






本篇主要是对论文:Attention is all you need 中的transformer模型作出解释。
自注意力机制(self-attention)
为什么要引入self-attention?
RNN中一个比较明显的缺陷是获得小梯度更新的层会停止学习,而那些层通常是比较早的层。这就导致RNN只具有短时记忆,难以记住长序列中较前的内容。
而LSTM虽然在一定程度上解决了这个问题,但是需要依次序序列计算,对于远距离相互依赖的特征,要经过若干步骤才能将两者联系起来,这就比较麻烦了。
Self-Attention则在计算中直接将任意两个单词的联系进行计算,就避免了如上的问题。一个明显的特征是self-attention在计算中采用并行计算,而不是循环计算。

self-attention的实现
先放一张总体的图,然后再进行具体的解释。

self-attention的输入为一个向量矩阵(a1,a2,…,an), α \alpha α用来表示两个向量的相关程度, α \alpha α’表示 α \alpha α经过softmax层后的结果,q、k、v分别表示query、key、value,也是三个向量矩阵,Wq,Wq,Wv则表示三个权重矩阵(这通常是随机设置,然后经过训练获得的矩阵),b向量则是经过self-attention后的输出了。
来看看q,k,v是怎么得到的。以q1为例,将权重矩阵Wq与a1进行点积(dot product)即得到q1。q向量的所有值即将权重矩阵与对应的输入进行相乘。k,v向量也是同理。用公式表示就是
接下来略为麻烦的相关系数 α \alpha α的计算。 α \alpha αmn表示向量am与an之间的相关系数,以 α \alpha α12为例,将q1与k2相乘得到 α \alpha α12。其他相关系数同理,用公式表示就是
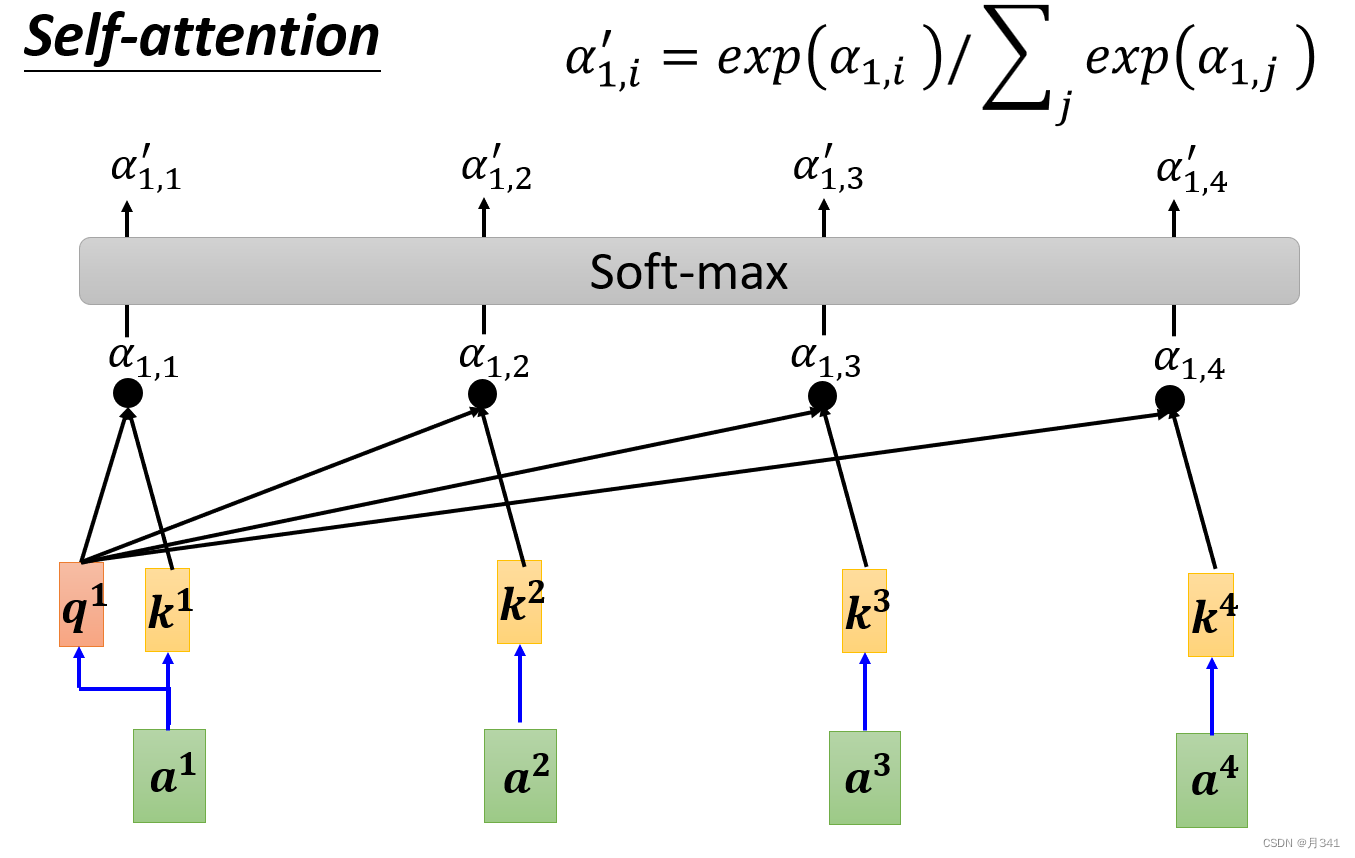
