






1.引言:
首先我们要明白,这个问题其实根源在于机器学习中的iid原则:训练所使用的数据应该是独立同分布的。分布不分布的我们不管,关键就在于这个独立性,我们不遵循这个独立性要求会出现什么问题呢?
2.梯度方向一致:
数据短期内强相关会导致计算出来的梯度实际上方向是大体一致的。
梯度:如图f(x)的梯度该如何求,其实我们熟知的梯度是对未知量求,但这里其实更像是f(ω)x是系数。如图可以求出其梯度是一个向量。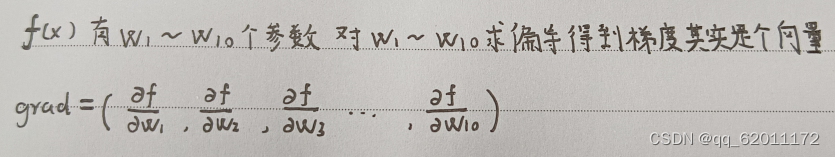 梯度方向:其实就是表示一个向量方向的方法,是一个绝对值为1的方向向量
梯度方向:其实就是表示一个向量方向的方法,是一个绝对值为1的方向向量
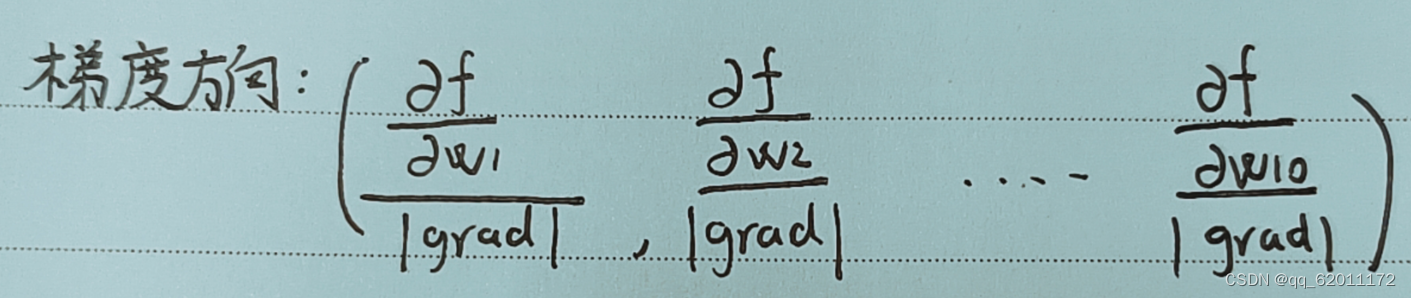 我们说梯度方向一致,指的就是两个梯度的方向向量相等。
我们说梯度方向一致,指的就是两个梯度的方向向量相等。
为什么会梯度方向一致:
我们假设Q值函数为f(x)如下,S状态向量长度为10,S = (x1,x2...x10),a动作向量长度为2,a=(x1,x2)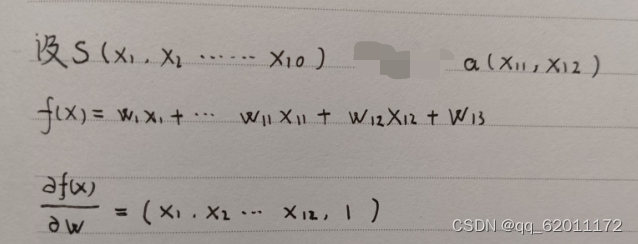
计算其梯度方向向量:

我们设想另一个梯度方向向量如何定义它们的方向一致呢?
我们规定一个方向差:用于衡量两个梯度方向是否大致一致如下:
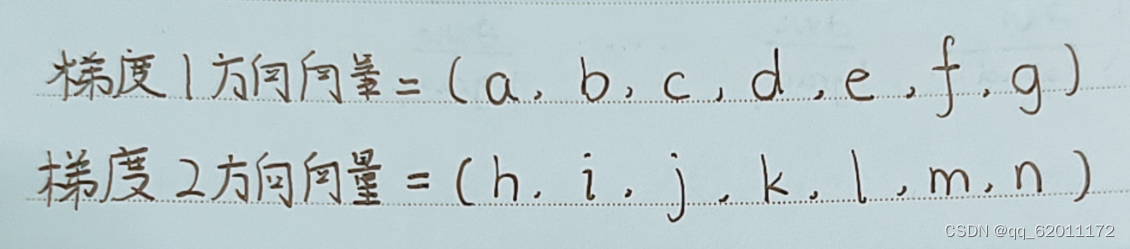
假如其中对应位置的元素如a与h大小差距超过某个值m,存在这种现象的位置不超过n个或某个比例,我们认为这两个梯度方向大致一致。
在我们举的例子中,很明显的是在紧挨着的两个经验中的两个状态之间,x1~x10是极为相同的,换句话说代入到梯度方向向量中使用我们定义的方向差可以判定二者方向应该是大致一致的。
推广而言:

这与上面我们举出的简单例子不同,梯度向量与参数也有一定关系。
总之时间顺序相关性强的两条经验(因为其s,ω差距极小)其计算的梯度方向大概率是大致一致的(其实这个得靠实验去证实,你所构造的神经网络,你所处理的环境,如果使用时间顺序相关性强的经验会不会呈现这种情况)。下面我们介绍假如出现这种情况带来的后果。
梯度方向一致带来的后果:震荡
借我们上个小段提出的方向差,我们完全可以围绕我们计算出来的实际梯度为中心以方向差为阈值,取出一个梯度集合出来,我们认为这个梯度集合内我们任选一条梯度对参数进行更新,其更新方向应该是大致一致的。何为更新方向:我们定义其为更新值的比例,如下虽然每个参数更新的值大小不一,但各更新值的比例应该是大致一致的。
利用第一个梯度进行更新,ω1更新值 η*grad 为3,ω2更新值η*grad 为6。
利用第二个梯度进行更新,ω1更新值 η*grad 为2,ω2更新值η*grad 为4。
3:6 = 2:4 = 1:2
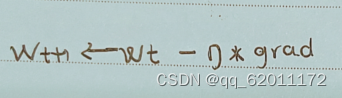
对应我们取出的梯度集合应该后面有一类数据,这一类数据计算出来的梯度属于这个梯度集合,换句话说,只要是使用这个梯度集合内的梯度进行更新,这一类数据的预测值都会更为准确。
我们要求我们的模型应该具备泛化能力,对应而言,就是训练使用的一个梯度其所代表的一类数据的预测值也可以得到矫正,并且我们使用的梯度应该保证其覆盖范围足够大。
训练所使用的梯度我们应该尽量保证同属于一个梯度集合的梯度数量保持某一个平衡,既能够保证某一类数据的预测值得到充分矫正,也要防止其训练太多次出现过拟合,其它数据的预测值得不到矫正。
但是如果使用时间顺序相关性极强的经验进行训练就会出现这样一种后果:训练所使用的梯度同属于一个梯度集合的太多,覆盖范围太少,泛化能力极度下降,过拟合。
什么是震荡:训练中出现平均回合奖励忽高忽低的情况,并且差距超级大。
一个episode,其实也代表着一条时间顺序相关性极强的动作状态序列,其有可能出现在先前训练中覆盖的那条序列中,有可能不出现,出现了奖励高,没出现奖励低















 2023
2023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









