







 本文详细讲解了UVM (Universal Verification Methodology) 中sequence与sequencer的关系,包括如何挂载sequence、item操作的宏定义,以及sequencer的仲裁机制、锁定功能和virtualsequence的使用。通过实例演示了如何设置优先级、仲裁模式并处理并发sequence的同步问题。
本文详细讲解了UVM (Universal Verification Methodology) 中sequence与sequencer的关系,包括如何挂载sequence、item操作的宏定义,以及sequencer的仲裁机制、锁定功能和virtualsequence的使用。通过实例演示了如何设置优先级、仲裁模式并处理并发sequence的同步问题。
目录
在上篇博客中,讲了sequencer和driver之间传递sequence item的握手过程,也讲了sequence和item之间的关系,下面我们来讲讲sequence和sequencer之间的关系,以及当多个sequence挂载到sequencer时冲裁这么处理。
sequence和sequencer
class bus_trans extends uvm_sequence_item;
rand int data;
`uvm_object_utils_begin(bus_trans)
`uvm_field_int(data, UVM_ALL_ON)
`uvm_object_utils_end
...
endclass
class child_seq extends uvm_sequence;
`uvm_object_utils(child_seq)
...
task body();
uvm_sequence_item tmp;
bus_trans req;
tmp = create_item(bus_trans::get_type(), m_sequencer,"req");
void'($cast(req, tmp));
start_item(req);
req.randomize with {data == 10;};
finish_item(req);
endtask
endclass
class top_seq extends uvm_sequence;
`uvm_object_utils(top_seq)
...
task body();
uvm_sequence_item tmp;
child_seq cseq;
bus_trans req;
// create child sequence and items
cseq = child_seq::type_id::create("cseq");
tmp = create_item(bus_trans::get_type(), m_sequencer,"req");
// send child sequence via start()
cseq.start(m_sequencer, this); // 挂载到sequencer
// send sequence item
void'($cast(req, tmp));
start_item(req);
req.randomize with {data == 20;};
finish_item(req);
endtask
endclass
class sequencer extends uvm_sequencer;
`uvm_component_utils(sequencer)
...
endclass
class driver extends uvm_driver;
`uvm_component_utils(driver)
...
task run_phase(uvm_phase phase);
REQ tmp;
bus_trans req;
forever begin
seq_item_port.get_next_item(tmp);
void'($cast(req, tmp));
`uvm_info("DRV", $sformatf("gor a item \n %s", req.sprint()), UVM_LOW)
seq_item_port.item_done();
end
endtask
endclass
class env extends uvm_env;
sequencer sqr;
driver drv;
`uvm_component_utils(env)
...
function void build_phase(uvm_phase phase);