最后是输出层的计算,这里也是实现所有向量互相联系的关键。将得到的 α \alpha α’矩阵与对应的v向量相乘,得到输出的一个值,最终结果是这些相乘的求和。这一步的图示在开头已经给出。用公式表示就是
需要注意的是,每个输出矩阵b都是平行进行计算的,这也就具备了一定的并行性。
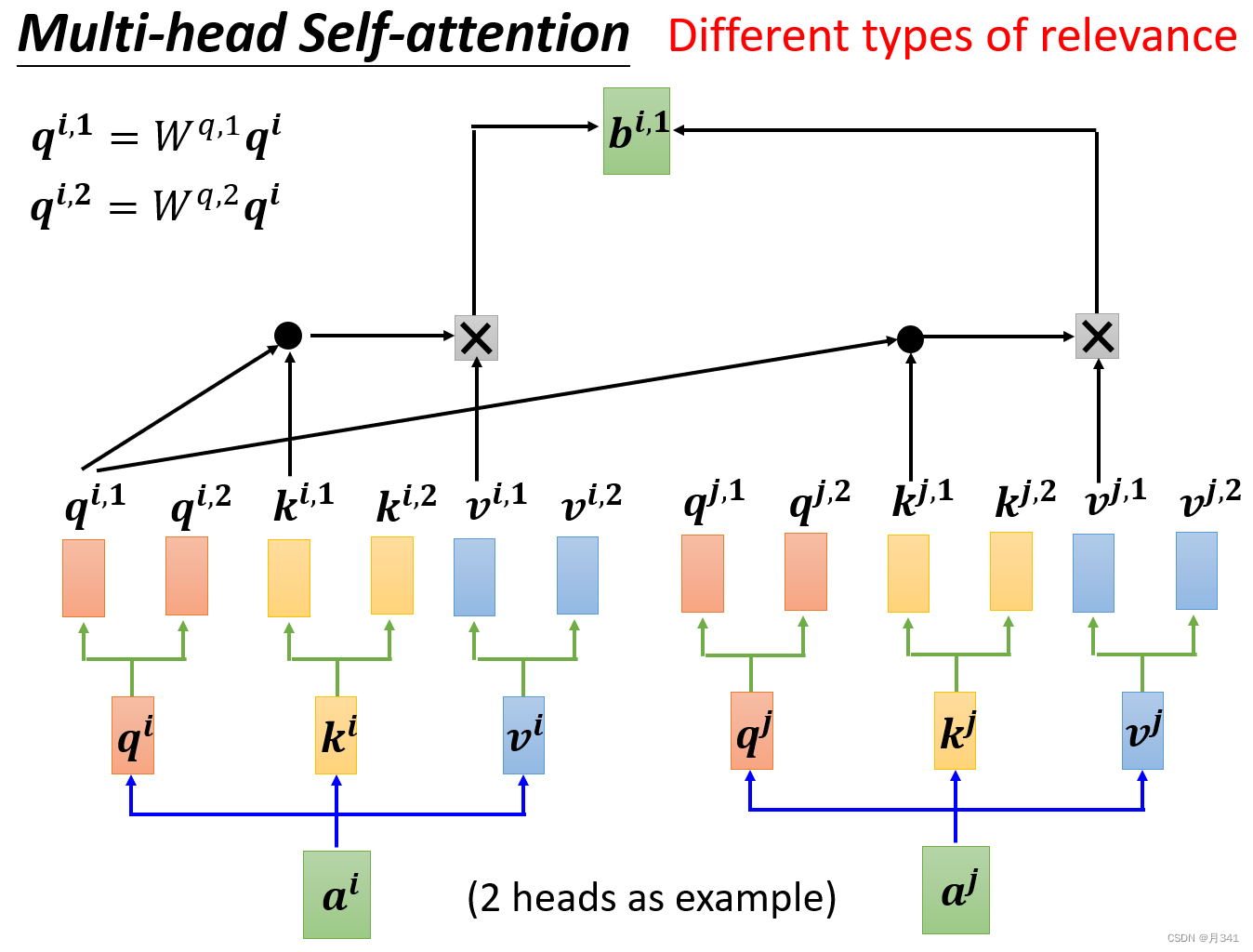
Multi-head Self-attention的实现
为什么我们需要Multi-head呢?我们在计算相关系数的时候,使用q和k在进行计算,但是相关这件事有很多种不同的形式和定义。所以可能我们需要不同类的q和不同类的k来对不同的形式的相关进行计算。
图像的分维度计算,其实也可以一定程度上看作是这种情形。
以2 head为例,这里的每一个q,k,v会乘上两个不同的权重矩阵而分成两个不同的矩阵,负责不同形式相关的情况。
