







Improving Adversarial Transferability via Model Alignment
本文 “Improving Adversarial Transferability via Model Alignment” 提出模型对齐技术,通过微调源模型最小化与见证模型的预测差异,提升对抗样本转移性。经几何分析和大量实验验证,该技术有效且与多种攻击算法兼容,为提升对抗样本转移性提供新方向。
摘要-Abstract
Abstract. Neural networks are susceptible to adversarial perturbations that are transferable across different models. In this paper, we introduce a novel model alignment technique aimed at improving a given source model’s ability in generating transferable adversarial perturbations. During the alignment process, the parameters of the source model are finetuned to minimize an alignment loss. This loss measures the divergence in the predictions between the source model and another, independently trained model, referred to as the witness model. To understand the effect of model alignment, we conduct a geometric analysis of the resulting changes in the loss landscape. Extensive experiments on the ImageNet dataset, using a variety of model architectures, demonstrate that perturbations generated from aligned source models exhibit significantly higher transferability than those from the original source model.
神经网络容易受到对抗扰动的影响,且这些扰动可在不同模型之间转移。在本文中,我们引入了一种新颖的模型对齐技术,旨在提高给定源模型生成可转移对抗扰动的能力。在对齐过程中,源模型的参数会被微调,以最小化一种对齐损失。这种损失衡量的是源模型与另一个独立训练的模型(称为见证模型)之间的预测差异。为了理解模型对齐的效果,我们对损失景观由此产生的变化进行了几何分析。在ImageNet数据集上,使用多种模型架构进行的大量实验表明,与原始源模型生成的扰动相比,对齐后的源模型生成的扰动具有显著更高的可转移性。
引言-Introduction
该部分主要介绍研究背景、研究动机和研究贡献,旨在说明模型对齐技术的重要性与创新性。具体内容如下:
- 研究背景:神经网络易受对抗样本干扰,其微小扰动就能误导网络做出错误预测。同时,对抗扰动具有跨模型转移性,这一特性引发了对机器学习系统在实际应用中安全性的担忧。一种解释是可转移扰动利用了源模型和目标模型的相似特征,神经网络会学习语义特征和人类不可感知特征,其中语义特征提取在不同模型间具有相似性,而人类不可感知特征的学习具有模型特异性 。
- 研究动机:已有研究表明,不同模型间可转移扰动的关键在于利用相似特征,但部分扰动仅针对源模型特定特征,无法有效转移。因此,本文提出模型对齐技术,通过微调源模型参数,使其与见证模型的特征提取相似,进而生成更具转移性的对抗扰动。该技术与其他攻击算法具有互补性,兼容性强。
- 研究贡献:提出模型对齐方法,通过最小化源模型与见证模型的输出差异来微调源模型;对模型对齐过程中损失景观的变化进行几何分析;实验证明,对齐后的源模型生成的对抗扰动在ImageNet数据集上,对多种模型架构的转移性显著提升。
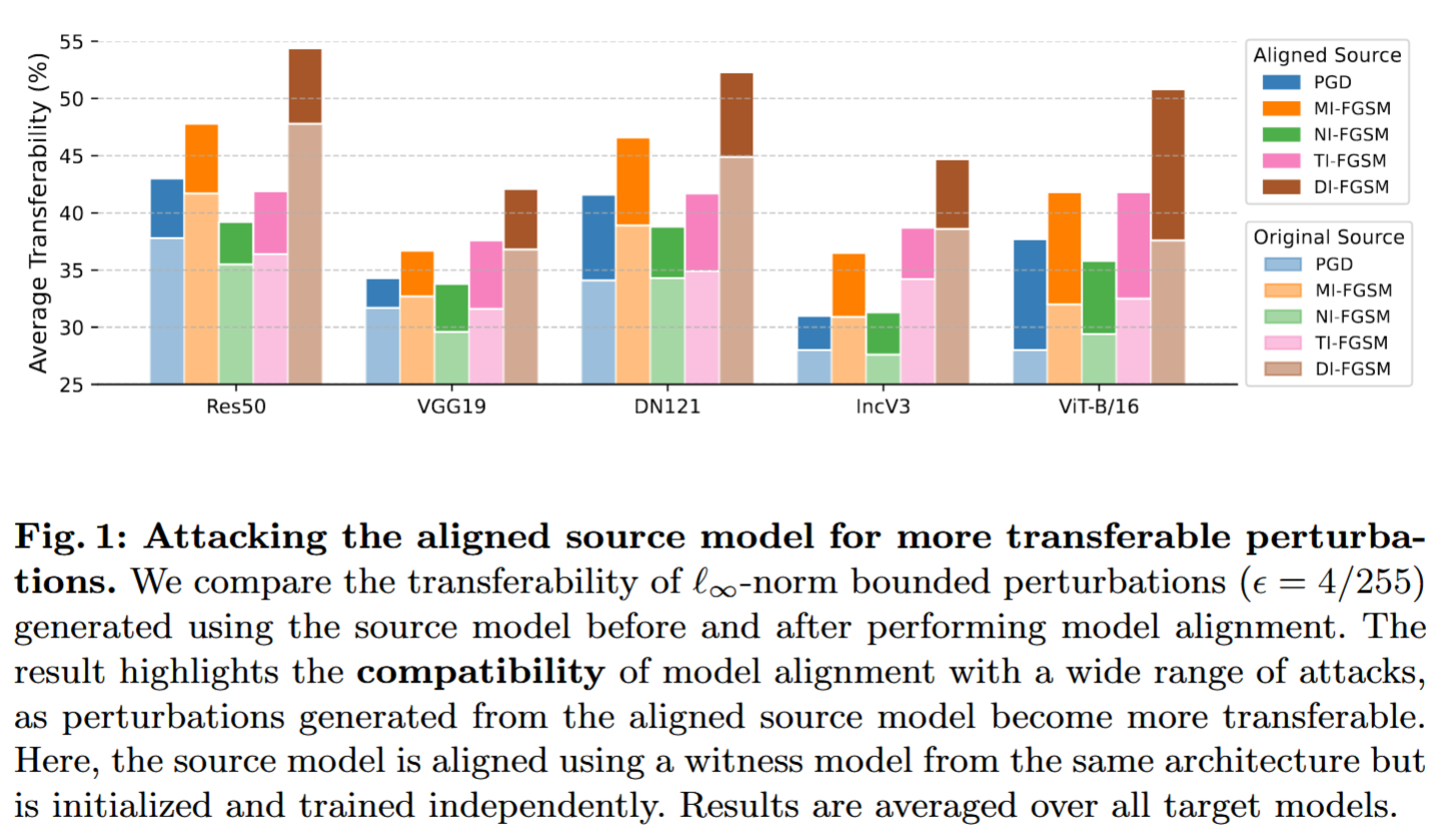
图1:攻击对齐后的源模型以获得更具转移性的扰动。我们比较了在进行模型对齐前后,使用源模型生成的
ℓ
∞
\ell_{\infty}
ℓ∞ 范数有界扰动(
ϵ
=
4
/
255
\epsilon = 4 / 255
ϵ=4/255)的转移性。结果突出了模型对齐与多种攻击方法的兼容性,因为从对齐后的源模型生成的扰动具有更强的转移性。在此,源模型使用具有相同架构但独立初始化和训练的见证模型进行对齐。结果是在所有目标模型上取平均值得到的。
相关工作-Related Work
该部分主要回顾了生成更具转移性对抗扰动的相关方法,以及对对抗扰动转移性理解的研究,为模型对齐技术的提出提供了研究基础与背景,具体内容如下:
- 生成可转移扰动的方法
- 数据增强方法:通过将数据增强技术融入攻击算法,防止对抗样本过度拟合源模型,以此提升其转移性。
- 优化方法:借助如动量、方差调整等优化手段,类比模型泛化概念,提升对抗扰动的转移性。
