






SuMa++: Efficient LiDAR-based Semantic SLAM
Lidar,surfel-based,Bonn University,Laval University,KITTI,2019
总结
可以当作是增加了语义信息的SuMa,为每个点云输出语义分割结果,使得建立的surfel地图包含丰富的语义,进而通过语义约束提高性能。
使用建图SUMA建图,使用RangeSeg++分割。主要工作集中于怎样将语义标签融合到地图中,以及如何使用语义信息过滤场景中的动态物体,有点类似于SemanticFusion,只不过SemanticFusion使用的是RGBD数据,而本文使用的是激光点云数据。(”RGBD的工作马上会在Lidar上被复现一遍“,师兄说的很有道理嘛)
本文贡献
- 将语义信息加入到surfel 地图中,在高动态场景下仍然能够精确的建图
- 提出了一种通过带语义标签的surfel地图来过滤动态目标的方法
方法介绍
结构总览:
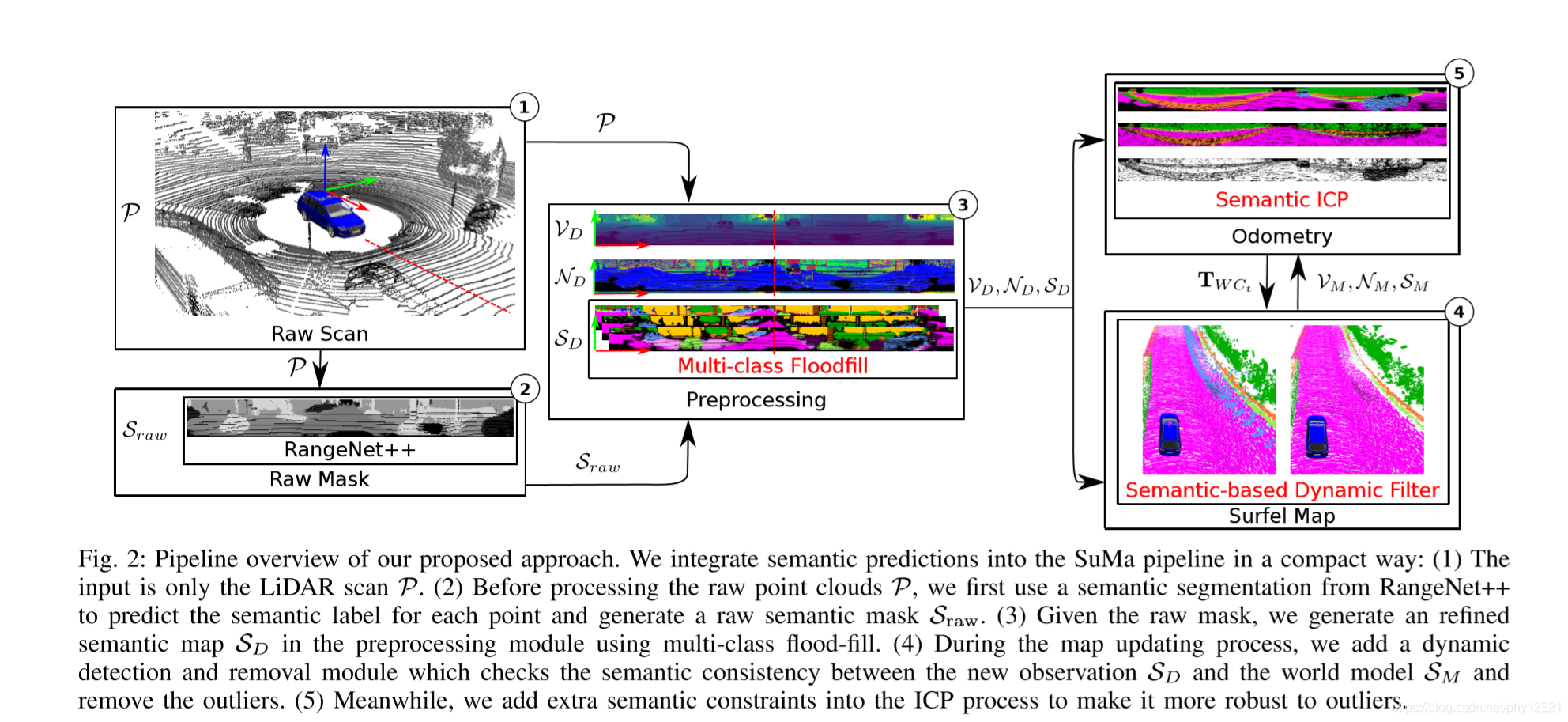
1.建图(surfel-based mapping,SuMa)
这个是用SuMa来做的,简单总结下:
- 在t时刻生成点云P的球形投影,即vertex map,然后用该图生成normal map Nd
