






2406.05835论文链接:2406.05835
背景与动机:
1.状态空间模型(SSM)的创新解决了Transformer带来的二次复杂度问题
2.SSM在图像处理中可能存在的局限性,如接收野不足和图像局域性问题
3.Mamba对于特定任务(如目标检测)的应用还未普遍流行
提出基于SSM的Mamba - YOLO,为YOLOs在目标检测方面建立了新的基线,为未来发展基于SSM的更高效、更有效的检测器打下了坚实的基础。ODSSBlock是基于SSM的自回归模型,能够有效地捕捉全局依赖关系;LSBlock则利用多层卷积和池化操作提取局部空间信息,弥补SSM在处理图像中的不足;而RGBlock则是将高维表达和残差连接相结合,有效地捕获了局部依赖关系,进一步提高模型的性能和鲁棒性。
架构:
1.overview
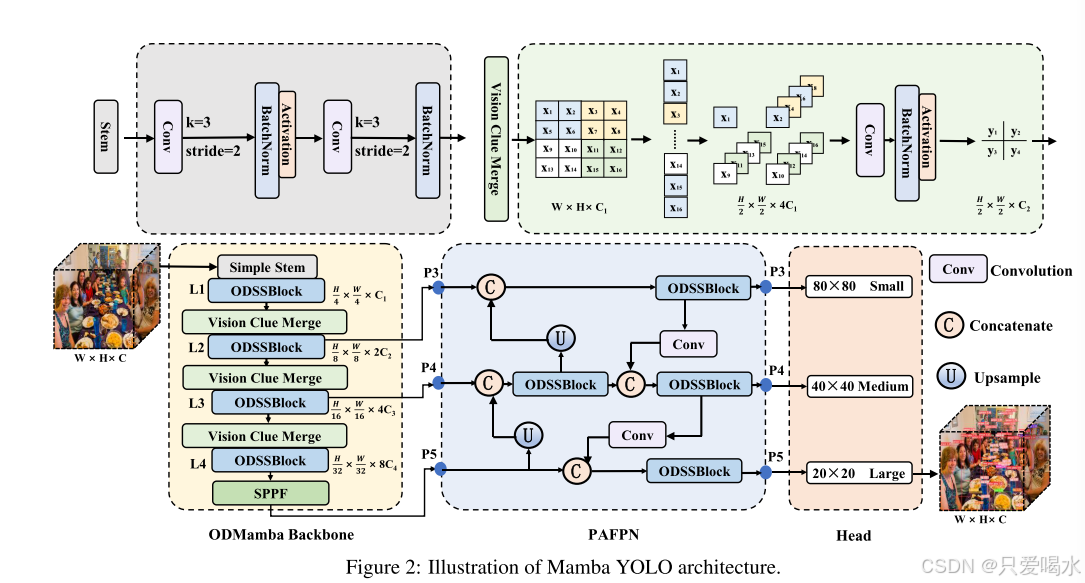
Mamba-YOLO目标检测模型由ODMamba骨干网络、PAFPN网络结构及Head检测头组成
ODMamba骨干网络:输入图片首先通过Simple Stem模块进行下采样,得到分辨率为H/4×W/4的2D特征图,随后经过串联的ODSSBlock和Vision Clue Merge模块,用于提取图像特征。
PANFPN网络结构:在Neck部分,采用了PAFPN的设计,并且用ODSSBlock代替原有结构的C2f模块,结构中还包含上采样的Upsample,单独负责下采样的Convolution(stride=2),该部分用于融合和细化不同尺度的特征,增强模型对于各种尺度物体的检测能力,尤其是在多尺度目标检测任务中非常有效。
Head检测头结构:检测头部结构分为3层,分别为80*80小尺度目标检测层、40*40中尺度目标检测层、20*20大尺度目标层。
2.ODSSBlock
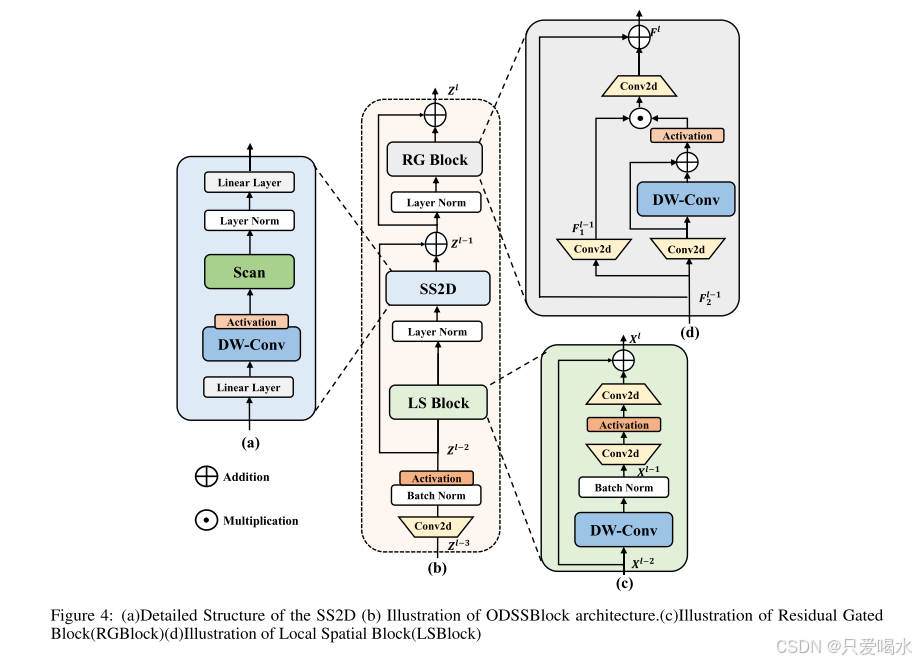
ODSSBlock是Mamba-YOLO的核心模块,该模块主要包含LSBlock、RGBlock、SS2D三个模块。在输入阶段经过一系列处理,可以使网络能够学习到更深入、更丰富的特征表示,同时通过批处理归一化保持训练推理过程的高效和稳定。ODSSBlock的批归一化、层归一化和残差连接设计允许模型在深层堆叠训练时有效流动。