- 模型修改方法:部分研究提出修改源模型来提高转移性,如去除批归一化、调整非线性激活函数的导数、增强跳跃连接梯度等。与这些方法不同,本文的模型对齐技术具有模型无关性,无需改变模型的前向或后向传播过程。
- 集成方法:利用多个模型生成对抗样本,例如攻击模型集成以欺骗目标模型,或者通过收集模型微调轨迹上的权重构建源模型集成。
- 理解对抗转移性的研究:已有工作从几何角度对对抗扰动的转移性展开分析。Liu等人发现弱转移性对抗样本常处于源模型的局部极大值,部分扰动无法转移是因其处于源模型特有的微小区域。Gubri等人则假设在平坦损失极大值处的对抗样本转移性更强。受这些研究启发,本文在后续研究中从几何角度探究模型对齐方法对源模型损失表面几何形状的影响,以生成转移性更强的对抗样本。
方法-Method
预备知识-Preliminary
该部分主要介绍用于分类任务的神经网络相关基础概念,为理解后续模型对齐方法奠定基础,具体内容如下:
- 神经网络表示:用于 m m m 类分类任务的神经网络可表示为一系列函数组合 f ( x ) = ( ϕ [ l ] ∘ ϕ [ l − 1 ] ∘ ⋯ ∘ ϕ [ 1 ] ) ( x ) f(x)=(\phi^{[l]} \circ \phi^{[l - 1]} \circ \cdots \circ \phi^{[1]})(x) f(x)=(ϕ[l]∘ϕ[l−1]∘⋯∘ϕ[1])(x)。其中, ϕ [ i ] \phi^{[i]} ϕ[i] 代表网络中的操作,包括线性变换(如全连接层)、激活函数或池化操作等;神经网络的参数统一用 θ \theta θ 表示 。
- 隐藏表示与中间输出:网络中各操作的中间输出称为隐藏表示,记为 z [ i ] z^{[i]} z[i] 。其计算关系为 z [ i ] = ϕ [ i ] ( z [ i − 1 ] ) z^{[i]}=\phi^{[i]}(z^{[i - 1]}) z[i]=ϕ[i](z[i−1]),这里 i = 1 , 2 , ⋯ , l i = 1, 2, \cdots, l i=1,2,⋯,l,而初始输入为 z [ 0 ] = x z^{[0]} = x z[0]=x。
- softmax函数与输出解释:在神经网络的最后一层融入softmax函数,即 ϕ [ l ] = s o f t m a x ( z [ l − 1 ] ) \phi^{[l]} = softmax(z^{[l - 1]}) ϕ[l]=softmax(z[l−1]),此时 z [ l − 1 ] z^{[l - 1]} z[l−1] 被称作logits。经过这样的定义,网络的输出 f ( x ) f(x) f(x) 能够被理解为对 m m m 个类别的概率分布,其中每个分量 f ( x ) f(x) f(x) 代表输入属于类别i的概率。
