






目录
5.1.4 (ROS)随机过采样、(RUS)随机欠采样和两阶段学习
1.摘要
本研究的目的是检验现有的深度学习技术,以解决类不平衡数据。使用不平衡数据进行有效分类是一个重要的研究领域,因为在许多现实应用中,例如欺诈检测和癌症检测,高等级不平衡是固有的。此外,高度不平衡的数据带来了额外的困难,因为大多数学习器会表现出对多数类的偏见,在极端情况下,可能会完全忽视少数类。
在过去二十年中,使用传统的机器学习模型(即非深度学习)对类失衡进行了深入研究。尽管深度学习最近取得了进展,但随着它的日益普及,在深度学习领域中,几乎没有关于类不平衡的实证研究。在几个复杂领域中取得了破纪录的性能结果,研究深度神经网络在包含高水平的类不平衡问题中的应用是非常有意义的。调查了关于类失衡和深度学习的现有研究,以便更好地理解深度学习在应用于类失衡数据时的效果。
这项调查讨论了每项研究的实施细节和实验结果,并提供了对其优缺点的更多见解。几个重点领域包括:数据复杂性、测试架构、性能解释、易用性、大数据应用以及对其他领域的概括。我们发现,这方面的研究非常有限,现有的大多数工作都集中在卷积神经网络的计算机视觉任务上,而且很少考虑大数据的影响。针对类不平衡的几种传统方法,例如数据采样和成本敏感学习,被证明适用于深度学习,而利用神经网络特征学习能力的更先进方法显示出有希望的结果。这项调查以一项讨论结束,该讨论强调了从类不平衡数据中进行深度学习的各种差距,以指导未来的研究。
关键词:深度学习,深度神经网络,阶级失衡,大数据
2.简介
监督学习方法需要标记的训练数据,在分类问题中,每个数据样本都属于一个已知的类或类别[1,2]。在来自两个类的数据样本的二元分类问题中,当一个类(少数组)包含的样本明显少于另一类(多数组)时,就会出现类不平衡。在许多问题[3-7]中,少数组是重要类,即正类。一个众所周知的类不平衡机器学习场景是检测疾病的医学诊断任务,其中大多数患者是是健康的,检测疾病更有意义。在本例中,大多数健康患者被称为负类。从这些不平衡的数据集学习可能非常困难,尤其是在处理大数据[8,9]时,通常需要非标准的机器学习方法来获得理想的结果。彻底了解类不平衡问题以及解决它的方法是必不可少的,因为在许多实际应用中都存在这样的偏差数据。
当训练数据中存在类不平衡时,由于多数类的先验概率增加,学习通常会过度分类。因此,属于少数类的实例比属于多数类的实例更容易被错误分类。使用不平衡数据训练神经网络时出现的其他问题将在“类不平衡数据的深度学习方法”一节中讨论。这些负类使得很难实现准确预测重要的正类的典型目标。此外,一些评价方法,如准确度,可能会以高分误导分析者,从而错误地表明良好的性能。给定一个正类分布为1%的二进制数据集,一个对所有输入总是输出负类标签的简单学习器将达到99%的准确率。许多传统的机器学习技术在“类不平衡数据的机器学习方法”一节中进行了总结,多年来已经发展起来,以对抗这些不利影响。
机器学习中处理类不平衡的方法可以分为三类:数据级技术、算法级方法和混合方法[10]。数据级技术试图通过各种数据采样方法来降低不平衡水平。处理类不平衡的算法级方法,通常使用权重或成本模式来实现,包括修改基础学习器或其输出,以减少对多类的偏差。最后,混合系统战略性地结合了采样和算法方法[10]。
在过去的10年中,深度学习方法随着语音识别、计算机视觉和其他领域的发展而越来越受欢迎[11]。他们最近的成功可以归因于数据可用性的提高、硬件和软件的改进[12-16],以及各种算法突破,这些突破加快了训练速度并改进了对新数据的概括[17]。尽管取得了这些进展,但很少有统计工作能够正确评估使用深度学习及其相应架构处理类不平衡的技术,例如,深度神经网络(DNN)。事实上,许多研究人员一致认为,对类不平衡数据的深度学习这一主题的研究不足[18-23]。因此,我们的调查仅限于15种深度学习方法来解决类不平衡问题。
我们进行了全面的文献综述,以确定广泛的深度学习方法来解决类不平衡。我们已经记录了文献检索过程的具体细节,以便其他学者在未来的研究中更自信地使用这项调查,这是任何文献综述中必不可少的一步[24]。候选论文首先通过谷歌学者[25]和IEEE Xplore[26]数据库发现。关键词搜索包括查询词的组合,如:“类不平衡”、“类稀有”、“倾斜数据”、“深度学习”、“神经网络”和“深度神经网络”。对搜索结果进行了审查和过滤,去除了那些没有从包含两个或更多隐藏层的神经网络的类不平衡数据中学习的结果。出版日期没有任何限制。然后,匹配的搜索结果用于执行向后和向前搜索,即查看匹配文章的参考文献和引用这些文章的其他来源。据我们所知,这一过程一直重复,直到所有相关文件都被识别出来。
附加的选择标准被应用于排除那些只测试了低水平的阶级不平衡、没有将所提出的方法与其他现有的类不均衡方法进行比较、或者只使用单个数据集进行评估的论文。我们发现,符合这些标准的论文非常有限。因此,为了增加选定作品的总数,放宽了这些额外要求。最后一组15份出版物包括期刊文章、会议论文和学生论文,这些文章采用了深度学习方法,数据不平衡。
我们探索了各种数据级、算法级和混合深度学习方法,旨在改进不平衡数据的分类。每个受调查作品的讨论中都包含了实现细节、实验结果、数据集细节、网络拓扑、类不平衡级别、性能指标和任何已知限制。表17和表18“调查作品讨论”部分总结了所有调查的深度学习方法及其相应数据集的细节。这项调查提供了最新的解决类不平衡的深度学习方法分析,总结并比较迄今为止所有相关工作,尽我们所知。
本文的其余部分组织如下。“类不平衡背景”部分提供了有关类不平衡问题的背景 信息,回顾了对类不平衡数据更敏感的性能指标,并讨论了一些更流行的用于处理不平衡数据的传统机器学习(非深度学习)技术。“深度学习背景”部分提供了关于深度学习的必要背景信息。介绍了整个调查中使用的神经网络架构,以及几个重要的里程碑,以及深度学习在解决大数据分析挑战中的应用。“类不平衡数据的深度学习方法”部分调查了15项已发表的研究,分析了解决类不平衡问题的深度学习法。“调查作品讨论”部分总结了调查作品,并进一步了解了其各种优势和劣势。“结论”部分结束调查并讨论未来工作的潜在领域。
3. 类不平衡背景
二元分类任务由一个正类和一个负类组成,在本节中用于讨论类不平衡以及解决其挑战的各种技术。这些概念可以扩展到多类问题,因为可以通过类分解将多类问题转换为一组两类问题[27]。
3.1 类不平衡问题
倾斜的数据分布自然出现在许多应用中,其中正类出现的频率降低,包括疾病诊断[3]、欺诈检测[4,5]、计算机安全[6]和图像识别[7]中发现的数据。内在不平衡是数据自然发生频率的结果,例如大多数患者的医疗诊断为健康。另一方面,外部不平衡是由外部因素引起的,例如收集或储存程序[28]。
在从不平衡的数据中学习时,考虑少数和多数类的代表性很重要。Krawczyk[10]提出,如果两个类都很好地表示并且来自非重叠分布,则无论类别不均衡,都可以获得良好的结果。Japkowicz[29]通过创建具有复杂度、训练集大小和不平衡程度的各种组合的人工数据集,研究了类不平衡的影响。结果表明,对不平衡的敏感性随着问题复杂性的增加而增加,非复杂的、线性可分离的问题不受所有级别的类不平衡的影响。
在某些领域,由于事件发生的频率较低,数据确实缺乏,例如检测漏油[7]。从极端的类不平衡数据中学习是非常重要的,因为我们最感兴趣的通常是这些罕见的事件,其中少数类只占训练数据的0.1%[10,30]。Weiss[31]讨论了从罕见事件中学习的困难以及解决这些挑战的各种机器学习技术。
可用的少数样本总数比少数样本的比例或百分比更令人感兴趣。考虑一个少数群体,它只占包含100万个样本的数据集的1%。尽管失衡程度很高,但仍有许多正样本(10000)可用于训练模型。另一方面,不平衡的数据集,其中少数类显示稀有或表示不足,更可能损害分类器的性能[30]。
(1)
为了比较本次调查中提出的所有工作的实验结果,将使用比率ρ(等式1)[23]来表示类间的最大不平衡水平。 和
分别返回所有i ii个类的最大和最小类大小。例如,如果一个数据集的最大类有100个样本,最小类有10个样本,那么数据的不平衡比ρ =10。由于实际样本数可能比这个比例更重要,表18还包括了本次调查中所有实验的最大和最小类大小。
3.2 性能度量
表1中的混淆矩阵总结了二元分类结果。FP和FN误差分别对应于I型和II型误差。本节中列出的所有性能指标都可以从混淆矩阵中导出。
表1:混淆矩阵
| Actual positive | Actual nefative | |
|---|---|---|
| Predicted positive | True positive(TP) | False positive(FP) |
| Predicted nefative | False negative(FN) | True negative(TN) |
(2)
(3)
准确率(等式2)和错误率(等式3)是评估分类结果时最常用的度量。然而,在处理类不平衡问题时,两者都是不够的,因为产生的值由多数类(即负类)主导。如前所述,给定一个数据集,其中正类分布仅为数据集的1%时,一个简单的分类器通过将所有样本标记为负类来获得99%的准确率分数。当然,这样的模型不会提供真正的价值。为此,我们回顾了几种常用于不平衡数据问题的评估指标。
(4)
(5)
(6)
精确度(等式4)衡量被标记为正类的样本中,实际为正类的百分比。精确度对类别不平衡很敏感,因为它考虑了被错误标记为正类的负样本的数量。然而,单靠精确性是不够的,因为它无法深入了解被错误标记为负类的的正类样本数量。另一方面,召回率(等式5)或真阳性率TPR衡量正样本中模型正确预测正类的的百分比。召回率不受不平衡的影响,因为它只依赖于正样本。召回率不考虑被错误分类为正类的负样本的数量,这在包含大量负样本的类不平衡数据的问题中可能是有问题的。精确度和召回率之间存在权衡,更重要的度量因问题而异。选择性(等式6)或真阴性率TNR衡量负样本中被正确预测为负类的百分比。

F-Measure(公式7),或称F1分数,使用谐波平均法将精确度和召回率结合起来,其中系数β用于调整精确度与召回率的相对重要性。G-Mean(公式8)通过使用TPR和TNR指标的乘积的平方根来衡量性能。与G-Mean类似,Balanced Accuracy(公式9)指标也结合了TPR和TNR值来计算一个对少数类更敏感的指标[18]。尽管F-Measure、G-Mean和Balanced Accuracy是对Accuracy和Error Rate的改进,但在比较分类器和各种分布之间的性能时,它们仍然不完全有效[28]。
由Provost和Faw-cett[32]首次提出的受试者工作特征曲(ROC)曲线是另一种流行的评估方法,它将真阳性率与假阳性率绘制在一起,形成一种可视化,描述了正确分类的正样本与错误分类的负样本之间的权衡。对于产生连续概率的模型,可以使用阈值处理来沿着ROC空间创建一系列的点[28]。由此可以计算出一个单一的总结性指标,即ROC曲线下的面积(AUC)指标并经常用于比较不同模型的性能。Weng和Poon[33]提出了一个加权的AUC指标,该指标在计算面积时考虑到了成本偏差。
根据Davis和Goadrich[34]的说法,ROC曲线可能会在高度偏斜的数据集上呈现过于乐观的结果,而应使用精度-召回(PR)曲线。作者声称,一条曲线只有在ROC空间中占主导地位,才能在PR空间中也占主导地位。这是因为ROC使用的假阳性率FPR=FP/(TN+FP),随着负类规模增加,对FP的变化不太敏感。
