







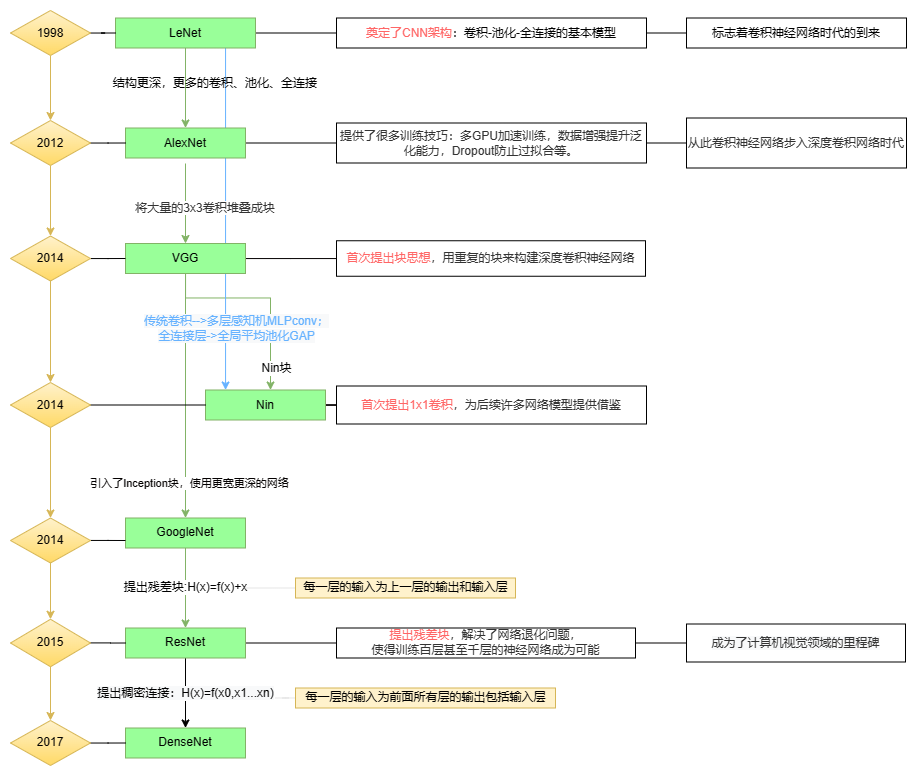
经典神经网络模型
文章目录
LeNet
论文:Gradient-based learning applied to document recognition
下载地址:https://www.et-fine.com/10.1109/5.726791
背景
LeNet是LeCun在1998年提出的用于解决手写数字识别任务的卷积神经网络模型,这一网络模型奠定了之后CNN的基本架构。它又被称为LeNet-5,5表示第5代版本。
结构
LeNet-5网络结构如下图:
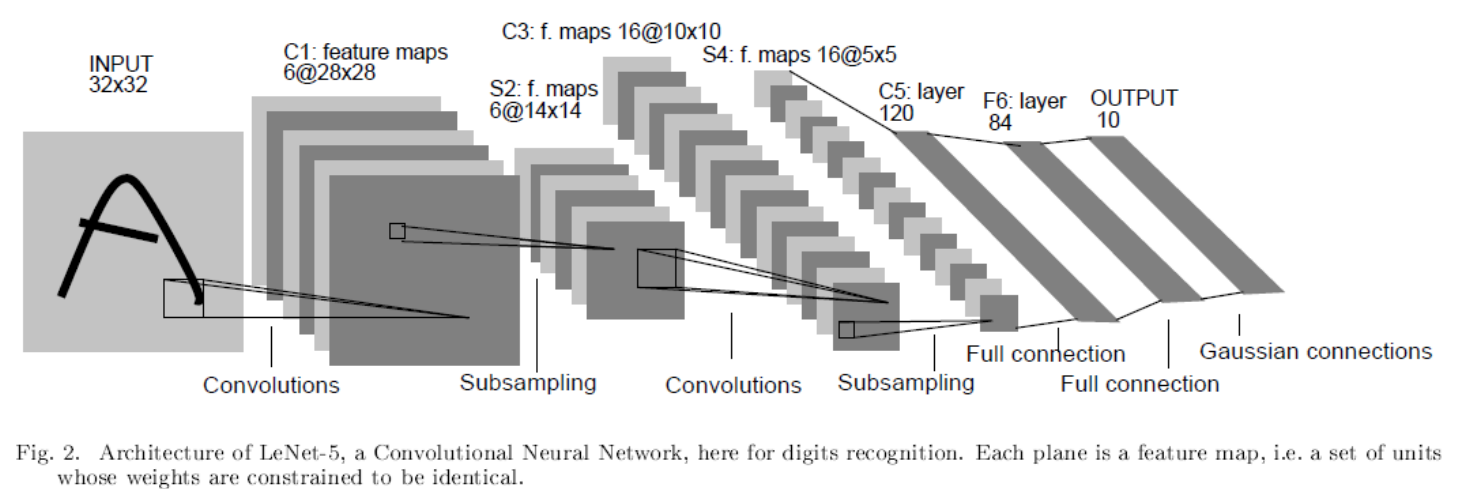
LeNet-5的基本结构是:卷积、池化、卷积、池化、全连接。

详解:
-
输入层:LeNet的输入是32x32x1大小的灰度图(只有一个颜色通道)。
-
CONV1(第一个卷积层):对大小为32x32x1的灰度图进行卷积,卷积核大小为5x5,步长s为1,卷积核个数为6,进行卷积操作后得到大小为28x28x6特征图(卷积后特征图大小:
output_size=(input_size-kernel_size+2*padding)/stride +1)。 -
第一个池化层:LeNet采用的是平均池化的方法,上层卷积得到的特征图尺寸为28x28x6,对此大小特征图进行池化操作。池化核大小为2x2,步长s=2,进行第一次池化后特征图大小为14x14x6(池化后特征图大小不会同样自行百度,卷积和池化得到特征图的公式基本是一致的)。
-
CONV2(第二个卷积层):对池化得到的14x14x6大小的特征图进行第二次卷积,卷积核大小为5x5,步长s为1,卷积核个数为16,进行卷积后得到大小为10x10x16的特征图。
-
第二个池化层:池化核大小为22,步长s=2,进行第二次池化后特征图大小为55x16。
-
第一个全连接层:上一步得到的特征图尺寸是5x5x16,经过这层后输出大小为120x1。为什么一个三维的向量一下子就变成了一个一维的?其实在得到5x5x16的特征图后,还要进行一个flatten(展平)操作,即是将5x5x16的特征图展开成一个(5x5x16)x1=400x1大小的向量,然后再进入到全连接层。即在第一个全连接层我们输入的是400个神经元,输出是120个神经元。
-
第二个全连接层:和上一层类似,输入的是120个神经元,输出的是84个神经元。
-
输出层:从得到84个神经元后,其实再经过一个全连接就得到输出,大小为10*1。
代码
源码
import torch.nn as nn
import torch.nn.functional as F
# 定义 LeNet-5 模型
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 定义卷积层C1,输入通道数为1,输出通道数为6,卷积核大小为5x5,步长为1
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1)
# 定义池化层S2,池化核大小为2x2,步长为2
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
# 定义卷积层C3,输入通道数为6,输出通道数为16,卷积核大小为5x5
self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1)
# 定义池化层S4,池化核大小为2x2,步长为2
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
# 定义全连接层F5,输入节点数为16x4x4=256,输出节点数为120
self.fc1 = nn.Linear(16 * 4 * 4, 120)
# 定义全连接层F6,输入节点数为120,输出节点数为84
self.fc2 = nn.Linear(120, 84)
