




Interpreting Adversarial Attacks and Defences using Architectures with Enhanced Interpretability
- 摘要-Abstract
- 引言及相关工作-Introduction and related works
- 对鲁棒模型和标准模型的主成分分析-PCA analysis in robust and standard models
- 全连接的鲁棒模型和标准模型的活动子网络重叠情况-Active subnetwork overlap in fully connected robust vs standard models
- 卷积架构中鲁棒模型与标准模型门控模式的分析与解释-Analysis and interpretation of gating patterns in robust vs standard models in convolutional architectures
- 结论-Conclusion
本文 “Interpreting Adversarial Attacks and Defences using Architectures with Enhanced Interpretability” 利用深度线性门控网络(DLGN)架构,对比分析了标准训练(STD - TR)和投影梯度下降对抗训练(PGD - AT)的模型,从多个角度揭示了对抗训练模型的特性,为理解对抗攻击与防御提供了新视角。
摘要-Abstract
Adversarial attacks in deep learning represent a significant threat to the integrity and reliability of machine learning models. Adversarial training has been a popular defence technique against these adversarial attacks. In this work, we capitalize on a network architecture, namely Deep Linearly Gated Networks (DLGN ), which has better interpretation capabilities than regular deep network architectures. Using this architecture, we interpret robust models trained using PGD adversarial training and compare them with standard training. Feature networks in DLGN act as feature extractors, making them the only medium through which an adversary can attack