根据Seliya等人[35],应使用一组互补的性能指标评估学习器,其中每个单独的指标都反映了性能的不同方面。在他们的综合研究中,22个不同的性能指标被用于评估35个独特数据集中的两个分类器。然后,使用共同因素分析对指标进行分组,确定可用于减少冗余和改进性能解释的不相关性能指标集。Seliya等人发现的一组补充性能指标是AUC、Brier不准确率[36]和准确性。
3.3 解决类不平衡数据的机器学习技术
在过去的二十年里,人们对用传统的机器学习技术解决类的不平衡问题进行了广泛的研究。通过改变训练数据以减少不平衡,或者通过修改模型的基本学习或决策过程以提高对少数类的敏感性,可以减轻对多数类的偏差。因此,处理类不平衡的方法被分为数据级技术、算法级方法和混合方法。本节总结了一些比较流行的处理类不平衡的传统机器学习方法。
3.3.1 数据级方法
解决类不平衡的数据级方法包括过采样和欠采样。这些方法修改了训练分布,以降低不平衡程度或减少噪音,例如错误标记的样本或异常情况。在它们最简单的形式中,**随机欠采样(RUS)会丢弃来自多数组的随机样本,而随机过度采样(ROS)**则会重复来自少数组的随机样本[37]。
欠采样会主动丢弃数据,减少模型所要学习的信息总量。过采样将导致训练时间的增加,因为训练集的大小增加了,而且也被证明会导致过度拟合[38]。 过拟合的特征是高方差,当一个模型与训练数据拟合得过于紧密,然后无法归纳到新的数据时就会发生。为了平衡这些权衡,已经开发了各种智能取样方法。
智能的欠采样方法旨在为学习保留有价值的信息。 Zhang和Mani[39]提出了几种Near-Miss算法,这些算法使用K-nearest neighbors(K-NN)分类器,根据它们与少数样本的距离来选择多数样本进行移除。Kubat和Matwin[40]提出了单边选择,是通过1-NN规则和Tomek Links发现的[41],作为一种从多数类中去除噪声和冗余样本的方法。Barandela等人[42]使用**Wilson’s editing[43],这是一种K-NN规则,**从训练集中去除错误分类样本的,从类的边界去除多数样本。
一些的过采样技术也被研究出来,以加强类的边界,减少过度拟合,并提高辨别力。Chawla等人[44]介绍了合成少数样本过采样技术(SMOTE),这种方法通过在现有少数样本和邻近的少数样本之间进行插值来产生人工少数样本。SMOTE的几个变种,例如Borderline-SMOTE[45]和Safe-Level-SMOTE[46],通过考虑多数类的邻居来改进原始算法。Borderline-SMOTE将过采样限制在类边界附近的样本,而Safe-Level-SMOTE定义了安全区域,以防止在重叠或噪声区域过采样。
监督学习系统通常用几个disjuncts来定义一个概念,其中每个disjunct是一个描述子概念的联合定义[47]。一个disjunct的大小对应于该disjunct正确分类的样本数量。小的disjuncts,通常对应于领域中的罕见情况,是只对少数数据样本进行正确分类的学习概念。这些小的disjuncts是有问题的,因为它们往往包含比大的disjuncts高得多的错误率,而且不能在不影响性能的情况下将它们删除[48]。(disjuncts:因为少数类分布的稀疏性sparsity,以及稀疏性导致的拆分多个子概念sub-concepts/子clusters,导致每个子概念仅含有较少的样本数量 [10])
Jo和Japkowicz[49]提出了基于聚类的过采样,以解决训练数据中存在的小的不连贯性。首先使用K-means算法对少数群体和多数群体进行聚类,然后对每个聚类分别进行过采样。
这可以改善类内不平衡和类间不平衡。
Van Hulse等人[37]比较了七种不同的采样技术和11种常用的机器学习算法。每个模型都用35个基准数据集进行了评估,使用6个不同的性能指标来比较结果。结果显示,抽样结果高度依赖于学习者和评估性能指标。实验表明,RUS总体上性能良好,在大多数情况下优于ROS和智能采样方法。结果表明,尽管RUS在大多数情况下表现良好,但没有一种抽样方法能保证在所有问题领域表现最好,在评估结果时应使用多种性能指标。
3.3.2 算法级方法
与数据采样方法不同,处理类不平衡的算法方法不会改变训练数据的分布。相反,学习或决策过程会以一种增加正类重要性的方式进行调整。最常见的是,通过考虑类别惩罚或权重修改算法,或者通过减少对负类的偏差来改变决策阈值。
在成本敏感学习 中,惩罚通过成本矩阵分配给每个类。增加少数类的成本相当于增加其重要性,降低学习器错误地分类该类中的样本[10]的可能性。二元分类问题的代价矩阵如表2[50]所示。表中的一个给定项c i j c_{ij}c ij ,是在真实类别为j jj,预测类别为i ii时相关的代价。通常,代价矩阵的对角线,即i = j i = ji=j,被设置为0 00。然后对假阳性和假阴性错误对应的代价进行调整,以达到预期的结果。
| 实际阳性 | 实际阴性 | |
| 预测阳性 | C(1,1)=c11 | C(1,0)=c10 |
| 预测阴性 | C(0,1)=c01 | C(0,0)=c00 |
Ling和Sheng[51]将成本敏感方法分为直接方法和元学习方法。直接方法是一种自身具有成本敏感能力的方法,通过修改学习器的底层算法来实现,以便在学习过程中考虑成本。优化过程由总误差最小化转变为总成本最小化。元学习方法利用包装器将成本不敏感的学习器转换为成本敏感的系统。如果一个代价不敏感的分类器产生后验概率估计,代价矩阵可以用来定义一个新的阈值p*,比如:
(10)
通常,阈值方法使用p* 在分类样本[51]时重新定义输出决策阈值。阈值移动,或使用(公式10)对输出类概率进行后处理,是一种元学习方法,它将代价不敏感的学习器转换为代价敏感的系统。
先验概率(prior probability):指根据以往经验和分析。在实验或采样前就可以得到的概率。
后验概率(posterior probability):指某件事已经发生,想要计算这件事发生的原因是由某个因素引起的概率。
成本敏感学习的最大挑战之一是分配一个有效的成本矩阵。成本矩阵可以根据过去的经验来定义,也可以由具有问题知识的领域专家来定义。或者,假阴性成本可以设置为一个固定的值,而假阳性成本是变化的,使用验证集来确定理想的成本矩阵。后者具有探索一系列代价的优势,但如果数据集的大小或特征的数量太大,则代价昂贵,甚至不切实际。
3.3.3 混合方法
数据级和算法级方法以各种方式结合起来,并应用于类不平衡问题[10]。一种策略包括执行数据采样来减少类噪声和不平衡,然后应用成本敏感学习或阈值来进一步减少对多数类的偏差。在[28]中介绍了几种集成方法与采样和代价敏感学习相结合的技术。Liu等[52]提出了两种算法,EasyEnsemble和BalanceCascade,它们通过将多数类的子集和少数类进行结合来学习多个分类器,为每个单独的分类器创建伪平衡训练集。SMOTEBoost[53]、DataBoost-IM[54]和JOUS-Boost[55]都将采样与集成结合起来。Sun[56]推出了三种成本敏感的方法,分别是AdaC1、AdaC2和AdaC3。这些方法通过在AdaBoost算法的权重更新中引入成本项,迭代地增加了少数类的影响。Sun表明,在大多数情况下,成本敏感的增强集成优于普通增强方法。
4. 深度学习背景
本节回顾了深度学习的基本概念,包括在整个调查作品中使用的神经网络架构的描述和表示学习的价值。我们还谈到了对深度学习的成功做出贡献的几个重要里程碑。最后,介绍了大数据分析的兴起及其面临的挑战,并讨论了深度学习在解决这些挑战中的作用。
4.1 深度学习介绍
深度学习是机器学习的一个子领域,它使用含有两个或多个隐藏层的人工神经网络(ANNs)来近似某些函数f* ,其中**f* 可用于将输入数据映射到新的表示形式或进行预测**。受生物神经网络的启发,人工神经网络是一组相互连接的神经元或节点,其中的连接是加权的,每个神经元通过对其加权输入的和应用非线性激活函数将其输入转换为单个输出。在前馈网络中,输入数据以前向传递的方式在网络中传播,每个隐藏层从前一层的输出接收其输入,产生依赖于输入数据、激活函数的选择和权重参数[1]的最终输出。然后使用梯度下降优化来调整网络的权重参数,以最小化损失函数,即期望输出与实际输出之间的误差。
多层感知器(MLP) 是一个包含至少一个隐藏层的全连接前馈神经网络。浅层和深层MLP如图1所示。就实现而言,深度MLP是最简单的深度学习模型,但随着加权连接的数量迅速增加,它很快就会变得非常耗费资源。
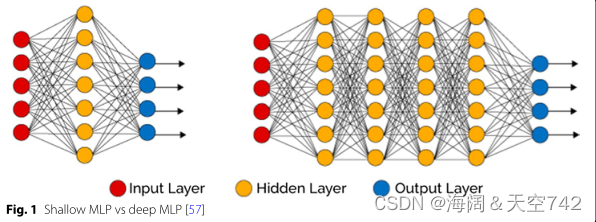
图1 浅层和深层MLP
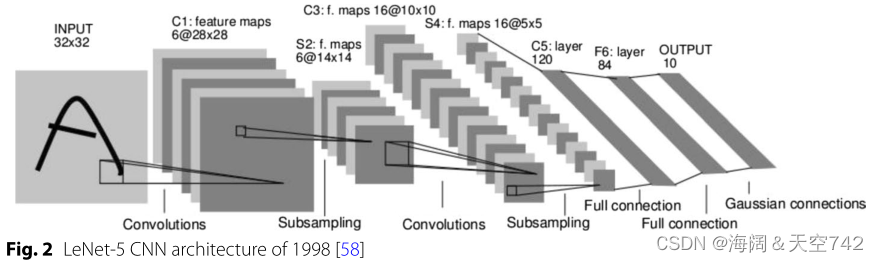
图2 卷积神经网络-LeNet5
卷积神经网络(CNN) 是一种专门用于处理多维数据的前馈神经网络,例如图像2。它的灵感来自大脑的视觉皮层,它的起源可以追溯到1980年福岛提出Neocognitron。CNN架构通常由卷积层、池化(子采样)层和全连接层组成。图2展示了LeCun等[58]在1998年提出的LeNet-5 CNN架构,用于字符识别。与全连接层不同,卷积层的单个单元只连接到其输入的一个小接受域,其中其连接的权重定义了一个过滤器组[11]。卷积运算用于在输入上滑动滤波器组,在每个接受域上产生激活,结合形成特征映射[60]。换句话说,相同的一组权重被用于检测特定的特征,例如在输入的每个接受域的一条水平线,而输出特征图表示该特征在每个位置的存在。局部连接和共享权重的概念利用了这样一个事实:彼此接近的输入信号通常是高度相关的,而且输入信号通常不随位置变化。通过在单个卷积层中组合多个滤波器组,该层可以学习检测输入中的多个特征,得到的特征映射成为下一层的输入。池化层添加在一个或多个卷积层之后,以便合并语义上相似的特征并降低维数[11]。在卷积层和池化层之后,多维输出被压平并馈送到全连接层进行分类。与MLP类似,输出激活从一层向前传递到下一层,权重通过梯度下降更新。
MLP和CNN只是多年来开发的众多备选DNN架构中的两个。循环神经网络(RNNs)、自编码器和随机网络在[1,60,61]中有详细的解释。他们还提出了先进的优化技术,已被证明可以改善训练时间和性能,例如正则化方法,参数初始化,改进的优化器和激活函数,以及规范化技术。
4.2 表示学习
传统机器学习算法的成功高度依赖于输入数据的表示,这使得特征工程成为机器学习工作流中的关键步骤。这是非常耗时的,对于许多复杂的问题,例如图像识别,很难确定哪些特征将产生最好的结果。深度学习通过建立在表示学习的概念上为这个问题提供了一个解决方案。
表示学习是利用机器学习将原始输入数据特征映射到新的表示,即新的特征空间,以改进检测和分类任务的过程。这种从原始输入数据到新表示形式的映射是通过输入数据的非线性转换实现的。组合多个非线性转换创建输入数据的分层表示,通过每个转换增加抽象级别。这种自动生成新特性的方法无需专家手动设计特性,从而节省了宝贵的时间,并提高了许多复杂问题领域的整体性能,例如图像和语音,在这些领域很难确定最佳特性。当数据通过DNN的隐藏层时,每一层都会将其转换为新的表示形式。给定足够的数据,DNN能够通过多个隐藏层的组成来学习输入的高级特征表示。这些习得的表征放大了输入中对辨别很重要的部分,同时抑制了那些不重要的部分。深度学习架构通过这种日益复杂的抽象表示组合[60]来实现它们的强大功能。这种解决问题的方法直观上是有意义的,因为将简单的概念组合成复杂的概念类似于许多现实世界的问题领域。
4.3 深度学习与大数据
许多组织都面临着大数据的挑战,因为他们正在探索大量数据以提取价值并指导决策[71]。大数据是指超出标准数据存储和数据处理系统能力的数据[72]。这迫使从业者采用新的技术来存储、操作和分析数据。大数据的兴起可以归因于硬件和软件的改进,互联网和社交媒体活动的增加,以及越来越多的支持传感器的互联设备,即物联网(IoT)。
