







目录
摘要
本周阅读的论文题目是《Skeleton-Based Action Recognition with Directed Graph Neural Networks》(《基于骨架动作识别与有向图神经网络》)。本文中基于自然人体中关节和骨骼之间的运动学依赖关系,将骨骼数据表示为有向无环图,从而设计了一种新颖的有向图神经网络(DGNN),专门用于提取关节、骨骼及其关系的信息,并基于提取的特征进行预测。此外,为了更好地适应动作识别任务,根据训练过程使图的结构自适应,这带来了显著的改进。此外,利用骨骼序列的运动信息,并将其与空间信息相结合,在一个双流框架中进一步增强了性能。
Abstract
This week's paper is titled "Skeleton-Based Action Recognition with Directed Graph Neural Networks." In this paper, based on the kinematic dependence between joints and bones in the natural human body, the skeletal data is represented as a directed acyclic graph, and a novel directed graph neural network (DGNN) is designed, which is specially designed to extract the information of joints, bones and their relationships, and make predictions based on the extracted features. In addition, in order to better adapt to the action recognition task, the structure of the graph is adaptive according to the training process, which brings significant improvements. In addition, taking the motion information of the bone sequence and combining it with spatial information further enhances performance in a dual-stream frame.
文献链接🔗:Skeleton-Based Action Recognition with Directed Graph Neural Networks
1 引言
在上周中学习的2s-AGCN,将骨骼的长度和方向表示为从源关节指向目标关节的向量,利用骨骼数据的二次信息,这种代表骨骼方向和大小的骨骼信息已被证明是骨骼基动作识别的良好模态。这种信息是直观的,因为人类自然根据人体骨骼的方向和位置来评估动作,而不是关节的位置。此外,已经证明关节和骨骼信息是相互补充的,将它们结合起来可以进一步提高识别性能。对于自然的人体,关节和骨骼是强耦合的,每个关节(骨骼)的位置实际上是由它们连接的骨骼(关节)决定的。
但是,现有的基于图的方法通常将骨骼表示为无向图,并用两个独立的网络来建模骨骼和关节,这不能充分利用关节和骨骼之间的这些依赖关系。 为了解决这个问题,本文中将骨骼表示为一个有向无环图,其中关节作为顶点,骨骼作为边,关节和骨骼之间的依赖关系可以通过图的有向边轻松建模。此外,还设计了一种新的有向图神经网络 (DGNN) 对构建的有向图进行建模,该网络可以在相邻关节和骨骼中传播信息,并在每一层更新它们的相关信息。最终提取的特征不仅包含每个关节和骨骼的信息,还包括它们的依赖关系,这有助于动作识别。
另一个问题是,原始骨架是根据人体结构手工设计的,可能不适合动作识别任务。所以本文通过应用一个自适应图来解决这个问题,这意味着图拓扑是参数化的,并在学习过程中进行优化,不仅确保了训练过程的稳定性,还避免了损失灵活性,从而带来了显著的改进。
并且,还基于双流架构方法的启发,从关节和骨骼中提取运动信息以辅助识别,本文提出了一种双流框架,提取了连续帧之间的运动信息以进行时间信息建模,以融合空间流和运动流的结果,进一步提高性能。
2 图构建
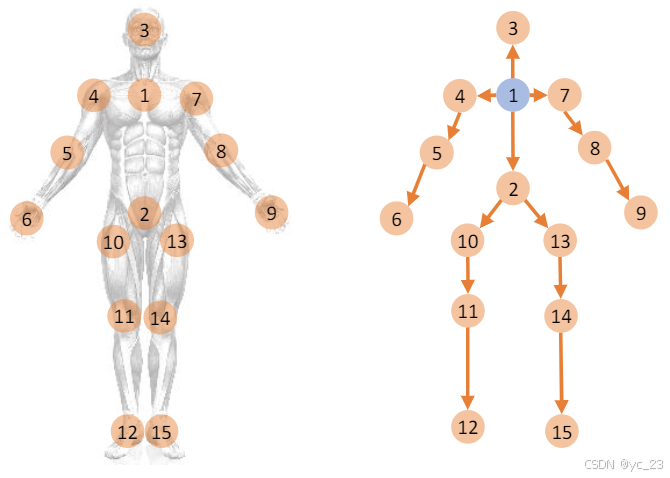