sqr = sequencer::type_id::create("sqr", this);
drv = driver::type_id::create("drv", this);
endfunction
function void connect_phase(uvm_phase phase);
drv.seq_item_port.connect(sqr.seq_item_export);
endfunction
endclass
将sequence挂载到sequencer
将sequence挂载到sequencer上:
uvm_sequence::start(uvm_sequencer_base sequencer, uvm_sequence_base parent_sequence = null, int this_priority = -1, bit call_pre_post = 1)
第一个变量,是指明sequence要挂载到哪个sequencer上面;第二个sequence是默认当前的sequence是没有parent sequence的;第三个参数默认值是-1,会使得该sequence如果有parent_sequence会继承其优先级值,如果它是顶层sequence,则其优先级会被自动设置为100,用户也可以自己指定优先级数值;第四个参数建议使用默认值,这样body() 函数预定义的回调函数,uvm_sequence::pre_body()和uvm_sequence::post_body()两个方法会在uvm_sequence::body()的前后执行。
在上面的代码中,child_seq被嵌套在top_seq中,所以在挂载的时候,需要指明它的parent_sequence;而在test一层调用top_seq时,由于它是root sequence,所以不需要再指定parent sequence;另外,在调用挂载sequence时,需要对这些sequence进行例化。

将item挂载到sequencer
发送方法是将item挂载到sequencer上:
uvm_sequence::start_item(uvm_sequence_item item, int set_priority = -1, uvm_sequencer_base sequencer = null);
uvm_sequence::finish_item(uvm_sequence_item item, int set_priority = -1);
在使用上面的一堆start&finish item方法时,需要使用create_item来对item进行创建,以及对其进行随机化处理。
对比start()方法和start_item()/finish_item()方法,要注意,它们面向的挂载对象是不同的。在执行start()的过程中,默认情况下会执行sequence的pre_body()和post_body(),但是如果start()的参数call_pre_post = 0,那么就不会执行。

item之所以必须要依赖于sequence,是因为在执行finish_item的时候,用到了sequencer的方法,只有item通过sequence,拿到sequence挂载的sequencer的句柄,才能调用它的方法send_request(item)和wait_for_item_done() 。
发送item和sequence相关的宏:
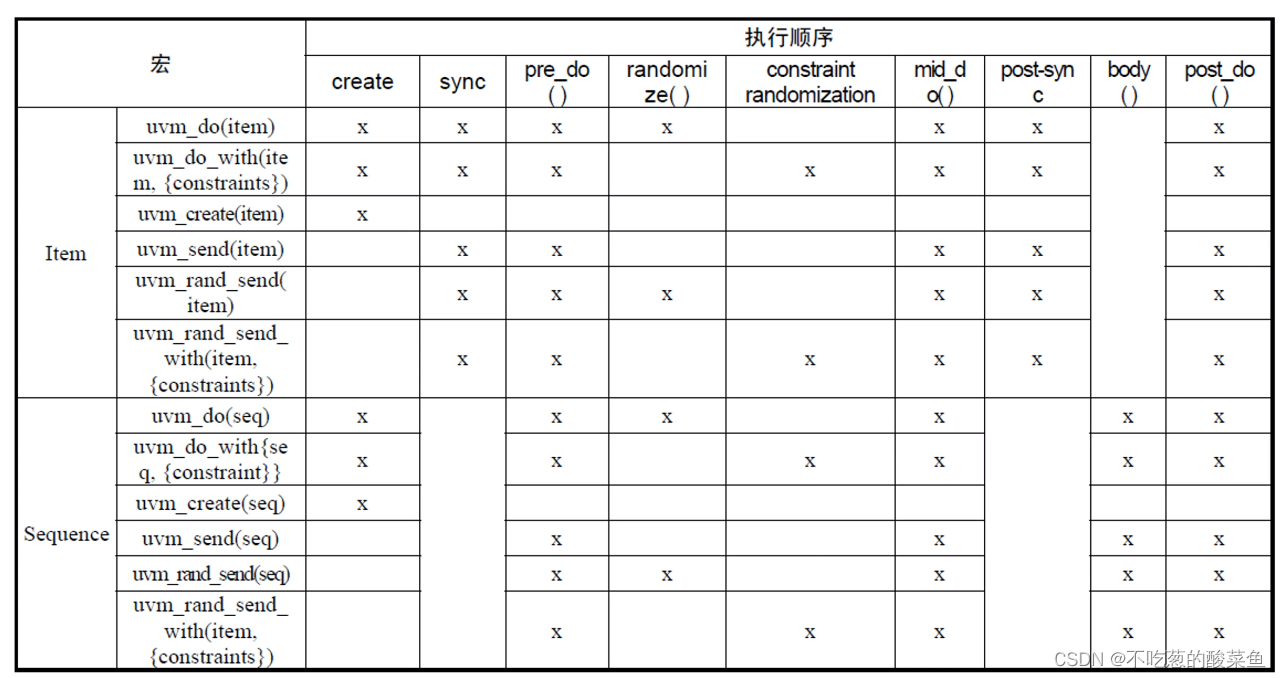
上面为UVM宏定义,每个宏所对应要做的事情,打x的为要做。uvm_create(item) + uvm_send(item)的功能可以等效为uvm_do(item) 。
用户可以通过`uvm_do/`uvm_do_with来发送无论是sequence还是item。这种不区分对象sequence还是item的方式,带来了不少便捷,但容易让新手不知道这些宏定义背后做了那些工作,因此,需要先了解它们背后的sequence和item各自发送的方法。
不同的宏,可能会包含创建对象的过程,也可能不会创建对象。比如`uvm_do/`uvm_do_with会创建对象,而`uvm_send则不会创建对象,也不会将对象做随机处理,因此需要了解它们各自包含的执行内容和顺序。
`uvm_do宏使用的场景只有在sequence中才可以使用,因为其中涉及了一些调用sequence中定义的方法,因此不能在其他例如uvm_test、uvm_env中调用sequence相关的宏定义。
宏定义使用实例
class child_seq extends uvm_sequence;
...