更具体地说,大数据可以用四个 V 来描述:体积(volume)、速度(velocity)、多样性(variety)和准确性(veracity)[72,73]。收集的大量数据需要高度可伸缩的硬件和高效的分析工具,通常要求 分布式实现。除了增加架构和网络开销外,分布式系统已被证明会加剧类不平衡数据的负面影响[74]。需要先进的技术来快速处理传入的数据流和保持适当的周转时间,以跟上数据生成的速度,即 数据的速度。大数据的 多样性对应于大部分非结构化、多样化和不一致的表示,这些表示是由于数据在较长时间内从多个来源消耗而产生的。这种多样性进一步增加了数据预处理和机器学习的计算复杂性。最后,大数据的 准确性。它的准确性和可信度,必须定期验证,以确保结果不会被无效输入破坏。被大数据放大的一些额外的机器学习挑战包括 高维、分布式基础设施、实时需求、特征工程和数据清理[75]。
Najafabadi等人[75]讨论了深度学习在解决大数据挑战中的应用。DNN从大量未标记的数据中提取有意义的特征的能力尤其重要,因为这在大数据分析中经常遇到。因此,从大多数非结构化和多样化的数据(例如图像、文本和音频数据)中自动提取特征非常有用。通过深度学习方法从大数据中提取抽象特征,通常可以使用简单的线性模型更有效地完成机器学习任务。高级的基于语义的信息存储和检索系统,例如语义索引和哈希[76,77],也可以通过这些高级功能实现。此外,深度学习已被用于标记传入的数据流,帮助对快速移动的数据进行分组和组织[75]。一般来说,大容量DNN非常适合从大数据分析中遇到的大量数据中学习。
随着大数据在组织内部的不断增加,将需要新的方法来跟上数据的涌入。尽管相对不成熟,但深度学习方法在解决许多大数据挑战方面被证明是有效的。我们相信,深度学习的进步,特别是从无监督数据中学习,将在未来的大数据分析中发挥关键作用。
5. 解决类不平衡数据的深度学习方法
Anand等人[78]在20世纪90年代探索了类不平衡对浅层神经网络反向传播算法的影响。作者表明,在类不平衡的情况下,少数类的梯度组成的长度远远小于多数类的梯度组成的长度。换句话说,多数类基本上控制了负责更新模型权重的网络梯度。这在早期迭代中非常迅速地减少了多数组的错误,但通常会增加少数组的错误,并导致网络陷入缓慢的收敛模式。
本节分析了一些用于解决类不平衡的深度学习方法,这些方法由数据级、算法级和混合方法组成。对于每一项调查工作,我们总结了实现细节和用于评估方法的数据集的特征。然后,我们讨论各种优缺点,考虑诸如类不平衡级别、结果解释、相对性能、使用难度以及对其他架构和问题域的泛化等主题。文中强调了已知的局限性,并提出了今后工作的建议。为了一致性,对于所有被调查的作品,类不平衡表现为最大类之间的比率ρ (公式1)。
5.1 数据级方法
本节包括四篇论文,探讨了用DNN解决类不平衡数据级方法。Hensman和Masko[79]首先表明,利用ROS来平衡训练数据可以改善不平衡图像数据的分类。然后Lee et al.[20]使用RUS和增强方法来减少类不平衡,以预训练 深度CNN。Pouyanfar等[21]引入了一种新的动态采样方法,该方法根据类的性能调整采样率。最后,Buda等[23]比较了多个不平衡图像数据集上的RUS、ROS和两阶段学习。
5.1.1 通过(ROS)随机过采样进行平衡训练
Hensman和Masko[79]利用深度CNN探索了类不平衡和ROS的影响。CIFAR-10[80]基准数据集由10个类组成,每个类有6000张图像,用于生成10个不平衡数据集进行测试。这10个生成的数据集包含不同的类别大小,在总数据集的6%到15%之间,产生最大不平衡比率ρ = 2.3 。除了类规模的变化,不同的分布也改变了少数类的数量,少数类是任何比最大类小的类。例如,一个主要的50-50分割(Dist 3)将5个类减少到数据集大小的6%,将5个类增加到数据集大小的14%。另一个例子是,一个主要的单数过度代表(Dist 5)将飞机类别的规模增加到14.5%,其他9个类别略微减少到9.5%。
亨斯曼和马斯科的所有实验都使用了AlexNet [17] CNN的一个变种,该变种已被证明在CIFAR10上表现良好。基线性能是通过在没有数据采样的所有分布上训练CNN来定义的。被评估的ROS方法包括从少数类中随机复制样本,直到训练集中的所有类都有相同数量的样本。
亨斯曼和马斯科将他们的结果以每个类正确答案的百分比表示,并包括所有类的平均分数,用Total表示。为了确保结果的有效性,每个实验一共进行了三次运行,然后取平均值。表3显示了未经任何数据采样的CNN的结果。这些结果证明了类不平衡在训练CNN模型时的影响。大多数不平衡分布的性能都有所下降。Dist 6和Dist 7不平衡程度很轻,没有过度代表性,表现与原来的平衡分布一样好。一些包含过度代表的类的不平衡分布,例如Dist 5和Dist 9,产生了完全偏向大多数类的无用模型。
左:表3 CIFAR-10不平衡分类 右:表4 使用ROS的CIFAR-10不平衡分类
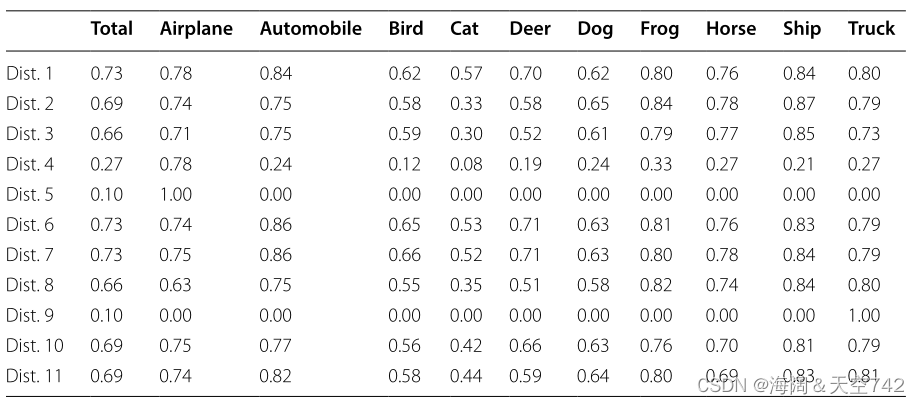
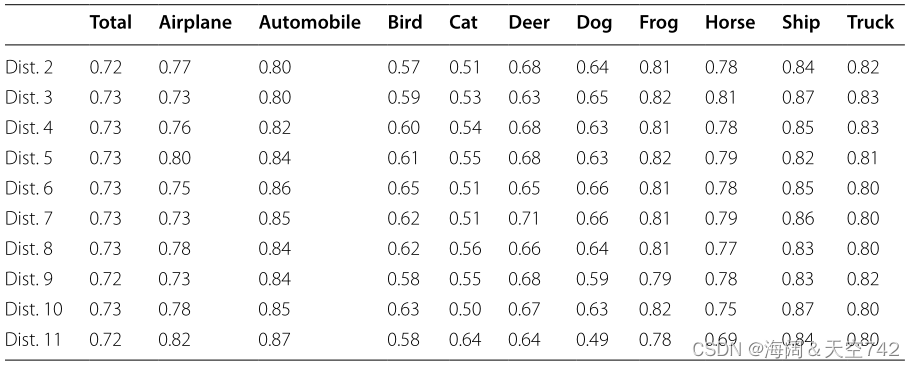
表4包含了使用ROS生成的平衡数据训练CNN的结果。这表明,过采样的表现明显优于表3的基线结果。Dist 1从表4中被排除,因为它已经平衡,即ROS不适用。在本实验中,ROS改善了所有分布的分类结果。Dist 5和Dist 9表现最佳,总F1-分数分别从0.10的基线提高到0.73和0.72。Dist 11的ROS分类结果与Dist 1的基线CNN的结果相当,这表明ROS完全恢复了模型性能。
Hensman和Masko的实验表明,将ROS应用于类平衡水平可以有效地解决图像数据中的轻微类不平衡。表3中的一些结果也清楚地表明,小水平的不平衡能够阻止CNN收敛到可接受的解决方案。我们认为测试的低不平衡水平(ρ = 2.3)是这个实验的最大限制,因为在实践中不平衡水平通常要高得多。除了探索更多的数据集和更高水平的不平衡 之外,值得进一步研究的一个领域是在不平衡数据上训练期间完成的总epoch数。在这些实验中,只完成了训练数据的10个周期,因为作者更感兴趣的是比较性能,而不是实现高性能。运行额外的epoch将有助于排除性能不佳是否是由于Anand等人所描述的缓慢收敛现象。
5.1.2 两阶段学习
Lee等人[20]结合RUS和迁移学习对浮游生物图像高度不平衡的数据集 WHOI-Plankton[81] 进行分类。该数据集包含340万张图像,分布在103个类中,其中90%的图像仅由5个类组成,第五大类仅占整个数据集的1.3%。ρ > 650的不平衡比率在数据集中表现出来,许多类构成不到数据集的0.1%。所提出的方法是两阶段学习过程,其中深度CNN首先使用阈值数据进行预训练,然后使用所有数据进行微调。用于预训练的阈值数据集是通过随机欠采样的大型类构造的,直到它们达到N个样本的阈值 。作者通过初步实验选择了一个阈值N = 5000,然后 将所有大的类都减少到N个样本 。将提出的模型(G)与六种替代方法(A - F)进行比较,这是一种迁移学习和增强技术的组合,使用非加权平均F1-分数来比较结果。
(A)Full:用原始的不平衡数据集训练CNN。
(B)噪声:使用增强数据训练的CNN,其中通过噪声注入复制少数类,直到所有类包含至少1000个样本。
(C)Aug:CNN使用增强数据训练,其中少数类通过旋转、缩放、平移和翻转图像进行复制,直到所有类包含至少1000个样本。
(D)Thresh:用阈值数据训练的CNN,通过随机欠采样生成,直到所有类最多有5000个样本。
(E)Noise + full:CNN使用来自(B)的噪声增强数据预训练,然后使用完整的数据集进行微调。
(F)Aug + full:CNN使用来自©的变换增强数据预训练,然后使用完整的数据集进行微调。
(G)Thresh + full:使用(D)中的阈值数据集预训练CNN,然后使用完整的不平衡数据集进行微调。
Lee等人的实验结果见表5,其中L5和Rest列分别为最大的五个类和其余少数类的未加权平均F1-分数。比较方法(B - D)表明,对所有类别的给定数据集,欠采样(D)优于噪声注入(B)和增强©过采样方法。方法(B-D)与基线(A)相比,Rest组有中度改善,但L5组在性能上有较大亏损。用(E-G)中的完整数据集重新训练模型,使模型能够重新捕获L5组的分布。提出的模型(G)在L5组中F1-分数最高(0.7791),在Rest组中F1-分数较基线从0.1548大幅提高到0.3262。
表5 WHOI-Plankton数据集的两阶段学习(平均F1得分)
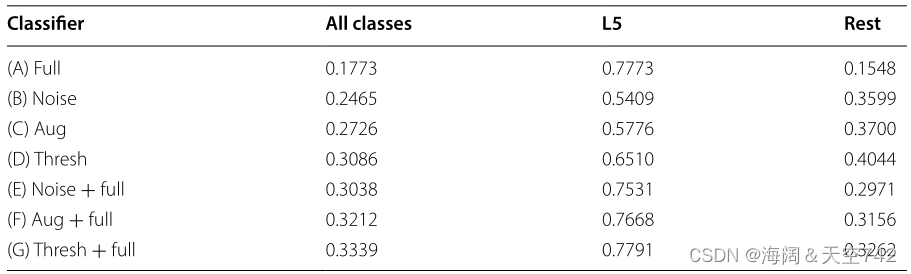
Lee等人提出的两阶段学习过程已被证明可以有效地提高少数类的成绩,同时仍然保持大多数类的成绩。与普通RUS完全从训练集中移除潜在有用信息不同,两阶段学习方法只在训练前阶段从大多数组中移除样本 。这允许少数类在预训练期间对梯度做出更多的贡献,并且仍然允许模型在微调阶段看到所有可用的数据。作者没有包括训练前阶段的细节,例如训练前阶段的数量或用于确定训练前何时完成的标准。在未来的工作中应该考虑这些细节,因为导致高偏差或高方差的预训练肯定会影响最终模型的分类性能。未来的工作还可以考虑一种混合方法,其中模型预训练的数据是通过欠采样多数类和增加少数类的组合生成的。
前一年,Havaei等人[82]在进行脑肿瘤图像分割时使用了类似的两阶段学习过程来处理类不平衡。脑瘤数据包含少数类别,占总数据集的1%不到。Havaei等人指出,两阶段学习过程是处理图像数据不平衡分布的关键。这篇论文的细节没有包括在这次调查中,因为两阶段学习只是他们领域特定实验的一个小组成部分。
5.1.3 动态采样
Pouyanfar等[21]采用动态采样技术,利用深度CNN对不平衡图像数据进行分类。其基本思想是对表现较差的类进行过采样,对表现较好的类进行欠采样,向模型展示它已经学过的内容更少,而更多的是它尚未理解的内容。这有点类似于人类的学习方式,一旦学会了简单的任务,就会把注意力集中在更困难的任务上。作者自行收集的数据集包含了从公共网络摄像机中捕获的10000多张图像,包括总共19 个语义概念,例如十字路口、森林、农场、天空、水、游乐场和公园。从原始数据集中,70%用于训练模型,20%用于验证,10%用于测试。作者报告了数据集中的不平衡比率高达ρ = 500。平均F1-分数和加权平均F1-分数被用来比较所提出的模型与基线CNN (A)和处理类不平衡的四种替代方法(B-E)。
Pouyanfar等人提出的系统包括三个核心部分:实时数据增强、迁移学习和一种新的动态采样方法。实时数据增强通过应用各种转换来选择每个训练批中的图像来提高泛化。迁移学习是通过微调使用ImageNet[84]数据预训练的Inception-V3网络[83]来实现的。动态抽样方法是解决类不平衡的主要方法。
(11)
是一个包含迭代 i 次后所有单独类的F1-分数的向量,
表示迭代 i 中类j 的F1-分数,其中每个类的F1-分数以一比一的方式计算。在下一次迭代中,F1-分数较低的类以更高的频率采样,迫使学习者更多地关注先前错误分类的样本。公式11用于获得给定类c j 下一次迭代的样本量,其中N*是类的平均大小。为了防止少数类的过拟合,采用无采样的迁移学习方法训练第二个模型。在推断时,输出标签是作为两个模型的函数计算的。
(A)基本CNN:VGGNet[85]是在整个数据集上训练的CNN。
(B)深度CNN特征+ SVM:用CNN生成的深度特征训练支持向量机(SVM)分类器。