the model. We analyze the feature network of DLGN with fully connected layers with respect to properties like alignment of the hyperplanes, hyperplane relation with PCA, and subnetwork overlap among classes and compare these properties between robust and standard models. We also consider this architecture having CNN layers wherein we qualitatively (using visualizations) and quantitatively contrast gating patterns between robust and standard models. We uncover insights into hyperplanes resembling principal components in PGDAT and STD-TR models, with PGD-AT hyperplanes aligned farther from the data points. We use path activity analysis to show that PGD-AT models create diverse, non-overlapping active subnetworks across classes, preventing attack-induced gating overlaps. Our visualization ideas show the nature of representations learnt by PGD-AT and STD-TR models.
深度学习中的对抗攻击对机器学习模型的完整性和可靠性构成了重大威胁。对抗训练是一种流行的针对这些对抗攻击的防御技术。在这项工作中,我们利用了一种网络架构,即深度线性门控网络(DLGN),它比常规深度网络架构具有更好的可解释性。使用这种架构,我们对通过投影梯度下降(PGD)对抗训练得到的鲁棒模型进行解读,并将它们与标准训练的模型进行比较。DLGN中的特征网络充当特征提取器,这使得它们成为对手攻击模型的唯一媒介。我们分析了具有全连接层的DLGN特征网络在超平面对齐、超平面与主成分分析(PCA)的关系以及不同类别之间子网络重叠等属性方面的情况,并比较了鲁棒模型和标准模型在这些属性上的差异。我们还考虑了具有卷积神经网络(CNN)层的这种架构,在其中我们通过定性(使用可视化方法)和定量的方式对比鲁棒模型和标准模型之间的门控模式。我们揭示了PGD - AT和标准训练(STD - TR)模型中与主成分相似的超平面的相关见解,发现PGD - AT模型的超平面与数据点的对齐距离更远。我们通过路径活动分析表明,PGD - AT模型在不同类别之间创建了多样化、不重叠的活动子网络,防止了攻击引起的门控重叠。我们的可视化方法展示了PGD - AT和STD - TR模型所学习到的表示的本质。