在2s-AGCN中了解到,骨骼可以表示为两个相连关节之间的坐标差。在本文中以此为基础,进一步将骨骼数据表示为以关节为顶点、骨骼为边的有向无环图(DAG)。每条边的方向由顶点与根顶点之间的距离确定,距离根顶点更近的顶点指向距离根顶点更远的顶点。在这里,根顶点被定义为骨骼的重心。
下图显示了骨骼及其相应的有向图表示,其中顶点1(蓝色圆点)是根顶点:
在数学表示上,对于每个顶点 ,将其指向的边定义为入边
,从其发出的边定义为出边
。同样,反过来,对于一个有向边
,定义它是一个从源顶点
到目标顶点
的向量。
即,如果 是
的目标顶点,则
是
的入边;反之,如果
是
的源顶点,则
是
的出边。如下图所示:
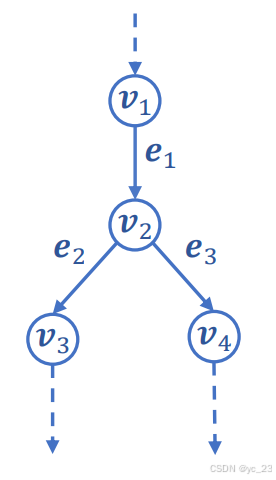
其中:
是
的源顶点,
是
是
的入边,
、
是
- 每条边只有一个源顶点和一个目标顶点;
- 但是对于一个顶点,其入边和出边的数量是变化的。
用 和
分别表示顶点
的入边集合和出边集合,这样基于骨骼的框架可以表示为有向图
,其中
是顶点(关节)集,
是有向边(骨骼)集。而基于骨骼的视频一系列帧可以表示为
,其中
表示视频帧长度。
图构建代码如下:
import sys
sys.path.extend(['../'])
from graph import tools
class Graph:
def __init__(self, labeling_mode='spatial'):
self.A = self.get_adjacency_matrix(labeling_mode) # 获取生成的邻接矩阵
self.num_node = num_node
self.self_link = self_link
self.inward = inward
self.outward = outward
self.neighbor = neighbor
# 生成邻接矩阵
def get_adjacency_matrix(self, labeling_mode=None):
if labeling_mode is None:
return self.A
if labeling_mode == 'spatial':
# 生成基于空间关系的邻接矩阵
A = tools.get_spatial_graph(num_node, self.self_link, self.inward, self.outward)
else:
raise ValueError("Unsupported labeling mode!")
return A
if __name__ == '__main__':
import matplotlib.pyplot as plt
import os
graph = Graph(labeling_mode='spatial')
A = graph.get_adjacency_matrix()
for matrix in A:
plt.imshow(matrix, cmap='gray')
plt.show()
print(A)3 DGNN
骨骼数据已表示为有向图,所以接下来的问题在于如何提取图中的信息以进行动作分类,特别是如何利用图中关节和骨骼之间的依赖关系。本文中提出了一种有向图神经网络(DGNN)来解决此问题,DGNN包含多个层,其中:
- 每一层都输入一个包含顶点和边属性的图,并输出具有更新属性的相同图,属性表示顶点和边的属性,这些属性被编码为向量;
- 在每一层中,顶点和边的属性根据其相邻边和顶点进行更新;
- 在底层,每个顶点或边只能从其相邻边或顶点接收属性;
- 这些层的模型旨在在更新属性时提取顶点和边的局部信息;
- 在顶层,来自彼此更远的关节和骨骼的消息可以累积在一起。
因此,提取的信息对于识别任务来说更加全局和语义化。这个概念类似于卷积神经网络的原则,即层次表示和局部性。
3.1 DGN
有向图网络(DGN)块是有向图神经网络的基本块,它包含:
- 两个更新函数
和
,用于根据其连接的边和顶点更新顶点和边的属性;
- 两个聚合函数
和
,由于连接到每个顶点的输入(输出)边的数量是变化的,而参数的数量是固定的,所以需要聚合函数来聚合连接到一个顶点的多个输入(输出)边中包含的属性;而且聚合函数应该对其输入的排列不变,和接受可变数量的参数,例如平均池化、最大池化和逐元素求和。
表达式上,上述过程可以表示为:
其中:
表示连接操作;
和
分别是
和
的更新版本;
- 公式1:对于每个顶点
,所有指向它的边都通过入度聚合函数
;
- 公式2:对于每个顶点
;
- 公式3:对于每个顶点
作为
- 公式4:对于每条边
,其与自身连接的更新源顶点
和更新目标顶点
经过边更新函数
作为边