(C )没有增强的迁移学习:在没有数据增强的情况下对Inception-V3进行微调。
(D)带增强的迁移学习:使用数据增强对Inception-V3进行微调。
(E)平衡增强的迁移学习:使用数据增强对Inception-V3进行微调,以执行类平衡训练批次的过采样和欠采样。
(F)提出的模型:在Inception-V3网络上进行动态采样、数据增强和迁移学习。
比较了所有19个概念的平均分类F1-分数,显示基本CNN在所有情况下表现最差。基本的CNN无法对几个不平衡比率非常高的概念正确分类单个样本,包括不平衡比率分别为ρ = 200和ρ = 500的Playground和Airport。迁移学习方法(C-E)的表现明显优于基线CNN,将加权平均F1-分数从0.630提高到0.779。表6中的结果表明,所提出的方法(F)优于在给定数据集上测试的所有其他模型。与基于基本增强的迁移学习(D)相比,动态抽样方法(F)将加权平均F1-分数从0.779提高到0.794。
表6 网络摄像机图像数据动态采样
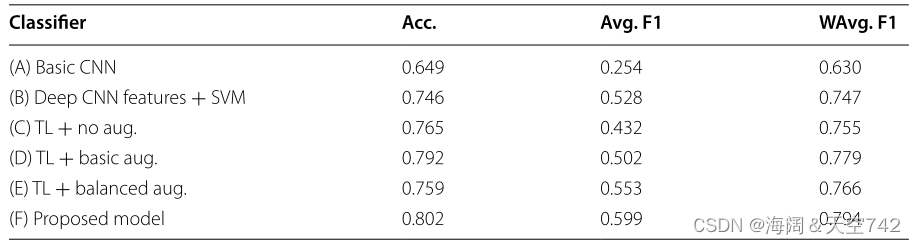
动态抽样方法最吸引人的特点是能够自我调整采样率。这使得该方法能够适应包含不同复杂程度和类不平衡的不同问题,几乎没有超参数调优。通过移除已经被网络参数捕获的样本,梯度更新将由更困难的正样本驱动。根据F1-分数,动态抽样方法优于过采样和欠采样混合 (E),但抽样方法的细节不在描述中。我们也不知道动态采样对普通RUS和ROS的表现如何,因为这些方法没有经过测试。这应该在未来的工作中仔细检查,以确定动态采样是否可以用作RUS和ROS的一般替代品。值得关注的一个方面是,该方法依赖于验证集来按类的性能指标确定计算所需的采样率。在类稀少的情况下,这肯定会有问题,因为只有很少的正样本存在,留出数据进行验证可能会使模型失去有价值的训练数据。在未来的研究中应包括最大化总可用训练数据的方法。此外,未来的研究应该将动态采样方法扩展到非CNN架构和其他领域。
5.1.4 (ROS)随机过采样、(RUS)随机欠采样和两阶段学习
Buda等人[23]使用三种多类图像数据集和深度CNN比较了ROS、RUS和两阶段学习。MNIST[86]、CIFAR-10和ImageNet数据集用于创建不同程度的不平衡分布。MNIST和CIFAR-10训练集都包含5万张图像,平均分布在10个类中,即每个类5000张图像。由MNIST和CIFAR-10分别在ρ ∈ [ 10 , 5000 ] 和ρ ∈ [ 2 , 50 ] 范围内创建了不平衡分布。ImageNet训练数据包含100个类,每个类最多1000个样本,用于在ρ ∈ [ 10 , 100 ] 范围内创建不平衡分布。
根据最近最先进的结果,为每个数据集选择了不同的CNN架构。对于MNIST和CIFAR-10实验,分别使用LeNet-5[58]版本和All-CNN[87]架构进行分类。在没有任何形式的类不平衡技术的情况下,通过对数据集进行分类,为每个CNN架构建立基线结果。没有数据采样或阈值。接下来,将7种不同的解决类不平衡的方法集成到CNN体系结构中并进行测试。通过平均每个类的单一与所有AUC,将ROC AUC扩展到多类问题,并用于比较方法。他们的部分结果如图3所示。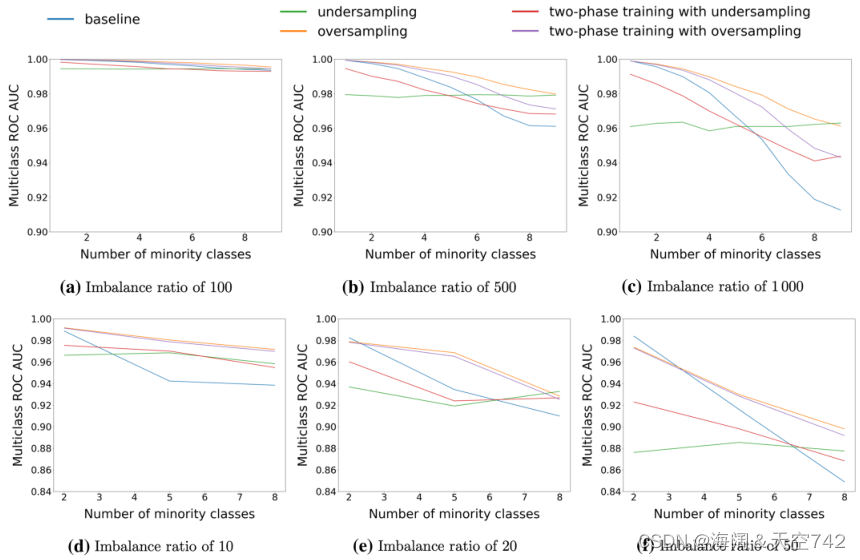
图3 在MNIST(a-c) 和 CIFAR-10(d-f) 上的ROS, RUS和两阶段学习
(A) ROS:所有少数类都被过采样,直到类达到平衡,其中任何少于最大类的类都被认为是少数类。在几乎所有的实验中,过采样显示出最好的性能,与基线相比,从未显示出性能下降。
(B) RUS:所有多数类都是欠抽样的,直到达到类平衡,其中任何大于最小类规模的类都被认为是多数类。与基线模型相比,RUS表现较差,且从未显示出明显的ROS优势。只有在少数类总数很高(80-90%)时,RUS才与ROS相当。
(C )使用ROS进行两阶段训练:首先在通过ROS生成的平衡数据集上对模型进行预训练,然后使用完整的数据集进行微调。总的来说,这种方法比严格的ROS (A)表现更差。
(D)使用RUS的两阶段训练:与(C )类似,只是用于预训练的平衡数据集是通过RUS生成的。结果表明,该方法的有效性低于RUS (B)。
(E)基于先验类概率的阈值化:网络的决策阈值在测试阶段根据每个类的先验概率进行调整,有效地转移输出类概率。阈值处理对整体准确度有改善,特别是与ROS联合使用时。
(F) ROS和阈值化:在用平衡数据集训练模型后应用阈值化方法(E),其中平衡数据集是通过ROS生成的。在大多数情况下,阈值联合ROS比基线阈值(E)表现更好。
(G) RUS和阈值化:在用平衡数据集训练模型后应用阈值化方法(E),其中平衡数据集是通过RUS产生的。在所有情况下,RUS阈值处理都比(E)和(F)差。
Buda等人的工作是全面的,它改变了类不平衡和问题复杂性的水平,已经在三个流行的数据集上训练了近23,000个深度CNN。在一组基线CNN上验证了类不平衡的影响,表明分类性能随着不平衡的增加而严重受损,并且类不平衡的影响似乎随着问题复杂性的增加而增加,例如,CIFAR-10与MNIST。作者得出结论,ROS是解决类不平衡的最佳整体方法,RUS通常表现不佳,使用ROS或RUS的两阶段学习不如使用普通ROS和RUS的学习有效。【不平衡程度】
虽然它确实提供了每个方法性能的合理高层视图,但多类ROC AUC评分并不能洞察潜在的类的性能权衡。目前尚不清楚类分数是否存在很大的差异,或者一个极低的类分数是否导致平均AUC分数大幅下降。我们相信附加的性能指标,包括按类别划分的分数,将更好地解释每种方法在解决类别不平衡方面的有效性,并帮助指导模型选择的从业者。
Buda等人得出结论,应进行ROS,直到所有类别不平衡被消除。尽管他们的实验结果,我们并不同意这种笼统的说法,并认为这可能是问题的依赖,需要进一步的探索。MNIST数据集复杂度相对较低,规模较小,用于证明过采样直到所有类都平衡是最好的。我们不知道 在更复杂的数据集上,或者在包含大数据或类罕见性的问题 上,这种水平的过采样会有多好。此外,在大数据问题中,过采样到这种级别的类平衡可能是非常资源密集型的,通过引入大量冗余数据大大增加了训练时间。
5.1.5 总结数据级方法
调查的两篇文章[23,79]表明,利用ROS消除训练数据中的类不平衡可以显著提高分类结果。Lee等人已经证明,使用RUS或基于增强的过采样生成的半平衡数据预训练DNN可以提高少数类的性能。与Lee等人相反,Buda等人发现普通ROS和RUS通常比两阶段学习表现更好。然而,与Lee等人不同的是,Buda等人使用直到抽样达到类别平衡的数据预先训练他们的网络。由于Lee等人和Buda等人使用不同的不平衡水平进行预训练,并报告了不同的性能指标的结果,因此很难理解两阶段学习 的有效性。动态采样方法优于基线CNN,但我们不知道它与ROS、RUS或两阶段学习相比 如何。尽管有这些限制,动态抽样方法在整个训练过程中自动调整抽样率 的能力是非常有吸引力的。能够自动调整到不同的复杂程度和不平衡程度的方法是有利的,因为它们减少了可调超参数的数量。
实验结果表明,使用ROS可以消除DNN训练过程中的类不平衡。这可能适用于相对较小的数据集,但我们认为这不适用于包含大数据或极端类不平衡的问题。应用ROS直到在非常大的数据集(例如WHOI-Plankton数据)中达到类平衡,将导致大量数据的重复,并将大大增加训练时间。另一方面,RUS减少了训练时间,因此可能在大数据问题中更实用。我们相信,去除冗余样本、减少类噪声和加强类边界的RUS方法将有助于解决这些大数据问题。未来的工作应该进一步探索这些场景。
所有提出的数据级方法都在深度CNN的类不平衡图像数据 上进行了测试。此外,性能指标和问题复杂性 的差异使得直接比较方法变得困难。未来的工作应该在各种数据类型、不平衡级别和DNN架构 上测试这些数据级方法。应该使用多个互补的性能度量 来比较结果,因为这将更好地说明方法的权衡并指导未来的从业者。
5.2 算法级方法
本节包括为解决类不平衡而修改深度学习算法的调查作品。这些方法可以进一步分为新的损失函数、代价敏感学习和阈值移动。Wang等[18]和Lin等[88]引入了新的损失函数,使得少数样本对损失的贡献更大。Wang等[89],Khan等[19]和Zhang等[90]对成本敏感的DNN进行了实验。Khan等和Zhang等提出的方法具有在训练过程中学习成本矩阵的优点。Buda等人在“ROS, RUS和两阶段学习”部分的工作也被包括在本节中,因为他们对阈值调整进行了实验。Zhang等人[91]结合迁移学习、CNN特征提取和基于聚类的最近邻规则来改进不平衡图像数据的分类。最后,Ding等人[92]对极深CNN进行了实验,以确定增加神经网络深度是否可以提高不平衡数据的收敛速度。
5.2.1 (MFE)平方损失
Wang等[18]在用深度MLP对不平衡数据进行分类的实验中,成功地修改了损失函数。从CIFAR100[93]和20个新闻组[94]集合中生成了8个不平衡二进制数据集,包括3个图像数据集和5个文本数据集。这些数据集都相对较小,大多数训练集包含不到2000个样本,最大的训练集仅包含3500个样本。对于生成的每个数据集,测试了ρ = 5 到 ρ = 20之间的不平衡比率。
作者首先表明,均方误差(MSE)损失函数在高度不平衡的情况下很差地捕捉了来自少数类的误差,因为许多负样本主导了损失函数。然后,他们提出了两个新的损失函数,它们对来自少数类的误差更敏感,即平均错误误差(MFE)和均方错误误差(MSFE)。所提出的损失函数 首先将MSE损失分解为平均假阳性误差(FPE)和平均假阴性误差(FNE)两个分量 。FPE (公式12)和FNE (公式13)值然后结合起来定义总系统损失,MFE (公式14),作为每个类的平均误差的和。
Wang等人引入MSFE损失(公式15)作为对MFE损失的改进,声称它更好地捕获来自正类的误差。MSFE可以展开为的形式,展示了优化过程如何最小化FPE和FNE之间的差异。作者认为,这个改进版本将 更好地平衡正类和负类之间的错误率。
(12)
(13)
(14)
(15)
使用 标准MSE损失训练 的深度MLP作为基线模型。然后使用相同的MLP架构来评估 MFE和MSFE损失 。图像分类结果(表7)和文本分类结果(表8)表明,在F-measure和AUC评分方面,所提出的模型在几乎所有情况下都优于基线。
左:表7 用MFE和MSFE进行CIFAR-100分类 右:表8 用MFE和MSFE进行新闻组分类
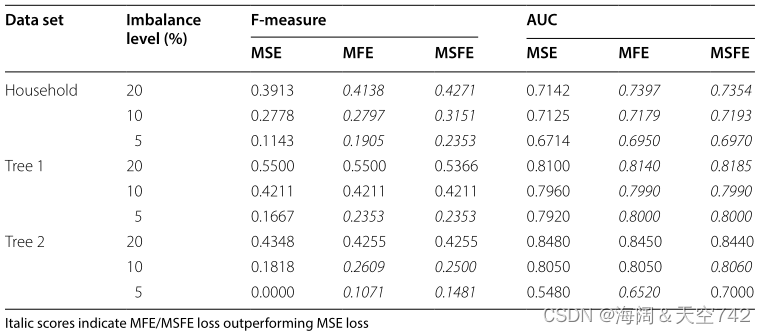
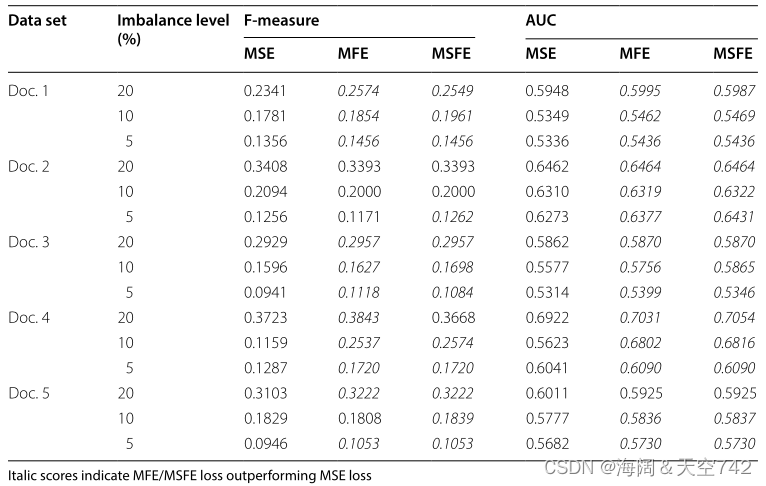
结果表明,MFE和MSFE损失函数几乎在所有情况下都优于MSE损失函数。当 类失衡最严重 时,即失衡水平达到5%时,相对于基准MSE损失的改善最为明显。图像数据上的MFE和MSFE性能增益也比文本数据上的更明显 。例如,MSFE损失改善了家庭图像数据的分类,当类别不平衡水平为5%时,F1-得分从0.1143提高到0.2353。
相对容易实现和集成到现有模型中是使用自定义损失函数解决类不平衡的最大优势之一。与增加训练集大小的数据级方法不同,损失函数 不太可能增加训练次数。损失函数应该可以很 容易地推广 到其他领域,但从比较图像和文本性能结果中可以看出,性能增益因问题而异。为了验证MFE和MSFE的有效性,还需要进行额外的实验,因为目前还 不清楚每个实验进行了多少轮,并且F1-评分和AUC在基线上的增益只有微小的改善。例如,在图像数据实验中,基线上的平均AUC增益仅为0.025,基线上的中位数AUC增益仅为0.008。