- 通过t-1时刻的投影ICP,计算出t-1到t时刻的位姿变换矩阵,进而链式的计算出世界坐标与t时刻的位姿变换矩阵
- 同时做闭环检测保证地图的全局一致性
2.语义分割(RangeNet++)
这个是用RangeNet++来做的。
RangeNet++为每一帧的每个点云生成一个语义标签以及概率,得到语义地图。
- 用DarkNet53作为骨干网络构建SqueezeSeg 的结构
3.优化语义地图(flood-fill algorithm)
由于深度神经网络的降采样作用和 BIOB-like 输出,需要解决语义标签错误带来的问题,这里提出了 Flood-fill算法:
- 输入:RangeNet++的输出,即语义mask,以及对应的Vertex map(每个点投影在点云坐标系中的最近邻点云的坐标).
- 输出:优化后的语义mask
算法流程:
-
边界侵蚀:为了消除分割边界的模糊
在输入的语义mask中,如果某个点的固定邻域中有其他的点的语义标签与该点不同,则删除该点,得到侵蚀后的语义mask
-
将侵蚀的语义mask,与从Vertex map 中得到的深度图结合,得到Fill-in mask
-
最后,对于语义标签空白的点云(应该是第一步被移除的点云),如果其领域内有其他点,则把该空白点的标签置为其邻域内点的标签(边界噪声过滤)

