






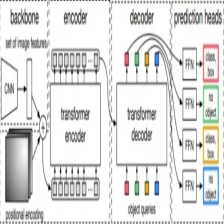
前面在完成了DETR模型的构建后,我们接下来便是进行数据集构造与模型训练了,模型训练阶段会涉及到网络前向传播与后向传播,这才是真正的难点。
数据集构造
创建数据集
在数据集构造前其首先进行了优化器的选择与学习策略的选择。随后创建数据集,共有3360张数据,batch_size=8,每个batch的数据为420
#训练选择AdamW优化器
optimizer = torch.optim.AdamW(param_dicts, lr=args.lr,
weight_decay=args.weight_decay)
#训练的学习率策略选择StepLR
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, args.lr_drop)
#创建训练、验证数据集
dataset_train = build_dataset(image_set='train', args=args)
dataset_val = build_dataset(image_set='val', args=args)

build_dataset方法实现:其按照不同类型的数据集进行构建,个人建议统一使用coco数据集格式。
def build_dataset(image_set, args):
if args.dataset_file == 'coco':
return build_coco(image_set, args)
if args.dataset_file == 'coco_panoptic':
# to avoid making panopticapi required for coco
from .coco_panoptic import build as build_coco_panoptic
return build_coco_panoptic(image_set, args)
raise ValueError(f'dataset {args.dataset_file} not supported')
随后执行 build_coco 方法:
def build(image_set, args):
root = Path(args.coco_path)
assert root.exists(), f'provided COCO path {root} does not exist'
#mode = 'instances'
PATHS = {
"train": (root / "images/train2023", root / "annotations" / f'train2023.json'),
"val": (root / "images/val2023", root / "annotations" / f'val2023.json'),
}
img_folder, ann_file = PATHS[image_set]#分别获取图像信息与annocation标签
dataset = CocoDetection(img_folder, ann_file, transforms=make_coco_transforms(image_set), return_masks=args.masks)
return dataset
CocoDetection方法具体实现,在该方法中进行数据集匹配。
class CocoDetection(torchvision.datasets.CocoDetection):
def __init__(self, img_folder, ann_file, transforms, return_masks):
super(CocoDetection, self).__init__(img_folder, ann_file)
self._transforms = transforms
self.prepare = ConvertCocoPolysToMask(return_masks)
def __getitem__(self, idx):
img, target = super(CocoDetection, self).__getitem__(idx)
image_id = self.ids[idx]
target = {'image_id': image_id, 'annotations': target}
img, target = self.prepare(img, target)
if self._transforms is not None:
img, target = self._transforms(img, target)
return img, target
随后便是进行数据集加载了,使用默认的pytorch中的方法即可。
数据集初始化
# 对于训练集进行随机抽样,对于验证集按顺序验证
sampler_train = torch.utils.data.RandomSampler(dataset_train)
sampler_val = torch.utils.data.SequentialSampler(dataset_val)
数据集按batch划分
batch_sampler_train = torch.utils.data.BatchSampler(
sampler_train, args.batch_size, drop_last=True)
加载数据集
该方法使用pytorch中写好的即可。
data_loader_train = DataLoader(dataset_train, batch_sampler=batch_sampler_train,
collate_fn=utils.collate_fn, num_workers=args.num_workers)
data_loader_val = DataLoader(dataset_val, args.batch_size, sampler=sampler_val,
drop_last=False, collate_fn=utils.collate_fn, num_workers=args.num_workers)
数据集构造完成后便是一些其他参数的初始化了,如保存路径,是否加载预训练模型等。
加载预训练模型参数
model_without_ddp.load_state_dict(checkpoint['model'],strict=False)
最终进入我们的重点,模型训练
模型训练
迭代epochs是通过for循环实现的,在每个epoch中执行下面的train_one_epoch方法。
train_stats = train_one_epoch(
model, criterion, data_loader_train, optimizer, device, epoch,
args.clip_max_norm)
迭代一次,即向内喂入数据,随后通过前向传播获得预测结果,然后进行损失计算并进行反向传播更新梯度。
for samples, targets in metric_logger.log_every(data_loader, print_freq, header):