5.2.2 焦点损失
Lin等人[88]提出了一个模型,该模型有效地解决了在目标检测问题中经常遇到的极端类不平衡问题,即正面的前景样本数量远远超过负面的背景样本。两级检测器和一级检测器是解决这类问题的著名方法,其中两级检测器通常以增加计算时间为代价实现更高的精度。Lin等人开始确定 快速单级探测器是否能够达到与当前两级探测器相当的最先进的结果 。通过对各种 两级检测器(如R-CNN[95]及其后续产品) 和 一级检测器(如SSD[96]和YOLO[97]) 的分析,类别不平衡被确定为一级检测器实现最先进性能的主要障碍。大量容易分类的负面背景样本产生的不平衡比率通常在ρ = 1000的范围内,导致负面类别占系统损失的大部分。
为了克服这些极端的不平衡,Lin等人提出了焦点损失(FL)(公式16),它重塑交叉熵(CE)损失,以减少容易分类的样本对损失的影响。这是通过将CE损失乘以调制因子来实现的。超参数
调整简单样本向下加权的速率,
是一个类权重,用于增加少数类的重要性。容易分类的例子,其中
->1,导致调制因子接近0,并减少样本对损失的影响。
(16)
提出的单级焦损模型视网膜网(RetinaNet)与几种最先进的单级和两级探测器进行了评估。视网膜网模型由一个骨干模型和两个子网络组成,骨干模型负责从输入图像生成特征图,两个子网络执行对象分类和边界框回归。作者选择 建立在ResNet架构[98]之上的特征金字塔网络(FPN)[88]作为骨干模型,并在ImageNet数据上进行预训练 。他们发现,产生不同尺度特征的FPN CNN在物体检测方面优于普通ResNet。然后使用另外 两个具有单独参数的CNN(子网络)执行分类和边界框回归。提出的 焦点损失函数应用于分类子网,其中总损失计算为所有焦点损失的总和≈100,000个候选。COCO[99]数据集 用于评估所提出的模型与竞争对手的比较。
第一次尝试使用标准CE损失训练视网膜网很快就失败了,并且由于 极端的不平衡 而发散。通过 初始化模型的最后一层,使探测到物体的先验概率为π = 0.01 ,结果显著改善到平均精度(AP)为30.2。额外的实验用于确定适当的焦损超参数,为所有剩余的实验选择γ = 2.0和α = 0.25。
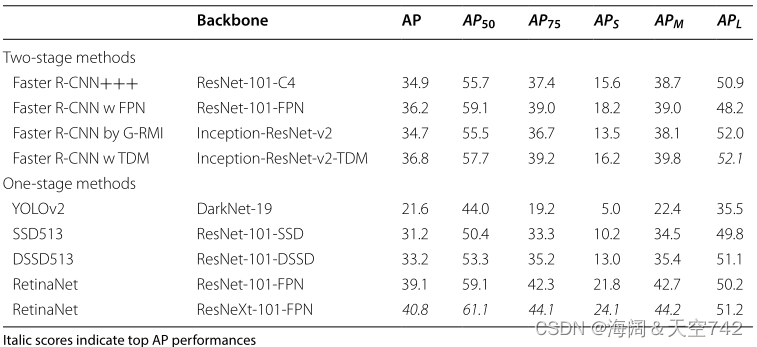
Lin等人的实验表明,使用焦点损失的视网膜网,能够优于现有的一级和两级物体探测器 。它比第二名的单级检测器(DSSD513[100])和最好的两级检测器(Faster R-CNN with TDM[101])分别高出7.6点和4.0点AP增益。与几种在线硬样本挖掘(OHEM)方法[102]相比,RetinaNet的AP从32.8提高到36.0,得分高于最佳方法。表9比较了RetinaNet和7个最先进的一级和二级检测器之间的结果。
表9 在COCO数据集上训练RetinaNet网络(焦点损失)
Lin等人提供了 额外的信息来说明焦点损失方法的有效性 。在一项实验中,他们使用一个 训练好的模型 来计算约107张负样本图像和约105张正样本图像的FL。通过 绘制正样本和负样本的累积分布函数,他们表明,随着γ 的增加,越来越多的权重被放在负样本的一个小子集上,即硬负样本。事实上,当γ = 2时,他们表明大部分损失来自非常小的一部分样本,而且焦点损失确实减少了容易分类的负样本对损失的影响。报告中包含了运行时统计数据,以证明他们能够构建一个快速的单级检测器,其性能优于精确的两级检测器。
新的FL方法不仅适用于类不平衡问题,而且适用于硬样本问题。它解决了 Anand等人定义的主要少数类梯度问题,防止多数类主导损失,并允许少数类对权重更新做出更多贡献 。与MFE和MSFE损失函数类似,优点是 相对容易集成到现有模型中,对训练时间的影响最小 。我们相信 FL方法降低易分类样本权重的能力 将使其能够很好地推广到其他领域。作者直接将FL与CE损失进行了比较,但我们不知道FL与其他现有的类不平衡方法如何比较。未来的工作应该将这个损失函数与跨各种数据集和类不平衡水平的替代类不平衡方法进行比较。
Nemoto等人[103]后来在另一项图像分类任务中使用了FL,即 自动检测罕见的建筑变化 , 例如新建筑。机载建筑图像标注了标签:不变、新建、重建、拆除、重新粉刷屋顶、铺设太阳能电池板。训练数据共包含203358张图像,其中20万张为阴性类,即不变。重新粉刷屋顶和铺设太阳能电池板的类别分别只包含326和222张图像,产生的类别不平衡比率高达900。
Nemoto等人的实验利用了VGG-16 [85] CNN架构,其中 基线CNN使用标准CE损失,图像通过旋转和反转来增强,每个类创建20,000个样本。验证集上的分类精度用于比较 FL损失和 CE损失 。(1)第一个实验使用CE损失函数,并表明在25,000次迭代后,重新粉刷屋顶和铺设太阳能电池板类别的精度开始下降,这表明过拟合。(2)在第二个实验中,使用相同的VGG-16架构和相同的图像增强程序评估 FL损失,每类生成20,000张图像。然而,与第一个实验不同的是,只选择了三个类进行训练和验证:不变、重新油漆屋顶和铺设太阳能电池板图像。为了更好地理解 FL损失的影响,在γ ∈ [ 0 , 5 ] 范围内改变焦损的向下加权参数γ 的值。
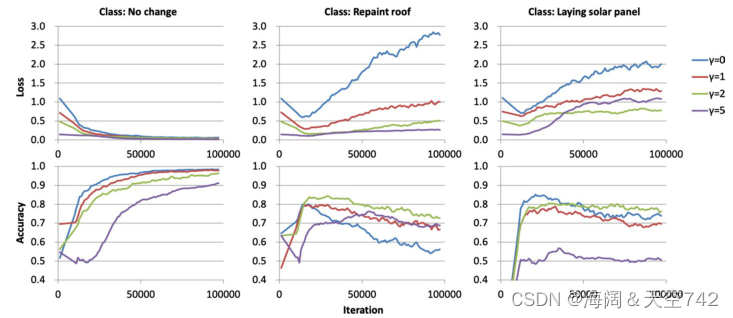
图4显示了 FL 方法的训练和验证的损失和准确性。Nemoto等人得出结论,FL 通过调整每个类的学习速度来改善与 类不平衡和过拟合 相关的问题。通过比较损失可以看出,随着γ γγ的增加,总损失下降得更快,模型过拟合的速度更慢 。然而,目前尚不清楚 γ > 0 的FL是否能产生更好的分类结果。(1)第一个实验的结果无法与第二个实验的结果进行比较,因为总类数已经从6个减少到3个,大大 降低了分类问题的复杂性。(2)图4中的结果表明,当γ = 0 时,不变和铺设太阳能电池板类的精度最高,其中铺设太阳能电池板类是最小的类。当γ = 0 时,焦点损失变为标准交叉熵损失,这表明本实验三个类中有两个类的 CE 优于FL。为了更好地理解FL的有效性,未来的工作应该包括一个具有一致训练数据的基线,解决类不平衡的几种替代方法,以及额外的绩效指标。
5.2.3 (CSDNN)代价敏感深度神经网络
Wang等人[89]采用成本敏感的深度神经网络(CSDNN)方法来检测医院再入院,这是一种类别不平衡的问题,其中一小部分患者在首次就诊后不久就重新入院。巴恩斯犹太医院(Barnes-Jewish Hospital)提供了两组数据,其中包含2007年至2011年的患者记录。(1)第一个数据集是普通医院病房GHW,包含生命体征、临床过程、人口统计、实时床边监测和其他电子数据源。在GHW的2565份记录中,406名患者在30天内重新入院,538名患者在60天内重新入院,分别产生了ρ = 5.3和ρ = 3.8的不平衡比率。(2)第二个数据集是手术室试验数据ORP,包含生命体征、术前数据、实验室检测、病史和手术细节。ORP数据集中有700条记录,其中157例在1年内再入院,124例在30天内再入院。ORP数据的不平衡比例不清楚;作者只是指出,ORP数据比GHW数据不平衡(ρ < 3.8)。各种 性能指标,包括ROC、AUC、准确度、召回率、精密度、阳性预测值(PPV)和阴性预测值(NPV) 被用于评估。PPV和NPV指标相当于正类和负类精度。研究发现,所提出的CSDNN方法优于现有的医院再入院预测系统,并已在Barnes-Jewish医院部署。
Wang等人 没有使用传统的独热编码来表示分类值,而是使用分类特征嵌入方法来创建更有意义的表示。此外,他们使用CNN从时间序列数据中自动提取特征,即患者的生命体征数据。将提取的特征和分类嵌入连接起来,形成最终的输入特征向量,馈送到DNN进行分类。DNN由两个隐藏层组成,每层有128和64个神经元。CE损失函数被修改为含有预定义的代价矩阵,迫使网络最小化错误分类代价。对于GHW数据集,假阴性误差的代价是假阳性误差代价的2倍。同样,对于ORP数据集,假阴性代价设置为假阳性错误代价的1.5倍。
分类特征:用来表示分类的,他不像数值类特征是连续的,分类特征是离散的。eg:性别 城市 颜色 IP地址 用户的账号ID
分类特征的编码方式:1.自然数编码/序列编码-Ordinal Encoding
某些分类本来就有一定的排序,这种情况下就可以使用简单的自然数编码。学位:学士-0 硕士-1 博士-2
2.独热编码-One-Hot Encoding
使用独热编码可以让不同的分类处在“平等的地位”,不会因为数值的大小而对分类造成影响。
颜色分类(假设只有3种颜色):红色-100 黄色-010 蓝色-001
3.目标编码-Target Encoding
目标编码是表示分类列的一种非常有效的方法,并且仅占用一个特征空间,也称为均值编码。该列中的每个值都被该类别的平均目标值替代。这可以更直接地表示分类变量和目标变量之间的关系。
4.散列编码-Hash encoding
散列函数也是大家常听到的哈希函数。散列函数是一个确定性函数,它映射一个潜在的无界整数到有限整数范围[1,m]。
假如有一个分类有1万个值,如果使用独热编码,编码会非常长。而使用了散列编码,不管分类有多少不同的值,都会转换成长度固定的编码。
5.分箱计数-Bin-Counting
分箱计数的思维有点复杂:他不是用分类变量的值作为特征,而是使用目标变量取这个值的条件概率。换句话说,我们不对分类变量的值进行编码,而是要计算分类变量值与要预测的目标变量之间的相关统计量。
Wang等人的 CSDNN方法与五个基线分类器进行了比较,包括三种决策树方法,一个SVM和一个ANN 。只有一种基线方法可以解决类不平衡问题,即使用随机森林(RF)分类器进行欠采样。除NPV外,该方法在所有性能指标上都优于所有基线分类器 。我们能够观察到类的性能权衡,因为报告了多个互补的性能度量。在GHW数据集上,CSDNN的AUC为0.70,超过了亚军(ANN分类器)的AUC为0.62。然而,不幸的是,不能确定代价敏感的损失函数是否为性能改进的原因 ,因为还有其他几个因素可能有助于改进,例如 分类特征嵌入和时间序列特征提取 。需要一个包括CNN特征提取器和分类嵌入的基线来判断代价敏感损失函数的有效性。
我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果

将成本矩阵合并到CE损失中是一个较小的实现细节,应该很好地推广到其他领域和架构,对训练时间的影响最小。确定理想成本矩阵的过程可能是最大的限制。 在数据集相对较小的传统机器学习问题中,模型可以在一系列成本上进行验证,并为最终模型选择最佳成本矩阵。然而,当使用DNN和大型数据集时,搜索最佳成本参数的过程可能非常耗时,甚至不切实际。在未来的工作中包括一系列成本矩阵的结果,将有助于证明随着成本的变化而发生的按类别的性能权衡。
5.2.4 (CoSen)成本敏感的CNN学习成本矩阵
Khan et al.[19]引入了一种有效的代价敏感的深度学习过程,在训练过程中联合学习网络权重参数和误分类代价。本文提出的方法CoSen CNN针对 6个不同不平衡程度的多类数据集进行评估:MNIST、CIFAR-100、Caltech-101[104]、MIT-67[105]、DIL[106]和MLC[107]。 对于MNIST, CIFAR-100, Caltech-101和MIT-67数据集,ρ = 10的类不平衡比率进行了测试。DIL和MLC数据集的不平衡比率分别为ρ = 13和ρ = 76 。在ImageNet数据上预训练的VGG-16在整个实验中被用作特征提取器和基线CNN。
