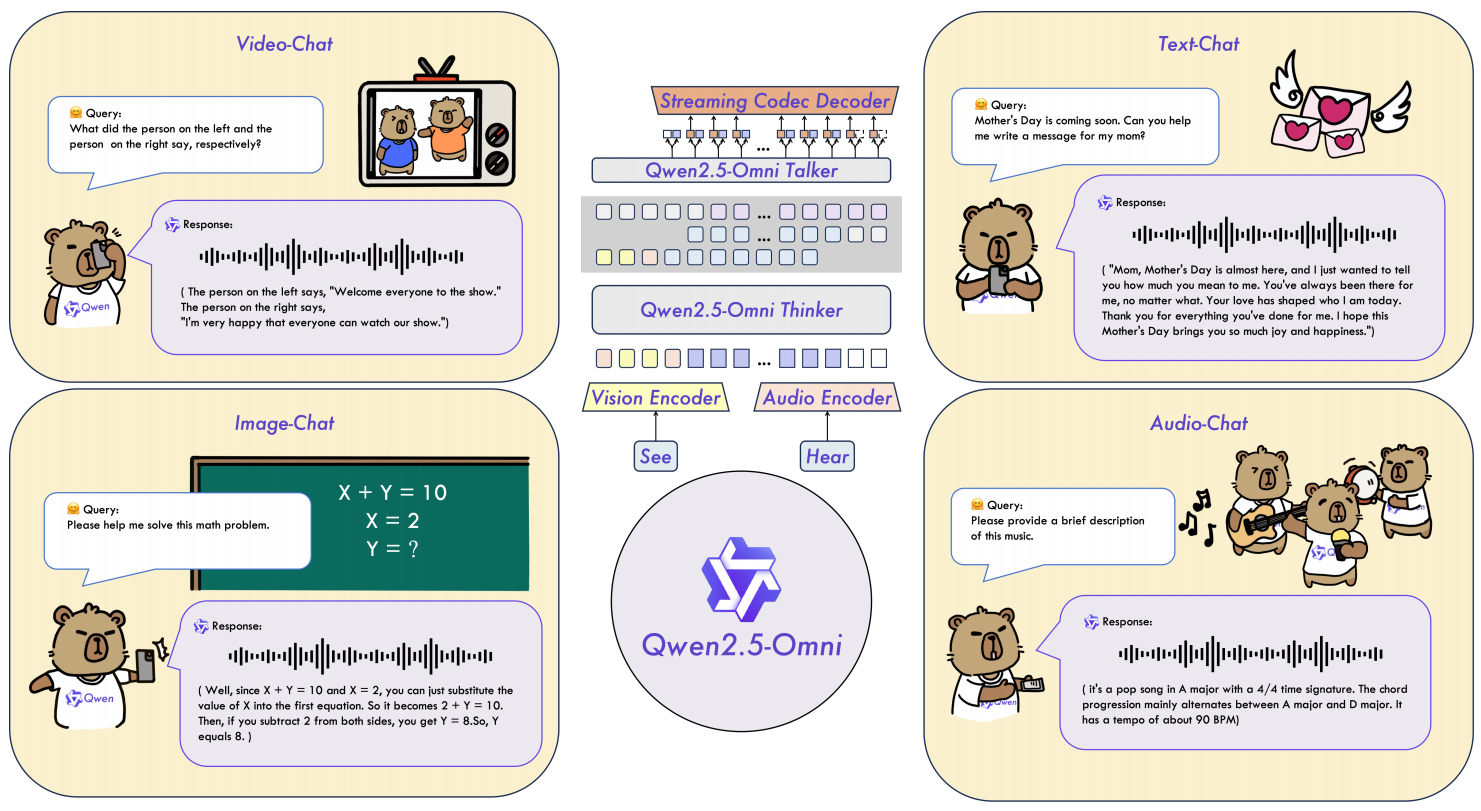
下图为Omni的应用场景概述图,主要思想就是让多模态数据(文字、图片、视频、音频)输入模型,然后通过文字大模型(Thinker)进行理解,然后配合语音大模型(Talker)进行语音输出。
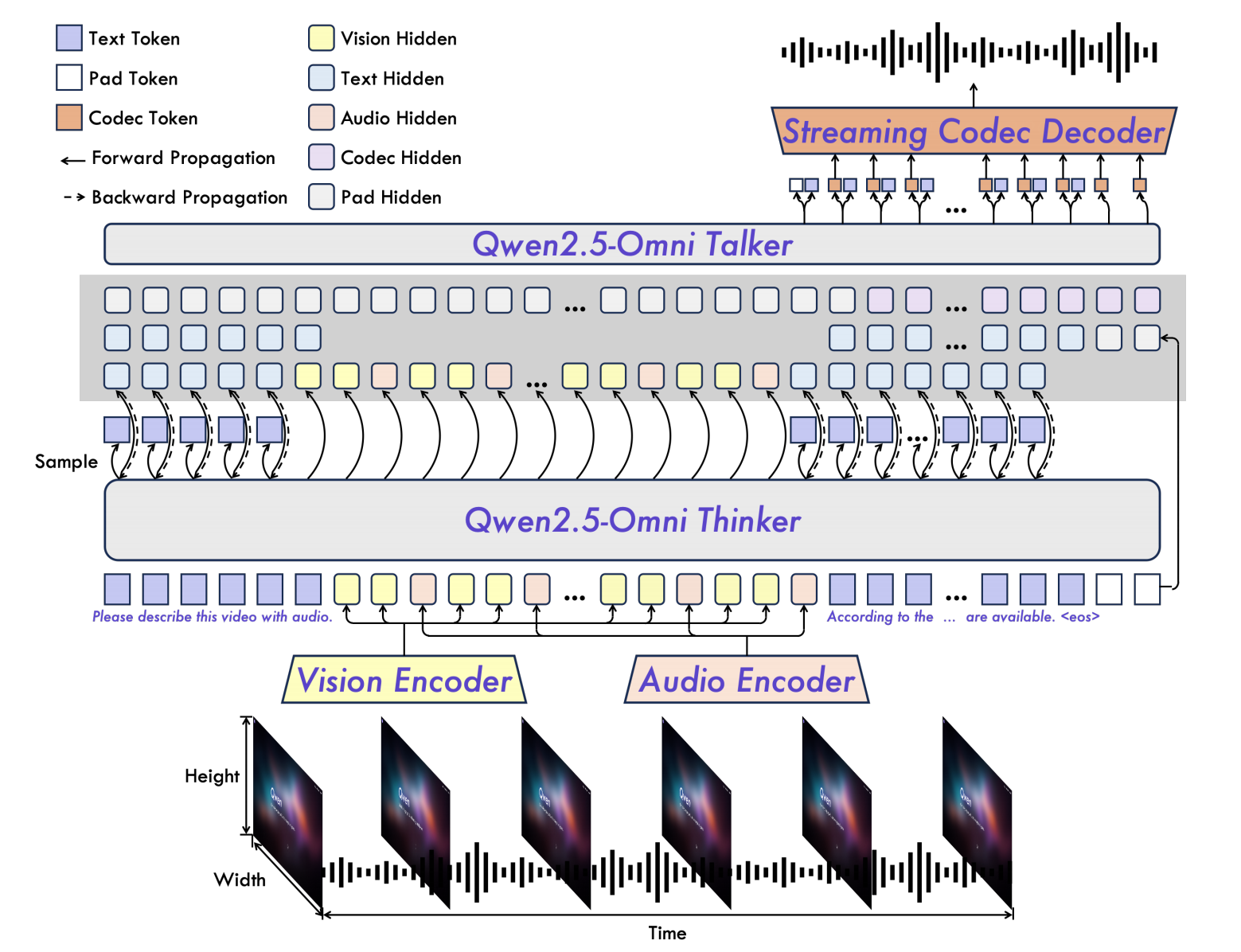
它的整体架构如下:
2 技术细节
2.1 输入数据处理
文本数据: 使用Qwen Tokenizer,分词算法为BBPE(byte-level byte-pair encoding),这是一个字节粒度的分词算法,同时词汇表大小为151,643。
视觉编码器: 使用Qwen2.5-VL的编码器,参数规模675M。
音频编码器: 提前将视频中的音频或者原始音频通过16kHz进行重采样,并且转换为窗口大小为25ms、步长为10ms的128通道的梅尔频谱图,使用Qwen2.5-Audio的编码器,每一帧音频对应于原始音频的大约40ms的一个片段。
2.2 TMRoPE(Time-aligned Multimodal RoPE)
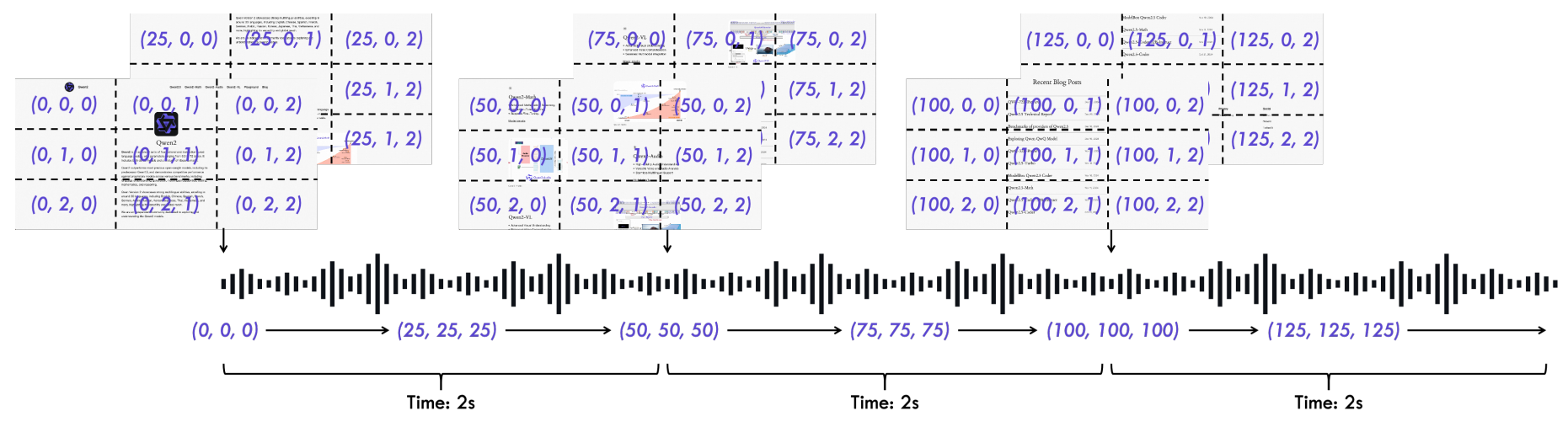