由于不同的相关形式,产生的输出b也应该有两个。以其中一个为例,计算方式与self-attention相同。需要注意的是,在q,k相乘的时候要用各自相关对应的矩阵。图示如下。
Masked Multi-head Self-attention的实现
相比于不加Masked的多头注意力机制,其实就是在计算的时候不计算后方的数据。实际上也意味着输出数据是一个一个产生的。
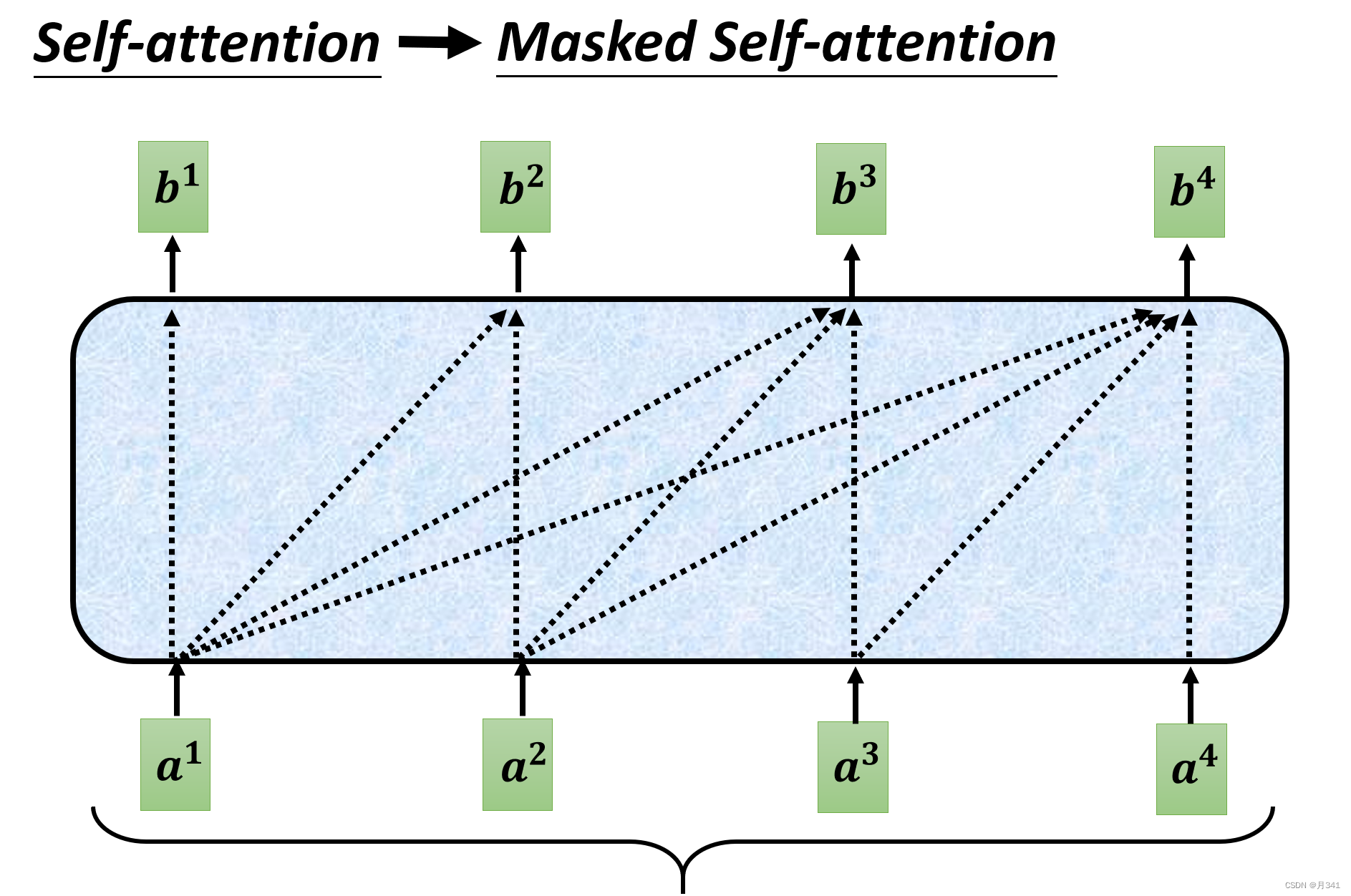
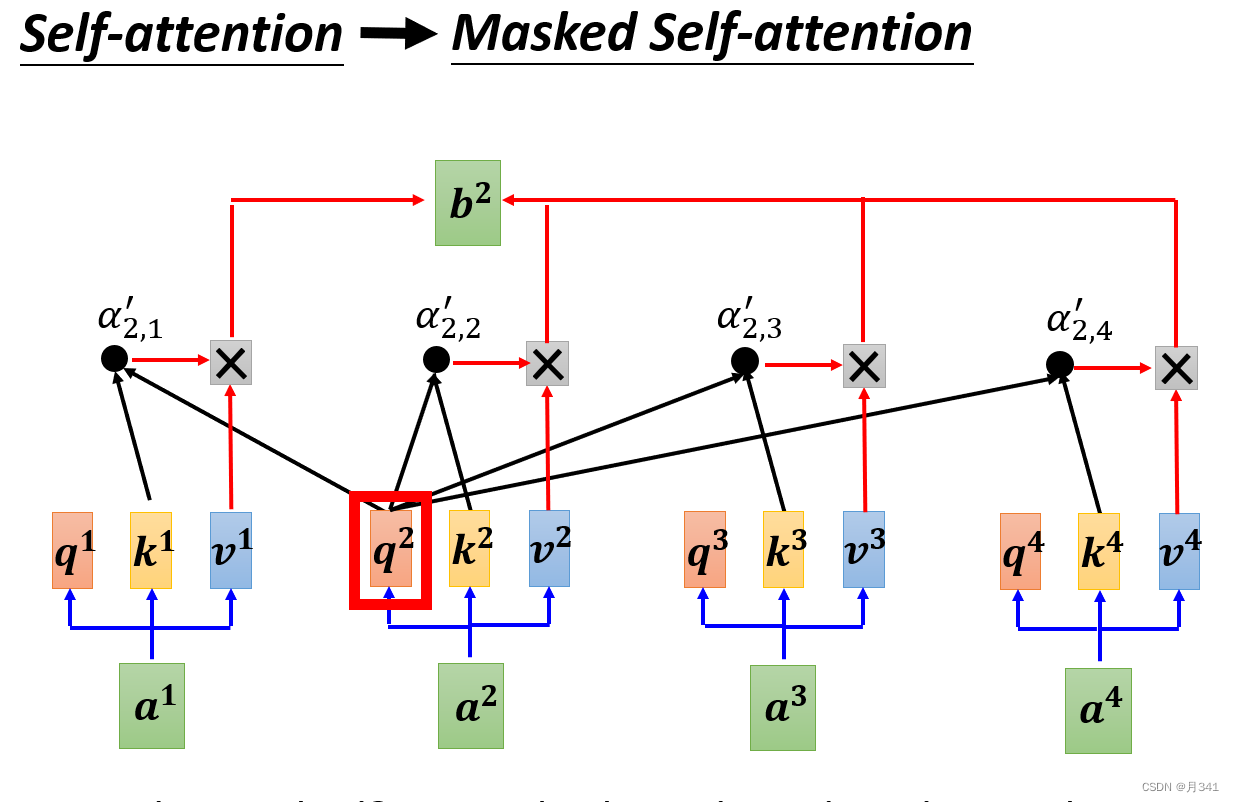
即在计算输出矩阵bi时,只取下标小于i的 α \alpha α’与对应的v相乘的总和。详情可见下图。
Positional Encoding
参考自知乎【一文教你彻底理解Transformer中Positional Encoding】
为什么需要Positional Encoding?