CoSen CNN学习的代价矩阵被用来修改VGG-16 CNN最后一层的输出,对代价越高的样本给予越高的重要性。该小组提出了 三种改进的损失函数,将学习到的成本参数加入MSE损失,SVM Hinge损失和CE损失。训练过程学习网络权重参数和错误分类成本参数,每次保持一个固定,并在训练期间将相对于另一个的成本最小化。成本矩阵的更新依赖于当前分类误差、总体分类误差和类与类的可分离性(C2C)。C2C可分性测量类内样本距离和类分离边界大小之间的关系。
CoSen CNN是根据基线CNN、多种采样方法和多种成本敏感方法进行评估的。 抽样分类方法采用两层神经网络, 成本敏感方法采用SVM和RF 。SVM和RF基线分类器使用预训练的VGG-16 CNN提取的特征作为输入。 SOSR CNN是一种代价敏感的深度学习方法,它将一个固定的代价矩阵合并到损失函数中[108]。
表10 对代价敏感的CoSen CNN结果(准确度)
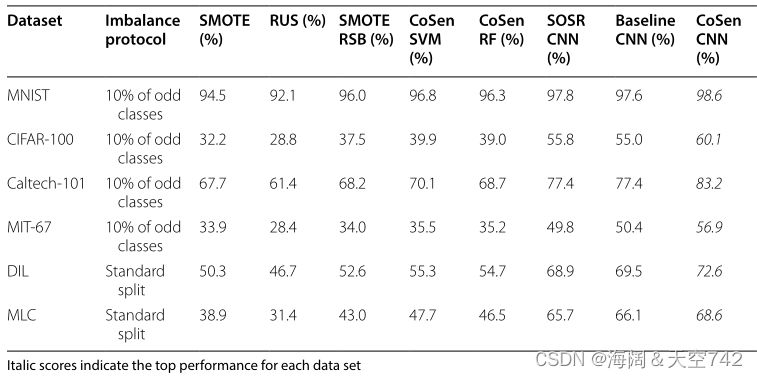
总体准确性表明,所提出的CNN在所有数据集上优于所有7种替代技术。表10显示,CoSen CNN表现异常出色,在CIFAR-100、Caltech-101和MIT-67上的表现优于亚军分类器超过5% 。实验结果中列出的 第二个最佳分类器介于SOSR CNN和基线CNN之间。在所有情况下,SMOTE优于RUS,混合采样方法SMOTE-RSB[109]优于SMOTE。不幸的是,在所有7种类别不平衡方法中,精度是唯一的性能指标,而在类别不平衡的情况下,精度是不可靠的,这些结果可能具有误导性。
F1和G-Mean得分报告表明,所提出的 CoSen CNN在所有数据集上都优于基线CNN, 例如,在Caltech-101数据集上,F1得分从0.389提高到0.416。Khan等人还给出样本网络训练时间, 表明增加的成本参数训练使每个训练周期增加了几秒 ,但对推理步骤几乎没有影响。在另一个实验中,作者使用 类别表示、数据可分离性和分类错误定义了三个固定成本矩阵来推导成本,并表明动态成本矩阵方法优于所有三种情况。
有趣的是,基线CNN,没有修改类不平衡,是CoSen CNN的第二名,在所有情况下都优于抽样方法,SVM和RF分类器。这 并不意味着没有类不平衡修改的深度CNN比传统采样方法更好地解决类不平衡问题。相反,这证明了重用经过大量数据训练的强大特征提取器的力量,例如,在这个实验中,超过130万张图像。
如前所述,代价敏感学习的难点之一是 选择合适的代价矩阵,通常需要领域专家或网格搜索过程。Khan等人提出的CoSen方法消除了这一要求,并提供了更多的端到端深度学习框架 ,能够从类不平衡数据中学习。作者报告了在各种数据集上的大量实验的结果,网络参数和成本参数的联合学习 似乎是从类不平衡数据中学习的优秀候选。未来的实验应该探索这种 成本敏感的方法从包含替代数据类型、大数据和类罕见性的问题中学习 的能力。
5.2.5 输出阈值处理
除了在ROS, RUS和两阶段学习一节中讨论的数据采样方法外,Buda等[23]还试验了调整CNN输出阈值以提高整体性能。他们分别使用了在ρ ∈ [ 1 , 5000 ] 和ρ ∈ [ 1 , 50 ] 范围内不同类不平衡比率的MNIST和CIFAR-10数据集。准确度评分用于将阈值与基线CNN、ROS和RUS方法进行比较,这些方法在ROS、RUS和两阶段学习部分中有描述。
作者通过将每个类的网络输出除以其估计的先验概率来应用阈值化,有效地降低了对少数类样本误分类的可能性。他们还考虑了将阈值移动与RUS和ROS相结合的混合方法。对于MNIST和CIFAR-10数据集上的所有级别的类别不平衡,阈值方法优于基线CNN。在MNIST数据的所有不平衡水平上,阈值处理优于ROS和RUS,但在CIFAR-10数据上,有几个实例是ROS优于阈值处理。阈值联合ROS的表现尤其好,几乎在所有情况下都优于其他方法。
正如在“ROS、RUS和两阶段学习”一节中所讨论的,Buda等人探索了各种深度学习方法来解决广泛的类不平衡水平。他们已经证明,整体精度可以通过阈值移动来提高,并且可以相对容易地使用先验类概率来实现。不幸的是,准确性评分并不能解释个别类的表现和权衡。由于 阈值只在推理过程中应用,它不影响训练时间。这也意味着阈值不会影响权重调整,因此不会提高模型区分类别的能力 。 无论如何,它仍然是一种 减少多数类偏差的合适方法,可以在已经训练好的网络上快速实现,以改善分类结果 。
5.2.6 类别中心
Zhang等人[91]对来自CIFAR-10和CIFAR-100数据集的类不平衡图像数据进行了深度表示学习实验。他们提出了一种解决类不平衡的方法,类别中心(CC),该方法结合了迁移学习、深度CNN特征提取和最近邻鉴别器。通过 随机欠采样,从每个原始数据集中创建了三个类不平衡分布,即Dist.A, Dist.B和Dist.C 。在Dist.A和Dist.B中,有一半的类大小减小,分别创建了ρ = 10和ρ = 20 的不平衡水平。在Dist.C,所有类的减少水平线性增加,最大不平衡ρ = 20。例如,CIFAR-100数据集的Dist. C在前10个类别中每个类别包含25张图像,在接下来的10个类别中每个类别包含75张图像,然后在接下来的10个类别中每个类别包含125张图像,等等。该模型与基线CNN和过采样方法进行了比较。平均精度 性能度量用于比较结果。
参考-聚类
Zhang等人观察到 同类相似图像在CNN深特征空间中倾向于很好地聚类。他们讨论了 由CNN的最后一层创建的决策边界,分类层负责分离这些深层特征簇,指出当存在类不平衡时,决策边界有更大可能出现大错误。为了避免在类不平衡的情况下出现这种边界误差,他们建议 使用CNN提取的高级特征来计算每个类在深度特征空间中的质心。然后,通过将新图像分配到最近的深特征分类中心,可以使用这些深特征空间中的分类中心对新图像进行分类。在 ImageNet数据上预训练的VGG-16网络 在整个实验中被用作基线CNN。该方法 对不平衡分布的CNN进行微调,将所有图像映射到相应的深度特征表示,然后计算每个类的质心 。在 测试时,使用训练好的CNN从新图像中提取特征,并将每个新图像分配到其在特征空间中最近的类别中心的类别,由特征之间的欧几里得距离定义。Zhang等人声称分类中心明显比CNN的分类层生成的边界更稳定,但没有证据支持这一观点。
表11 CIFAR-10数据分类中心(AP)
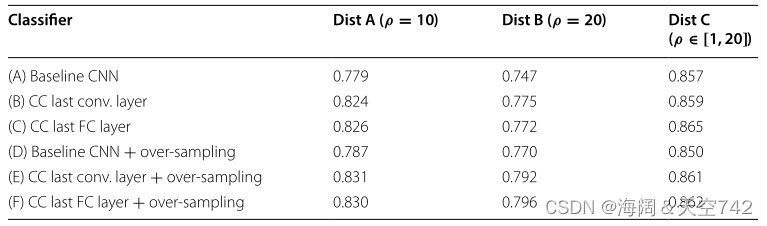
Zhang等的部分研究结果见表11。作者尝试使用两个不同的CNN层进行特征提取,最后一个为卷积层(B)和全连接层©,以确定是否一组特征表现更好。最后,对基线和类别中心方法进行过采样,以确定数据采样对 CC (D-F)的影响。这些结果表明,CC方法(B, C)在所有三种不平衡场景的平均精度上优于基线CNN (A) 。结果还表明,过采样(D-F)的加入改善了CIFAR-10分布的结果,但Dist.C除外。例如,过采样(E)的CC方法将区域A的平均精度从基线(A)的0.779提高到0.830。CIFAR-100的结果是相似的,在这个意义上,所提出的方法(B, C)优于基线(A)的所有三个分布。与CIFAR-10数据不同的是,有趣的是,在对CIFAR-100分布进行分类时,过采样并没有改善所提出的方法的结果,但它确实改善了基线CNN。
我们认为,CC方法最大的局限性是它高度依赖于DNN生成良好聚类的判别特征的能力。如果大量的类平衡、标记的训练数据无法用于预训练DNN,深度特征边界可能不够强,无法应用CC方法。在方法(D-F)中使用的过抽样方法的细节是未知的,所以我们不知道过抽样是否应用于类平衡或其他比例的水平。此外,我们不知道这些结果是几轮实验的平均值,还是仅仅是单个实例的结果。由于没有平衡分布结果,过采样方法不清楚,并且只有一个性能指标,很难理解所提出的CC方法在从类不平衡中学习时的表现如何。
5.2.9 算法层面的方法总结
本节包括8种算法级方法,用于解决DNN的类不平衡。Wang等人提出的MFE和MSFE损失函数在若干图像和文本数据集上优于标准MSE损失。Lin等人的焦点损失降低了易于分类的样本的权重,被用于在COCO数据集上优于几个最先进的一级和两级物体探测器。Nemoto等人还研究了FL,以检测罕见的建筑变化,但结果有些矛盾。Wang等人使用一种成本敏感的方法,将预先定义的误分类代价纳入CE损失函数,以预测医院再入院。Khan等人提出了一种成本敏感的深度CNN (CoSen),在训练过程中联合学习网络参数和成本矩阵参数。总体准确性表明,CoSen CNN在六个图像数据集上始终优于基线CNN、多种采样方法和多种成本敏感方法。类似地,Zhang等人将DBN与一种搜索最佳误分类代价的进化算法相结合,但结果再次与精度度量一起报告,并且难以解释。Buda等人演示了如何使用先验分类概率来调整DNN输出阈值,以提高分类图像数据的整体准确性。Zhang等人提出了类别中心,这是一种结合迁移学习、深度CNN特征提取和最近邻深度特征聚类判别规则来解决类不平衡的方法。最后,Ding等人对极深神经网络(> 10层)进行了实验,并表明由于误差曲面的变化,允许更快的优化,较深的网络可能会更快地收敛。
与数据采样方法不同,所提出的算法级方法不改变训练数据,也不需要任何预处理步骤。与“数据级方法”部分中由多位作者推荐的ROS相比,算法级方法不太可能影响训练时间。这表明,算法级方法可能 更适合解决大数据问题。除了定义误分类代价外,算法级方法几乎不需要调优。幸运的是, 本文提出了两种自动学习成本参数的方法。能够以最小的调整适应不同问题的方法是首选,因为它们可以快速应用于新问题,并且不需要特定的领域知识。焦点损失函数和CoSen CNN展示了这种灵活性,我们相信它们将很好地推广到许多复杂的问题领域。
一般来说,缺乏将深度学习算法级方法与替代类不平衡方法进行适当比较的研究。这是由于 基线模型 的糟糕选择、性能指标 的不足以及特定领域的实验 未能隔离所提出的类不平衡方法。与调查的深度学习数据级方法类似,本节中的大多数方法都是在 使用深度CNN的图像数据 上进行评估的。我们最感兴趣的是解决类不平衡的深度学习方法之间的比较,以及与解决类不平衡的传统机器学习技术的比较。我们相信,填补这些研究空白并正确评估这些方法将对未来的深度学习应用产生巨大影响。
5.3 混合方法
本节中用于解决类不平衡的深度学习技术结合了算法级和数据级方法。Huang等人[22]使用了一种新的损失函数和采样方法,在他们的大边缘局部嵌入(LMLE)方法中生成更多的判别表示。Ando和Huang[117]提出了第一个深度特征过采样方法——深度过采样(Deep Over Sampling, DOS)。最后,Dong等人[118]通过新的损失函数和硬样本挖掘解决了大规模图像分类中的类不平衡问题。
5.3.1 (LMLE)大边际局部嵌入
Huang等人[22]提出了LMLE方法,用于学习不平衡图像数据的更具判别力的深度表示。该方法的动机是观察到少数类是稀疏的,通常包含高变异性,因此这些少数类样本的局部邻域很容易被另一类样本入侵。通过将一种新的quintuplet采样方法与一种新的three header Hinge损失函数相结合,从不平衡的图像数据中学习了保持同一类局域性并增加类间区别的深度特征表示。这些形成了定义良好聚类的深层特征表示,然后使用快速聚类KNN分类方法标记新样本。提出的LMLE方法被证明在CelebA[119]数据集上取得了最先进的结果,其中包含高达ρ = 49 的高不平衡水平。