task body();
bus_trans req;
`uvm_create(req)
`uvm_rand_send_with(req, {data == 10};)
//上面两行宏定义也可以合并成一条:uvm_do_with(req, {data == 10};)
endtask
endclass
class top_seq extends uvm_sequence;
...
task body();
child_seq cseq; //sequence
bus_trans req; //item
// send child sequence via start()
`uvm_do(cseq)
// send sequence item
`uvm_do_with(req, {data == 20;})
//使用宏定义后,发送sequence和item和之前相比,减少了很多代码
endtask
endclass尽量要避免使用fork-join_any和for-join_none来控制sequence的发送顺序,因为退出fork-join块之后,在执行后续的操作时,可能有sequence还没发送完毕,那么在用户想终止后台运行的sequence线程而使用disable时,可能会在不合适的时间点锁住sequencer。
如果一定要使用fork-join_any和for-join_none来控制sequence的发送顺序,应当在使用disable之前,对各个sequence线程的后台状况保持关注,尽量在发完item完成握手之后再终止sequence;如果要使用fork-join,那么应当确保有方法可以让sequence线程在满足一些条件后停止发送item。否则只要有一个sequence线程无法停止,则整个fork-join无法退出。
sequencer仲裁特性
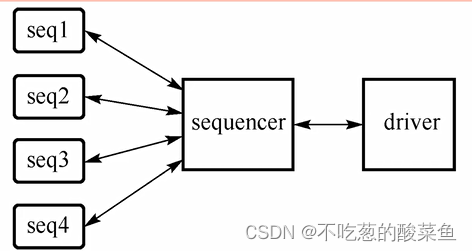
在多个sequence挂载到一个seuqencer的情况下,uvm_sequencer类自建了仲裁机制来保证多个sequence在同时挂载到sequencer时,可以按照仲裁规则允许特定sequence中的item优先通过。
在实际使用中,我们可以通过uvm_sequencer::set_arbitration(UVM_SEQ_ARB_TYPE val)函数来设置仲裁模式,这里的仲裁模式UVM_SEQ_ARB_TYPE有如下几种值可以选择:
※ UVM_SEQ_ARB_FIFO:默认模式,来自sequences的发送请求,按照FIFO先进先出的方式被依次授权,和优先级没有关系,谁先申请,谁就获得。
※ UVM_SEQ_ARB_STRICT_FIFO:先看优先级,再看顺序,优先级高的先发送,优先级一致的,优先授权先申请的sequence。
※ UVM_SEQ_ARB_WEIGHTED:不同sequence的发送请求,按照它们的优先级权重随机授权。
※ UVM_SEQ_ARB_RANDOM:不同的请求会被随机授权,而无视它们的抵达顺序和优先级。
※ UVM_SEQ_ARB_STRICT_RANDOM:不同的请求,会按照它们的最高优先级随机授权,与抵达时间无关。
※ UVM_SEQ_ARB_USER:用户可以自定义仲裁方法user_priority_arbitration()来裁定哪个sequence的请求被优先授权。
实例
class bus_trans extends uvm_sequence_item;
rand int data;
...
endclass
class child_seq extends uvm_sequence;
rand int base;
...
task body();
bus_trans req;
repeat(2) `uvm_do_with(req, {data inside {[base: base+9]};})
endtask
endclass
class top_seq extends uvm_sequence;
...
task body();
child_seq seq1,seq2,seq3;
m_sequencer.set_arbitration(UVM_SEQ_ARB_STRICT_FIFO);
fork
`uvm_do_pri_with(seq1, 500, {base == 10;})
`uvm_do_pri_with(seq2, 500, {base == 20;})
`uvm_do_pri_with(seq3, 300, {base == 30;})
join
endtask
endclass
class sequencer extends uvm_sequencer;
...