# 定义输出层,输入节点数为84,输出节点数为10
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(6, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
李沐
(更好理解)
总体来看,(LeNet(LeNet-5)由两个部分组成:)
- 卷积编码器:由两个卷积层组成;
- 全连接层密集块:由三个全连接层组成。
每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。请注意,虽然ReLU和最大汇聚层更有效,但它们在20世纪90年代还没有出现。每个卷积层使用 5 × 5 5\times 5 5×5卷积核和一个sigmoid激活函数。这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。每个 2 × 2 2\times2 2×2池操作(步幅2)通过空间下采样将维数减少4倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量。
通过下面的LeNet代码,可以看出用深度学习框架实现此类模型非常简单。我们只需要实例化一个Sequential块并将需要的层连接在一起。

import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
#原输入是32*32,但mnist数据集的图片都是28*28,为了得到28*28*6的输出,故将这里加一个padding=2
#虽然ReLU和最大汇聚层更有效,但它们在20世纪90年代还没有出现,所以这里用的是sigmoid
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
贡献
LeNet的主要贡献:奠定了之后的CNN架构,无论何种CNN模型都逃不出卷积/池化/全连接(非线性激活函数)的基本模式,标志着卷积神经网络时代的到来。
AlexNet
论文:ImageNet Classification with Deep ConvolutionalNeural Networks
背景
LeNet在早期的小规模数据集上表现还不错,一些机器学习方法(支持向量机等)也能与之掰掰手腕。LeNet面临的主要问题是神经网络的深度不够,这受限于当时的硬件条件。2000年后,通用GPU的概念被提出。GPU擅长矩阵计算,最初的用途是计算机图形学的相关计算。2010年后,GPU开始被广泛用在机器学习领域。2012年,Alex Krizhevsky提出了AlexNet,凭借top5-15.3%的误差率在当年ImageNet图像分类大赛获得冠军。从这一年开始,卷积网络的深度越来越深。AlexNet的深度为8层,包括:5个卷积层,3个全连接层。
结构
AlexNet的网络结构如下图所示:
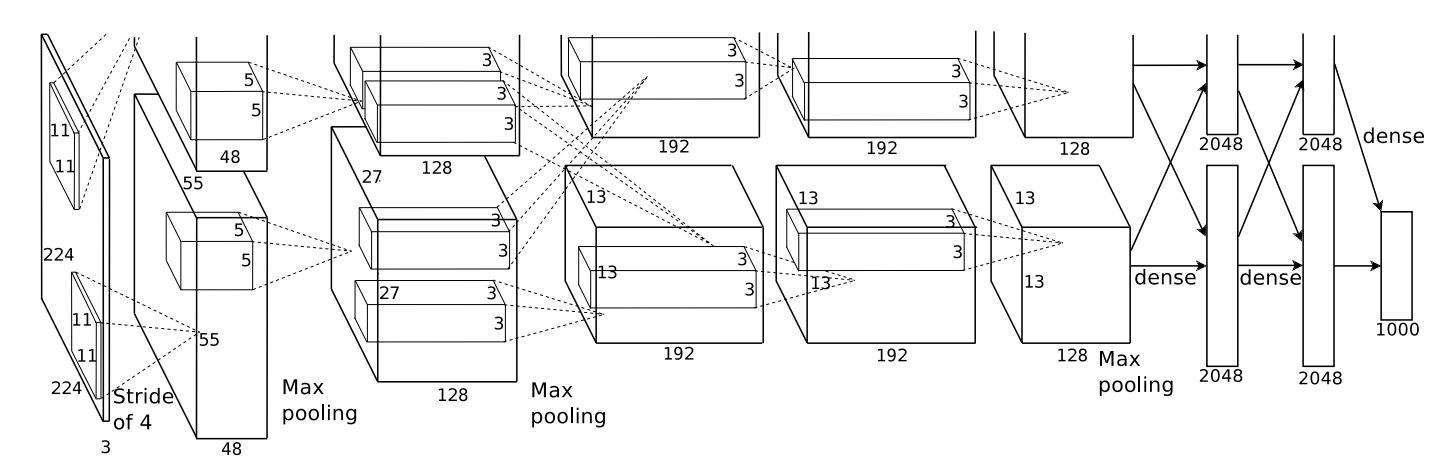
值得注意的是作者Alex采取了两块GPU来训练,因此出现了上图中两个“并行的”计算过程。两块GPU的计算同时进行,整体上实现了特征图通道数加倍的效果。以第一层为例:输入图片尺寸为224x224x3,分别经过上下5x5x48的卷积核后得到55x55x48的特征图,因此这一层的输出特征图尺寸为55x55x96.因为现在计算条件比以前好太多,我们在实现AlexNet的时候不需要分两块GPU计算,直接选择5x5x96的卷积核即可。不过,这个思路值得学习。
结构详解:
- 输入层:AlexNet的输入是224x224x3大小的彩色图片(有三个颜色通道)
- 第一个卷积层:对大小为227x227x3的彩色图片进行卷积,卷积核大小为11x11,步长s为4,padding=0,卷积核个数为96,进行卷积后得到大小为55x55x96的特征图。