模型对齐-Model Alignment
该部分主要介绍了模型对齐的目标、方法和扩展方式,具体内容如下:
- 模型对齐目标:模型对齐旨在修改源模型,使其提取的特征与见证模型相似。通过这种方式,期望源模型生成的对抗扰动更具转移性,从而增强攻击效果。
- 模型对齐方法:用 θ s \theta_{s} θs 和 θ w \theta_{w} θw 分别表示源模型和见证模型的参数,采用点态公式计算对齐损失: ℓ a ( x , θ s , θ w ) = d ( z s [ q ] ( x ) , z w [ q ] ( x ) ) \ell_{a}\left(x, \theta_{s}, \theta_{w}\right)=d\left(z_{s}^{[q]}(x), z_{w}^{[q]}(x)\right) ℓa(x,θs,θw)=d(zs[q](x),zw[q](x)),其中 d d d 为度量函数,用于衡量模型在 q q q 层的输出差异。当 q = l q = l q=l 时,常使用 KL 散度作为度量,以衡量两个模型生成的概率分布之间的差异。模型对齐是一个微调过程,通过更新源模型参数来最小化对齐损失,捕捉模型间的输出差异。
- 扩展到多个见证模型:对齐过程可扩展到多个见证模型。使用一组见证模型 Θ \Theta Θ(数量为 ∣ Θ ∣ |\Theta| ∣Θ∣),基于随机梯度下降(SGD)的源模型参数更新规则为: θ s ( t + 1 ) = θ s ( t ) − η 1 ∣ B ∣ ∣ Θ ∣ ∑ x ∈ B ∑ θ w ∈ Θ ∇ ℓ a ( x , θ s ( t ) , θ w ) \theta_{s}(t + 1)=\theta_{s}(t)-\eta \frac{1}{|\mathcal{B}||\Theta|} \sum_{x \in \mathcal{B}} \sum_{\theta_{w} \in \Theta} \nabla \ell_{a}\left(x, \theta_{s}(t), \theta_{w}\right) θs(t+1)=θs(t)−η∣B∣∣Θ∣1∑x∈B∑θw∈Θ∇ℓa(x,θs(t),θw),其中 B \mathcal{B} B 表示小批量数据, η \eta η 为学习率。
理解模型对齐-Understanding Model Algnment
该部分从语义特征利用和损失表面几何分析两个角度,深入探究模型对齐的内在机制,揭示其提升对抗样本转移性的原因,具体内容如下:
- 语义特征利用
- 验证目的:验证对齐后的模型生成的对抗扰动是否更多地利用语义特征。