endclass
class driver extends uvm_driver;
...
task run_phase(uvm_phase phase);
REQ tmp;
bus_trans req;
forever begin
seq_item_port.get_next_item(tmp);
void'($cast(req, tmp));
`uvm_info("DRV",
$sformatf("got a item %0d from parent sequence %s",
req.data, req.get_parent_sequence().get_name()), UVM_LOW)
seq_item_port.item_done();
end
endtask
endclass
class env extends uvm_env;
sequencer sqr;
driver drv;
...
function void build_phase(uvm_phase phase);
sqr = sequencer::type_id::create("sqr", this);
drv = driver::type_id::create("drv",this);
endfunction
function void connect_phase(uvm_phase phase);
drv.seq_item_port.connect(sqr.seq_item_eport);
endfunction
endclass
class test1 extends uvm_test;
env e;
...
task run_phase(uvm_phase phase);
top_seq seq;
phase.raise_objection(phase);
seq = new();
seq.start(e.sqr);
phase.drop_objection(phase);
endtask
endclass输出结果:

由于将seq1和seq2设置为同样的高优先级(500),而seq3设置为较低的优先级(300),这样在随后的UVM_SEQ_ARB_STRIC_FIFO仲裁模式下,可以从输出结果看到,按照优先级高低和传送请求时间顺序,先将seq1和seq2中的item发送完毕,随后再将seq3发送完。
sequencer的锁定机制
uvm_sequencer提供了两种锁定机制,分别通过lock()和grab()方法实现,这两种方法的区别在于:
lock()和unlock()这一对方法可以为sequence提供排外的访问权限,但前提条件是,该sequence首先需要按照sequencer的仲裁机制获得授权。而一旦sequence获得授权,则无需担心权限被收回,只有该sequence主动解锁(unlock)它的sequencer,才可以释放这一锁定的权限。lock()是一种阻塞任务,只有获得了权限,它才会返回。
grab()和ungrab()也可以为sequence提供排外的访问权限,而且它只需要在sequencer下一次授权周期时就可以无条件地获得授权。与lock方法相比grab方法无视同一时刻内发起传送请求的其他sequence,而唯一可以组织它的只有已经预先获得授权的其他lock或者grab的sequence。
如果sequence使用了lock()或者grab()方法,必须在sequence结束前调用unlock()或者ungrab()方法来释放权限,否则sequencer会进入死锁状态而无法继续为其余sequence授权。
实例
class bus_trans extends uvm_sequence_item;
...
endclass
class child_seq extends uvm_sequence;
rand int base;
...
task body();
bus_trans req;
repeat(2) #10ns `uvm_do_with(req, {data inside {[base: base+9]};})
endtask
endclass
class lock_seq extends uvm_sequence;
...
task body();
bus_trans req;
#10ns;
m_sequencer.lock(this);
`uvm_info("LOCK", "get exclusive access by lock()", UVM_LOW)
repeat(3) #10ns `uvm_do_with(req, {data inside {[100:110]};})
m_sequencer.unlock(this);
endtask
endclass
class grab_seq extends uvm_sequence;
...
task body();
bus_trans req;
#20ns;
m_sequencer.grab(this);
`uvm_info("GRAB", "get exclusive access by grab()", UVM_LOW)
repeat(3) #10ns `uvm_do_with(req, {data inside {[200:210]};})
m_sequencer.ungrab(this);
endtask
endclass
class top_seq extends uvm_sequence;
...
task body();
child_seq seq1, seq2, seq3;
lock_seq locks;
grab_seq grabs;
m_sequencer.set_arbitration(UVM_SEQ_ARB_STRICT_FIFO);
fork
`uvm_do_pri_with(seq1, 500, {base == 10;})
`uvm_do_pri_with(seq2, 500, {base == 20;})
`uvm_do_pri_with(seq3, 300, {base == 30;})
`uvm_do_pri(locks, 300)
`uvm_do(grabs)
join
endtask
endclass
输出结果:

之所以seq1和seq2都在10ns的时候发送一次,而不是发送两次,是因为在发送item时,延迟了10ns再发送。然后lock_sequence锁住sequencer,发送三次item。
class grab_seq extends uvm_sequence;
...