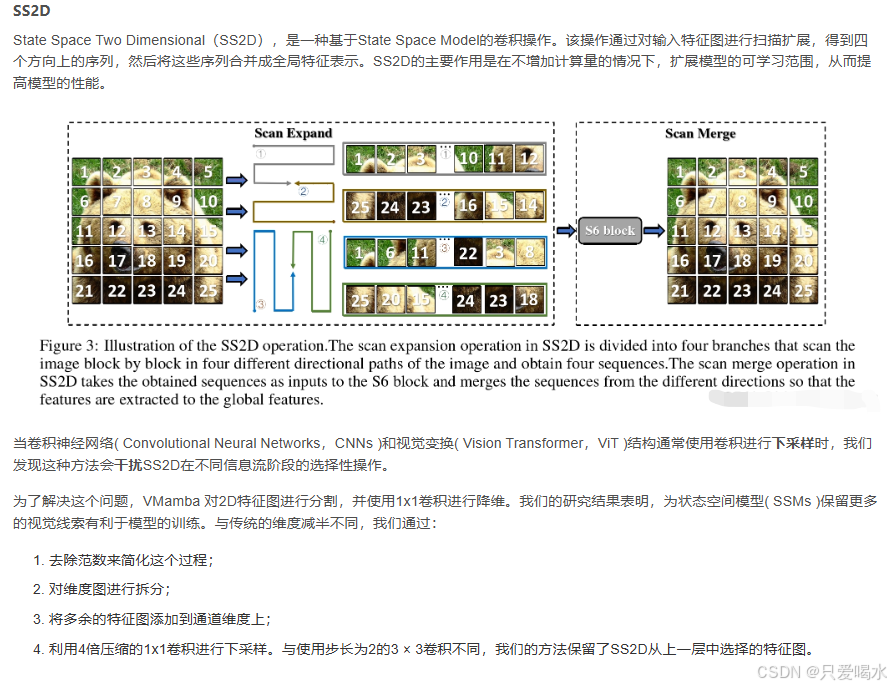
实验
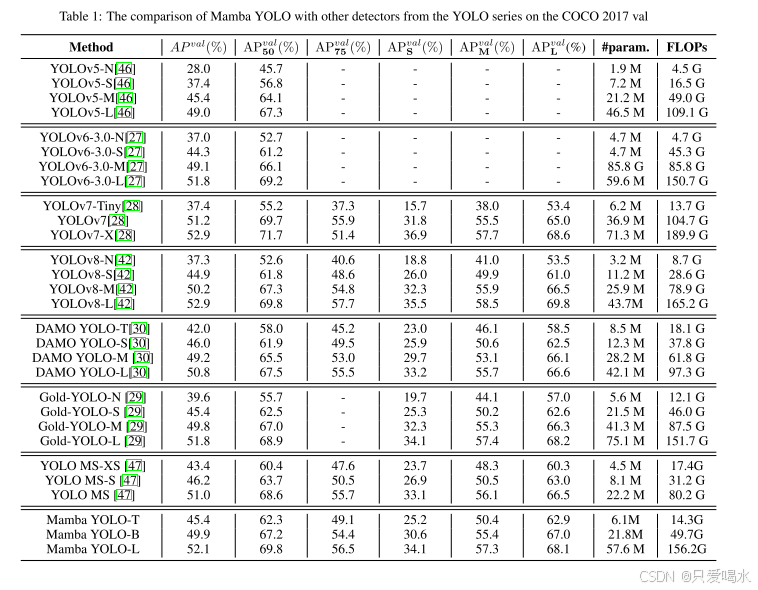
1.Main
COCO2017训练数据集上进行训练300个ehpoc,并在COCO2017val数据集上进行验证。
2.Ablation
1.Mamba YOLO改进点的消融研究
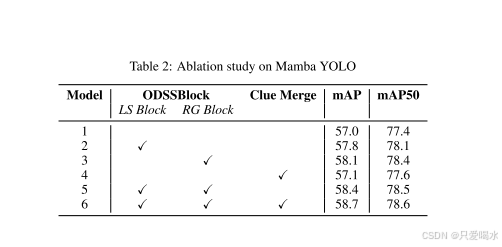
2.RGBlock结构的消融研究
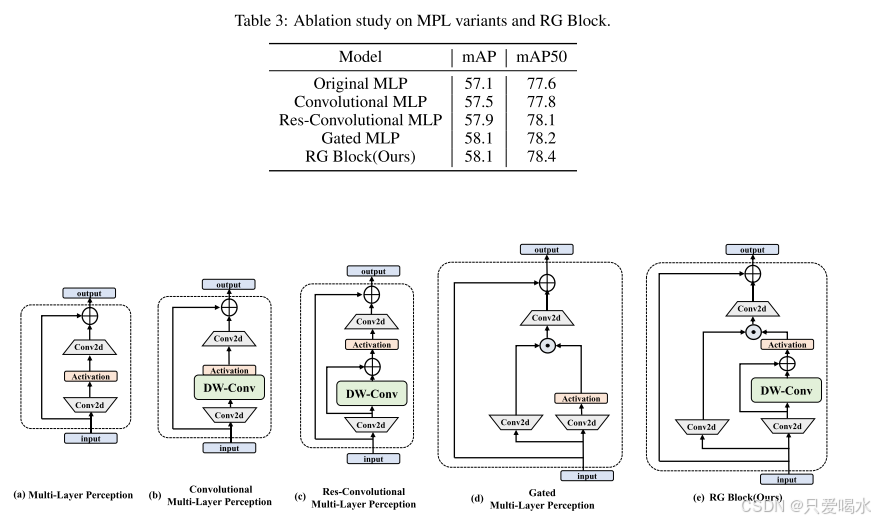
总结
一种新的检测器模型Mamba-YOLO,将状态空间模型(SSM)引入到实时目标检测领域,并结合了当前最先进的YOLO系列算法的优点。具体来说,作者提出了ODSSBlock模块来应用SSM结构,同时设计了LSBlock和RGBlock两个新模块来增强模型的局部特征捕捉能力和通道表达能力。实验结果表明,Mamba-YOLO在PASCAL VOC和COCO数据集上表现出了比现有最先进算法更高的mAP值。 此外,该论文还对该领域的其他相关研究进行了综述和比较,展示了Mamba-YOLO的独特性和优越性。未来,还可以运用到如自动驾驶、智能安防等领域中。
复现:
1.按照reademe安装环境(CUDA最好是12.x以上)
2.环境安装好之后,修改ultralytics/cfg/datasets/coco.yaml文件,修改为你自己的数据集地址

3.coco官方数据集给的是annonation注释,需要转换为yolo格式
import os
import json
import cv2
from PIL import Image
def convert_coco_to_yolo(coco_annotation_path, image_dir, output_dir):
# 读取 COCO 注解文件
with open(coco_annotation_path, 'r') as f:
coco_data = json.load(f)
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 构建类别 ID 映射