- 第一个池化层:xxAlexNet采用的是最大池化的方法。上层卷积得到55x55x96的特征图,对此特征图进行最大池化操作。池化核大小为3x3,步长s为2,padding=0,经池化后特征图大小为27x27x96。
- 第二个卷积层:输入维度为27x27x96,卷积核大小为5x5,步长s为1,padding=2,卷积核个数为256,进行卷积后得到大小为27x27x256的特征图。
- 【注1:为什么这里的步长s=1,padding=2 ?这里就涉及到卷积的三种模式了,我们可以设置特定的s和padding来达到卷积前后特征图前两个维度大小不变的效果】
- 【注2:看到上图此步卷积时写有same,则表示卷积的方式是same mode,也即卷积前后特征图大小相同】
- 第二个池化层:输入维度为27x27x256,池化核大小为3x3,步长s为2,padding=0,经池化后特征图大小为13x13x256。
- 第三个卷积层:输入维度为13x13x256,卷积核大小为3x3,步长s为1,padding=1,卷积核个数为384,进行卷积后得到大小为13x13x384的特征图。
- 第四个卷积层:输入维度为13x13x384,卷积核大小为3x3,步长s为1,padding=1,卷积核个数为384,进行卷积后得到大小为13x13x384的特征图。
- 第五个卷积层:输入维度为13x13x384,卷积核大小为3x3,步长s为1,padding=1,卷积核个数为256,进行卷积后得到大小为13x13x256的特征图。
- 第三个池化层:输入维度为13x13x256,池化核大小为3x3,步长s为2,padding=0,经池化后特征图大小为6x6x256。
- 第一个全连接层:输入的是6x6x256=9216个神经元,输出的是4096个神经元。
- 第二个全连接层:输入的是4096个神经元,输出的是4096个神经元。
- 输出层:得到4096个神经元后,其实再经过一个全连接就得到输出,大小为1000x1。
AlexNet VS LeNet
AlexNet和LeNet的架构非常相似,如 :numref:fig_alexnet所示。 注意,本书在这里提供的是一个稍微精简版本的AlexNet,去除了当年需要两个小型GPU同时运算的设计特点。
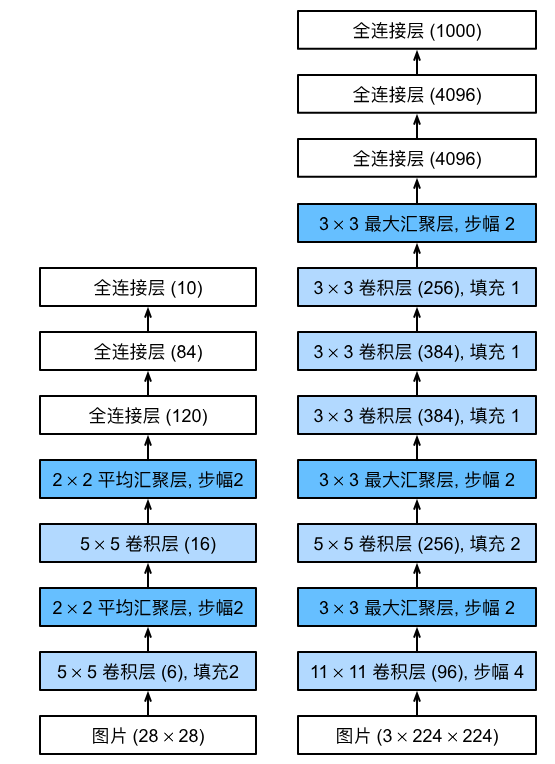
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
- AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet使用ReLU而不是sigmoid作为其激活函数。
下面的内容将深入研究AlexNet的细节。
创新
-
网络增大( 5Conv(3maxpool) + 3fc )
-
数据增广(Data Augmentation):水平翻转、随机裁剪、平移变换、颜色、光照变换;
-
Dropout抑制过拟合
-
ReLU减少梯度消失
-
LRN(局部响应归一化 )归一化层的使用【此方法在之后的VGG中被认为是无效的】
-
带动量的随机梯度下降
-
百万级ImageNet图像数据,GPU实现
代码
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
贡献
AlexNet的主要贡献:1)从此卷积神经网络步入深度卷积网络时代。2)提供了很多训练技巧:多GPU加速训练,数据增强提升泛化能力,Dropout防止过拟合等。
ZFNet
ZFNet的网络结构和AlexNet的结构基本是一致的,主要的改变就是在AlexNet的第一层将卷积核的大小由1111变成了77,并且将步长s由4变成了2。既然ZFNet相比于AlexNet只改变了这么点,那为什么要讲这个结构呢。这是我觉得ZFNet更宝贵的是提出了一种逆变换的思想来可视化了神经网络,将卷积核变小也是因为可视化而产生的结论,即小卷积核使网络效果更好。

VGG
背景
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员在2014年一起研发的深度卷积神经网络。VGGNet的论文中对很多的网络结构做对比(主要表现在网络的层数不同),具体如下图所示:
Alexnet是在Lenet上扩展的更深更大的网络,Vgg借用这种思想,将大量的3x3卷积堆叠成块,
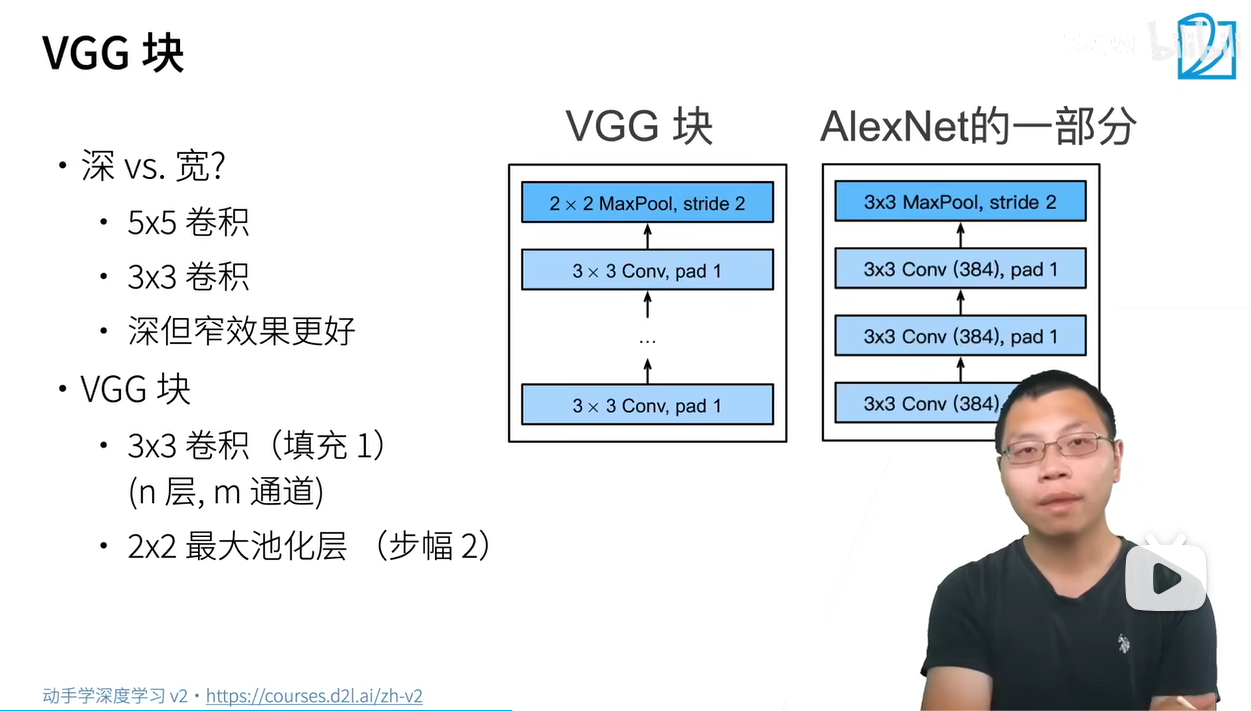
多个VGG块后接全连接层,不同次数的重复块得到不同的架构VGG-16,VGG-19
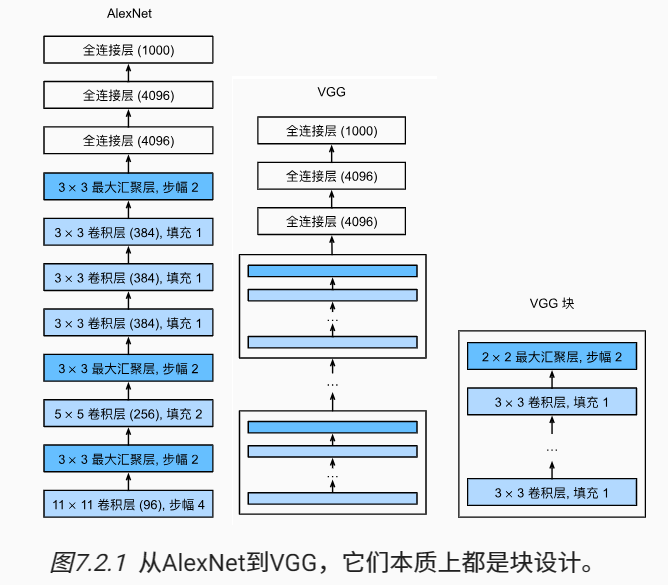
总结
- VGG使用可重复使用的卷积块来构建深度卷积神经网络;
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
创新点
1.用三个3×3的卷积核代替7×7的卷积核,有的FC层还用到了1×1的卷积核以及2×2的池化层。网络更深,增加了CNN对特征的学习能力。
2.在更深的结构中没有用到LRN(推翻了Alex),避免了部分内存和计算的增加。
3.VGG采用的是一种Pre-training的方式,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
4.采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率 。
Nin
论文: Network In Network (dosf.top)
2013年末,ICLR接收了来自NUS的这篇《Network In Network》。本文提出的NiN模型在结构上大胆创新,超越了当年的SOTA。
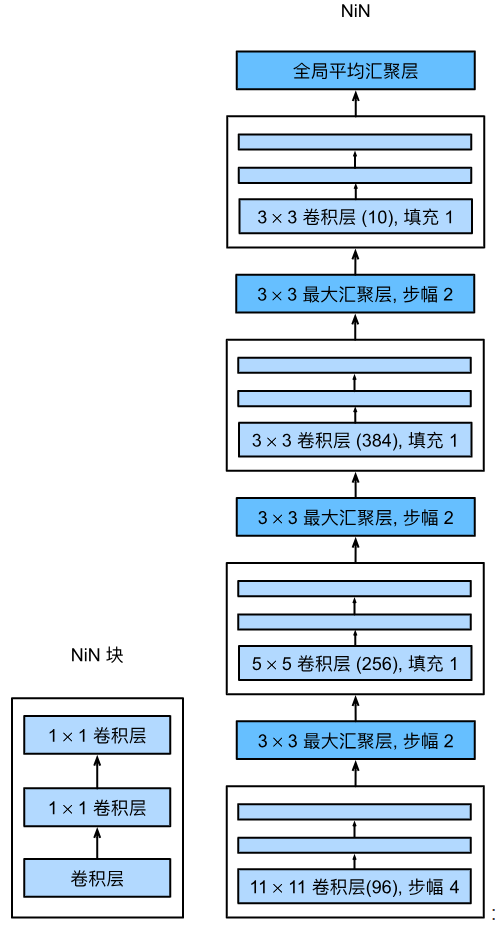
NiN的创新体现在两方面:1.采用多层感知器(MLPconv)代替传统卷积,取得了很好的效果;2.采用全局平均池化(GAP)来代替传统全连接层,从而实现抗过拟合。NiN网络的整体架构图如下:
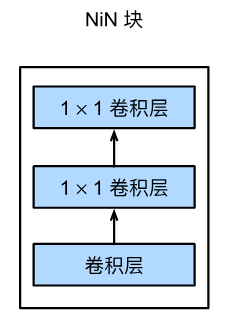
多层感知器(MLPconv)
传统卷积由卷积层和池化层交替组成,所谓多层感知器,就是在已有的卷积层后多加了1x1卷积,这1x1卷积后续被证明是很有效的。一方面1x1卷积可以在不改变特征图长宽的情况下改变通道数,并可以大幅度减少参数数量,另一方面1x1卷积也显著提升了卷积层提取特征的能力。
全局平均池化(GAP)
全局平均池化:将特征图的一个通道的全局平均作为某个输出节点的置信度。这样一来,就摆脱了全连接层广受诟病的“黑盒模式”,增强了网络的可解释性。但是也带来了问题:模型更难迁移和训练。GAP只能说是结构上的一次大胆尝试,并没有撼动全连接层的地位。总体来说,NiN某种程度上是把原本处于最后一层的全连接层给提前到了前面的卷积层中,从而增强了CNN提取特征的能力。
为什么用GAP?
为了展现GAP的优点,作者将GAP与传统CNN中的全连接层做了一个对比:
我们知道,传统的CNN网络中,前面堆叠的卷积层用于提取特征,而最后接的全连接层负责分类提取出的特征。但是全连接层很容易导致模型过拟合,过拟合就会导致模型的泛化性能差,泛化性能差准确性就会差,针对这个问题后来有了dropout,我们知道dropout可以有效的减轻过拟合,所以AlexNet拿下了2012年ImageNet竞赛的冠军。于是作者感觉到了避免过拟合对提升模型性能的重要性,换了一个清奇的思路:不在全连接层的基础上搞了,给它直接换成全局平均池化(GAP)!
作者告诉我们,全局池化是有很多优点的。一是很大程度减少了参数的数量,因为我们知道传统的全连接层参数数量非常之多,作者创造性的直接用GAP替换掉全连接层,而GAP是没有需要学习的参数的!而且与此同时GAP还没有全连接层容易过拟合的缺点,简直完虐全连接层。其次,作者认为GAP更符合CNN的特点,这种特征图和类别一一对应的模式,加强了特征图与概念(类别)的可信度的联系,使得分类任务有了很高的可理解性。再者,对每个特征图进行全局取平均操作综合了空间信息,使得模型的鲁棒性更强了.