samples = samples.to(device)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
# 获得模型输出
outputs = model(samples)
# 计算Loss
loss_dict = criterion(outputs, targets)
weight_dict = criterion.weight_dict
# 得到加权loss和
losses = sum(loss_dict[k] * weight_dict[k] for k in loss_dict.keys() if k in weight_dict)
# reduce losses over all GPUs for logging purposes
loss_dict_reduced = utils.reduce_dict(loss_dict)
loss_dict_reduced_unscaled = {f'{k}_unscaled': v
for k, v in loss_dict_reduced.items()}
loss_dict_reduced_scaled = {k: v * weight_dict[k]
for k, v in loss_dict_reduced.items() if k in weight_dict}
losses_reduced_scaled = sum(loss_dict_reduced_scaled.values())
loss_value = losses_reduced_scaled.item()
# 是否loss不为无穷数,否则训练有误,停止训练
if not math.isfinite(loss_value):
print("Loss is {}, stopping training".format(loss_value))
print(loss_dict_reduced)
sys.exit(1)
# 反向梯度传播
optimizer.zero_grad()
losses.backward()
首先我们来看看 simple 与 targets :
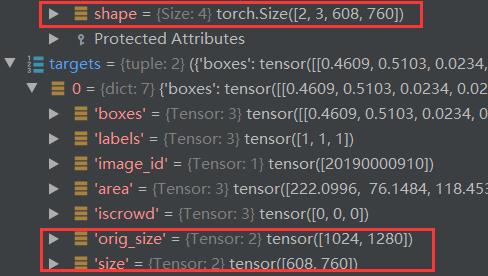
维度变化分析
骨干网络
进入骨干网络对输入图像进行特征提取,得到
features特征图: torch.Size([2, 2048, 19, 24])
pos位置编码:torch.Size([2, 256, 19, 24])
features, pos = self.backbone(samples)
通常 Backbone 的输出通道为 2048,图像高和宽都变为了 1/32。在这里可以看到通道数为2048,608/19=32 ,760/24=32 (向上取整)
分离特征图与掩码
mask的作用:当一个batch中的图片大小不一样的时候,我们要把它们处理的整齐,简单说就是把图片都padding成最大的尺寸,padding的方式就是补零,那么batch中的每一张图都有一个mask矩阵。
src, mask = features[-1].decompose()
进入Transformer
经过 Backbone 后,将输出特征图 reshape 为 C × H W ,因为 C = 2048 C = 2048是每个 token 的维度,还是比较大,所以先经过一个 1 × 1 的卷积进行降维,然后再输入 Transformer Encoder 会更好。
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
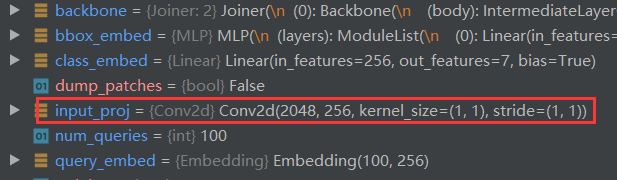
其中的input_proj方法便是一个1*1卷积,用来做通道变换的。
进入Transformer后:
def forward(self, src, mask, query_embed, pos_embed):
# src: transformer输入,mask:图像掩码, query_embed:decoder预测输入embed, pos_embed:位置编码
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
# 获取encoder输入
src = src.flatten(2).permute(2, 0, 1)#flatten先变为bs,c,h*w,随后通过perute变为h*w,bs,c
# 获取位置编码
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)#位置编码做相同变化
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)#unsequeeze表示再dim维度给加已维度
# 获取输入掩码
mask = mask.flatten(1)
# torch.zeros_like:生成和括号内变量维度维度一致的全是零的内容。
# tgt初始化,意义为初始化需要预测的目标。因为一开始不清楚需要什么样的目标,所以初始化为0,它会在decoder中
# 不断被refine,但真正在学习的是query embedding,学习到的是整个数据集中目标物体的统计特征。而tgt在每一个epoch都会初始化。
# tgt 也可以理解为上一层解码器的解码输出 shape=(100,N,256) 第一层的tgt=torch.zeros_like(query_embed) 为零矩阵,
# query_pos 是可学习输出位置向量, 个人理解 解码器中的这个参数 全局共享 提供全局注意力 query_pos=(100,N,256)
tgt = torch.zeros_like(query_embed)
# 获取encoder输出
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
# 获取decoder输出,return_intermediate_dec为true时,得到decoder每一层的输出
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
下面来详细分析其变化:
首先是src的维度变化,经过下面的变为 torch.Size([456, 2, 256]),其中456=19*24
src = src.flatten(2).permute(2, 0, 1)
随后对位置编码做相同变换为torch.Size([456, 2, 256])
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)#位置编码做相同变化
经过下面变换,query_embed变为:torch.Size([100, 2, 256])
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)#unsequeeze表示再dim维度给加已维度
掩码维度变为:torch.Size([2, 456])
mask = mask.flatten(1)
