







上一部分简单介绍了经典的传统机器学习分类模型在人体动作分类领域的基本应用。传统的基于机器学习分类方法主要包括三个步骤,第一对原始输入数据进行预处理,第二对预处理以后的数据进行特征提取,第三是使用分类器进行分类识别。其中的第二步,特征提取非常依赖数据处理人员的先验知识。因此,导致使用机器学习进行的人体动作分类识别性能主要依赖于人工特征的质量,这对人体动作分类的智能化需求是一个巨大的挑战,这也是传统机器学习方法的局限性。
近些年来以卷积神经网络(Convolutional Neural Network,CNN)为代表的深度学习技术发展迅速,深度学习在语音识别、图像和自然语言处理等领域取得了巨大成功,尤其在自学习特征方面的优势被作为一种良好的机器学习方法使用。这一部分讲解如何使用深度学习中的CNN来完成与上一节相同的任务。如果对于CNN理论不熟悉的,目前在网上已有许多的资料可以参阅,这里不再展开叙述。
通常的卷积神经网络是指二维卷积神经网络(2D-CNN),对应的计算过程是将一个特征图在宽和高两个方向进行滑动窗口操作,然后对应位置进行相乘求和,具体如图1所示: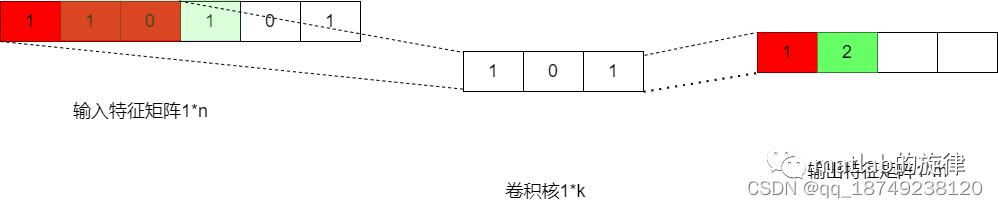
而使用的1D-CNN则只是在宽或高方向上进行滑动窗口并相乘求和,过程如图2所示,是一种退化的二维卷积
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