引言及相关工作-Introduction and related works
这部分内容主要介绍了对抗攻击与防御的背景、模型鲁棒性的解释方法,引出深度线性门控网络(DLGN),并阐述了研究目标,具体如下:
- 对抗攻击与防御:机器学习算法在正常情况下表现良好,但易受精心设计的对抗样本影响,引发安全问题。白盒攻击中,攻击者可获取模型内部信息,PGD攻击是实践中较强的白盒攻击方式。针对对抗攻击,已有多种防御技术,其中Madry等人提出的对抗训练(PGD - AT)将防御视为求解极小极大优化问题,受到广泛关注。
- 模型鲁棒性的解释:对抗攻击与防御的发展促使众多研究从不同角度分析对抗攻击,如分布转移分析、特征表示分析(反演、傅里叶频谱分析等)、主成分分析和Shapley值分析等。
- 深度线性门控网络(DLGN):Relu激活可看作输入与门的乘积,控制网络通路的激活状态。DGN架构将模型训练视为激活子网络学习,由特征网络和值网络组成。但DGN中值网络可视化意义不大,特征网络因非线性难以解释。DLGN则将门控信号从特征网络移出,使特征网络完全线性,相比标准架构具有显著的可解释性优势。
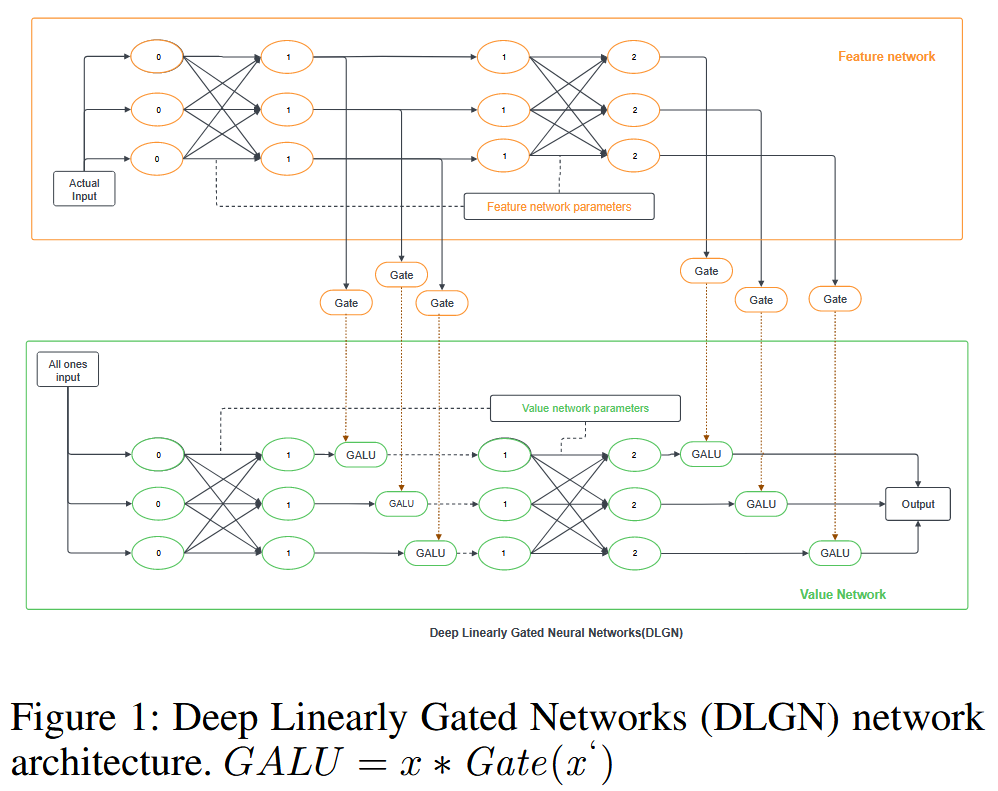
图1:深度线性门控网络(DLGN)架构。 G A L U = x ∗ G a t e ( x ) GALU = x * Gate(x) GALU=x∗Gate(x) - 研究目标:利用DLGN模型增强的可解释性,通过分析模型内部结构,对比标准训练(STD - TR)和PGD - AT训练的模型。运用DLGN架构特有的超平面分析,结合神经网络中的特征可视化和路径视图等方法,从多个维度深入理解模型的鲁棒性 。
- 本文贡献:本文聚焦于借助深度线性门控网络(DLGN)架构对比分析PGD对抗训练(PGD - AT)和标准训练(STD - TR)模型,获得了一系列关键成果:
- 超平面分析新发现:通过合并DLGN特征网络层,揭示PGD - AT和STD - TR模型超平面特性。PGD - AT模型超平面离数据点更远,在增强模型对抗攻击的鲁棒性上发挥关键作用。
- 子网络重叠研究成果:利用神经路径核衡量子网络重叠,发现PGD - AT模型在不同类间生成的活动子网络更多样,面对攻击时,能有效避免不同类样本的活动子网络重叠,提升模型容量利用效率。
- 门控模式定量分析结论:运用交并比思想定量比较门控重叠,表明PGD - AT模型能有效防止门控模式显著变化,避免攻击引起的门控变化与其他类重叠,保障模型稳定准确。
- 模型表示可视化解读:借助可视化技术解读模型表示,PGD - AT模型在捕捉类特征和面对对抗攻击时保持类信息方面表现更优,而STD - TR模型则相对脆弱。
全连接鲁棒和标准模型特征网络中超平面分析-Analysis of hyperplanes in feature network of fully connected robust and standard models