- 验证方法:对比原始源模型和对齐后源模型生成的对抗扰动。由于对抗扰动在空间域难以通过特定特征刻画,研究在频率域进行分析。以往研究表明语义特征多集中在频谱低频端,因此通过离散余弦变换(DCT),比较两种模型生成扰动的DCT系数,即 D C T ( Δ x s ) DCT(\Delta x_{s}) DCT(Δxs) 和 D C T ( Δ x a ) DCT(\Delta x_{a}) DCT(Δxa),并计算 ∣ D C T ( Δ x a ) ∣ − ∣ D C T ( Δ x s ) ∣ |DCT(\Delta x_{a})|-|DCT(\Delta x_{s})| ∣DCT(Δxa)∣−∣DCT(Δxs)∣ ,结果取ImageNet测试集1000张随机采样图像的平均值。
- 验证结果:从图2可知,两种扰动的差异主要集中在DCT频谱左上角,即低频信息部分。这表明对齐后模型生成的对抗扰动更多地利用了低频语义特征。
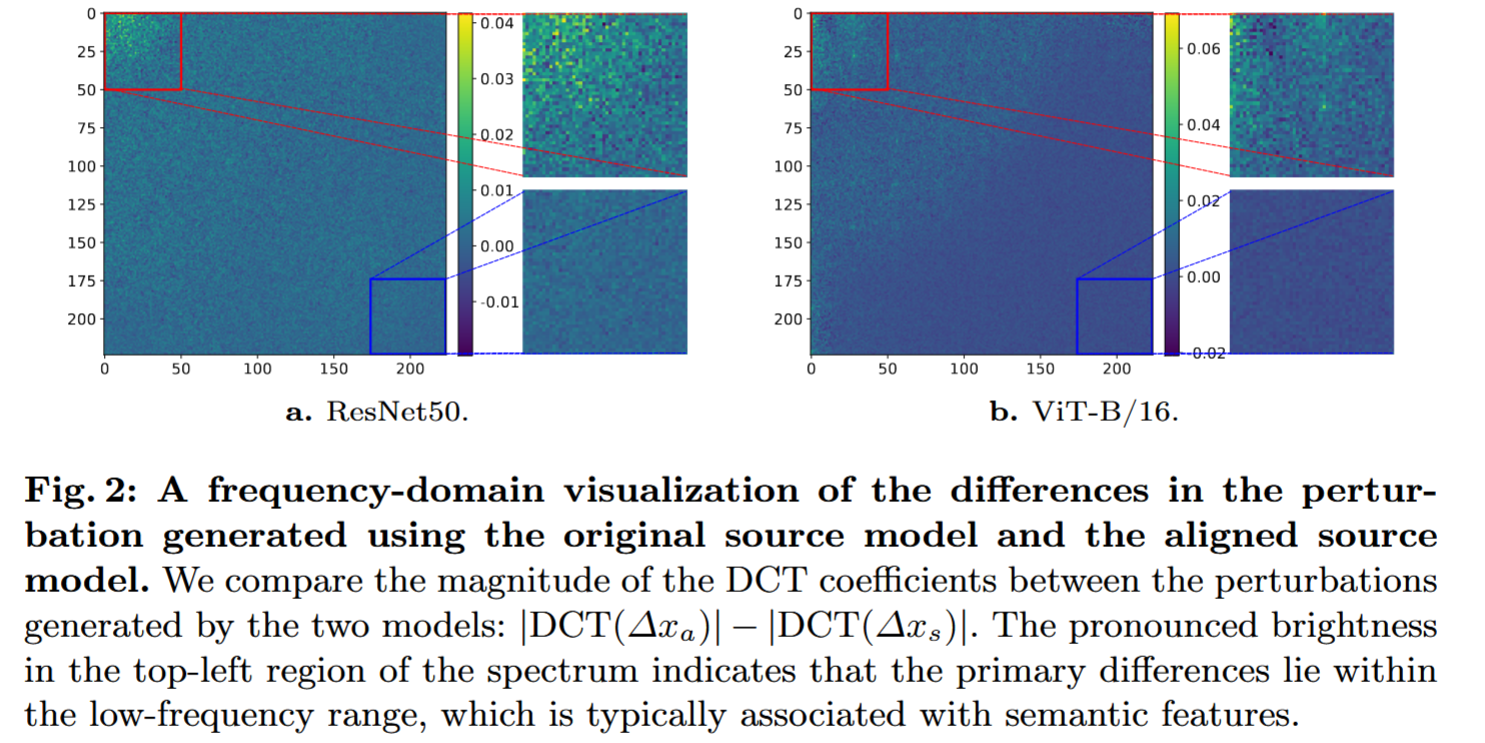
图2:使用原始源模型和对齐后的源模型生成的扰动差异的频域可视化。我们比较了这两个模型生成的扰动的离散余弦变换(DCT)系数的幅度: ∣ D C T ( Δ x a ) ∣ − ∣ D C T ( Δ x s ) ∣ |DCT(\Delta x_{a})| - |DCT(\Delta x_{s})| ∣DCT(Δxa)∣−∣DCT(Δxs)∣。频谱左上角明显的亮度表明,主要差异存在于低频范围内,而低频通常与语义特征相关。
- 损失表面几何分析
- 研究背景:先前研究发现,尖锐损失极大值处的扰动转移性较差。本文拓展该几何视角,探究模型对齐对源模型损失表面几何形状的影响,以及其与生成更具转移性对抗样本的关系。
- 分析过程:当对齐损失使用 KL 散度衡量两模型预测差异时,源模型在对齐过程中使用见证模型输出的软标签进行微调。与硬标签相比,软标签能防止模型过度自信,提升泛化能力,还可隐式正则化输入雅可比范数,使决策边界更平滑。在图3中,针对基于原始源模型生成的扰动无法转移,而对齐后模型生成的扰动能误导目标模型的情况,对该数据点周围的损失表面进行可视化。以
Δ
x
s
\Delta x_{s}
Δxs、
Δ
x
s
⊥
\Delta x_{s}^{\perp}
Δxs⊥、
Δ
x
a
\Delta x_{a}
Δxa 和
Δ
x
a
⊥
\Delta x_{a}^{\perp}
Δxa⊥ 两对正交向量所张成的平面展示损失表面,其中
Δ
x
s
⊥
\Delta x_{s}^{\perp}
Δxs⊥ 和
Δ
x
a
⊥
\Delta x_{a}^{\perp}
Δxa⊥ 是随机选择且受相同
ϵ
\epsilon
ϵ 约束的正交向量,图中青色点为干净数据点,红色点为对抗样本。