(1)quintuplet采样方法 根据类间和类内聚类距离选择一个锚点和另外四个样本。在训练过程中,每个小批从少数和多数类中选择相同数量的quintuplet。通过quintuplet采样方法获得的五个样本被馈送到五个相同的CNN,它们的输出被聚合成一个单一的结果。 (2)然后使用three header Hinge损失计算误差并相应地更新网络参数。这种正则化的损失函数限制了深度特征表示,使得聚类崩溃为类间和类内聚类之间具有适当边缘的小邻域。
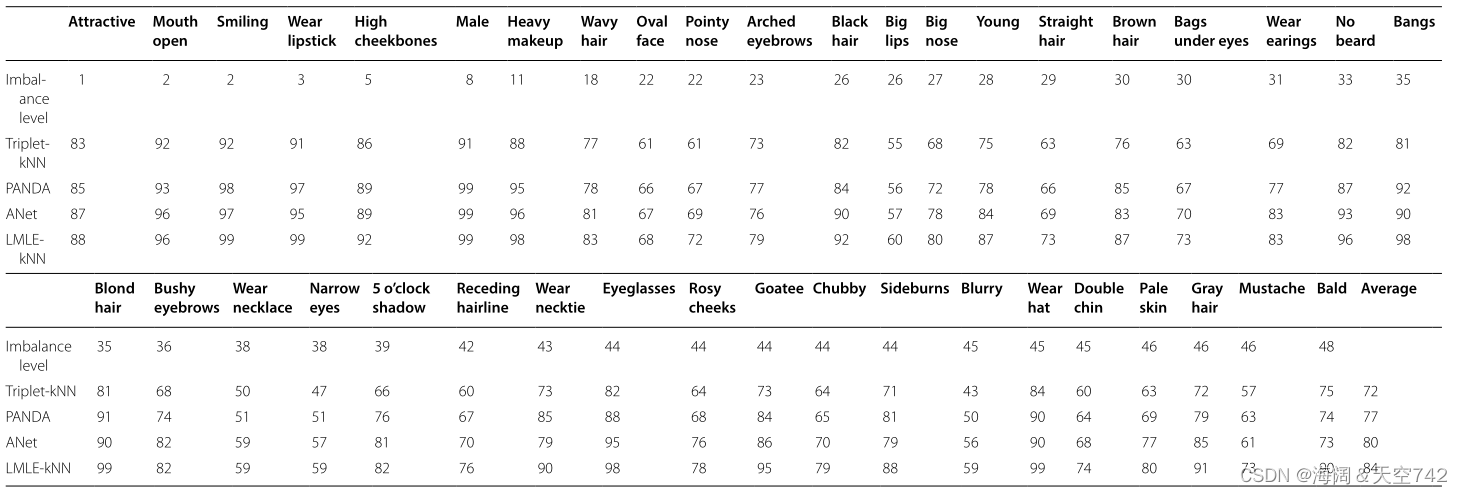
CelebA数据集包含带有40个属性的面部图像,不平衡水平高达ρ = 49 (秃头vs非秃头)。总共使用16万张图像来训练CNN,然后将学习到的深度表示馈送到改进的KNN分类器。 平衡精度(Eq. 9)度量是为每个面部属性计算的。 LMLE-KNN 模型与面部属性识别领域的三个最先进的模型进行了比较:Triplet-kNN [120], PANDA[121]和ANet[122]。表13中的 结果显示LMLE-KNN在所有面部属性上的表现与其他方法一样好,甚至更好。与其他方法相比,性能收益随着不平衡程度的增加而增加,例如,与第二名相比,LMLE将Bald属性的准确度从75提高到90。作者 将LMLE-KNN与BSDS500[123]边缘检测数据集上的14个最先进的模型 进行比较时,获得了类似的结果。
表13 LMLE CelebA面部属性识别(平衡精度)
Huang等人是最早使用类不平衡数据研究深度表示学习 的人之一。提出的LMLE方法结合了几个强大的概念,在流行的图像数据基准上获得了最先进的结果,并显示出未来在其他领域工作的潜力。然而,高性能的结果是有代价的,因为系统既复杂又计算昂贵。在 进行quintuplet采样之前,必须对数据进行预聚类,如果给定的数据集没有合适的特征提取器,这可能会很困难。作者 建议初始聚类并不重要,因为学习过程可以用于在整个训练过程中重新聚类数据。此外,每次通过系统的前向传递都需要从五个CNN进行计算,每个CNN对应一个采样的quintuplet。我们同意Ando和Huang[117]的说法,使LMLE适应新问题将需要许多任务和模型特定配置。这可能会阻止许多从业者在尝试解决类不平衡问题时使用这种方法,因为大多数人将求助于更简单和更快的方法。Dong等人在“类校正损失(CRL)和硬样本挖掘”部分提供的结果将表明LMLE在CelebA数据集上优于ROS、RUS、阈值和代价敏感学习。
5.3.2 (DOS)深度过度采样
Ando和Huang[117]在DOS框架中将过采样引入到CNN产生的深度特征空间中。通过从五个流行的图像基准数据集生成不平衡数据集,包括MNIST、mist -back-rot、SVHN[124]、CIFAR-10和STL-10[125],对所提出的方法进行了广泛的评估。分类精度和查全率、F1分数和AUC被用来评估DOS框架与其他方法的区别。
DOS框架由两个同步的学习过程组成,分别对底层和上层参数进行优化。下层负责获取嵌入函数,而上层则学习使用生成的嵌入来区分类。为了学习嵌入特征,CNN的输入包含一个类标签和一组深度特征目标,这是一个来自深度特征空间的类内最近邻聚类。然后,微聚类损失计算每个深度特征目标与其均值之间的距离,约束下层的优化以将深度特征嵌入向类均值移动。Ando和Huang指出,将目标表示转移到相应的局部均值将导致更小的类内方差,并加强学习表示中的类区别 。用于区分类的上层是通过取CE损失的加权和来训练的,即每个深度特征目标的CE损失。
Embedding就是从原始数据提取出来的Feature,那个通过神经网络映射之后的低维向量。
深度过采样组件是从深度特征空间中选择 K个类内邻居的过程。为了解决类的不平衡,类内邻居的数量应该在类之间有所不同。例如,对少数类使用k = 3,对多数类使用k = 0,将用额外的嵌入补充少数类,同时保持多数类不变。
在第一个DOS实验中,他们将DOS框架与处理类不平衡的两种替代方法进行了比较,大边际局部嵌入(LMLE)[22]和成本敏感学习的三重重采样(TL-RS-CSL)。MNIST反向旋转图像用于创建三个数据集,其类减少率分别为0%、20%和40%。研究表明,DOS框架在20%和40%的降低率时优于TL-RS-CSL和LMLE ,并且随着不平衡水平的增加,DOS性能的恶化速度比TL-RS-CSCL和LMLE都慢。例如,在不平衡的MNIST-back-rot数据上(减少了40%),DOS的平均类召回率为75.43,而LMLE的为70.13。
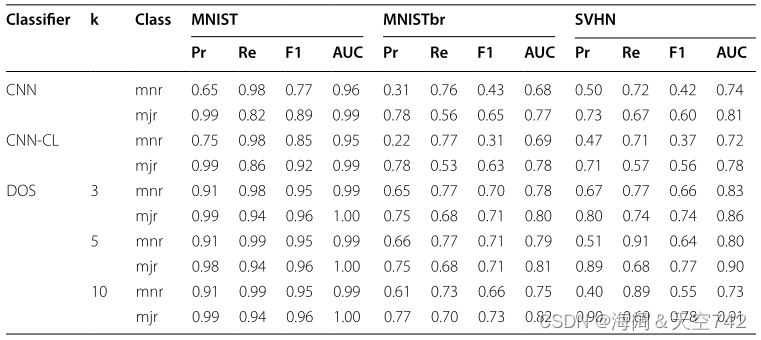
左:表14 不同不平衡的DOS 右:表15 不同k的DOS
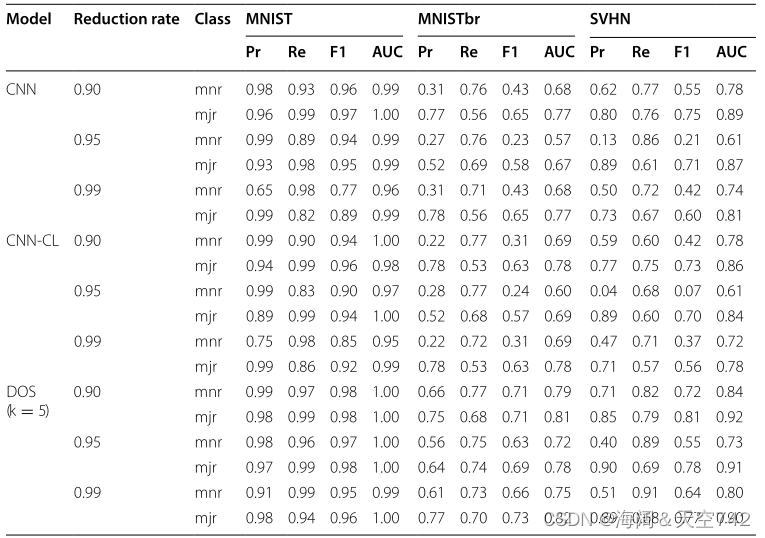
在第二个实验中,将DOS框架与基本CNN和用CNN深度特征(CNN-CL)训练的KNN分类器进行比较。使用三个不同的数据集生成不平衡的数据集,减少率为90%、95%和99%,产生不平衡比率高达ρ = 100。表14中的结果再次显示,随着类不平衡程度的增加,DOS框架性能的改进变得更加明显。第三个层次的不平衡(减少率为99%)表明,DOS框架在所有数据集和所有性能指标上都明显优于CNN和CNN-CL。
最后的实验 使用平衡的数据集来检查DOS参数 k kk 的灵敏度,该参数定义了要采样的深度特征类内邻居的的数量 。从表15可以看出,当 k 增加到10时,少数类的表现开始恶化。这些结果还表明,所提出的DOS框架在平衡数据集上优于基线CNN和CNN-CL。
DOS方法在多数类和少数类之间,或者在精度和召回率之间,没有显示出明显的性能权衡。在 不存在类别不平衡的情况下 ,它优于其他方法的能力非常吸引人,因为这种品质在类别不平衡的学习方法中并不常见。最重要的是,当 将CNN或CNN-CL与少数类的DOS模型进行比较时,观察到的一些性能增益非常大 ,例如,在99%的不平衡率下,MNIST-back-rot和SVHN F1得分分别从0.43增加到0.66和0.42增加到0.64。像其他混合方法一样,DOS比更常见的数据级和算法级方法更复杂,这可能会阻止统计学家使用它。然而,我们同意Ando和Huang的观点,DOS方法通常可以扩展到其他领域和深度学习架构。未来的工作应该在这些新环境中评估DOS方法,并将结果与整个调查中提出的其他类不平衡方法进行比较。
5.3.3 (CRL)类矫正损失与困难样本挖掘
Dong等人[118]提出了一种端到端深度学习方法,用于解决大规模图像分类中的极端类别不平衡问题。他们明确地将他们的工作与更传统的包含小水平不平衡的小规模类不平衡问题区分开来,这表明这种方法可能无法推广到小规模问题。
实验结果将所提出的方法与数据采样、代价敏感学习、阈值移动和一些相关的最先进的方法 进行了比较。平均敏感性分数被用来作为主要的绩效指标,通过类平均召回率分数。该方法将少数类硬样本挖掘与正则化目标函数类校正损失(CRL)相结合。
硬样本挖掘选择少数样本,这些样本预计对每个小批量具有更大的信息量,使模型用更少的数据更有效地学习。Dong等人努力以渐进式的方式矫正或纠正类分布偏差,通过 训练使少数类偏差逐渐增强 。与LMLE[22]试图强化多数和少数类的结构不同,这种方法只会加强少数类的偏差。为了识别少数类,所有类都按其大小排序,然后从最小到最大进行选择,直到它们的总和最多为数据集大小的一半,确保少数类最多占训练batch的一半。在执行硬样本挖掘时,要同时考虑类级和样本级硬度度量。(1)在类层面,硬阳性指的是识别能力弱,即正确标记的样本预测得分低。或者,硬阴性是明显的错误,样本被错误地标记为高预测分数。(2)在样本级别,硬阳性是由在特征空间距离中具有远距离的正确标记的图像定义的,而硬阴性是在特征空间中距离较近的错误标记的图像。
CRL损失函数Eq. 17,其中 与类不平衡的水平成线性比例,对优化过程施加了批量类平衡约束。这减少了多数类过度代表所造成的学习偏差。CRL正则化施加了一种不平衡自适应学习机制,对高度不平衡的标签施加更多的权重,而对不平衡程度较低的标签降低权重 。通过实验探索了三种不同的损失标准
,其中Triplet Ranking损失[126]被选为许多实验的默认值。
(17)
实验通过使用所提出的方法扩展最先进的CNN架构并对三个基准数据集进行分类来进行。CelebA数据集包含ρ = 49的最大不平衡水平。X-Domain[127]数据集包含245,467张零售店服装图像,这些图像标注了9个多类属性标签,其中165 , 467 张用于训练。X-Domain包含ρ > 4000的极端类不平衡比率。从CIFAR-100集中生成了几个不平衡的数据集,不平衡比率高达ρ = 20 ,以演示CRL如何处理增加的不平衡水平。
表16 CRL与CelebA数据(平衡精度)
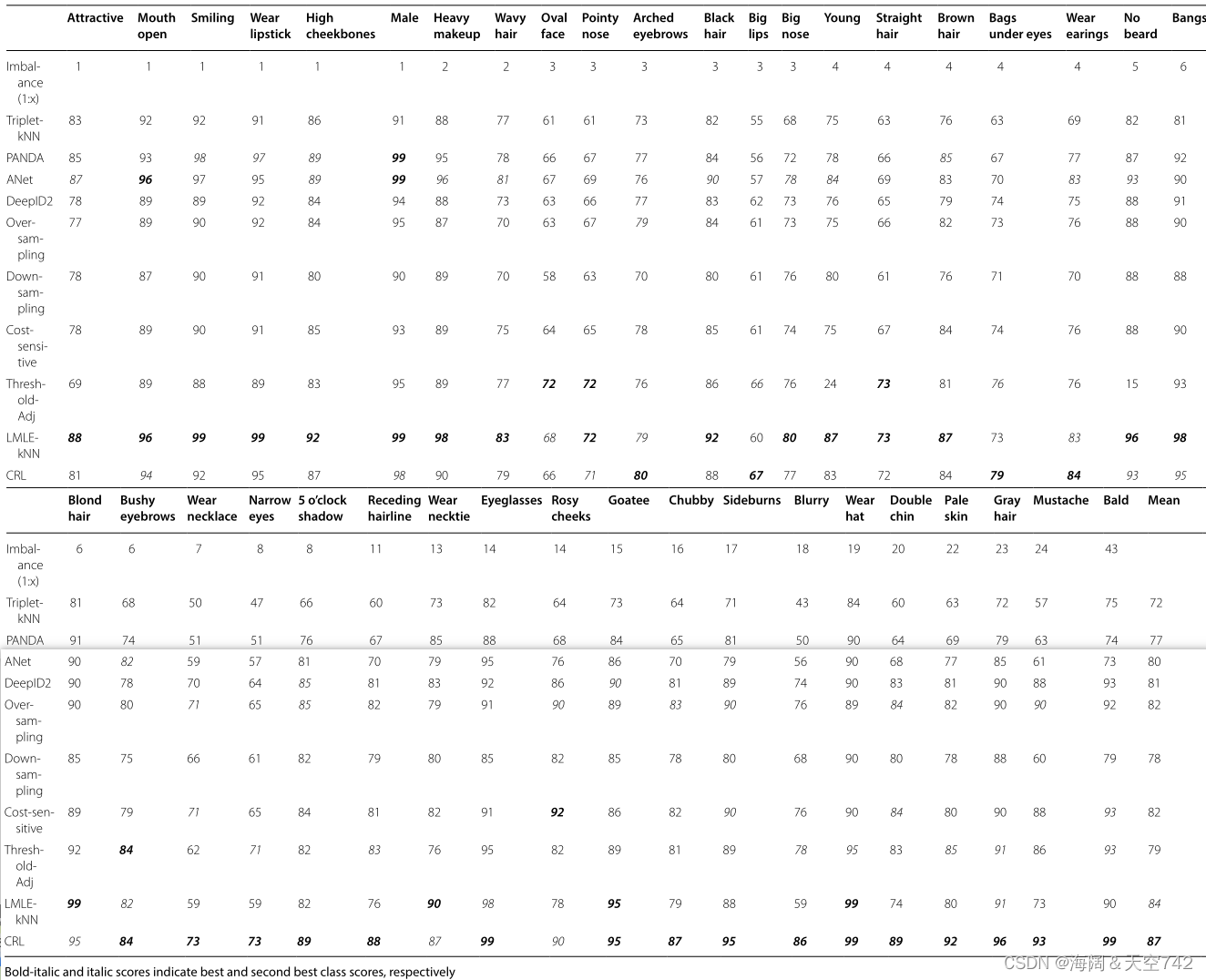
表16为CelebA面部属性识别结果。所有提出的类不平衡方法都是在5层CNN, DeepID2[128]的基础上实现的。参考数据属性的下半部分,当不平衡比率ρ ≥ 6时,欠采样几乎总是比过采样、代价敏感学习和阈值移动表现得更差。根据平均敏感性得分,过采样和成本敏感学习表现相同,分别优于阈值和欠采样3%和4%。
与最佳非不平衡学习方法(DeepID2)和最佳不平衡学习方法(LMLE)相比,本文提出的CRL方法的平均灵敏度分别提高了6%和3%。通过分析属性级别的分数,我们可以看到,在许多 类不平衡水平较低的情况下,LMLE的性能优于CRL ,例如在吸引人的属性上,LMLE的性能优于CRL 7%。董等人承认LMLE似乎比CRL更好地处理低级不平衡。 对于许多 高不平衡属性,非不平衡方法DeepID2优于LMLE方法。 当类不平衡达到最高时,所建议的CRL方法执行得最好,并且比其他方法获得最显著的性能增益。
在X-Domain数据集的另一个实验中,CRL在所有类别上都优于LMLE,比LMLE实现了近5%的平均灵敏度性能增益。成本敏感学习、阈值和ROS的得分都比CRL低6%左右,而RUS的表现也非常糟糕。当对来自CIFAR-100数据集的平衡分布进行实验时,CRL方法应用于三个最先进的CNN模型:CifarNet[129]、ResNet32[98]和DenseNet[130]。对于每个模型,CRL方法在基线上持续改进,平均灵敏度分别提高3.6%、1.2%和0.8%。Dong等人的额外成本分析表明,CRL明显比LMLE快,在给定的测试用例上,CRL只需要27.2小时,而LMLE需要166.6小时。
通过综合实验,验证了CRL算法在大规模类不平衡图像数据处理上的优越性。它被证明有效地优于许多流行的类不平衡方法,包括ROS, RUS,阈值,代价敏感学习和LMLE。它的训练速度也明显快于LMLE方法。作者清楚地区分这种方法在包含高度不平衡的大规模图像数据中是有效的,面部属性检测的结果表明,LMLE对许多不平衡水平较低的面部属性表现更好。这表明CRL方法可能不适合包含低水平类不平衡的类不平衡问题。尽管进行了初步观察,但是应该在具有不同复杂程度的广泛数据集上评估CRL,以便更好地理解何时应该使用它。探索CRL方法从非图像数据中学习的能力也很有趣。
5.3.4 混合方法总结
本节分析了解决类不平衡的三种混合深度学习方法。Huang等人提出的LMLE方法在CelebA和BSDS500图像数据集上优于几种最先进的模型。Ando和Huang介绍了DOS方法,该方法学习了一个产生更多鉴别特征的嵌入层,然后在深度特征空间中通过过采样补充少数类。在多类不平衡图像数据集上,DOS被证明优于LMLE和基线CNN。最后,Dong等人的CRL损失函数被证明优于四种最先进的模型,ROS, RUS,代价敏感学习,输出阈值和LMLE在CelebA数据集上。