NiN的主要贡献:首次提出1x1卷积,为后续许多网络模型借鉴。
代码
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
参考:深度学习网络篇——NIN(Network in Network)_nin(network in network)模型的主要创新点是:-CSDN博客
GoogleNet InceptionV1
论文:Going deeper with convolutions
在2014年的ImageNet图像识别挑战赛(ILSVRC分类比赛)中,一个名叫GoogLeNet :cite:Szegedy.Liu.Jia.ea.2015的网络架构大放异彩。 GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。
Inception块
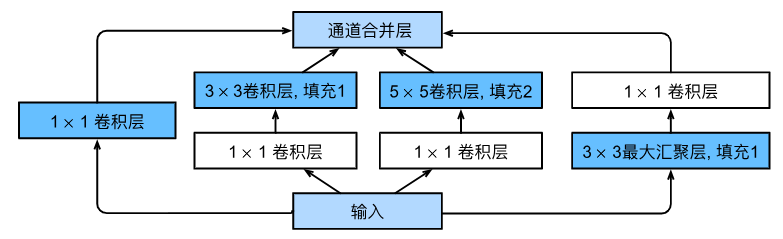
- Inception块由四条并行路径组成。
- 前三条路径使用窗口大小为 1 × 1 1\times 1 1×1、 3 × 3 3\times 3 3×3和 5 × 5 5\times 5 5×5的卷积层,从不同空间大小中提取信息。(之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding=0、1、2,那么卷积之后便可以得到相同维度的特征,方便最后拼接在一起)
- 中间的两条路径在输入上执行 1 × 1 1\times 1 1×1卷积,以减少通道数,从而降低模型的复杂性。
- 第四条路径使用 3 × 3 3\times 3 3×3最大汇聚层,然后使用 1 × 1 1\times 1 1×1卷积层来改变通道数。
- 这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
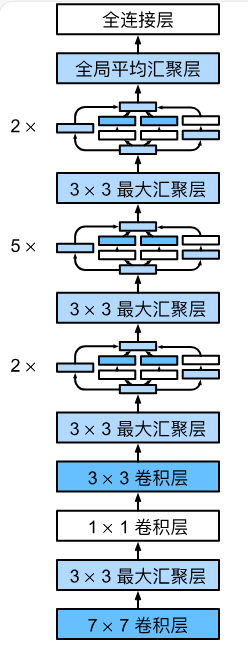
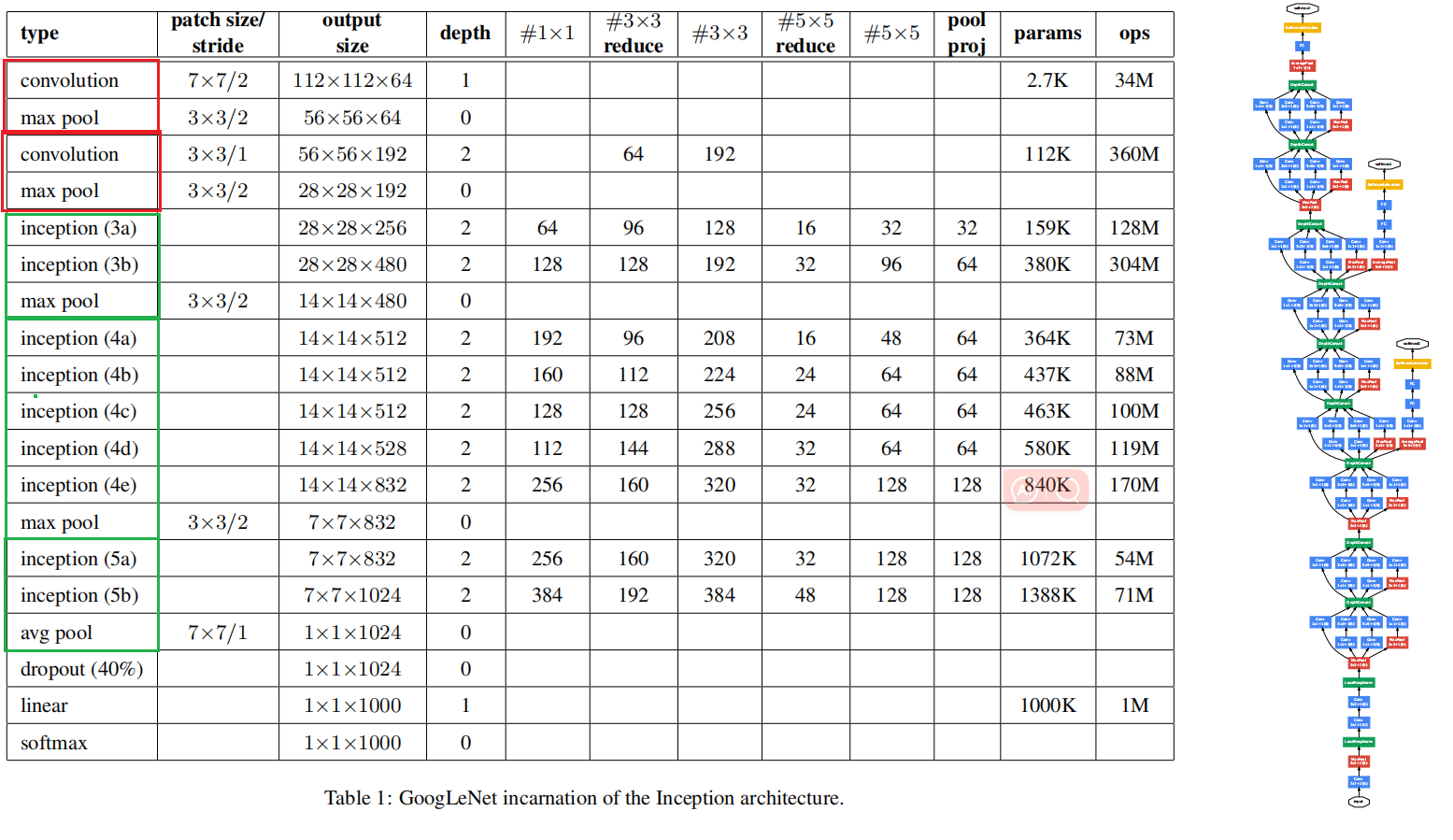
GoogLeNet模型
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
创新点
(1)引入了Inception,使用更宽更深的网络,提升网络性能;
(2)感受野的大小不同,获得不同尺度特征;
(3)用稀疏连接代替密集连接,减少计算资源需求;
(4)1*1的卷积核降维,提高计算资源利用率;
(5)添加两个辅助分类器帮助训练,避免梯度消失;
(6)后面的全连接层全部替换为简单的全局平均pooling**。**
代码
Inception块
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
googleNet模型
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
批量归一化

ResNet
论文:Deep Residual Learning for Image Recognition
背景
何恺明在2015年提出ResNet,一举获得了ILSVRC2015分类任务的第一名和CVPR2016最佳论文。ResNet使得训练百层甚至千层的神经网络成为可能,毫无疑问地成为了计算机视觉领域的里程碑。
之前深度学习网络中普遍存在的问题——随着网络层数的加深,网络训练结果并不能得到提升,反而会发生下降的问题,这种现象被称之为网络退化问题。
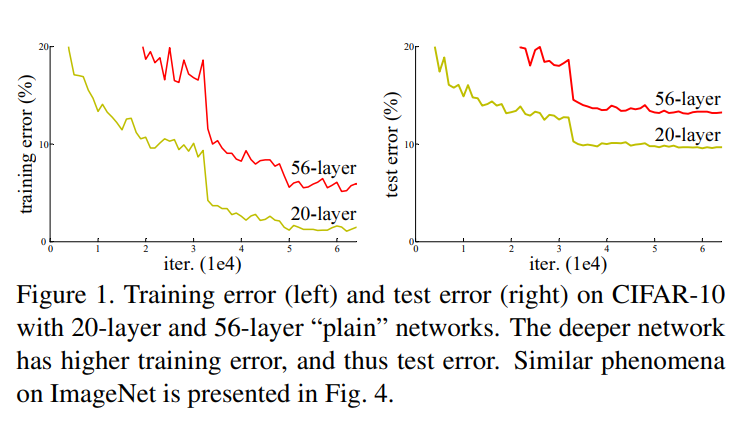
当发生网络退化问题后,人们一度认为深度学习就到这里为止了,直到ResNet的出现才解决了这一问题。
为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。这个网络结构的想法主要源于VLAD(残差的想法来源)和Highway Network(跳跃连接的想法来源)。
网络
ResNet的核心就是残差模块,下面主要来讲讲残差模块的设计。
在原论文中,残差路径可以大致分成2种,一种有bottleneck结构,即下面右图中的1×1 卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为“bottleneck block”,另一种没有bottleneck结构,如下图左所示,称之为“basic block”。basic block由2个3×3卷积层构成。
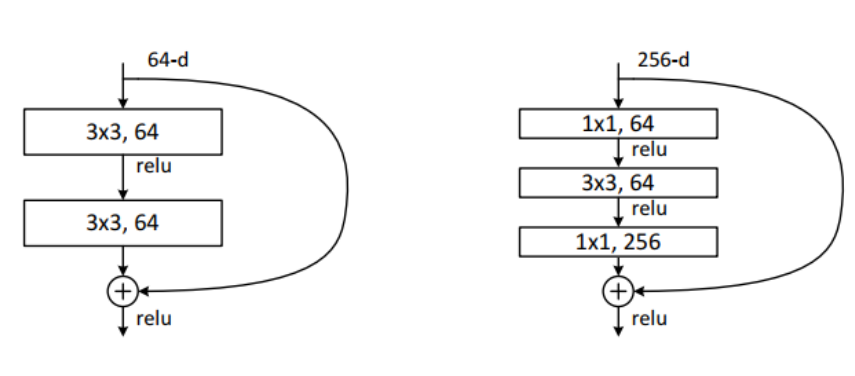
左边的残差结构适用于网络层数较浅的网络,也就是ResNet-34,右边的适用于ResNet-50/101/152。这个是进行一个相加操作,不是拼接操作
**残差模块:**一条路不变(恒等映射);另一条路负责拟合相对于原始网络的残差,去纠正原始网络的偏差,而不是让整体网络去拟合全部的底层映射,这样网络只需要纠正偏差。
**本质:**在ResNet中,传递给下一层的输入变为H(x)=F(x)+x,即拟合残差F(x)=H(x)-x
(1)加了残差结构后,给了输入x一个多的选择。若神经网络学习到这层的参数是冗余的时候,它可以选择直接走这条“跳接”曲线(shortcut connection),跳过这个冗余层,而不需要再去拟合参数使得H(x)=F(x)=x
(2)加了恒等映射后,深层网络至少不会比浅层网络更差。
(3)而在Resnet中,只需要把F(x)变为0即可,输出变为F(x)+x=0+x=x很明显,将网络的输出优化为0比将其做一个恒等变换要容易得多。
注意:如果残差映射(F(x))的结果的维度与跳跃连接(x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对x进行升维操作,让他俩的维度相同时才能计算。
升维的方法有两种:
- 全0填充;
- 采用1*1卷积
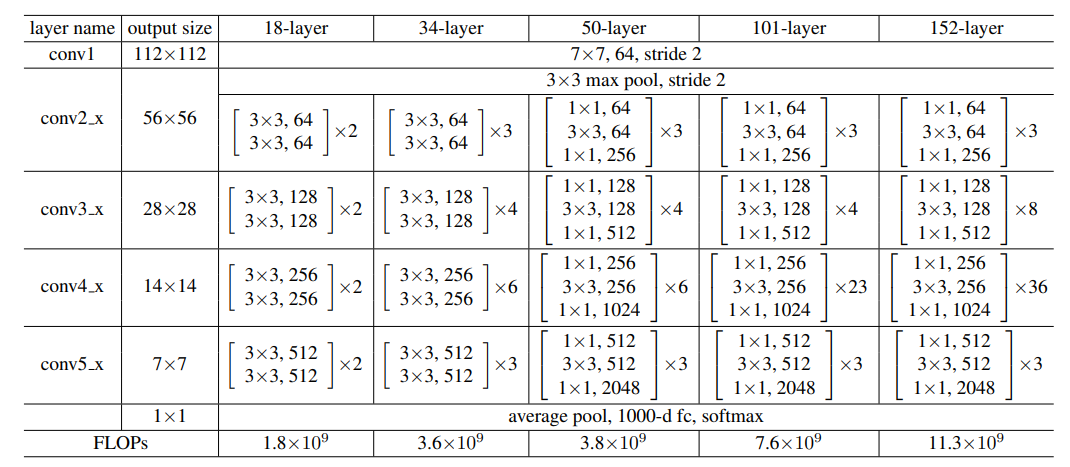
网络配置
创新点
(1)实现了超深的网络结构(突破1000层)
(2)提出了残差网络,将x直接传递到后面的层,使得网络可以很容易的学习恒等变换,从而解决网络退化的问题,同时也使得学习效率更高。
(3)使用BatchNormalization加速训练(丢弃dropout)
代码
import torch
import torch.nn as nn
def conv3x3(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1),