该过程可以总结为一个顶点更新过程,随后是一个边更新过程,如下图所示:
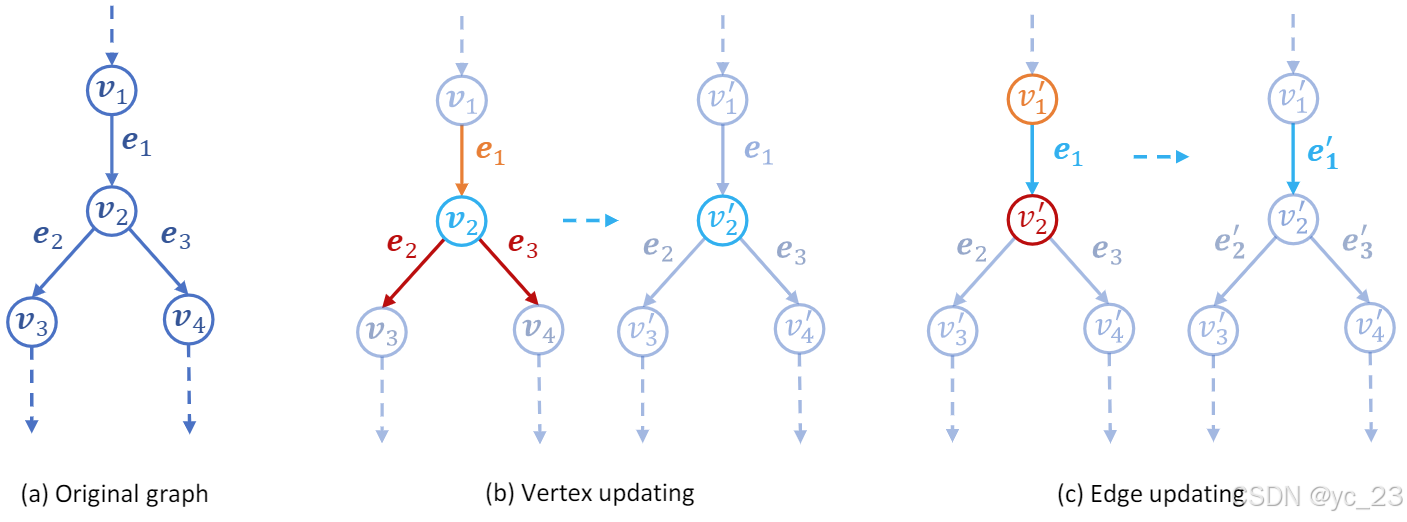
其中:
- (a)是原始图;
- (b)显示了顶点更新过程,其中顶点本身的属性(
);
- (c)显示了边更新过程,其中边的属性(
)和目标顶点(
);
- 蓝色圆圈(箭头)表示正在更新的边(顶点);
- 橙色圆圈(箭头)表示参与更新的源顶点(入边);
- 红色圆圈(箭头)表示参与更新的目标顶点(出边)。
本文中选择平均池化作为入边和出边的聚合函数,选择单个全连接层作为更新函数。
在实现DGN块时,有:
- 顶点的输入数据实际上形成一个
的张量
,其中
是通道数,
是帧数,
表示骨架图中顶点的数量;
- 边的数据为一个
的张量
,
是图中边的数量。
但是这样的输入数据形式并不能满足和实现DGN,在上一章中,已经了解到实现DGN块的关键是找到每个顶点的入边集合()和出边集合(
),以及找到每条边的源顶点(
)和目标顶点(
)。
由此,通过使用图的关联矩阵,给定一个具有个 顶点和
条边的有向图,
的关联矩阵是一个
的矩阵,其元素
表示相应顶点(
)和边(
)之间的关系:
- 如果
;
- 如果
;
- 如果
。
为了区分源顶点和目标顶点,使用 来表示源顶点的关联矩阵,其中只包含
中小于0的元素的绝对值;同样,定义
为目标顶点的关联矩阵,其中只包含
中大于 0 的元素。以下图为例:
可以得到关联矩阵 和对应的
、
,
表示矩阵的转置运算:
给定一个输入张量和关联矩阵,就可以通过矩阵乘法过滤所需的边和顶点并执行聚合函数。例如,给定 和
,首先将
重塑为
矩阵;然后,
和
的乘积可以提供一个
的张量。根据矩阵乘法定义,该张量的每个元素对应于对应边的源顶点的总和。
本文中使用的聚合函数是平均池化操作,并且关联矩阵需要归一化。具体来说,定义 作为
的归一化版本,其中
是对角矩阵且
,
是一个很小的数,以避免除以零,代码如下:
def normalize_digraph(A):
Dl = np.sum(A, 0) # 计算每列的和
h, w = A.shape # 获取矩阵的形状
Dn = np.zeros((w, w)) # 初始化归一化矩阵
for i in range(w):
if Dl[i] > 0: # 避免除以零
Dn[i, i] = Dl[i] ** (-1) # 对角线元素设为 1/Dl[i]
AD = np.dot(A, Dn) # 矩阵相乘,得到归一化后的邻接矩阵
return AD由此,将上一章中的公式修改为:
其中, 表示单层全连接层,即上一章中的更新函数。
类似于传统的卷积层,在每个DGN块之后添加一个BN层和一个ReLU层。
DGN块的代码如下:
class DGNBlock(nn.Module):
def __init__(self, in_channels, out_channels, source_M, target_M):
super().__init__()
self.num_nodes, self.num_edges = source_M.shape
self.source_M = nn.Parameter(torch.from_numpy(source_M.astype('float32')))
self.target_M = nn.Parameter(torch.from_numpy(target_M.astype('float32')))
# 更新函数H_v、H_e
self.H_v = nn.Linear(3 * in_channels, out_channels)
self.H_e = nn.Linear(3 * in_channels, out_channels)
self.bn_v = nn.BatchNorm2d(out_channels)
self.bn_e = nn.BatchNorm2d(out_channels)
bn_init(self.bn_v, 1)
bn_init(self.bn_e, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, fv, fe):
N, C, T, V_node = fv.shape
_, _, _, V_edge = fe.shape
# 将特征张量重塑为 `(N, CT, V)`
fv = fv.view(N, -1, V_node)
fe = fe.view(N, -1, V_edge)
# 聚合函数
# 聚合边到顶点
fe_in_agg = torch.einsum('nce,ev->ncv', fe, self.source_M.transpose(0,1))