Dong等人提供的结果是最有信息量的,因为他们将CRL方法与LMLE和其他几个数据级和算法级深度学习方法进行了比较,以解决类不平衡问题。他们不仅表明,随着类不平衡水平的增加,CRL方法优于其他方法,而且还说明了RUS、ROS、阈值和代价敏感学习的有效性。从他们在CelebA数据集上的结果来看,我们观察到ROS和代价敏感学习的平均表现优于RUS和阈值移动。这些结果与“数据级方法”部分的结果一致,表明ROS通常是解决DNN类失衡的一个很好的选择。Dong等人也证实了我们最初的观察,LMLE是相当复杂和资源密集型的,通过证明CRL的训练速度比LMLE快6倍。直接比较DOS和CRL将被证明是有用的,因为这两种方法的性能都优于LMLE方法。
一般来说,从类不平衡数据中学习的混合方法比算法级方法和数据级方法更复杂,也更难实现。这是意料之中的,因为算法级和数据级方法都是为了提高分类性能而结合起来的。随着学习者变得越来越复杂,他们的灵活性和易用性将会下降,这可能会使他们更难适应新问题。
表16中CelebA数据集上的按类别的性能分数表明,当受到不同程度的类别不平衡时,不同的方法表现得更好。这一观察结果支持了我们对未来研究的需求,即评估各种类不平衡水平和问题复杂性的多种深度学习方法。当模型在各种数据类型和DNN架构上进行评估时,我们希望看到模型之间类似的权衡。填补当前研究中的这些空白将有助于塑造未来涉及类别不平衡、类别稀少和大数据的深度学习应用。
6. 讨论调查的工作
为了提供一个高层次的总结,更好地比较目前的类失衡深度学习方法,我们将调查的作品及其数据集汇总在表17和表18中。在表17中,每一组提出的方法被分为三种类型之一:数据、算法或混合。传统机器学习中处理类不平衡的所有通用方法都已扩展到深度学习中,包括:随机抽样、知情抽样、代价敏感学习、阈值和混合方法。
表17 深度学习类失衡方法总结
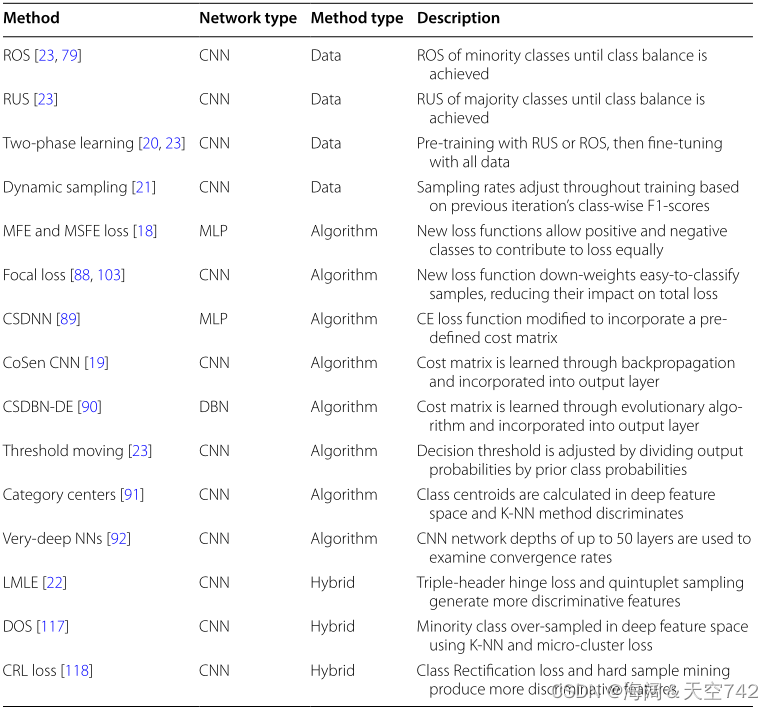
解决深度学习中类不平衡的数据级技术包括:ROS[23,79]、RUS[23]、带采样的两阶段学习[20,23]和基于性能的动态采样[21]。(1)ROS实验报告了类平衡水平的过采样在不平衡的图像数据上效果最好。 (2)两阶段学习方法使用RUS或ROS用类平衡数据集预训练DNN,然后使用所有数据对网络进行微调。 (3)动态抽样方法使用按类的F1分数来确定抽样率,允许模型以更高的速率对困难的类进行抽样。
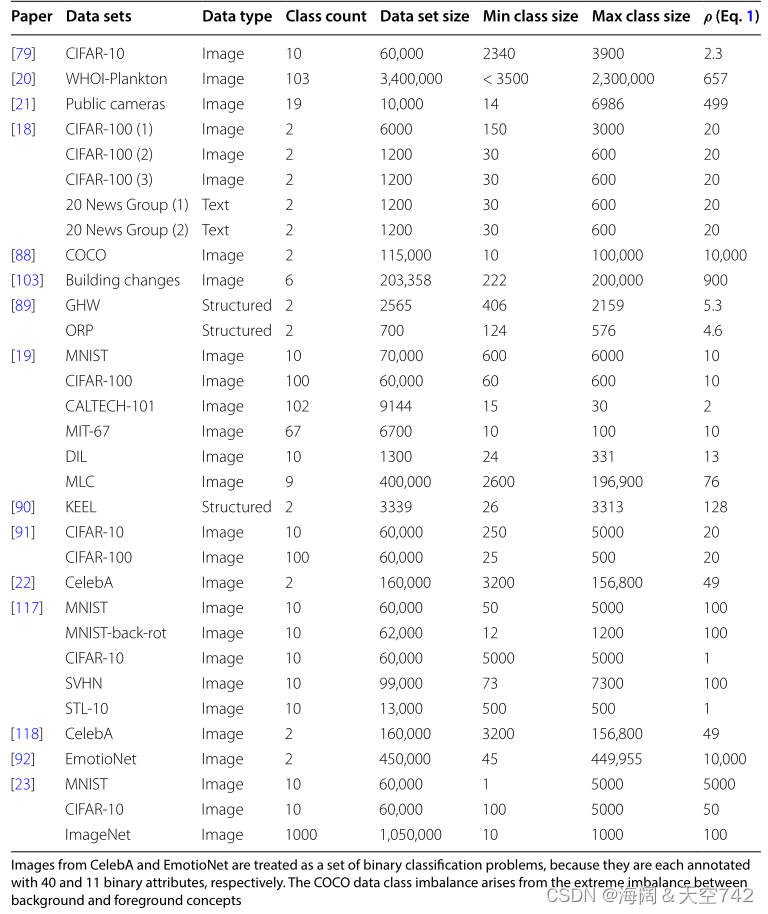
表18 数据集和类不平衡水平的总结
九项研究探索了算法级方法,并可以进一步分解为新的损失函数、代价敏感方法、输出阈值和深度特征1NN规则。(1)MFE和MSFE损失函数[18]是MSE损失的修改,允许正类和负类相等地贡献损失。 (2)焦点损失函数[88,103]通过降低易分类样本的权重来改善分类,防止易分类的负样本主导损失。 (3)Wang等人轻微修改了CE损失,将预定义的类成本纳入学习过程,创建了一个最小化总成本的优化过程。 所评估的最后两种成本敏感方法是独特的,因为它们在整个训练过程中迭代地改进成本矩阵,而不需要预先定义成本。 (4)CoSen CNN[19]使用额外的损失函数通过反向传播学习代价参数, (5)CSDBN-DE[90]使用进化算法来产生越来越好的代价值。 (6)Buda等人使用类先验概率来调整深度CNN输出阈值,减少对大多数类的偏见。 (7)类别中心方法[91]使用CNN生成的特征在特征空间中计算类别中心,然后使用1NN规则根据其最近的类别中心对新数据进行分类。 (8)Ding等人研究了极深CNN(> 10层),以确定在不平衡数据上训练时,深度网络是否比浅网络收敛得更快。
结合数据级和算法级更改来解决类不平衡问题的三种混合方法与基线和替代方法进行了比较。 (1)LMLE[22]结合了quintuplet采样和three header Hinge损失来学习更多的判定特征。 (2)CRL损失函数与硬样本挖掘相结合[118]可以改善表示学习并优于LMLE。 (3)Ando和Huang是第一个在深度特征空间中探索过采样的人,这表明DOS能够在不平衡的图像数据上优于LMLE。
两阶段学习[20]和动态采样[21]在不平衡图像数据分类方面均优于迁移学习和增强方法。
Buda等人表明,两组研究结果相互矛盾,普通ROS比两阶段学习和RUS都表现得更好。
Dong等人表明,ROS和成本敏感学习方法在CelebA数据集上的表现相当,都优于RUS和阈值方法。
Khan等人的实验,评估了六个数据集,表明成本敏感的CNN可以优于使用神经网络和成本敏感的SVM和RF学习器的数据采样方法。
Wang等人使用了最先进的医院再入院预测器,该预测器使用成本敏感的DNN构建,优于现有模型。
MSE损失的类平衡版本MFE和MSFE[18]在分类不平衡的图像和文本数据时表现出改进。
在[117]中,使用深度特征空间的过采样对五个数据集进行分类,表明DOS框架优于LMLE和TL-RS-CSL。
焦点损失[88]函数在COCO数据集上优于领先的一级和两级探测器。
在CelebA人脸属性检测任务中,CRL损失[118]优于LMLE、数据采样、代价敏感学习和阈值。
多位作者[19,23,79]建议将深度学习与ROS结合使用来解决类不平衡问题,结果表明ROS几乎在所有情况下都优于RUS。Buda,Hensman和Masko都建议应用ROS,直到训练集中的类不平衡被消除,但实验没有考虑大数据场景。我们认为,当受到大数据或类稀有性的影响时,将ROS应用于这一级别将无法成立。复制如此大量的数据可能会导致 过拟合,并且计算成本非常高。在一个对比的例子中,Bauder等人[131]发现,在使用传统机器学习算法检测具有类稀有性的大数据中的欺诈时,RUS比ROS更有效。未来的工作应该考虑这些大数据场景,并且应该尝试删除重复和加强类边界的RUS方法。
几乎所有被调查的作品(80%)都使用了深度CNN架构来解决类不平衡图像数据。然而,所提出的所有方法都可以扩展到非CNN架构和非图像数据。CNN、图像分类和目标检测在研究界的流行部分归因于流行的基准数据集,如MNIST和CIFAR,以及像LSVRC这样的竞争性事件所推动的持续改进。类不平衡并不局限于图像数据,必须做额外的工作来评估这些深度学习类不平衡方法在其他领域的使用。
大约一半的研究在评估解决阶级不平衡的深度学习方法时只使用了一个数据集。作者对此没有过错,因为大多数人都专注于解决特定的问题或基准任务。然而,更全面的研究,在更广泛的数据集上评估这些方法,具有不同程度的类不平衡和复杂性,将更好地展示它们的优点和缺点。此外,只有三分之一的研究表明了每个实验执行的轮数或重复次数。换句话说,剩下的组要么没有进行多次测试,要么没有包含这些细节,并给出了最有利的结果。为他们证明,在大型数据集上训练深度学习模型可能需要几天甚至几周的时间,这使得很难进行几轮实验。这为未来的研究创造了几个途径,因为在许多数据集上通过重复比较各种深度学习方法将增加对结果的信心,并有助于指导未来的从业者进行模型选择。
在接受调查的作品中,只有不到一半的作品使用了超过10万个样本的数据集。Lee等人是唯一研究了100多万个包含不平衡数据的样本的人。Pouyanfar等人提供了一个大数据分析工作流来分类快速流媒体网络摄像机数据,但他们的实验仅限于10,000张图像。如果我们希望深度学习能够提供大数据分析解决方案,这是一个非常重要的研究领域,需要得到重视。在本次调查中提出的方法,例如ROS和RUS,在大数据环境下的表现也很可能会有很大的不同。
目前还不可能直接比较已经提出的方法,因为它们是在不同级别的类不平衡的各种数据集上进行评估的,并且报告的结果与不一致的性能指标。此外,一些研究报告了相互矛盾的结果,进一步表明性能高度依赖于问题的复杂性、类表示和所报告的性能指标。总的来说,目前还没有证据表明任何一种深度学习方法在从类不平衡数据中学习方面更胜一筹,在得出这样的结论之前还需要进行更多的实验。
7. 总结
据我们所知,这项调查提供了深度学习方法解决阶级不平衡数据问题的最全面的分析。本文总结和讨论了2015年至2018年间发表的15项研究,探索了一些使用DNN从不平衡数据中学习的先进技术。研究表明,处理类不平衡的传统机器学习技术可以成功地扩展到深度学习模型中。调查还发现,这一领域的几乎所有研究都集中在使用cnn的计算机视觉任务上。尽管对大数据分析解决方案的需求不断增长,但很少有研究在阶级不平衡和大数据的背景下正确评估深度学习。从类不平衡数据中进行的深度学习在很大程度上仍未得到充分研究,并且不存在将新发表的方法在各种数据集和不平衡水平之间进行比较的统计证据。
未来工作的几个领域是显而易见的。将新提出的方法应用于更广泛的数据集和类别不平衡水平,将结果与多个互补的性能指标进行比较,并报告统计证据,这将有助于为未来包含类别不平衡的应用确定首选的深度学习方法。在大数据和类稀少的背景下,用深度学习方法来解决类不平衡的实验将被证明对大数据分析的未来有价值。对于非卷积DNN,还需要做更多的工作,以确定所提出的方法是否能很好地推广到替代架构,例如MLP和RNN。最后,评估使用深度学习来解决非图像数据中的类不平衡的研究是有限的,应该进行扩展。
* 缩写
ANN:人工神经网络;AP:平均精度;AUC:曲线下面积;C2C:类对类;CE:交叉熵;CNN:卷积神经网络;CRL:类矫正损失;CSDBN-DE:成本敏感的深度信念网络与差异进化;CSDNN:成本敏感的深度神经网络;DBN:深度信念网络;DNN。深度神经网络;DOS:深度过度采样;ELM:极端学习机;FAU:面部动作单元;FL:焦点损失;FN:假阴性;FNE:假阴性错误;FP:假阳性;FPE:假阳性错误;FPN:特征金字塔网络;GHW:综合医院病房;GPU:图形处理单元;IoT:物联网;K-NN。K-近邻;KEEL:基于进化学习的知识提取;LMLE:大边际局部嵌入;LSVRC:大规模视觉识别挑战赛;MFE:平均错误;MLP:多层感知器;MSE:平均平方误差;MSFE:平均错误平方;NPV:负预测值;OHEM:在线硬例挖掘;ORP:手术室试点;PPV:正预测值;PR:精度-召回;ReLU:整顿线性单元;RF:随机森林;RNN:循环神经网络;ROC:接受者操作特征;ROS:随机过采样;RUS:随机欠采样;SMOTE:合成少数人过度采样技术;SVM:支持向量机;TL-RS-CSL:成本敏感学习的三重重采样;TN:真负;TNR:真负率;TP:真正;TPR:真正率。
三、参考文献
[1] 李航.统计学习方法
[2] Peter Harrington.Machine Learning in Action/李锐.机器学习实战
[3] https://www.zhihu.com/question/34554321
[4] T. Soni Madhulatha.AN OVERVIEW ON CLUSTERING METHODS
[5] https://zhuanlan.zhihu.com/p/32375430
[7] https://www.cnblogs.com/tiaozistudy/p/dbscan_algorithm.html
[8] https://blog.csdn.net/itplus/article/details/10089323
[9] Mihael Ankerst.OPTICS: ordering points to identify the clustering structure

















 3632
3632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