该部分主要围绕全连接的鲁棒模型(PGD - AT训练)和标准模型(STD - TR训练),对DLGN特征网络中的超平面进行分析,通过引入相关符号和实验,揭示超平面特性与模型鲁棒性的关系,具体内容如下:
- 符号定义与有效线性变换:定义了模型中特征网络和值网络的参数,如 θ f \theta_{f} θf、 θ v \theta_{v} θv,以及特征网络各层的权重 W l W_{l} Wl、偏置 b l b_{l} bl 等。在全连接的DLGN架构中,特征网络完全线性,通过合并前面的层可得到每层的有效线性变换,包括有效权重 E l E_{l} El 和偏置 p l p_{l} pl. 这种分析因层间的非线性在标准神经网络中难以实现。
- 超平面与模型鲁棒性的关系:对于输入扰动 δ \delta δ,从公式推导可知, E l p x + p l E_{l}^{p}x + p_{l} Elpx+pl 的值越大,门在路径 p p p 上的敏感度越低,模型的对抗鲁棒性越强。直观理解为数据点离超平面越远,需要更大或多维度的扰动才会翻转门,进而影响模型输出。
- 实验分析
- MNIST和Fashion MNIST数据集实验:在MNIST和Fashion MNIST数据集上分别训练具有四个全连接层(宽度128)的DLGN模型,采用标准训练和PGD - AT训练(
ϵ
=
0.3
\epsilon = 0.3
ϵ=0.3,
α
=
0.1
\alpha = 0.1
α=0.1,
T
=
40
T = 40
T=40),并使用PGD攻击(40步,
ϵ
=
0.3
\epsilon = 0.3
ϵ=0.3)。实验发现,PGD - AT模型中每个超平面上翻转的点比STD - TR模型少。通过计算数据点到超平面的投影距离
E
l
T
x
+
p
l
∥
E
l
∥
2
\frac{E_{l}^{T}x + p_{l}}{\left\|E_{l}\right\|_{2}}
∥El∥2ElTx+pl,发现投影距离越大,门翻转越少,鲁棒性越强。并且PGD - AT模型中数据点到超平面的中位数投影距离在许多超平面索引上比STD - TR模型更高。
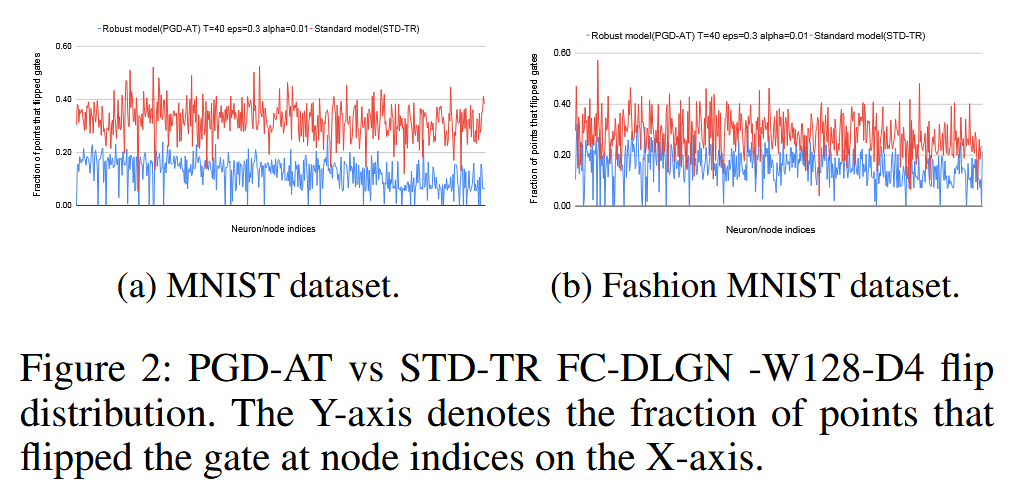
图2:PGD - AT与STD - TR全连接深度线性门控网络(FC - DLGN)-宽度128 - 4层模型的门翻转分布。Y轴表示在X轴所示节点索引处翻转门的点的比例。
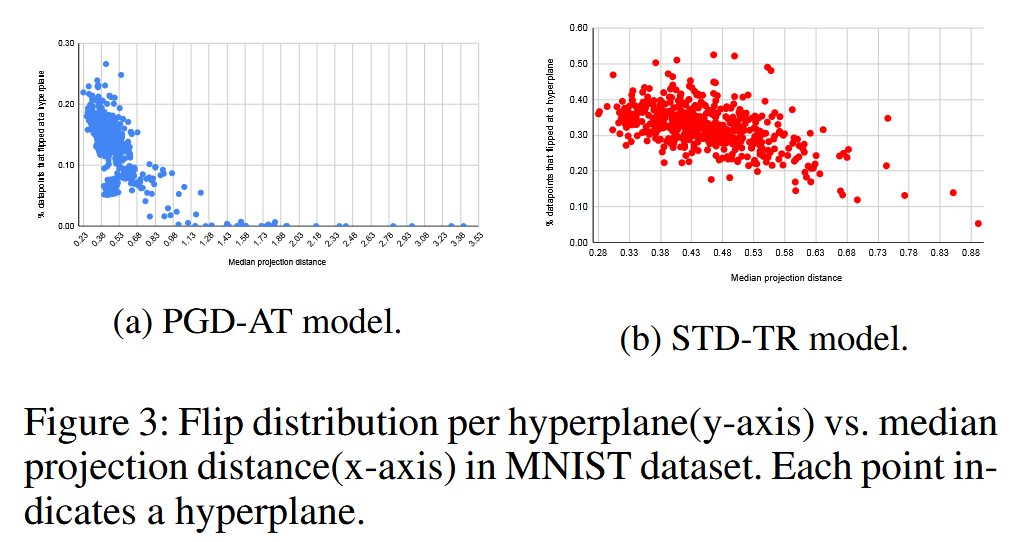
图3:MNIST数据集中每个超平面的翻转分布(纵轴)与投影距离(横轴)的关系。每个点代表一个超平面。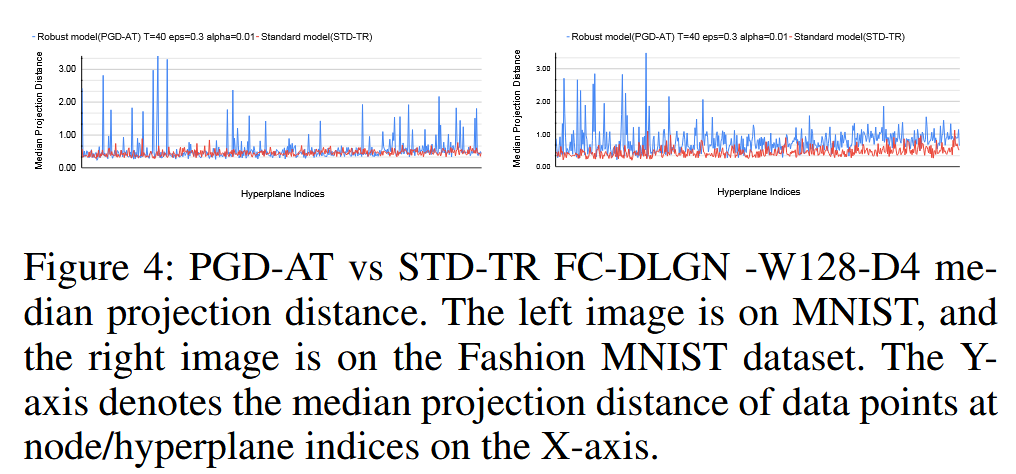
图4:PGD - AT与STD - TR的全连接深度线性门控网络(FC - DLGN)-宽度128 - 4层模型的中位数投影距离对比。左边的图是关于MNIST数据集的,右边的图是关于Fashion MNIST数据集的。Y轴表示在X轴上节点/超平面索引处数据点的中位数投影距离。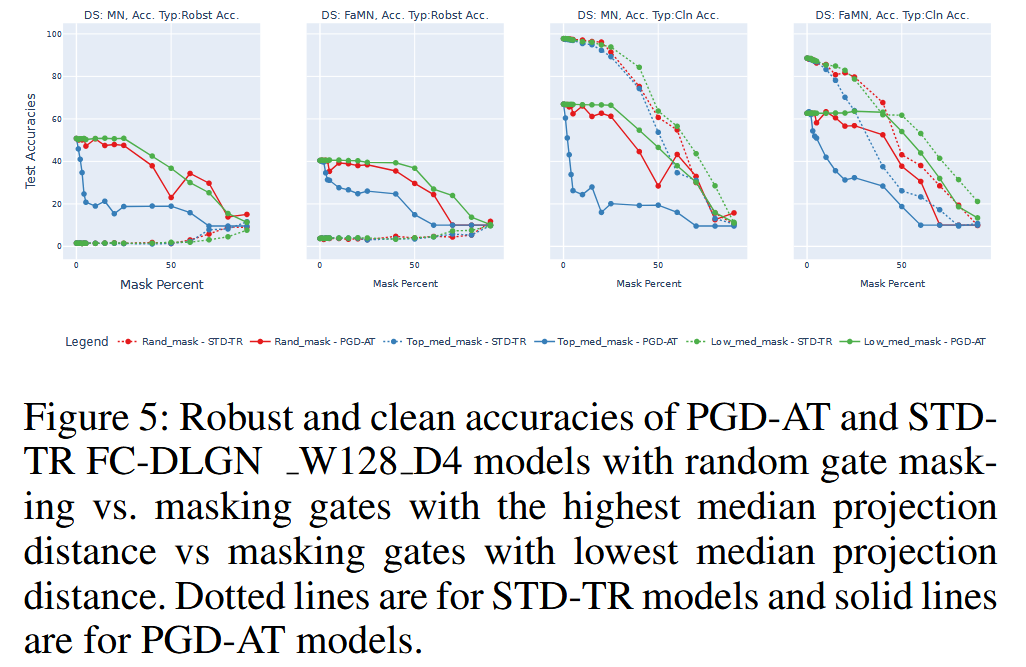