nn.BatchNorm2d(out_channels),
)
def conv1x1(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, 1),
nn.BatchNorm2d(out_channels),
)
class BasicNet(nn.Module):
def __int__(self, in_channel, out_channel, downsample=None):
super(BasicNet, self).__init__()
self.conv1 = conv3x3(in_channel, out_channel)
self.conv2 = conv3x3(out_channel, out_channel)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.relu(out)
out = self.conv2(out)
out = self.relu(out)
if self.downsample is not None:
identity = self.downsample(x)
out += x
out = self.relu(out)
return out
class BottleNet(nn.Module):
def __init__(self, in_channel, out_channel, extension=4, downsample=None):
super(BottleNet, self).__init__()
self.extension = extension
self.downsample = downsample
self.conv1 = conv1x1(in_channel, out_channel)
self.conv2 = conv3x3(out_channel, out_channel)
self.conv3 = conv1x1(out_channel, self.extension * out_channel)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.relu(out)
out = self.conv2(out)
out = self.relu(out)
out = self.conv3(out)
if self.downsample is not None:
identity = self.downsample(x)
out = out + identity
out = self.relu(out)
return out
class ResNet50(nn.Module):
def __init__(self, block, cnt, extension=4):
super(ResNet50, self).__init__()
self.pool1 = nn.MaxPool2d(2, 2)
self.pool2 = nn.MaxPool2d(3, 2)
self.relu = nn.ReLU(inplace=True)
self.extension = extension
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.layer1 = self._make_layers(block, 64, 64, cnt[0])
self.layer2 = self._make_layers(block, 256, 128, cnt[1])
self.layer3 = self._make_layers(block, 512, 256, cnt[2])
self.layer4 = self._make_layers(block, 1024, 512, cnt[3])
self.pool3 = nn.AvgPool2d(7 * 7 * 2048)
self.fc = nn.Linear(7*7*2048, 1000)
def forward(self, x):
out = self.conv1(x)
out = self.pool2(out)
out = self.relu(out)
out = self.layer1(out)
out = self.pool1(out)
out = self.layer2(out)
out = self.pool1(out)
out = self.layer3(out)
out = self.pool1(out)
out = self.layer4(out)
out = self.pool1(out)
out = self.pool3(out)
out = out.view(x.shape[0], -1)
out = self.fc(out)
return out
def _make_layers(self, block, inc, outc, cnt):
layers = []
layers.append(block(inc, outc))
for i in range(cnt - 1):
layers.append(block(outc*self.extension, outc))
return nn.Sequential(*layers)
cnts = [3, 4, 6, 3]
resnet = ResNet50(BottleNet, cnts, 4)
DenseNet
论文:Densely Connected Convolutional Networks
DenseNet是CVPR 2017的best paper,主要还是和ResNet及Inception网络做对比,比ResNet来的更加彻底,即当前的每一层都和前面的每一层连接,在CIFAR指标上全面超越ResNet。可以说DenseNet吸收了ResNet最精华的部分,并在此上做了更加创新的工作,使得网络性能进一步提升。
从ResNet到DenseNet
ResNet极大地改变了如何参数化深层网络中函数的观点。稠密连接网络(DenseNetHuang.Liu.Van-Der-Maaten.ea.2017在某种程度上是ResNet的逻辑扩展。让我们先从数学上了解一下。
ResNet的数学表达为 f ( x ) = x + g ( x ) . f(\mathbf{x}) = \mathbf{x} + g(\mathbf{x}). f(x)=x+g(x).
