







目录
1.XGBoost介绍
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升(Gradient Boosting)的机器学习算法,由陈天奇于2016年提出。它在结构化数据建模(如分类、回归、排序)中表现优异,广泛应用于数据科学竞赛(如Kaggle)和工业界。
1.1模型原理
(1)梯度提升(Gradient Boosting)
核心思想:通过迭代训练多个弱模型(决策树),每一步纠正前一步的残差(预测误差)。
数学表达:
其中是第
棵树的预测,目标是最小化损失函数
(如均方误差、交叉熵)
(2)目标函数优化
XGBoost的目标函数包括两部分:
- 第一项:损失函数(如交叉熵、MSE)
- 第二项:正则化项(防止过拟合)
(3)决策树的分裂策略
- 遍历所有特征和分裂点,选择增益(Gain)最大的分裂方式
1.2模型参数
| 参数 | 说明 | |
|---|---|---|
| 主要 | learning_rate | 学习率 |
| n_estimators | 树的数量(迭代次数) | |
| max_depth | 树的最大深度(控制过拟合) | |
| min_child_weight | 子节点最小样本权重和(防止过拟合) | |
| subsample | 每棵树使用的样本比例(随机森林思想) | |
| colsample_bytree | 每棵树使用的特征比例 | |
| 次要 | gamma | 分裂所需的最小损失下降(值越大,模型越保守) |
| reg_alpha | L1正则化系数(类似Lasso) | |
| reg_lambda | L2正则化系数(类似Ridge) |
2.灰狼优化算法(GWO)介绍
灰狼优化算法(GWO)是一种受自然界灰狼群体狩猎行为启发的群体智能优化算法,由 Mirjalili 等人于 2014 年 提出。它模拟了灰狼的社会等级制度和协作捕猎机制,被广泛应用于函数优化、机器学习调参、工程优化等领域。
2.1算法数学原理
(1)社会等级编码
解空间中的候选解可以分为四类:
:当前最优解
:第二优解
:第三优解
:其余候选解
(2)包围猎物(全局探索)
灰狼的位置实时更新公式:
其中:
:当前灰狼与猎物(最优解)之间的相对距离
:猎物位置(当前最优解,比如
狼位置)
:当前灰狼个体的位置向量(其余候选解)
、
:系统向量,控制探索与开发
:从2线性递减到0
、
:[0,1]内的随机向量
(3)狩猎行为(局部开发)
由、
、
共同引导位置更新:
(4)攻击猎物(收敛)
-
攻击的本质:灰狼在猎物附近小范围移动(局部开发),由
和
共同控制。
是一个从 2 线性递减到 0 的标量,控制算法的全局探索与局部开发:
初始阶段:
大概率
-
即使
,此时
,但其他狼的随机性仍维持探索。
后期阶段:
,灰狼开始靠近猎物(攻击)。
会直接使
,触发精确局部优化。
起到决定性作用:
-
a 控制算法阶段:
-
a≥1:强制全局探索(无论
如何随机)。
-
a<1:允许局部开发(需 ∣
配合)。
-
-
随机性
的调节作用:
-
在 a<1 时,
-
3.GWO优化XGBoost超参数代码的实现
3.1完整代码实现
此处是对乳腺癌数据集做回归:首先构建XGBoost模型,再利用GWO算法以该模型的-RMSE的最大值为优化目标进行超参数寻优,得到最优参数和最优目标值。
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
from xgboost import XGBClassifier
from mealpy.swarm_based import GWO
from mealpy.utils.problem import Problem
from mealpy.utils.space import IntegerVar, FloatVar
# 加载数据(此处是直接用了乳腺癌数据集,可以换成其他的模型数据训练)
data = load_breast_cancer()
X, y = data.data, data.target
# 定义目标函数(优化准确率)
def objective_function(solution):
params = {
'max_depth': int(solution[0]), # 整数
'learning_rate': max(float(solution[1]), 1e-3), # 最小1e-3防止过小
'n_estimators': int(round(solution[2])), # 四舍五入取整
'min_child_weight': float(solution[3]),