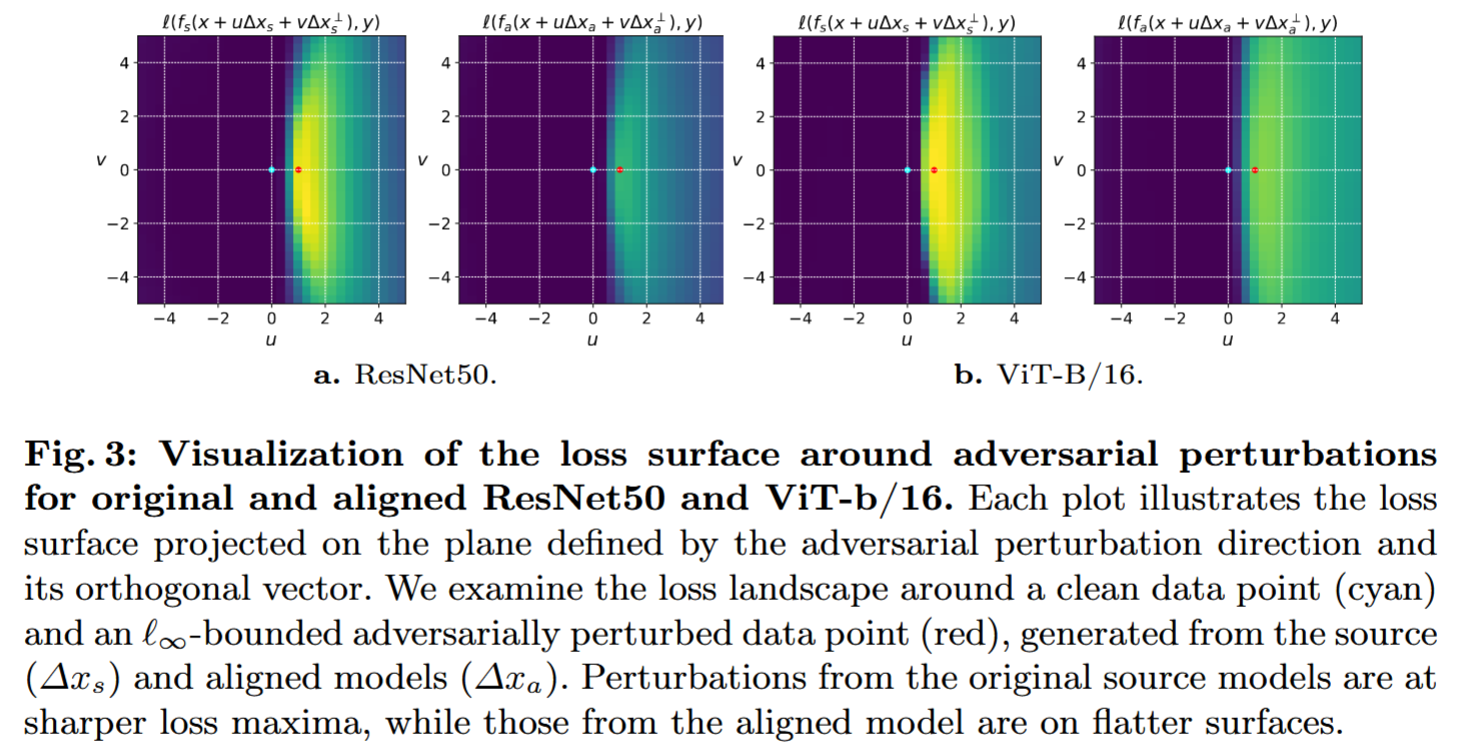
图3:原始和对齐后的ResNet50与ViT-b/16对抗扰动周围损失曲面的可视化。每张图展示了损失曲面在由对抗扰动方向及其正交向量所定义平面上的投影。我们研究了一个干净数据点(青色)和一个由源模型( Δ x s \Delta x_{s} Δxs)及对齐模型( Δ x a \Delta x_{a} Δxa)生成的 ℓ ∞ \ell_{\infty} ℓ∞ 范数有界对抗扰动数据点(红色)周围的损失景观。原始源模型产生的扰动位于更尖锐的损失极大值处,而对齐模型产生的扰动则处于更平坦的曲面上。 - 分析结果:原始源模型生成的扰动位于尖锐损失极大值处(图中明亮黄色区域),应用到目标模型时无法有效增加损失;而对齐后模型生成的扰动周围损失表面更平坦,符合平坦极大值处对抗扰动更易转移的结论。此外,通过评估损失梯度的
ℓ
2
\ell_{2}
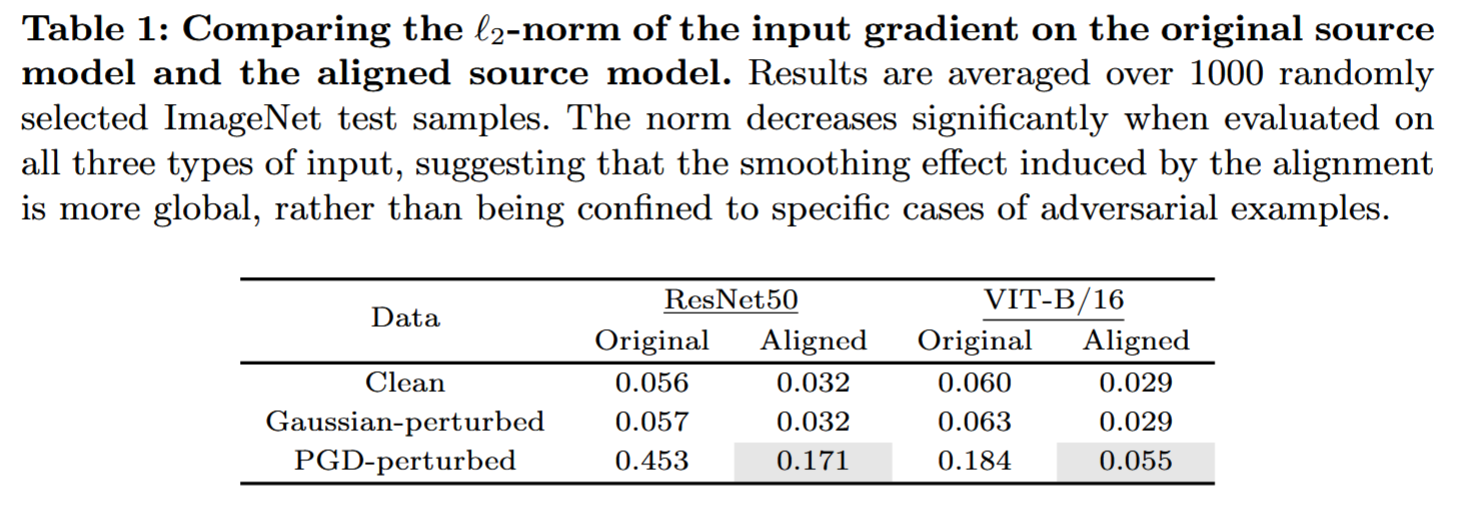
ℓ2 范数变化发现,对齐过程对干净、高斯扰动和PGD扰动输入的梯度范数均有显著降低,表明其平滑效果具有全局性,这进一步解释了对齐后模型对抗扰动转移性提升的原因。在附录C.2中,还讨论了输入Hessian矩阵最大特征值的变化等相关结果,进一步支持了上述结论。
表1:比较原始源模型和对齐后的源模型输入梯度的 ℓ 2 \ell_{2} ℓ2 范数。结果是对从ImageNet测试集中随机选取的1000个样本求平均得到的。在对所有三种类型的输入进行评估时,该范数均显著下降,这表明对齐所引起的平滑效应更具全局性,而非局限于对抗样本的特定情形。
实验-Experiments
该部分通过一系列实验验证了模型对齐技术的有效性,包括提升对抗扰动转移性、探究影响对齐过程的因素以及展示与多种攻击算法的兼容性,具体内容如下:
- 实验设置
- 模型选择:选用多种神经网络架构作为源模型、见证模型和目标模型,如CNNs中的ResNet系列、VGG19等,ViTs中的Swin Transformers、ViT - T/16等。
- 微调策略:源模型在对齐过程中使用SGD进行一个epoch的微调,设置动量为0.9,采用余弦退火学习率衰减和线性热身策略。对不同模型设置不同的学习率,使用特定的批大小,对ViT - 基模型进行梯度裁剪。
- 数据集:基于ImageNet测试集随机选择1000个样本,要求这些样本能被源模型和目标模型正确分类,且从各模型生成的对抗样本能使各自模型误分类。