也就是说,ResNet将 f f f分解为两部分:一个简单的线性项和一个复杂的非线性项。那么再向前拓展一步,如果我们想将 f f f拓展成超过两部分的信息呢?一种方案便是DenseNet。
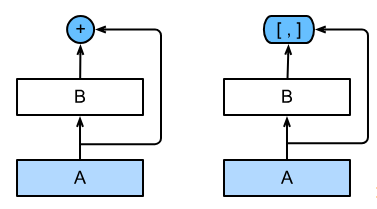
ResNet和DenseNet的关键区别在于,DenseNet输出是连接(用图中的
[
,
]
[,]
[,]表示)而不是如ResNet的简单相加。
因此,在应用越来越复杂的函数序列后,我们执行从
x
\mathbf{x}
x到其展开式的映射:
x → [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) , f 3 ( [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) ] ) , … ] . \mathbf{x} \to \left[ \mathbf{x}, f_1(\mathbf{x}), f_2([\mathbf{x}, f_1(\mathbf{x})]), f_3([\mathbf{x}, f_1(\mathbf{x}), f_2([\mathbf{x}, f_1(\mathbf{x})])]), \ldots\right]. x→[x,f1(x),f2([x,f1(x)]),f3([x,f1(x),f2([x,f1(x)])]),…].
最后,将这些展开式结合到多层感知机中,再次减少特征的数量。实现起来非常简单:我们不需要添加术语,而是将它们连接起来。
DenseNet这个名字由变量之间的“稠密连接”而得来,最后一层与之前的所有层紧密相连。
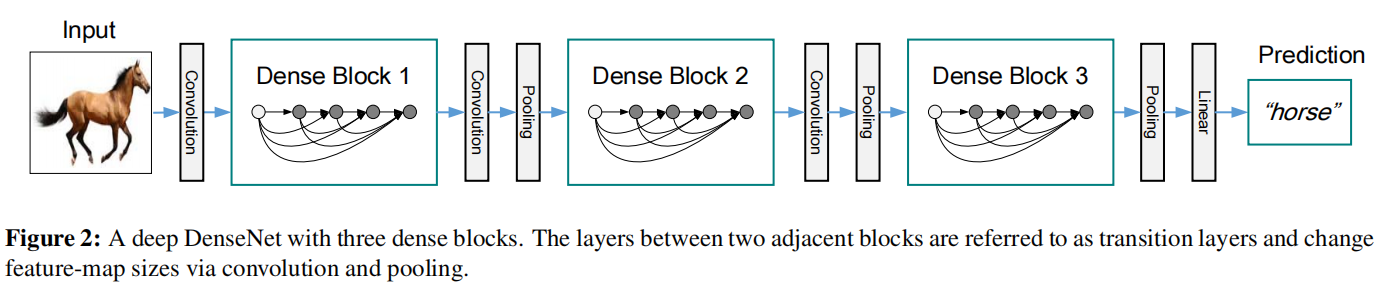
稠密连接如图所示 :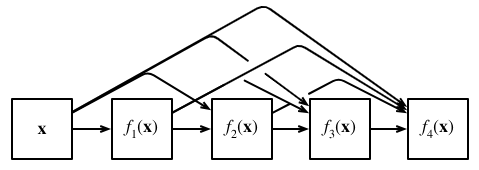
总结:它的核心思想是将网络中的每一层都与前面的所有层相连,使得每一层的输出都成为后续层的输入。这种连接方式不仅增强了网络的信息流通,还有效地缓解了梯度消失问题,从而提高了网络的性能。
网络架构
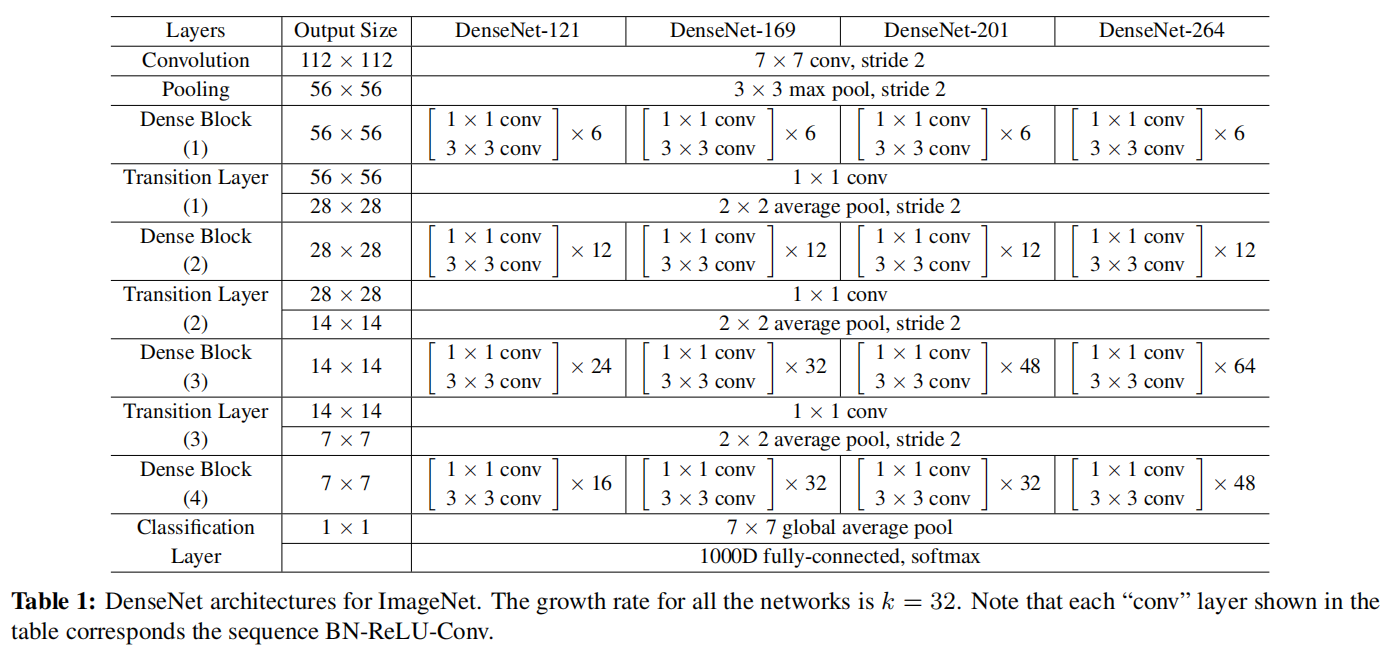
稠密网络主要由2部分构成:稠密块(dense block)和过渡层(transition layer)。
前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂。
💕✨DenseNet的网络结构主要由Dense Block+Transition组成:
1)dense block 是包含很多层的模块,每个层的特征图大小相同,层与层之间采用稠密连接方式。
- **conv_block:**BN+ReLU+Conv
- **Bottleneck layers:**1x1conv_block+3x3conv_block=BN+Relu+1×1Conv+BN+Relu+3×3Conv
2)transition layer 是连接两个相邻的Dense Block,并且通过Pooling使特征图大小降低。
转换层=BN+ReLU+1×1Conv+2×2AveragePooling
创新点
(1)前馈方式连接:它建立的是前面所有层与后面层的密集连接(dense connection)即在这个模块中才进行每一层的连接,这样便于控制输入尺寸的大小,Dense block模块之间就可以直接使用池化操作了
(2)特征重用(feature reuse):引入了具有相同特征图大小的任意两层之间的直接连接,产生易于训练和高效的参数压缩模型。将不同层学习的feature-map串联起来,增加了后续层输入的变化,提高了效率。
代码
bottleneck layers
import torch
import torch.nn as nn
import torch.nn.functional as F
class DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(DenseLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(num_input_features)
self.relu1 = nn.ReLU()
self.conv1 = nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False)
self.bn2 = nn.BatchNorm2d(bn_size*growth_rate)
self.relu2 = nn.ReLU()
self.conv2 = nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)
self.drop_rate = drop_rate
def forward(self, x):
output = self.bn1(x)
output = self.relu1(output)
output = self.conv1(output)
output = self.bn2(output)
output = self.relu2(output)
output = self.conv2(output)
if self.drop_rate > 0:
output = F.dropout(output, p=self.drop_rate)
return torch.cat([x, output], 1)
Dense Block
class DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(DenseBlock, self).__init__()
for i in range(num_layers):
if i == 0:
self.layer = nn.Sequential(
DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,drop_rate)
)
else:
layer = DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,drop_rate)
self.layer.add_module("denselayer%d" % (i+1), layer)
def forward(self,input):
return self.layer(input)
Transition
class Transition(nn.Sequential):