图5:PGD - AT和STD - TR的全连接深度线性门控网络(FC - DLGN)W128 D4模型在随机掩蔽门、掩蔽具有最高中位数投影距离的门以及掩蔽具有最低中位数投影距离的门这三种情况下的鲁棒准确率和干净准确率对比。虚线代表STD - TR模型,实线代表PGD - AT模型。 - 合成XOR数据集实验:构建2D XOR数据集,训练具有3个全连接层(宽度4)的DLGN模型。结果显示,PGD - AT模型的决策边界更接近最优,其学习到的超平面比STD - TR模型离数据点更远,且这种趋势在更深层更明显,进一步证明超平面与数据点距离大对增强鲁棒性至关重要。
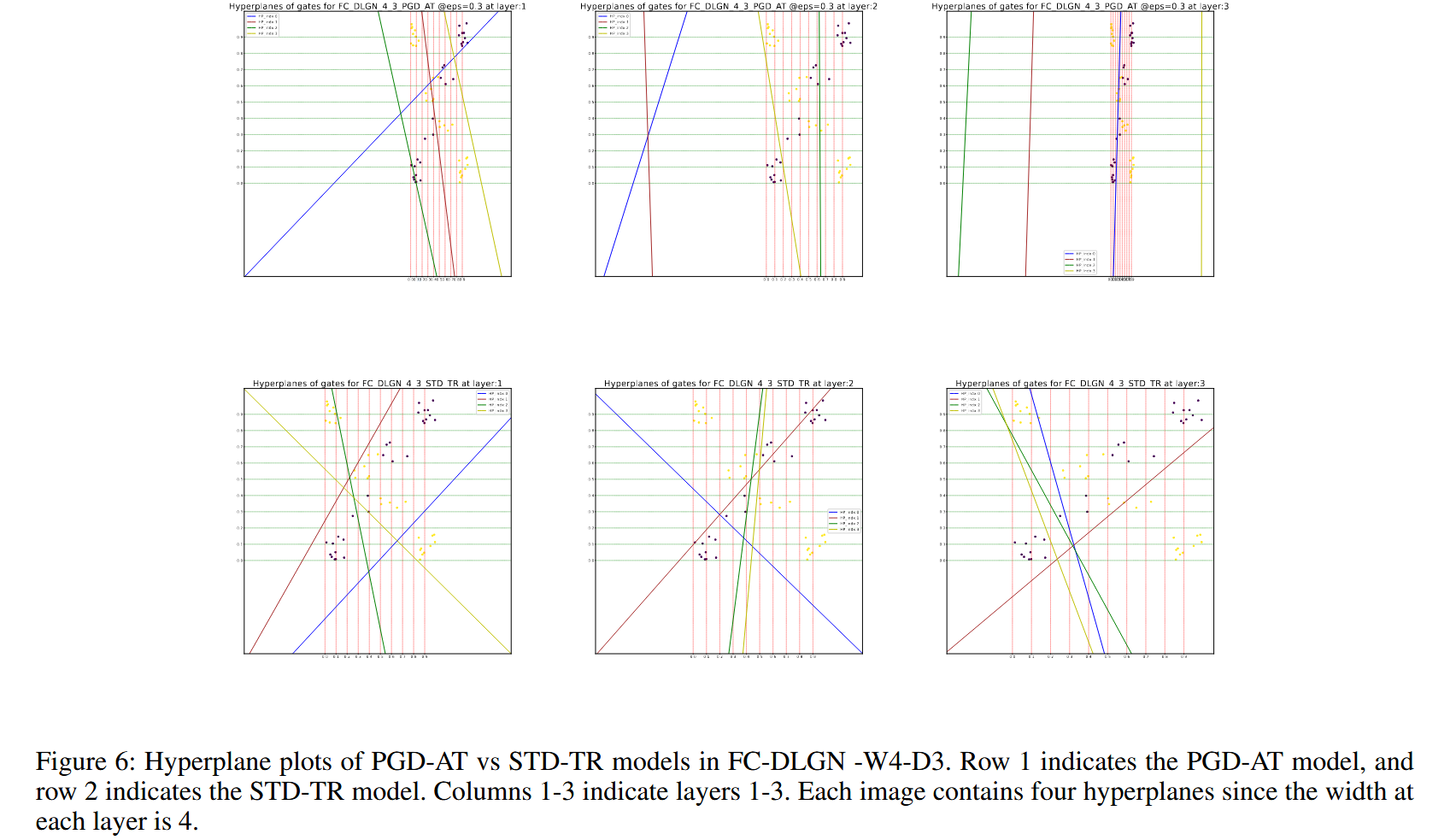
图6:全连接深度线性门控网络(FC - DLGN)-宽度4 - 3层模型中,PGD - AT与STD - TR模型的超平面绘图。第一行表示PGD - AT模型,第二行表示STD - TR模型。第1 - 3列分别表示第1 - 3层。由于每层的宽度为4,所以每张图包含四个超平面。
- MNIST和Fashion MNIST数据集实验:在MNIST和Fashion MNIST数据集上分别训练具有四个全连接层(宽度128)的DLGN模型,采用标准训练和PGD - AT训练(
ϵ
=
0.3
\epsilon = 0.3
ϵ=0.3,
α
=
0.1
\alpha = 0.1
α=0.1,
T
=
40
T = 40
T=40),并使用PGD攻击(40步,
ϵ
=
0.3
\epsilon = 0.3
ϵ=0.3)。实验发现,PGD - AT模型中每个超平面上翻转的点比STD - TR模型少。通过计算数据点到超平面的投影距离
E
l
T
x
+
p
l
∥
E
l
∥
2
\frac{E_{l}^{T}x + p_{l}}{\left\|E_{l}\right\|_{2}}
∥El∥2ElTx+pl,发现投影距离越大,门翻转越少,鲁棒性越强。并且PGD - AT模型中数据点到超平面的中位数投影距离在许多超平面索引上比STD - TR模型更高。
对鲁棒模型和标准模型的主成分分析-PCA analysis in robust and standard models
该部分主要研究了主成分分析(PCA)对鲁棒模型(PGD - AT训练)和标准模型(STD - TR训练)的影响,以及PCA与超平面之间的关系,具体内容如下:
- 研究动机:PCA旨在最小化点到超平面的距离,而PGD - AT过程是通过增加这些距离来提高模型的鲁棒性,两者存在根本差异。这一差异促使研究人员探究PCA对对抗训练的影响。
- 实验设置:将PCA投影操作嵌入DLGN架构的输入层,确保训练和推理过程都考虑到这种变换,同时使攻击者知晓该操作且不改变模型输入维度。为抵消PCA降维带来的模型容量损失,增加所有层的宽度以保持模型容量恒定。
