







在分享代价敏感错误率和代价曲线之前我们举个例子,方便小伙伴们理解~
假如说我现在有一个自动贩卖水果的机器,机器里面有100个西瓜和橘子,在用一个训练集(西瓜和橘子)训练完机器学习模型后,我现在用模型去识别这100个西瓜和橘子(重新挑选的,并非来自原数据集),如果识别出来是西瓜,机器就当作西瓜卖给买家,识别出来是橘子,那我就当作橘子买给买家,我们看下图:
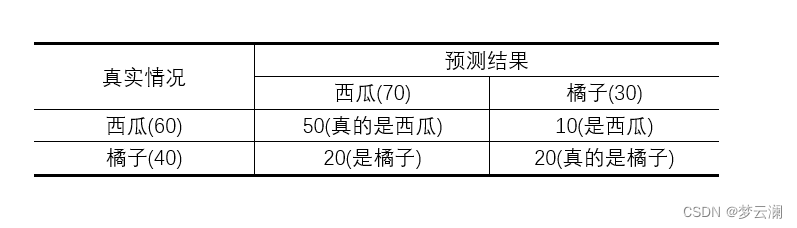
你看,我们这里面识别出来70个西瓜里面有20个橘子,我们把它当作西瓜卖了,这样可能是我们赚了,但是有名誉损失,但是在卖的橘子里面有10个是当西瓜卖了,那我们就赔了。你看,虽然都是识别错误的,但是付出的代价是不太一样的,我们今天讨论的就是这两个识别错误付出的代价展开的。(例子不一定恰当,只是便于理解)
我们把这个代价抽象出来,如下表:
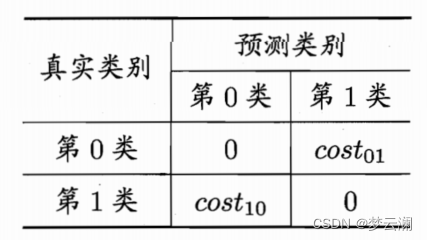
这是个二分类代价矩阵,这里我们只关注预测错误的代价,所以表里面只对假正例和假反例赋有权重(也就是代价),这里肯定有小伙伴们忘记矩阵里面的四个位置都代表啥了叭~我们回顾一下,看下表:
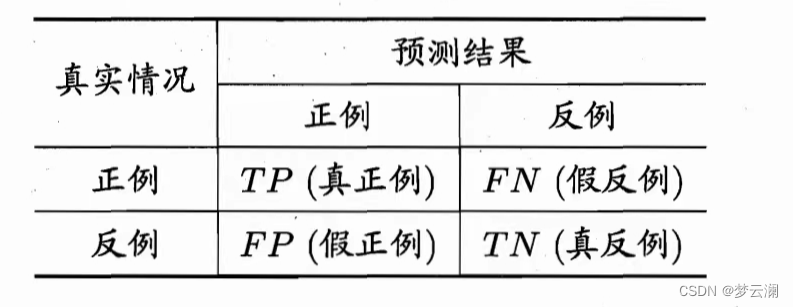
就是这张表里面的FN和FP的位置,然后计算(假反例率),
(假正例率)哦~理解了叭~
然后我们介绍一下代价敏感错误率公式:
乍一看,这公式好长呀,别慌别慌,咱一个一个解释字母的含义:
:机器学习的识别规则,相当于数学上的一个函数
:数据个数
:正例集合
:负例集合
:相当于一个布尔函数,括号内的条件成立则输出1,不符合则输出0
:计算机识别的结果和真实的不一样呗
这样是不是就清晰了啦,括号里面其实计算的就是识别错误的结果,然后再相应的乘上一个权重(代价),最后再除以数据个数就是代价敏感错误率嘞~
再来说说代价曲线,既然说曲线,那肯定要介绍一下代价曲线的横轴,纵轴都代表什么,先来说横轴,横轴为正例概率代价:
啊?这是什么?怎么又这么长?别慌,咱解释解释,其实你细看一下里面就一个p你不知道,这个p的意思是样例(数据集)中正例的比例(概率),其他的上述都介绍过啦,分母其实就是归一化用的,使得这个结果在0到1上变化,因为理论上来讲,代价可以取任何非负值,归一化后不管代价取什么值都可以在0到1上分析,这里面一直变化的量其实是p哦,代价是提前定好的。
再看纵轴,纵轴代表的是归一化代价
哈哈哈,这个公式依然很长,但是依旧别慌,分母依然是做归一化处理,分子就是乘了个假真例率和假反例率,整体就是一个期望,一个随着p变化的期望,我们换个形式展现这个公式,如下表:

我们看这个表,求一下期望大家都会叭~,你看求完期望再做一下归一化是不是就是纵轴的含义呀。
说了这么多,看一下曲线的庐山真面目叭~

我们这里面是画了多个曲线(就是图里面的直线),啊?怎么会这么多曲线?这个是在不同阈值下,归一化代价(期望)随正例概率代价变化的图像,每一条曲线下方与x轴围成的面积就是在这个阈值下归一化代价的总期望。我们这个图是想干什么的呢?其实就是图中的那块儿叫期望总体代价也叫最小期望代价,也就是说,我们通过这个最小期望代价,找出最优阈值,因为每一条曲线都有一个阈值,在图中,期望总体代价的边界曲线对应的就是最优阈值,这个其实也不难理解,我们这里求的是识别或者叫预测错误的期望,我们当然想把这个期望降到最低,通过这个图我们就可以找到阈值,使得代价期望最小。
ok,这篇就分享到这里啦~欢迎小伙伴们批评指正~(图片知识来源于西瓜书)
















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