def __init__(self, num_input_feature, num_output_features):
super(Transition, self).__init__()
self.bn = nn.BatchNorm2d(num_input_feature)
self.relu = nn.ReLU()
self.conv = nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(2, stride=2)
def forward(self,input):
output = self.bn(input)
output = self.relu(output)
output = self.conv(output)
output = self.pool(output)
return output
DenseNet整体构建
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
# 前部
self.features = nn.Sequential(
#第一层
nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_init_features),
nn.ReLU(),
#第二层
nn.MaxPool2d(3, stride=2, padding=1)
)
# DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, num_features, bn_size, growth_rate,drop_rate)
if i == 0:
self.block_tran = nn.Sequential(
block
)
else:
self.block_tran.add_module("denseblock%d" % (i + 1), block)#添加一个block
num_features += num_layers*growth_rate#更新通道数
if i != len(block_config) - 1:#除去最后一层不需要加Transition来连接两个相邻的DenseBlock
transition = Transition(num_features, int(num_features*compression_rate))
self.block_tran.add_module("transition%d" % (i + 1), transition)#添加Transition
num_features = int(num_features * compression_rate)#更新通道数
# 后部 bn+ReLU
self.tail = nn.Sequential(
nn.BatchNorm2d(num_features),
nn.ReLU()
)
# classification layer
self.classifier = nn.Linear(num_features, num_classes)
# params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):#如果是卷积层,参数kaiming分布处理
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):#如果是批量归一化则伸缩参数为1,偏移为0
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):#如果是线性层偏移为0
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
block_output = self.block_tran(features)
tail_output = self.tail(block_output)
out = F.avg_pool2d(tail_output, 7, stride=1).view(tail_output.size(0), -1)#平均池化
out = self.classifier(out)
return out
import torch
from torch import nn
from d2l import torch as d2l
#卷积块conv block
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
Dense Block
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输入和输出
X = torch.cat((X, Y), dim=1)
return X
在下面的例子中,我们[定义一个]有2个输出通道数为10的(DenseBlock)。
使用通道数为3的输入时,我们会得到通道数为
3
+
2
×
10
=
23
3+2\times 10=23
3+2×10=23的输出。
卷积块的通道数控制了输出通道数相对于输入通道数的增长,因此也被称为增长率(growth rate)。
blk = DenseBlock(2, 3, 10)
X = torch.randn(4, 3, 8, 8)
Y = blk(X)
Y.shape
transition layer
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
总结
LeNet作为卷积神经网络的开篇,奠定了CNN基本结构;AlexNet尝试加深网络,进入深度卷积神经网络时代,为解决深度网络模型中难以训练、梯度爆炸/消失的问题,提出一系列技巧,如多GPU并行计算、数据增强、Dropout等;NIN、VGG发现小卷积核具有较好的表现,但仍旧无法突破瓶颈ResNet较好地解决了深度网络模型精度下降的问题,标志着训练深度模型成为可能。
参考资料:
【深度学习】经典CNN模型梳理与Pytorch实现:LeNet、AlexNet、NiN、VGGNet、ResNet_lenet alexnet vgg net torch 用的是那个模型-CSDN博客
图像分类经典神经网络大总结(AlexNet、VGG 、GoogLeNet 、ResNet、 DenseNet、SENet、ResNeXt )-阿里云开发者社区 (aliyun.com)















 3761
3761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