- 攻击方法:聚焦于 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束的非针对性对抗扰动,默认使用20次迭代的PGD攻击,设置 ϵ = 4 / 255 \epsilon = 4 / 255 ϵ=4/255, α = 1 / 255 \alpha = 1 / 255 α=1/255。
- 评估指标:以错误率衡量对抗扰动的转移性,错误率越高表示转移性越强。实验结果取三次独立运行的平均值。
- 模型对齐提升转移性
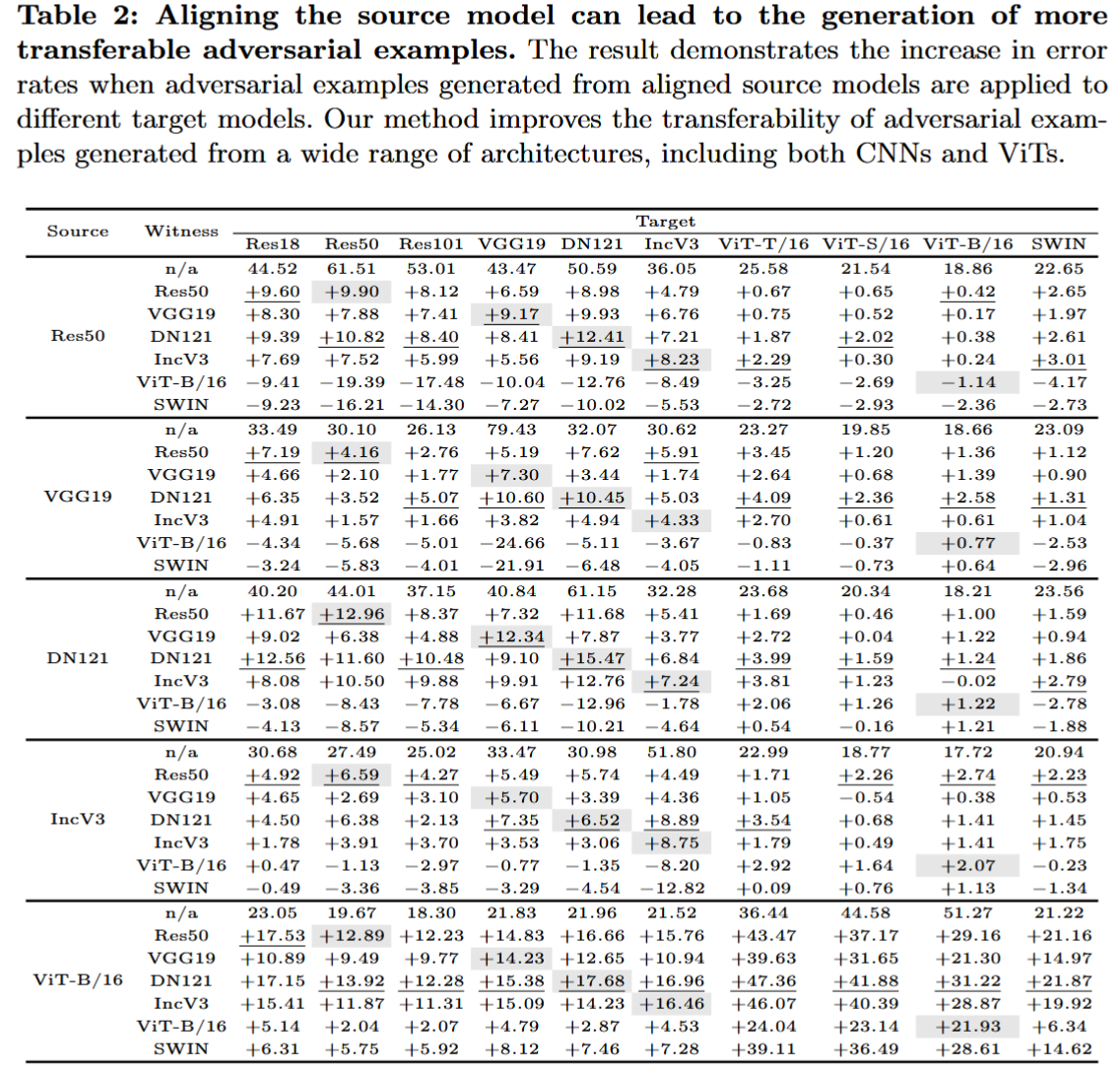
- 整体提升效果:在多种源模型和见证模型组合下,对众多目标模型进行评估,发现模型对齐能显著提升PGD攻击生成的对抗扰动的转移性。这表明对齐源模型可有效生成转移性更强的对抗样本,且CNNs和ViTs源模型均能从中受益。
- 不同模型架构间的对齐差异:研究发现CNN - 基源模型与CNN - 基见证模型对齐效果更好,而ViT - B/16源模型与CNN和ViT家族见证模型对齐都能提升转移性。可能原因是ViTs和CNNs学习的特征差异较大,在模型对齐中存在不对称性。
- 见证模型选择:实验结果表明,改进的转移性不受特定见证模型选择的限制,采用相同架构但独立初始化和训练的自对齐策略有效。同时,还探讨了防止过拟合的方法,如早期停止、使用多个见证模型以及调整softmax函数的温度缩放等。
表2:对齐源模型能够生成更具转移性的对抗样本。该结果展示了将对齐后的源模型生成的对抗样本应用于不同目标模型时,错误率的提升情况。我们的方法提高了从多种架构(包括卷积神经网络(CNNs)和视觉Transformer(ViTs))生成的对抗样本的转移性。
- 消融实验
-
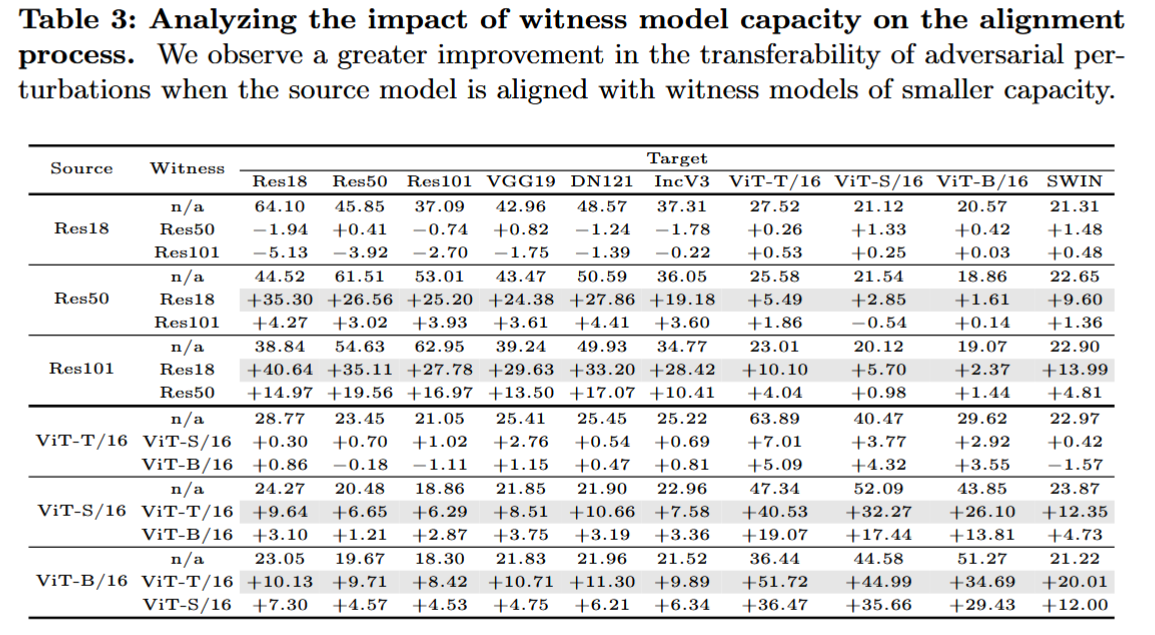
见证模型容量的影响:研究发现当见证模型容量较小时,模型对齐更有效。如使用Res101作为源模型时,与低容量的Res18对齐比与Res50对齐更能提升对抗扰动的转移性。原因可能是小模型更专注于学习语义特征,源模型与小模型对齐时能学习到更多跨模型共享的语义特征,从而生成更具转移性的扰动。
表3:分析见证模型容量对对齐过程的影响。我们发现,当源模型与容量较小的见证模型对齐时,对抗扰动的转移性有更显著的提升。
-
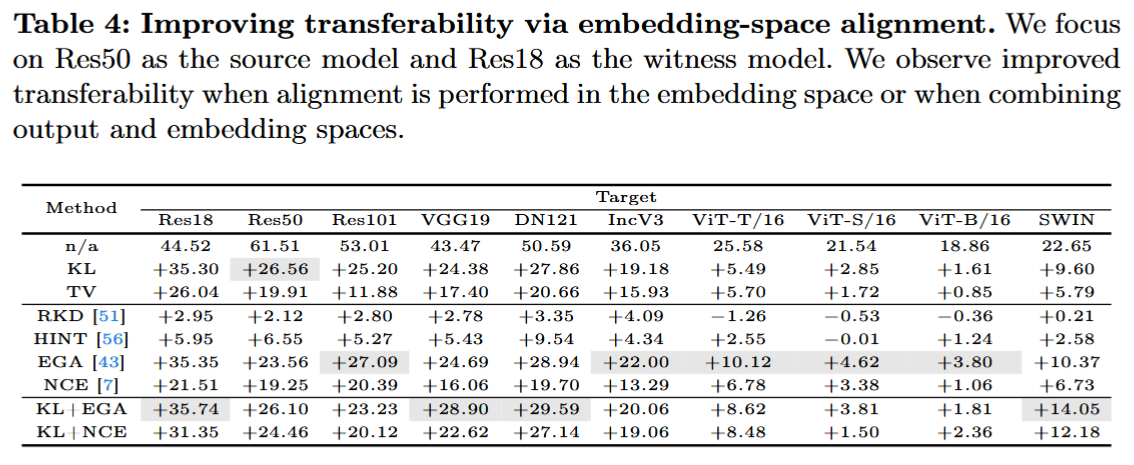
嵌入空间对齐的效果:受知识蒸馏中对齐中间表示的启发,对Res50源模型和Res18见证模型的隐藏表示进行对齐实验。设置 q q q 为全连接层前的层,评估多种嵌入空间蒸馏方法,发现嵌入空间对齐或结合输出与嵌入空间对齐都能提升转移性。
表4:通过嵌入空间对齐提高转移性。我们以Res50作为源模型,Res18作为见证模型。我们发现,在嵌入空间进行对齐,或者同时结合输出空间和嵌入空间进行对齐时,转移性会得到提升。
-