效果展示:

4.根据语义滤除动态目标
根据当前时刻的观测与世界模型(之前观测的结果)的语义一致性来移除动态目标
具体的,加入了一个惩罚项来计算surfel面元的"稳定性"(通过不断更新每个surfel的稳定性因子L_s来衡量)
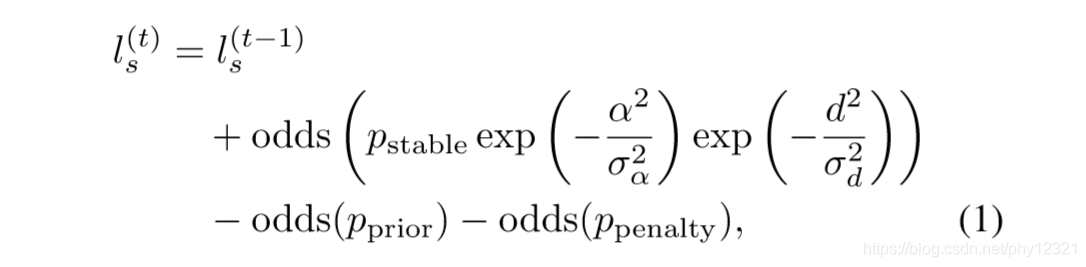
其中EXP 项是为了解释噪声
效果展示:
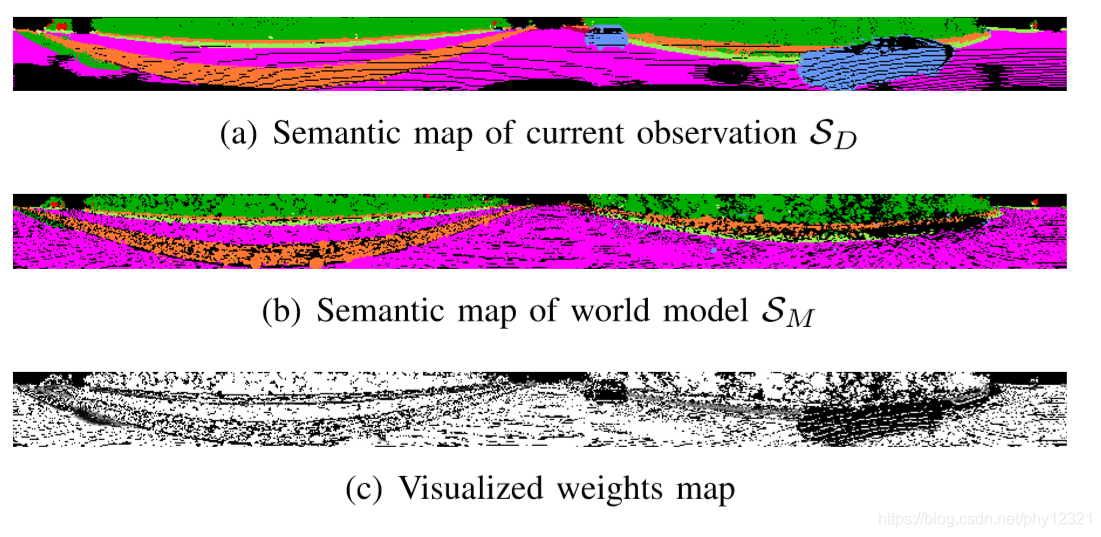
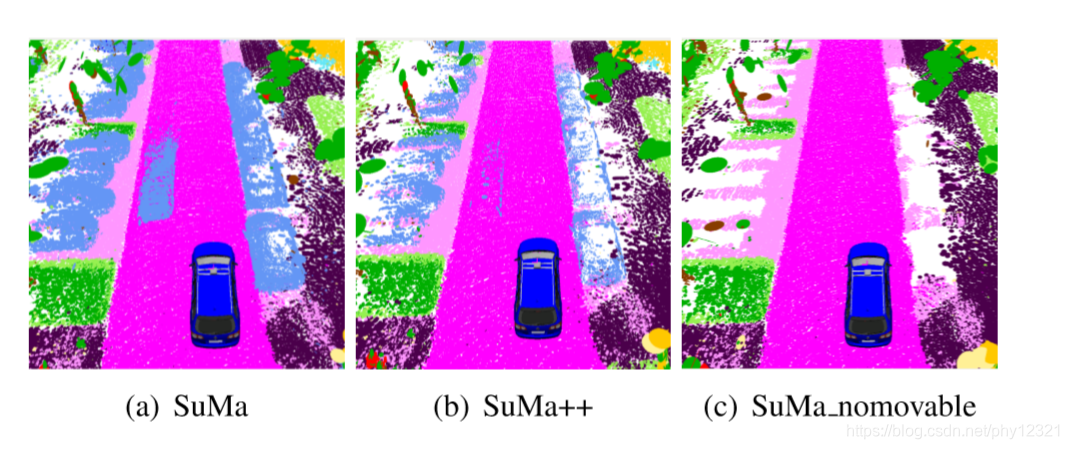 右边是SuMa 移除所有可能运动的物体的结果,文中提到这种做法会带来问题:在语义稀疏的场景静止的汽车包含丰富的特征点,在ICP配准时会有很大的帮助,移除之后可能会因为丢失对应点而导致配准失败
右边是SuMa 移除所有可能运动的物体的结果,文中提到这种做法会带来问题:在语义稀疏的场景静止的汽车包含丰富的特征点,在ICP配准时会有很大的帮助,移除之后可能会因为丢失对应点而导致配准失败
5.语义ICP
即加入了语义约束的ICP。
新的ICP误差函数:
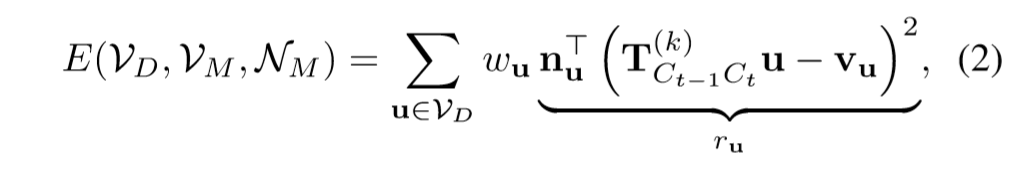