TMRoPE(时间对齐的多模态旋转位置嵌入)是一种新颖的位置编码方法,它将原始的旋转位置嵌入分解为时间、高度和宽度三个维度,并为不同模态(如文本、音频和视觉)提供不同的位置编码。在处理视频和音频时,算法会根据实际帧率动态调整时间位置编码,确保每个时间ID精确对应40毫秒。此外,为了同时处理视觉和听觉信息,算法采用了一种时间交错方法,将视频和音频的表示交错排列,使得模型能够同时接收和处理这两种模态的信息。
3D位置编码如下所示:
2.3 生成
从前面的架构图可以看到,Omni是通过Thinker来生成文本token和高维语义token传入到Talker中。所以Thinker实际上就是文本大语言模型,通过自回归采样生成token。
不过要注意,文本大模型生成的结果具备的是语义相似性,而不是语音和音素的相似性,也就是说,同一个词但不同语气在文本大模型输出的高维度token中的表示可能十分接近,不能区分,这也就导致这样的输出不能直接转化为语音输出,仍然需要多一个步骤来继续解析这些输出的token。
Talker是双轨自回归 Transformer 解码器架构,它与Thinker共享上下文,并且接受Thinker的生成内容,它自回归生成文本token和音频token,最后Qwen还设计了一种高效的语音编解码器 qwen-tts-tokenizer。qwen-tts-tokenizer 能够高效地表示语音的关键信息,并且可以通过因果音频解码器实时解码为语音流。
3 优化
3.1 分块预填充(Chunked-Prefills)
音频编码器:将长音频切分为2秒的块,逐块处理(而非全时长一次性处理),减少内存占用和计算量。
视觉编码器:使用Flash Attention加速计算,并通过MLP合并相邻的2×2图像块(类似下采样),支持不同分辨率图像的统一处理。
3.2 流式编解码生成(Streaming Codec Generation)
滑动窗口注意力:限制语音生成的上下文范围,仅关注当前块的相邻块(如“回看2块,前瞻1块”),降低计算复杂度。
Flow-Matching DiT模型:通过扩散模型(Diffusion Transformer)生成梅尔频谱图(语音的中间表示),再通过改进的BigVGAN(高质量声码器)将频谱图转换为波形(音频信号)。
分块生成:梅尔频谱图和音频波形均以分块方式生成,确保流式输出的同时保留必要上下文信息。

















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