与其他转移增强方法的兼容性:实验表明模型对齐与多种攻击算法兼容,如基于优化的MI - FGSM、NI - FGSM等,以及基于数据增强的TI - FGSM、DI - FGSM等。即使增大 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束和迭代次数,模型对齐仍能提升攻击算法的转移性。此外,模型对齐还能与模型修改攻击方法(如LinBP和BPA)集成,提升其对抗扰动的转移性。
表5:模型对齐与不同攻击算法的兼容性。Res50和ViT-B/16源模型分别与Res18和ViT-T/16见证模型进行对齐。表格中的每个条目都以原始源模型生成的扰动的错误率开头,随后是模型对齐后错误率的变化。结果表明,模型对齐过程提高了所有攻击算法的有效性。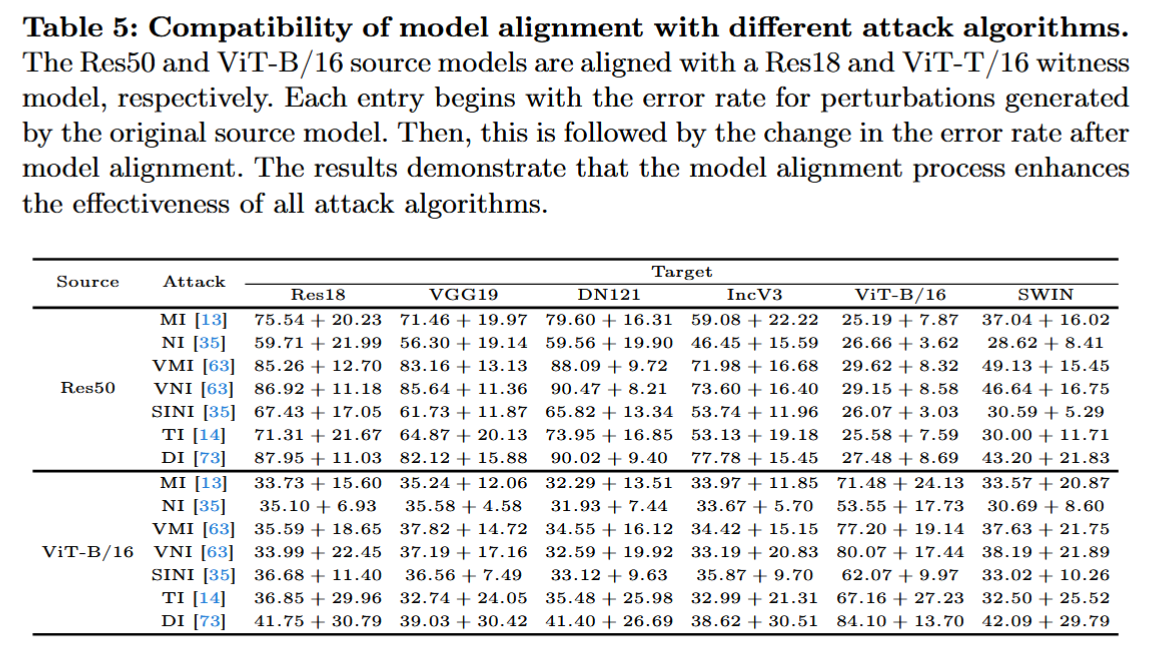
-
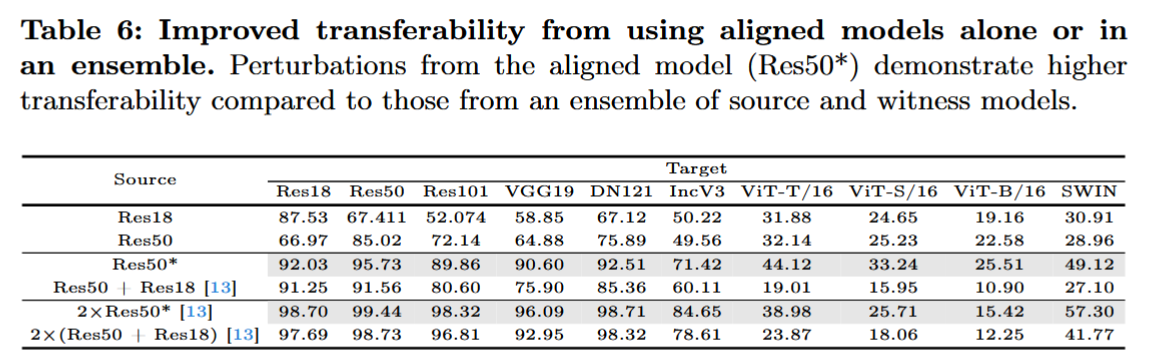
与集成攻击的比较:对比对齐模型和源模型与见证模型集成生成的对抗扰动,发现单个对齐模型的扰动转移性更高,且两个对齐模型的集成进一步提升了转移性,同时在推理时间和内存需求上优于传统集成方法。此外,还发现针对ViTs时,ResNet集成生成的扰动转移性有限。
表6:单独使用对齐模型或使用对齐模型的集成可提高转移性。与源模型和见证模型的集成所产生的扰动相比,来自对齐模型(Res50)的扰动表现出更高的转移性。*
-
结论-Conclusion
本文提出模型对齐技术来提升对抗样本的转移性,结论部分总结了该技术的核心内容、研究成果以及未来研究方向:
- 模型对齐技术概述:模型对齐通过微调源模型参数,最小化其与见证模型预测结果的差异,从而改善源模型生成可转移对抗扰动的能力。在ImageNet数据集上,使用多种模型架构进行实验,结果表明对齐后的源模型生成的对抗扰动转移性显著高于原始源模型。
- 研究成果
- 理论分析:对模型对齐过程进行几何分析,研究其对损失景观的影响。发现模型对齐使源模型的损失表面更平滑,这与使用软标签训练模型的效果相似,能够有效提升对抗扰动的转移性。
- 实验验证:模型对齐与多种攻击算法具有兼容性,且在不同模型架构(包括CNNs和ViTs)的源模型上均有效。此外,通过消融实验,确定了较小容量的见证模型以及嵌入空间对齐等因素对提升对抗扰动转移性的积极作用。
- 未来研究方向:目前研究的局限性在于缺乏理解模型对齐过程的理论框架,未来将致力于构建相关理论体系,进一步完善对模型对齐技术的研究。


















 3702
3702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