fe_out_agg = torch.einsum('nce,ev->ncv', fe, self.target_M.transpose(0,1))
fvp = torch.stack((fv, fe_in_agg, fe_out_agg), dim=1)
fvp = fvp.view(N, 3 * C, T, V_node).contiguous().permute(0,2,3,1)
fvp = self.H_v(fvp).permute(0,3,1,2)
fvp = self.bn_v(fvp)
fvp = self.relu(fvp)
# 聚合顶点到边
fv_in_agg = torch.einsum('ncv,ve->nce', fv, self.source_M)
fv_out_agg = torch.einsum('ncv,ve->nce', fv, self.target_M)
fep = torch.stack((fe, fv_in_agg, fv_out_agg), dim=1)
fep = fep.view(N, 3 * C, T, V_edge).contiguous().permute(0,2,3,1)
fep = self.H_e(fep).permute(0,3,1,2)
fep = self.bn_e(fep)
fep = self.relu(fep)
return fvp, fep此外,为了提高模型训练的灵活性,直接将关联 设置为模型的参数,但将其固定在前几个训练周期。早期固定图形结构可以简化训练,之后取消固定图形结构可以为图形构造提供更大的灵活性。
3.2 TCN
上述的DGN块只能处理单个帧的空间信息,因此,想要处理一系列连续帧的情况,需要完成在骨架序列中建模时间动态的任务。在此之前,有方法使用二维卷积来建模空间信息,然后使用一维卷积来建模时间信息,通过解耦空间和时间维度,可以更经济有效地建模时空信息。受此方法启发,并且由于所有帧中的相同关节或骨骼可以自然地组织成一个一维序列,所以在更新每个DGN块中关节和骨骼的空间信息后,沿着时间维度应用一维卷积来建模时间信息,代码如下:
class TemporalConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=9, stride=1):
super().__init__()
pad = int((kernel_size - 1) / 2) # 计算需要填充的大小,以保持时间维度的尺寸不变
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(kernel_size, 1), # 卷积核仅在时间维度上应用
padding=(pad, 0),
stride=(stride, 1)
)
self.bn = nn.BatchNorm2d(out_channels)
conv_init(self.conv)
bn_init(self.bn, 1)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x然后分别对节点特征和边特征进行时序卷积,组成时间卷积块(TCN),代码如下:
class BiTemporalConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=9, stride=1):
super().__init__()
self.tempconv = TemporalConv(in_channels, out_channels, kernel_size, stride) # 使用 TemporalConv 作为卷积模块
def forward(self, fv, fe):
return self.tempconv(fv), self.tempconv(fe) # 分别对节点和边特征应用时序卷积3.3 双流框架
如“站立”、“坐下”等动作从空间信息中难以识别,需要通过采用计算连续帧之间的像素移动信息来识别,所以本文中提取关节的运动和骨骼的变形来帮助识别。由于骨骼数据是以关节坐标表示的,因此关节的运动可以很容易地通过时间维度的坐标差来计算,同样,骨骼的变形表示为连续帧中同一骨骼向量的差:
- 在时间
时,关节
。骨骼的变形定义为
;
- 与空间信息建模一样,运动信息被表示为有向无环图序列
,其中
,
和
;
- 然后,将运动图输入另一个DGNN以预测动作标签;
- 两个网络最终通过添加softmax层的输出分数进行融合。