- 实验结果:在MNIST和Fashion MNIST数据集上的实验表明,与STD - TR模型相比,PGD - AT模型在嵌入PCA后,PGD - 40和干净准确率都显著下降。这表明PCA对PGD - AT模型的对抗鲁棒性产生了负面影响,说明PCA的降维操作与对抗训练的鲁棒性目标存在冲突。
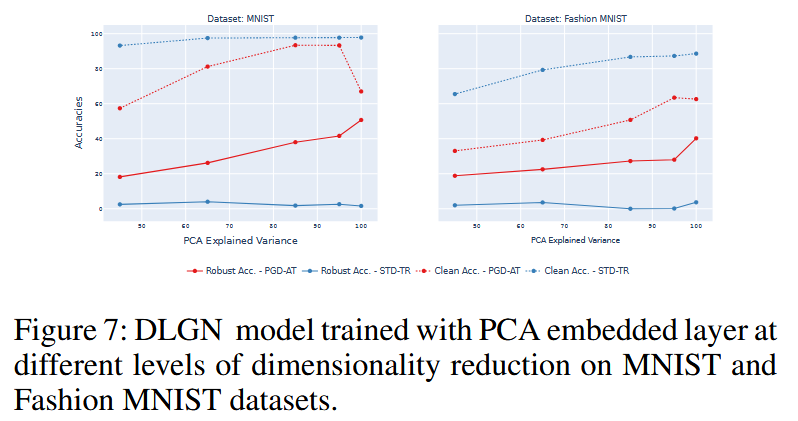
图7:在MNIST和Fashion MNIST数据集上,嵌入PCA层并进行不同程度降维训练的深度线性门控网络(DLGN)模型。 - PCA与超平面关系分析:计算MNIST和Fashion MNIST训练数据集的前k个主成分,并分析其与模型特征网络层有效权重的相似性(通过
C
l
=
P
T
E
l
C_{l}=P^{T}E_{l}
Cl=PTEl 计算)。结果显示,STD - TR模型中主成分与超平面的对齐度高于PGD - AT模型,这支持了PGD - AT模型超平面是为最大化鲁棒性而非最小化点到超平面距离的观点,进一步解释了PCA对PGD - AT模型鲁棒性产生负面影响的原因。

图8:使用全连接深度线性门控网络(FC - DLGN)-宽度128 - 4层架构的PGD - AT(底行)和STD - TR(顶行)模型中,有效权重与顶级主成分的关系。
全连接的鲁棒模型和标准模型的活动子网络重叠情况-Active subnetwork overlap in fully connected robust vs standard models
这部分内容主要围绕全连接的鲁棒模型(PGD - AT训练)和标准模型(STD - TR训练),分析了它们的活动子网络重叠情况,具体内容如下:
- 研究动机和方法:为探究对抗训练模型如何利用模型容量来抵御攻击,引入神经路径核(NP - kernel)概念,通过计算NP - kernel衡量不同类样本间活动子网络的重叠程度。NP - kernel能捕捉不同类样本在特征网络路径上的活动差异,其值越大表示重叠越多,模型在区分不同类时越困难。
- 实验设置:在MNIST和Fashion MNIST数据集上,对具有四个全连接层(宽度128)的DLGN模型分别进行标准训练和PGD - AT训练( ϵ = 0.3 \epsilon = 0.3 ϵ=0.3, α = 0.1 \alpha = 0.1 α=0.1, T = 40 T = 40 T=40 ),并使用PGD攻击(40步, ϵ = 0.3 \epsilon = 0.3 ϵ=0.3)。通过计算不同类样本间的NP - kernel,比较鲁棒模型和标准模型在正常数据和对抗样本下的活动子网络重叠情况。
- 实验结果
- 正常数据情况:在MNIST和Fashion MNIST数据集上,PGD - AT模型在不同类之间的NP - kernel值比STD - TR模型低,表明PGD - AT模型在正常数据下能生成更多样化的活动子网络,不同类之间的重叠较少,有助于更好地区分不同类样本。
- 对抗样本情况:对于对抗样本,STD - TR模型的NP - kernel值显著增加,意味着不同类的活动子网络出现重叠,这可能导致模型对不同类的区分能力下降,进而降低模型的鲁棒性。而PGD - AT模型在对抗样本下,NP - kernel值的增加幅度较小,仍能保持相对较低的重叠水平,说明其活动子网络在面对攻击时更具稳定性,能够有效防止不同类样本的活动子网络因攻击而发生重叠,从而维持模型的鲁棒性。