'subsample': float(solution[4]), # 0~1之间
'colsample_bytree': float(solution[5]), # 0~1之间
'gamma': float(solution[6]),
'reg_alpha': float(solution[7]), # L1正则
'reg_lambda': float(solution[8]), # L2正则
'random_state': 42,
'eval_metric': 'logloss'
}
# 训练模型并交叉验证
model = XGBClassifier(**params)
#cross_val_score得到的模型分数默认是越大越好,因此此处取得是RMSE的负数为评价目标
score = cross_val_score(model, X, y, cv=5, scoring='neg_root_mean_squared_error').mean()
return score # 最大化问题
# 定义参数范围(可以自由选择)
bounds = [
IntegerVar(lb=3, ub=10, name="max_depth"), # 深度范围3~10
FloatVar(lb=1e-3, ub=0.3, name="learning_rate"), # 学习率0.001~0.3
IntegerVar(lb=50, ub=500, name="n_estimators"), # 树数量50~500
FloatVar(lb=1, ub=10, name="min_child_weight"), # 子节点最小权重
FloatVar(lb=0.5, ub=1, name="subsample"), # 样本采样比例
FloatVar(lb=0.5, ub=1, name="colsample_bytree"), # 特征采样比例
FloatVar(lb=0, ub=0.5, name="gamma"), # 节点分裂最小损失下降
FloatVar(lb=0, ub=1, name="reg_alpha"), # L1正则系数
FloatVar(lb=0, ub=1, name="reg_lambda") # L2正则系数
]
# 构造优化问题
problem = Problem(
bounds=bounds, #超参数取值范围
minmax="max", #最大化目标(可选参数max和min)
obj_func=objective_function, #目标函数(此处为模型交叉验证之后的RMSE的负数)
name="XGBoost_Optimization" #优化器名字
)
# 运行优化
model = GWO.OriginalGWO(
epoch=10, #迭代次数
pop_size=15 #狼群数量
# log_to="console" # 打印日志
)
agent = model.solve(problem)
best_params = agent.solution #最优参数
best_score = agent.target.objectives #目标函数值
# 输出结果
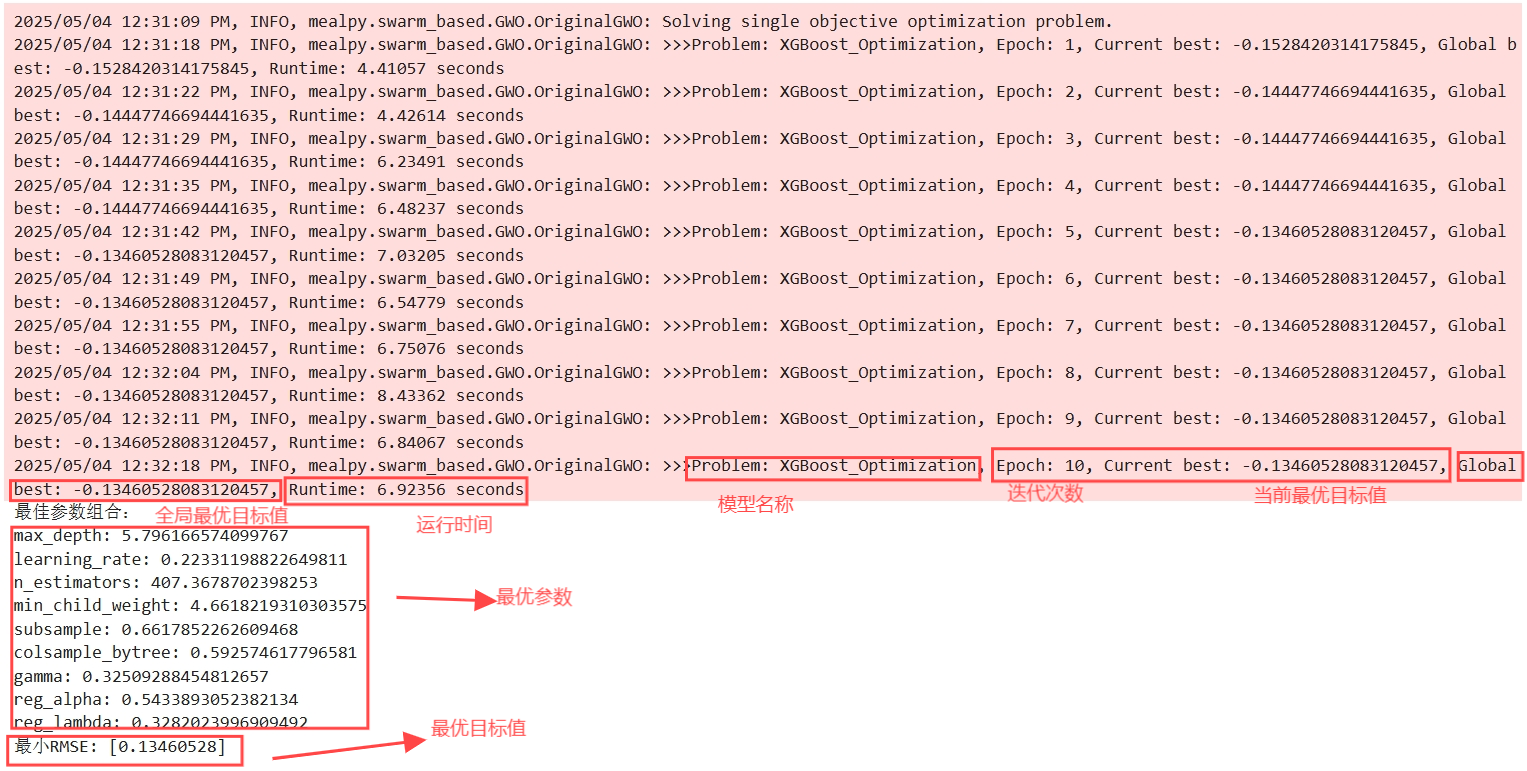
print("最佳参数组合:")
for i, param in enumerate(best_params):
print(f"{bounds[i].name}: {param}")
print(f"最小RMSE: {-best_score}") #由于交叉验证的函数值为RMSE评价指标的负数,因此-best_score才是RMSE3.2输出结果展示
该模型实际应用到的相关文献:
Zicheng Xin, Jiangshan Zhang, Kaixiang Peng, Junguo Zhang, Chunhui Zhang, Jun Wu, Bo Zhang, and Qing Liu, Explainable machine learning model for predicting molten steel temperature in the LF refining process, Int. J. Miner. Metall. Mater., 31(2024), No. 12, pp.2657-2669. https://dx.doi.org/10.1007/s12613-024-2950-4

















 1358
1358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