tgt 也可以理解为上一层解码器的解码输出 shape=(100,N,256) 第一层的tgt=torch.zeros_like(query_embed) 为零矩阵,即初始化为0
query_pos 是可学习输出位置向量, 个人理解 解码器中的这个参数 全局共享 提供全局注意力 query_pos=(100,N,256)
tgt = torch.zeros_like(query_embed)
随后进入encoder,其内计算相对简单,送入的数据分别为src(输入数据),pos位置编码
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
具体计算流程,此时在Encoder
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output
在每层循环中会进入EncoderLayer
with_pos_embed(src, pos)执行将src加上位置编码操作
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
最终经过一系列计算得到memory的值为torch.Size([456, 2, 256])
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
随后送入decoder
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
与encoder相同,其也具有多个encoderlayer
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)#加入位置编码
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]#自注意力计算
tgt = tgt + self.dropout1(tgt2)#残差连接
tgt = self.norm1(tgt)#层归一化
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)#残次连接
tgt = self.norm2(tgt)#层归一化
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))#feed and forward
tgt = tgt + self.dropout3(tgt2)#残次连接
tgt = self.norm3(tgt)#normal归一化
return tgt
我们来详细看一下:
q,k使用 tgt 与位置编码信息做初始化 torch.Size([100, 2, 256])
最终将 tgt 返回即为 torch.Size([100, 2, 256])随后对输出结果使用
经过Transformer后的结果为:torch.Size([6, 2, 100, 256])
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
随后经过分类头与回归头,所得维度分别为:torch.Size([6, 2, 100, 7])与torch.Size([6, 2, 100, 4]),这个6指的是6层decoder的结果都要。最后便是进行损失计算了。
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
最终返回到detr中:
if self.aux_loss:
out['aux_outputs'] = [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
return out
得到输出结果,输出out包含三个内容:
pred_boxes:torch.Size([2, 100, 4])
pred_logits:torch.Size([2, 100, 7]),这里的logits本为表示全连接层的输出,这里指的就是标签。
‘aux_output’={list:5} 0-4 每个都是dict:2 pred_logits+pred_boxes 表示5个decoder前面层的输出
构建完的DETR模型如下:可以不用看
DETR(
(transformer): Transformer(
(encoder): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(1): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(2): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(3): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(4): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(5): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
(decoder): TransformerDecoder(
(layers): ModuleList(
(0): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(1): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(2): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(3): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(4): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(5): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(class_embed): Linear(in_features=256, out_features=7, bias=True)
(bbox_embed): MLP(
(layers): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=4, bias=True)
)
)
(query_embed): Embedding(100, 256)
(input_proj): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(backbone): Joiner(
(0): Backbone(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d()
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
(relu): ReLU(inplace=True)
)
)
)
)
(1): PositionEmbeddingSine()
)
)

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