自然语言中,一个句子里词语的位置和顺序对句子的意思表达是有影响的。
对于Transformer采用的self-attention来说,它不像RNN那样在处理的时候会保存词语的顺序信息。由于所有词向量都是同时进入网络进行处理,所以丢失了原本的顺序信息。
Positional Encoding就是为了解决这样一件事。
Positional Encoding的实现
一种有效的编码如以下公式所示:
p ⃗ \vec{p} p t (2k+1) = f(t) (2k+1) = cos \cos cos( ω \omega ω kt)
其中 ω \omega ω k = ( 1 10000 \frac{1}{10000} 100001) 2k/d
t表示当前词语在句子中的位置, p ⃗ \vec{p} p t表示该词语对应的位置编码。
从公式可以看出,其实一个词语的位置编码是由不同频率的余弦函数函数组成的,从低位到高位,余弦函数对应的频率由 1 降低到了 1 10000 \frac{1}{10000} 100001,按照论文中的说法,也就是,波长从2 π \pi π增加到了1000*2 π \pi π。
这样能得到Positional Encoding的向量表示pt,在进行运算时,我们只需要把它和对应位置的输入词向量相加即可。pt+at后再进行self-attention的计算。
位置前馈网络(Position-wise Feed-Forward Networks)
位置前馈网络就是一个全连接前馈网络,每个位置的词都单独经过这个完全相同的前馈神经网络。其由两个线性变换组成,即两个全连接层组成,第一个全连接层的激活函数为 ReLU 激活函数。可以表示为:
在每个编码器和解码器中,虽然这个全连接前馈网络结构相同,但是不共享参数。
Transformer
Transformer的结构
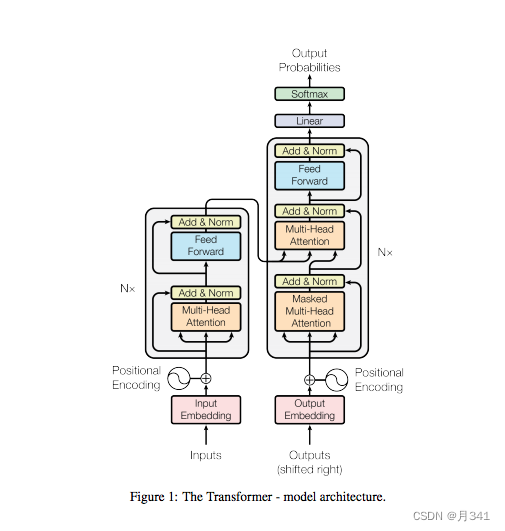
Transformer其实采用的是Seq2Seq的encoder-decoder的结构。上图中左边的部分即是encoder部分,右边的部分是decoder部分。
为什么Decoder要用到Masked?