4 DGNN网络结构
DGNN的整体架构有9个单元,每个单元包含一个DGN块和一个TCN块,通过结合DGN和TCN,用于捕捉时空特征,再使用双分支时序卷积分别处理节点和边特征,并通过残差连接稳定模型训练:
class GraphTemporalConv(nn.Module):
def __init__(self, in_channels, out_channels, source_M, target_M, temp_kernel_size=9, stride=1, residual=True):
super(GraphTemporalConv, self).__init__()
self.dgn = DGNBlock(in_channels, out_channels, source_M, target_M)
self.tcn = BiTemporalConv(out_channels, out_channels, kernel_size=temp_kernel_size, stride=stride)
self.relu = nn.ReLU(inplace=True)
if not residual: # 不使用残差连接
self.residual = lambda fv, fe: (0, 0) # 返回零张量
elif (in_channels == out_channels) and (stride == 1): # 条件满足时,直接使用输入作为残差
self.residual = lambda fv, fe: (fv, fe)
else: # 其他情况下,使用双分支时序卷积作为残差连接
self.residual = BiTemporalConv(in_channels, out_channels, kernel_size=temp_kernel_size, stride=stride)
def forward(self, fv, fe):
fv_res, fe_res = self.residual(fv, fe)
fv, fe = self.dgn(fv, fe)
fv, fe = self.tcn(fv, fe)
fv += fv_res
fe += fe_res
return self.relu(fv), self.relu(fe)9个单元的输出通道为64、64、64、128、128、128、256、256和256。在分类预测的最后,添加了一个全局平均池化层和一个softmax层,整体网络结构如下:
class Model(nn.Module):
def __init__(self, num_class=60, num_point=25, num_person=2, graph=None, graph_args=dict(), in_channels=3):
super(Model, self).__init__()
if graph is None:
raise ValueError()
else:
Graph = import_class(graph)
self.graph = Graph(**graph_args)
source_M, target_M = self.graph.source_M, self.graph.target_M # 获取邻接矩阵
self.data_bn_v = nn.BatchNorm1d(num_person * in_channels * num_point)
self.data_bn_e = nn.BatchNorm1d(num_person * in_channels * num_point)
self.l1 = GraphTemporalConv(3, 64, source_M, target_M, residual=False) # 输入层
self.l2 = GraphTemporalConv(64, 64, source_M, target_M) # 单元1,输出通道64
self.l3 = GraphTemporalConv(64, 64, source_M, target_M) # 单元2,输出通道64
self.l4 = GraphTemporalConv(64, 64, source_M, target_M) # 单元3,输出通道64
self.l5 = GraphTemporalConv(64, 128, source_M, target_M, stride=2) # 单元4,步幅为2,输出通道128
self.l6 = GraphTemporalConv(128, 128, source_M, target_M) # 单元5,输出通道128