category_map = {cat['id']: cat['name'] for cat in coco_data['categories']}
category_ids = list(category_map.keys())
category_names = list(category_map.values())
# 构建类别 ID 到 YOLO 类别 ID 的映射
yolo_category_map = {category_id: idx for idx, category_id in enumerate(category_ids)}
# 处理每个注解
for annotation in coco_data['annotations']:
image_id = annotation['image_id']
category_id = annotation['category_id']
bbox = annotation['bbox']
# 找到对应的图像信息
image_info = next((img for img in coco_data['images'] if img['id'] == image_id), None)
if image_info is None:
continue
image_filename = image_info['file_name']
image_width = image_info['width']
image_height = image_info['height']
# 计算 YOLO 格式的边界框
x, y, width, height = bbox
x_center = (x + width / 2) / image_width
y_center = (y + height / 2) / image_height
width = width / image_width
height = height / image_height
# 构建 YOLO 格式的注解行
yolo_line = f"{yolo_category_map[category_id]} {x_center} {y_center} {width} {height}\n"
# 构建输出文件路径
base_name = os.path.splitext(image_filename)[0]
yolo_file_path = os.path.join(output_dir, f"{base_name}.txt")
# 写入 YOLO 格式的注解
with open(yolo_file_path, 'a') as f:
f.write(yolo_line)
print("转换完成!")
if __name__ == "__main__":
# 设置路径
coco_annotation_path = '/media/dell/DATA/coco2017/annotations/instances_train2017.json' # 替换为你的 COCO 注解文件路径
image_dir = '/media/dell/DATA/coco2017/images/train2017' # 替换为你的 COCO 图像文件夹路径
output_dir = '/media/dell/DATA/coco2017/labels/train2017' # 替换为你希望输出 YOLO 标签文件的文件夹路径
# 转换 COCO 数据集为 YOLO 格式
convert_coco_to_yolo(coco_annotation_path, image_dir, output_dir)4.出现如右报错 torch.cat(): expected a non-empty list of Tensors大多数是数据集结构路径不对
正确的数据集结构路径如下:
coco2017
----images
--------train
--------------图片
--------val
--------test
----labels
--------train
-------------train-img.txt
--------val
-------------val-img.txt
修改完之后就可以训练起来了,作者没有给出测试代码,只能在验证集上查看效果,当然300个ehpoc不是谁都有资源跑的(作者只跑了10个ephoc)。

















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