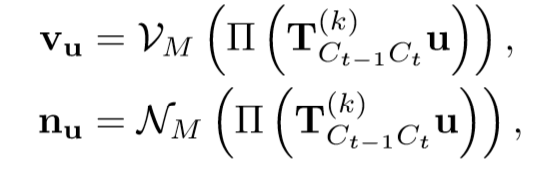
通过高斯牛顿法优化最小误差
效果展示:
可以看到在引入权重项后,右边的动态目标(汽车)被完美的移除
实验结果与分析
设计两个实验分别证明了本文工作的两个优越性:
- 在高动态的场景下仍然能够精确建图
- 相比于现有滤除动态物体的方法(移除所有有可能运动的物体,如静止的汽车),本文方法性能更佳
实验1: KITTI Road Sequences (目的:证明在高动态的场景下仍然能够精确建图)
由于不是里程计数据,所以在做分割时没有语义标签。

可以看到在高动态目标的场景中,SuMa由于没有语义信息,地图一致性被破坏,SuMa++则很好的维护了地图的一致性。
位姿估计错误对比:
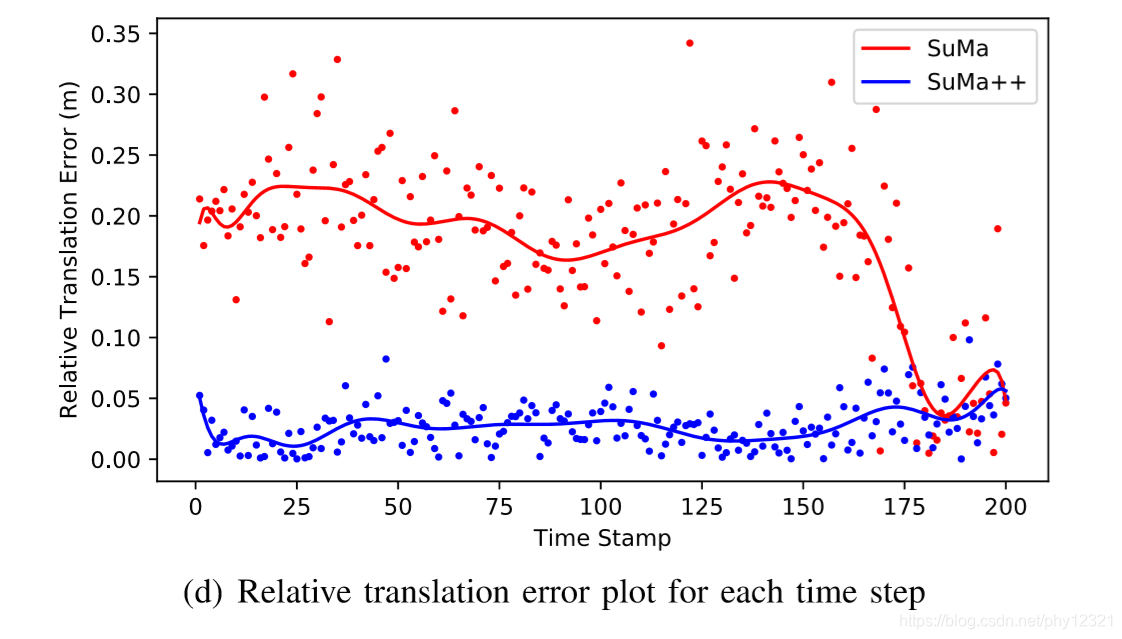
可以看出SUMA++的偏移量少了很多,说明在高动态场景中其位姿估计精度得到了很大提升
实验2: KITTI Odometry Benchmark (相比于现有滤除动态物体的方法 本文方法性能更佳) 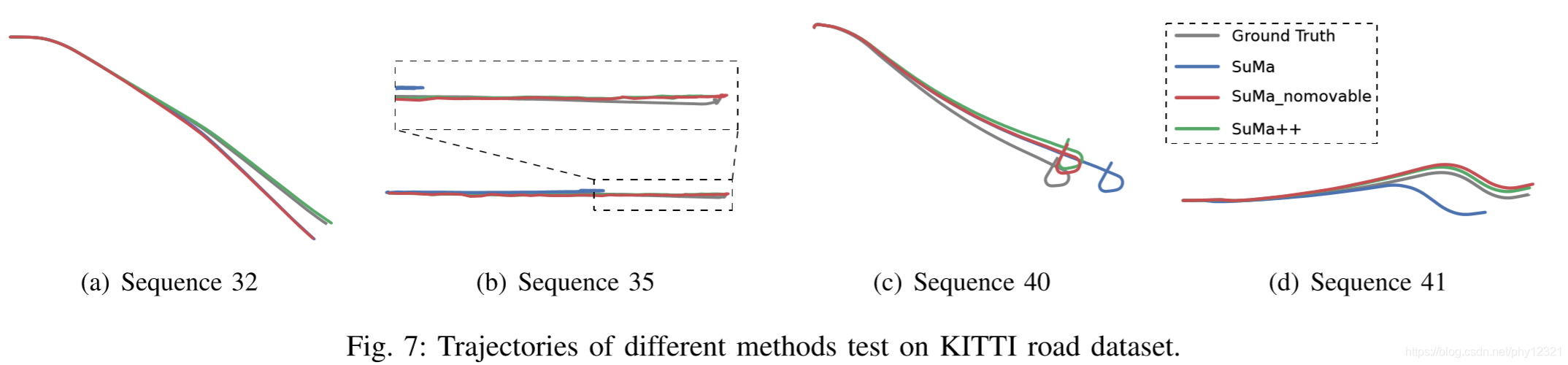
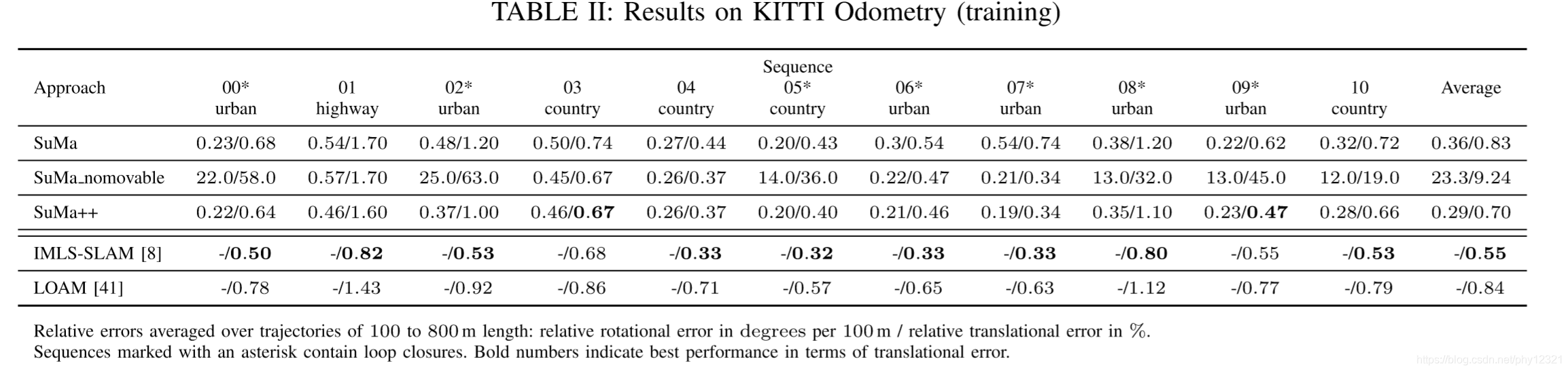
可以看出SUMA++ 相对于SUMA有一定的提升,相比于SOTA的工作,其性能相似(略低)。
论文针对相比SOTA,SUMA++性能持平和SUMA性能欠佳的现象分别做出了分析:
- SUAM++中语义标签并不都是全部正确的,导致一些surfel被错误的移除
- SUMA中移除所有可能移动的目标,使得一些有利的特征点也被移除
3.KITTI的测试数据集
unseen的数据集进行测试,性能相比SUMA:
average rotational error : 0.0032 deg/m
average translational error : 1.06%,
when compared to 0.0032 deg/m and 1.39% of the original SuMa
总结与讨论:
关于究竟要不要移除静止汽车这类目标的讨论。
以及本文方法的不足:在首次观测时不能识别物体是否是运动的(因为识别是靠两帧做比对以及语义标签进行的),目前是通过移除首帧的所有可能运动的物体来解决。
未来的研究方向
语义信息辅助闭环检测
细粒度的语义信息预测,例如车道结构,道路类型

















 1819
1819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