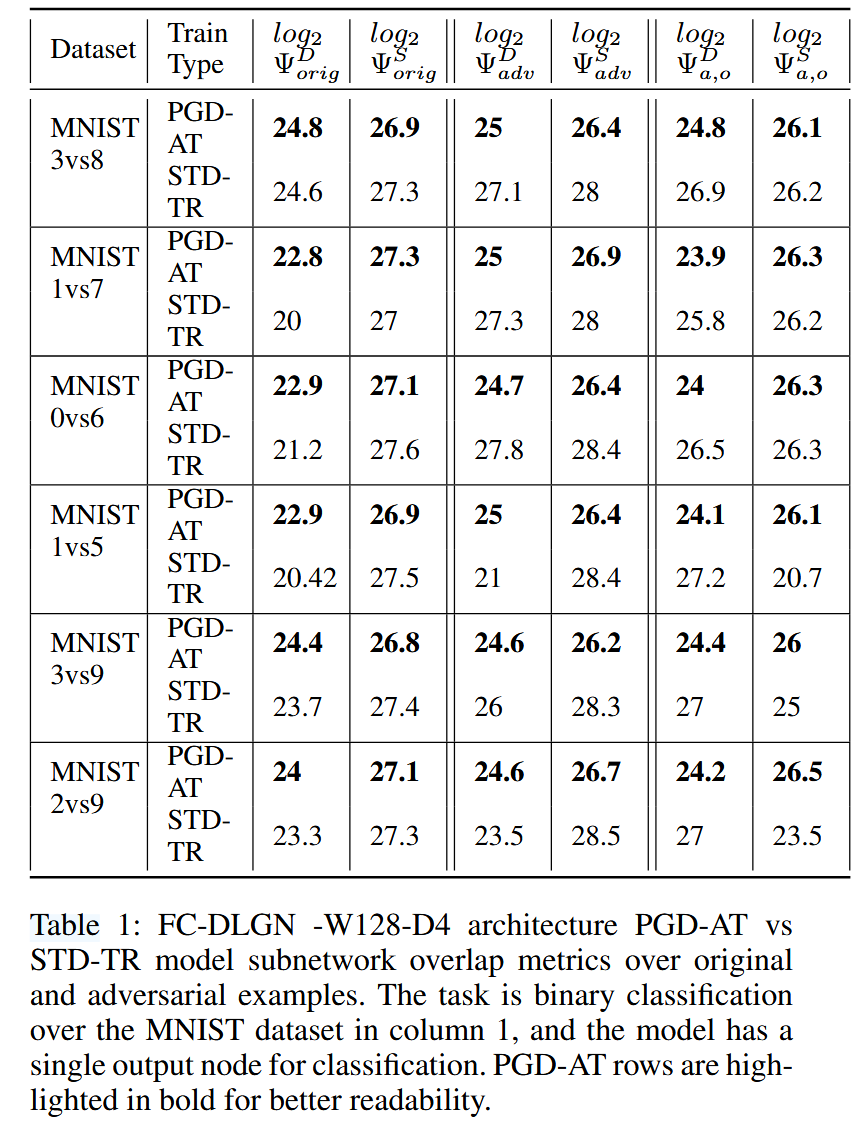
表1:全连接深度线性门控网络(FC - DLGN)-宽度128 - 4层架构的PGD - AT模型与STD - TR模型在原始样本和对抗样本上的子网络重叠度量指标。第1列中的任务是对MNIST数据集进行二分类,并且该模型有一个用于分类的单一输出节点。为了便于阅读,PGD - AT的行以粗体突出显示。
卷积架构中鲁棒模型与标准模型门控模式的分析与解释-Analysis and interpretation of gating patterns in robust vs standard models in convolutional architectures
该部分围绕卷积架构中鲁棒模型(PGD - AT训练)和标准模型(STD - TR训练)的门控模式展开分析与解读,涵盖门控模式分析及解读两方面,具体内容如下:
- 鲁棒模型和标准模型的门控模式分析
- 研究目的与方法:为理解对抗训练如何影响卷积架构下模型的门控模式,采用交并比(IOU)量化不同类别间活动门的重叠程度,还通过可视化技术呈现模型对干净样本和对抗样本的门控响应。
- 实验设置:在MNIST数据集上训练含4个卷积层(每层128个滤波器)的CONV DLGN模型,分别用STD - TR和PGD - AT((\epsilon = 0.3),(\alpha = 0.1),(T = 40) )训练。用PGD攻击(40步,(\epsilon = 0.3))生成对抗样本,计算不同类别对间活动门数量的IOU并进行门控模式可视化。
- 实验结果:干净样本上,PGD - AT模型的IOU值低于STD - TR模型,表明其不同类别活动门重叠少,门控模式更特异。对抗样本上,STD - TR模型IOU值显著增加,门控模式趋同,类别区分度降低;PGD - AT模型IOU值增幅小,门控模式对攻击鲁棒,能防门控模式因攻击与其他类重叠。
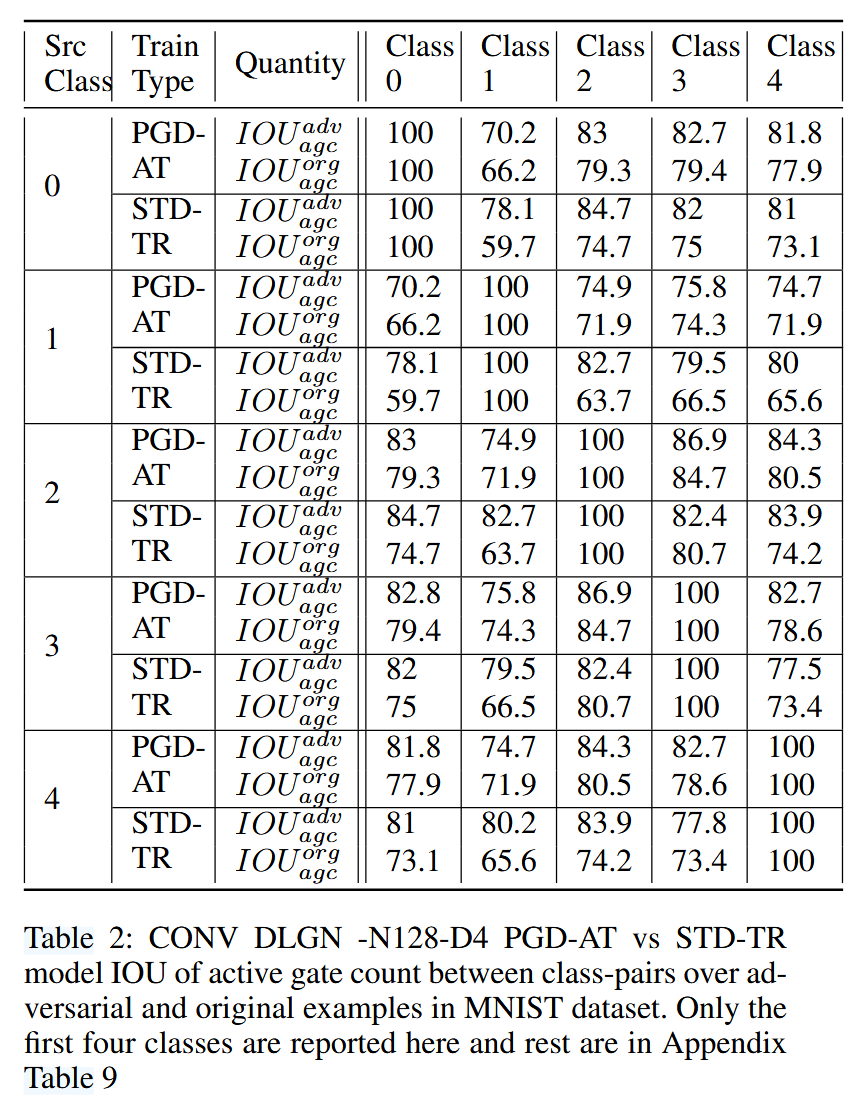
表2:卷积深度线性门控网络(CONV DLGN)- 含128个单元、4层结构,经投影梯度下降对抗训练(PGD-AT)的模型与标准训练(STD-TR)模型,在MNIST数据集中的对抗样本和原始样本上,类别对之间活动门数量的交并比(IOU)。此处仅报告前四类的情况,其余内容见附录表9。
- 鲁棒模型与标准模型门控模式的解读
- 可视化结果解读:可视化显示,PGD - AT模型对干净样本和对抗样本,能更好捕捉类特征,受攻击时也能一定程度保持类信息独特性。例如,在面对对抗样本时,仍能维持相对稳定的门控模式来区分不同类别。
- 对比STD - TR模型:STD - TR模型门控模式在对抗攻击下变化显著,难以维持类信息稳定性,对不同类别的区分能力下降。如在攻击后,其不同类别间的门控模式变得相似,无法有效区分各类样本。

表3:图像I,其在卷积深度线性门控网络(CONV DLGN)- 单元数为128、层数为4的模型上,触发了每类的主导门控模式。这些模式分别是从对抗样本中得到的(第3、5列)、从原始样本中得到的(第2、4列)、仅从对抗样本中得到而未从原始样本中得到的(第6、8列),以及既从原始样本又从对抗样本中得到的(第7、9列)。可视化损失函数按照公式(6)设置, λ = 0.9 \lambda = 0.9 λ=0.9, α = 0.1 \alpha = 0.1 α=0.1,优化过程按照公式(7)进行。为简洁起见,我们仅报告了几个类别。详细结果见附录中的表10和表11。
结论-Conclusion
这部分内容主要对全文进行了总结,并提出了未来的研究方向,具体如下:
- 结论总结
- 模型架构与可解释性:深度线性门控网络(DLGN)架构使特征网络完全线性化,为分析模型提供了清晰框架,增强了模型可解释性。通过DLGN能深入研究对抗训练(如PGD - AT)和标准训练(STD - TR)模型的差异,在全连接和卷积架构中都能有效分析模型内部属性。
- 超平面与模型鲁棒性:在全连接模型中,研究发现超平面与数据点距离大对增强模型鲁棒性至关重要。PGD - AT模型的超平面使数据点离超平面更远,且在不同类别之间创建了多样化、不重叠的活动子网络,能有效防止攻击引起的门控重叠,提升了模型的鲁棒性;而STD - TR模型在这些方面表现较差,在对抗样本下活动子网络易重叠,导致鲁棒性降低。
- 主成分分析(PCA)与模型关系:PCA旨在最小化点到超平面的距离,与对抗训练增加该距离以提高鲁棒性的目标相悖。实验表明,在模型中嵌入PCA会显著降低PGD - AT模型的对抗鲁棒性,且STD - TR模型中主成分与超平面的对齐度高于PGD - AT模型。
- 卷积架构下的门控模式:在卷积架构中,PGD - AT模型在不同类别之间的活动门重叠较少,对攻击具有更好的鲁棒性,能够有效捕捉类特征并在攻击下保持类信息的独特性;而STD - TR模型在对抗样本下活动门重叠增加,门控模式变化显著,难以维持类信息的稳定性。
- 未来研究方向
- 探索不同架构的影响:未来可研究DLGN在其他网络架构(如循环神经网络、Transformer架构等)中的应用,分析这些架构下对抗训练和标准训练模型的差异,进一步拓展对模型鲁棒性的理解。
- 优化对抗训练方法:基于对模型内部机制的理解,探索更有效的对抗训练方法,以提高模型的鲁棒性和泛化能力。例如,尝试改进训练过程中的超参数设置,或者设计新的对抗训练策略,使模型能够更好地抵御各种类型的攻击。
- 研究模型压缩与鲁棒性的关系:研究模型压缩技术(如剪枝、量化等)对模型鲁棒性的影响,探索如何在压缩模型的同时保持或提高其鲁棒性,实现模型效率和鲁棒性的平衡。
- 结合其他技术提升鲁棒性:考虑将DLGN与其他技术(如生成对抗网络、强化学习等)相结合,探索新的方法来提升模型的鲁棒性,应对更复杂的对抗攻击场景。


















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