self.l7 = GraphTemporalConv(128, 128, source_M, target_M) # 单元6,输出通道128
self.l8 = GraphTemporalConv(128, 256, source_M, target_M, stride=2) # 单元7,步幅为2,输出通道256
self.l9 = GraphTemporalConv(256, 256, source_M, target_M) # 单元8,输出通道256
self.l10 = GraphTemporalConv(256, 256, source_M, target_M) # 单元9,输出通道256
self.fc = nn.Linear(256 * 2, num_class) # 全连接层,用于分类
# 初始化全连接层权重
nn.init.normal_(self.fc.weight, 0, math.sqrt(2. / num_class))
bn_init(self.data_bn_v, 1)
bn_init(self.data_bn_e, 1)
def count_params(m):
return sum(p.numel() for p in m.parameters() if p.requires_grad)
for module in self.modules():
print('Module:', module)
print('# Params:', count_params(module))
print()
print('Model total number of params:', count_params(self))
def forward(self, fv, fe):
N, C, T, V_node, M = fv.shape
_, _, _, V_edge, _ = fe.shape
# 预处理节点特征
fv = fv.permute(0, 4, 3, 1, 2).contiguous().view(N, M * V_node * C, T)
fv = self.data_bn_v(fv)
fv = fv.view(N, M, V_node, C, T).permute(0, 1, 3, 4, 2).contiguous().view(N * M, C, T, V_node)
# 预处理边特征
fe = fe.permute(0, 4, 3, 1, 2).contiguous().view(N, M * V_edge * C, T)
fe = self.data_bn_e(fe)
fe = fe.view(N, M, V_edge, C, T).permute(0, 1, 3, 4, 2).contiguous().view(N * M, C, T, V_edge)
# 通过多个图时序卷积层
fv, fe = self.l1(fv, fe)
fv, fe = self.l2(fv, fe)
fv, fe = self.l3(fv, fe)
fv, fe = self.l4(fv, fe)
fv, fe = self.l5(fv, fe)
fv, fe = self.l6(fv, fe)
fv, fe = self.l7(fv, fe)
fv, fe = self.l8(fv, fe)
fv, fe = self.l9(fv, fe)
fv, fe = self.l10(fv, fe)
# 提取特征并准备输入全连接层
out_channels = fv.size(1)
fv = fv.view(N, M, out_channels, -1).mean(3).mean(1)
fe = fe.view(N, M, out_channels, -1).mean(3).mean(1)
# 拼接节点和边特征
out = torch.cat((fv, fe), dim=-1)
return self.fc(out) # 返回预测结果总结
本文中通过将关节和骨骼信息表示为有向无环图,每个关节表示为一个节点,边表示关节之间的骨骼连接,从而设计出有向图神经网络(DGNN)来根据构建的图预测动作。此外,还使图结构自适应,以更好地适应多层架构和识别任务。进一步地,提取连续帧之间的运动信息来建模骨骼序列的时间信息,并在双流框架中融合空间和运动信息。

















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