相对比encoder和decoder部分,只有decoder部分用了Masked Multi-head Self-attention,为什么要使用它呢?我的理解是这样的。
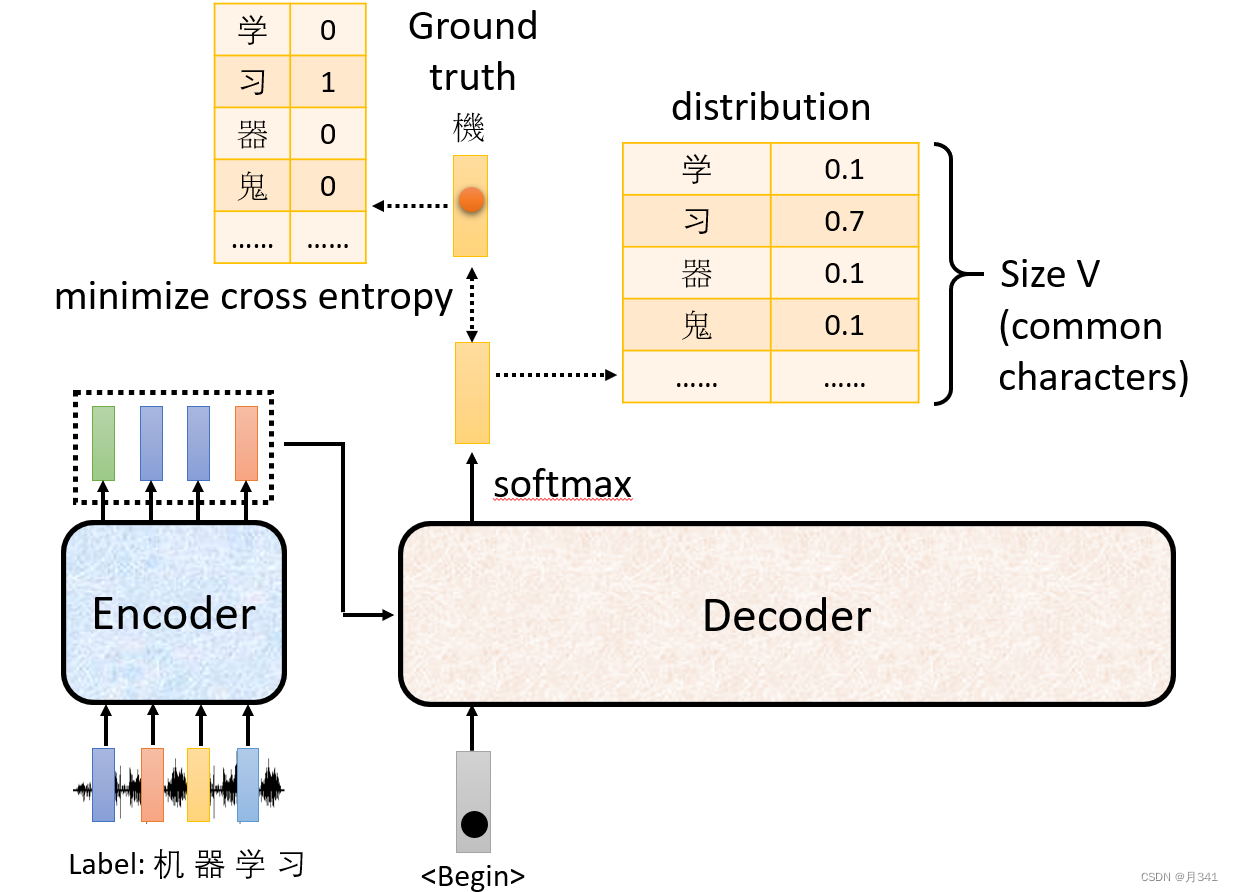
encoder由于输入词向量是已知的,可以并行进行计算。
decoder的计算不同于encoder,输出数据是一个一个产生的。
如上图,数据经过encoder层后进入decoder层,在decoder层中给出开始信号后产生一个结果。在训练的时候,我们会对这个结果与标准结果比对,做交叉熵损失,以此来更新参数,不断缩小这个损失函数。
在训练的时候,我们可以直接告知机器decoder后方的数据,这样提高了训练效率。
但是当测试的时候,是机器进行数据的预测,只能一个一个对数据进行预测。需要得出前面的数据,再根据已有数据对接下来的结果进行预测。这样就意味着,decoder必须使用Masked Multi-head Self-attention。
但是很疑惑的是,如果我根据第一个数据预测出了第二个数据是错误的,那岂不是会根据第二个数据进行第三个数据的预测吗?这不就错上加错了吗?
事实上,一定程度上是这样的。有相应的解决方法,其中一个解决方法就是在训练的时候就刻意加入会出错的数据,据说这样训练后的模型会比不加得到更好的准确率。















 8071
8071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