task body();
bus_trans req;
#20ns;
m_sequencer.grab(this);
`uvm_info("GRAB", "get exclusive access by grab()", UVM_LOW)
repeat(3) #10ns `uvm_do_with(req, {data inside {[200:210]};})
m_sequencer.ungrab(this);
endtask
endclass从这段代码中,我们知道,grab_sequence在20ns的时候,就已经开始申请sequencer了(实际上seq1、seq2、seq3也同时发起了请求),但是在40ns才获得sequencer,这是因为sequencer被lock_sequence锁住了。等到40ns,unlock之后才被grab。被grab后,发送三次item,到70ns,ungrab。seq1、seq2、seq3再根据优先级依次发送item。
virtual sequence
virtual sequence可以承载不同目标sequencer的sequence群落,组织协调这些sequence的方式类似于高层次的hierarchical sequence。virtual sequencer和普通的sequencer有很大的不同,它起到了桥接其他sequencer的作用,即virtual sequencer是一个链接所有底层sequencer句柄的地方,是一个中心化的路由器。
virtual sequencer本身不会传送item数据对象,因此virtual sequencer不需要与任何driver进行TLM链接。所以用户需要在顶层connect阶段,做好virtual sequencer中各个sequencer句柄与底层sequencer实体对象的一一对接,避免句柄悬空。
在virtual sequence中使用uvm_do_on把不同sequence挂载到不同的sequencer上面,而不是想hierarchical sequence那样直接用uvm_do默认把sequence挂载到顶层。
对于virtual sequence而言,它可以承载各个子模块环境的element sequence,而最后通过virtual sequencer中的各个底层sequencer句柄,各个element sequence可以分别挂载到对应的底层sequencer上。
使用`uvm_declare_p_sequencer,可以在后台新建一个p_sequencer变量,而将m_sequencer的默认变量(uvm_sequencer_base类型)通过动态转换($cast),变为类型virtual_sequencer的p_sequencer。
这种中心化的协调方式,使得顶层环境在场景创建和激励控制方面更加得心应手,而且在代码后期维护中,测试场景的可读性也得到了提高。
使用virtual sequence时容易遇到的错误:
※ 需要区分virtual sequence 同其它普通sequennce(element sequence、hierarchical sequence)
※ 需要区分virtual sequencer同其它底层负责传送数据对象的sequencer。
※ 在virtual sequence中记得使用宏`uvm_declare_p_sequencer来创建正确类型的p_sequencer变量,方便接下来各个目标的sequencer索引。
※ 在顶层环境中记得创建virtual sequencer,并且完成virtual sequencer中各个sequencer句柄与底层sequencer的跨层次链接,避免句柄悬空。
layering sequence
在构建更加复杂的协议总线传输,例如PCIe,USB3.0等,那么通过一个单一的传输层级会对以后的激励复用、上层控制不那么友好。对于这种更深层次化的数据传输,在实际中无论是VIP还是自开发的环境,都倾向于通过若干抽象层次的sequence群落来模拟协议层次。
通过层次化的sequence可以分别构建transaction layer、transport layer和physical layer等从高抽象级到低抽象级的transaction转化。这种层次化的sequence构建方式,我们称之为layering sequence。例如在进行寄存器级别的访问操作,其需要通过transport layer转化,最终映射为具体的总线传输。
layering sequence会包含三部分,高抽象层次的item、低抽象层次的item、中间作转化的sequence。
在各个抽象级的sequencer中,需要有相应的转换方法,将从高层次的transaction从高层次的sequencer获取,继而转换为低层次的transaction,最终通过低层次的sequencer发送出去。例如adapter_seq负责从layer_sequencer获取layer_trans,再将其转换为phy_master_sequencer一侧对应的sequence或者transaction,最后将其从phy_master_sequencer发送出去。



















 2533
2533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











