






1.第一部分 Mamba的提出背景与结构原理
1.1 研究背景和摘要:
翻译过来的意思是:基础模型目前为深度学习中大多数令人兴奋的应用提供动力,它们几乎都基于Transformer 架构及其核心注意力模块。许多亚二次方程时间架构,如线性注意、门控卷积和递归模型,以及结构化状态空间模型(SSM)、门控卷积和递归模型,以及结构化状态空间模型(SSM)等许多亚四元时间架构都是为了解决变压器在长序列上的计算效率低下问题,但它们在语言等重要模态上的表现不如注意力好。但它们在语言等重要模态上的表现并不尽如人意。我们发现,这些模型的一个关键弱点是无法进行基于内容的推理,并做出了几项改进。首先,只需让 SSM 参数成为输入的函数,就能解决它们在离散模态下的弱点。首先,只需让 SSM 参数成为输入的函数,就能解决它们在离散模态方面的弱点,使模型能根据当前标记的长度维度,有选择地传播或遗忘信息。序列长度维度传播或遗忘信息。其次,尽管这种变化妨碍了使用高效的卷积,我们还是设计了一种硬件感知的并行递归模式算法。我们将这些选择性 SSM 集成到一个简化的端到端神经网络中。我们将这些选择性 SSM 集成到一个简化的端到端神经网络架构中,该架构无需关注,甚至无需 MLP 块(Mamba)。Mamba推理速度快(吞吐量比 Transformers 高 5 倍),序列长度呈线性扩展,其性能在百万长度的真实数据上得到了提高。在真实数据上的性能提高了一百万长度的序列。作为通用序列模型的骨干,Mamba 在语言、音频和基因组学等多种模式中实现了最先进的性能。在语言建模方面,我们的 Mamba-3B 模型在语言建模方面,我们的 Mamba-3B 模型在预训练和下游评估中均优于同等规模的 Transformers,并可与两倍于其规模的 Transformers 相媲美。
1.2 回顾Transformer
既然摘要中明确的和Transformer做出了对比,那么这里我们不妨先回顾一下Transformer,作为CV领域的“大红人”,为图像处理质量的提升做出了非常大贡献,经典原文:Attention Is All You Need 原文链接:1706.03762 (arxiv.org)
Transformer是一种深度学习模型架构,它在自然语言处理(NLP)和其他序列建模任务中取得了革命性的成功。Transformer模型的几个关键特点:
-
自注意力机制(Self-Attention):Transformer模型的核心是自注意力机制,它允许模型在处理序列的每个元素时,考虑序列中所有位置的信息。这种机制使得模型能够捕捉到序列内部的长距离依赖关系。
-
并行化处理:由于自注意力机制不依赖于序列中元素的顺序,Transformer可以并行处理整个序列,这与传统的循环神经网络(RNN)形成对比,后者需要按顺序逐步处理序列。
-
可扩展性:Transformer模型的设计允许它很容易地扩展到更大的模型尺寸和更长的序列长度,这使得它能够处理复杂的任务和大量的数据。
-
编码器-解码器架构:在典型的Transformer模型中,包含编码器(Encoder)和解码器(Decoder)两个部分。编码器处理输入序列,而解码器生成输出序列。两者之间通过注意力机制进行交互。
-
位置编码:Transformer模型通过添加位置编码来使模型能够理解序列中单词的顺序。位置编码通常是与时间步长的正弦和余弦函数相关的固定向量。
-
多头注意力:Transformer模型使用多头注意力机制,它允许模型同时从不同的角度和抽象层次捕捉序列的信息。
-
层归一化和残差连接:Transformer模型在每个子层中使用层归一化(Layer Normalization)来稳定训练过程,并通过残差连接(Residual Connections)来帮助梯度流动,从而缓解深度网络中的梯度消失问题。
-
预训练和微调:Transformer模型通常在大量数据上进行预训练,学习通用的语言表示,然后可以在特定任务上进行微调,以提高任务性能。
Transformer的结构:
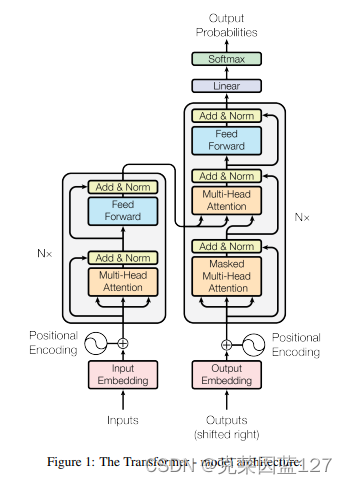

1.3 状态空间模型SSMs(State Space Models,简称SSMs)
继续回归主题:好好好,重点“可与Transformer相媲美”,看来功能确实强大,那我们来看看这个mamba具体结构是怎么样的:
首先提到Mamba,就必须要提及状态空间模型(State Space Models,简称SSMs)
SSMs是一种用于序列建模的深度学习架构。SSMs可以被视为循环神经网络(RNNs)和卷积神经网络(CNNs)的结合体,它们从经典的状态空间模型中获得灵感。SSMs能够有效地以线性或接近线性的复杂度处理序列数据,并且能够模拟某些数据模态中的长期依赖关系。
再来看一下SSMs的结构:
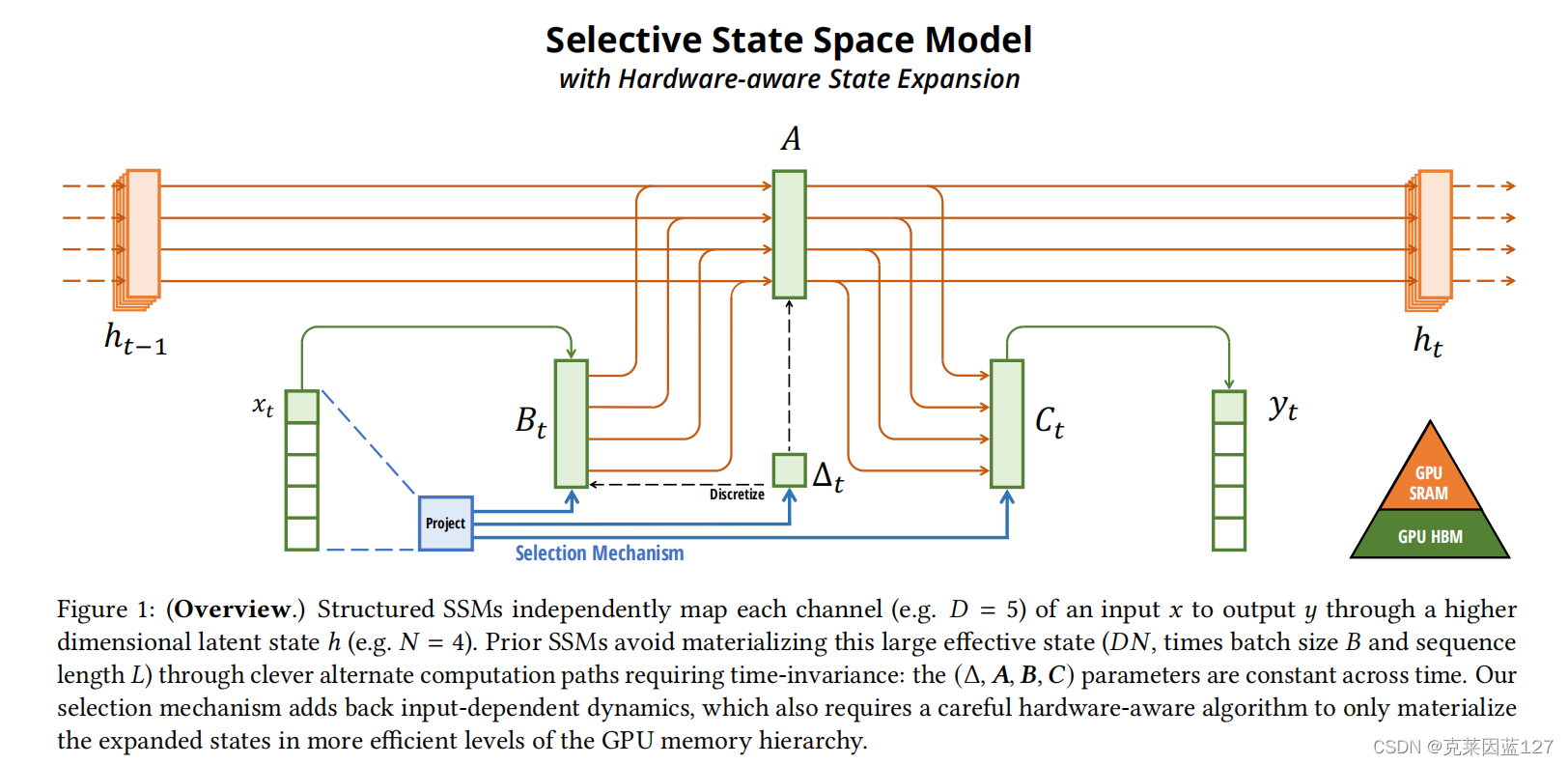
SSMs概述:结构化的ssm独立地映射输入𝑥的每个通道(例如𝐷= 5),通过更高维的潜在状态ℎ(例如𝑁= 4)输出𝑦。先前的ssm通过需要时不变性的聪明的替代计算路径避免实现这种大的有效状态(𝐷𝑁,乘以批大小𝐵和序列长度𝐿):(Δ,𝑨,𝑩,𝑪)参数在时间上是恒定的。我们的选择机制添加了依赖于输入的动态,这也需要一个仔细的硬件感知算法,只在GPU内存层次的更有效的级别上实现扩展状态。
1.4 Mamba结构
我们再来看Mamba的结构:
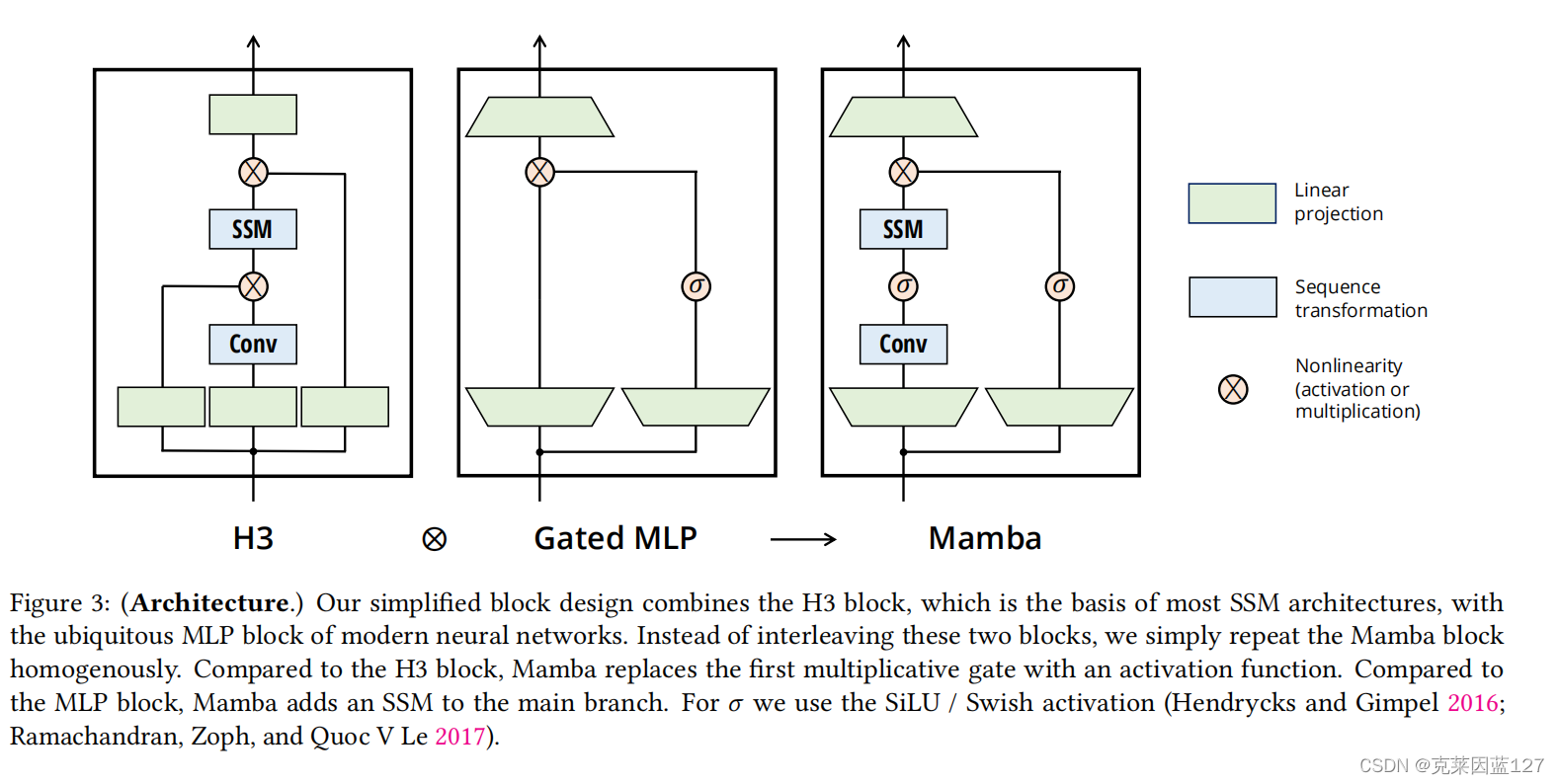
mamba体系结构概述:我们的简化块设计结合了大多数SSM架构的基础H3块和现代神经网络中无处不在的MLP块。我们没有交错这两个块,而是简单地均匀地重复曼巴块。与H3块相比,Mamba用一个激活函数取代了第一个乘法门。与MLP块相比,Mamba在主分支中添加了一个SSM。对于𝜎,我们使用SiLU / Swish激活(亨德里克斯和Gimpel 2016;拉曼钱德兰,Zoph,和Quoc V Le 2017)。
总结一下SSMs和Mamba的关系:
Mamba是论文中提出的一种新型的SSM,它通过引入选择机制来改进传统的SSMs。
1.5 Mamba与其他注意力机制模型性能对比
接下来又是重点,Mamba与主流的注意力机制模型进行各方面的对比,可以说是具有很大优势:
1.精度对比
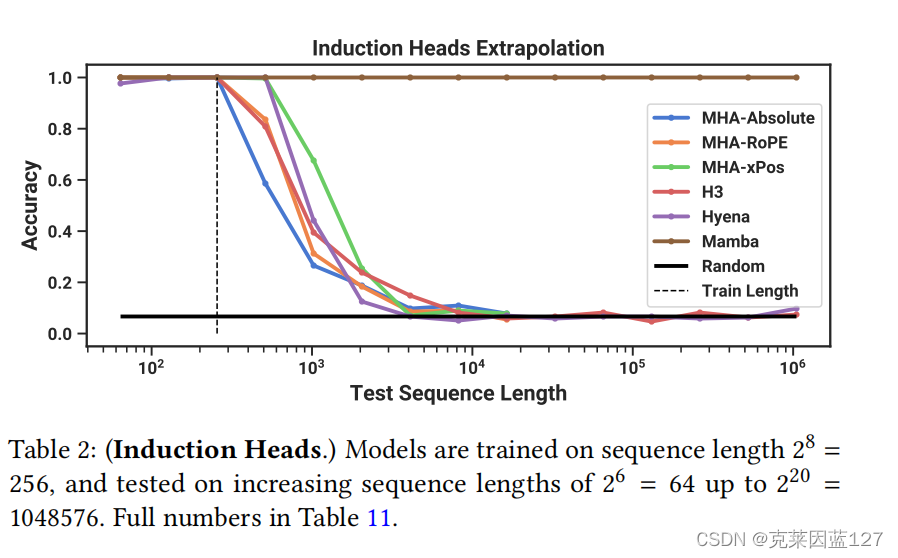

结果表2显示,Mamba——或者更准确地说,它的选择性SSM层——能够完美地解决任务,因为它能够选择性地记住相关的令牌,而忽略介于两者之间的其他一切。它完美地概括到百万长度的序列,或比它在训练中看到的长4000×,而没有其他方法超过2×。
2.参数运算量对比

图4:(比例定律)大小为≈125𝑀到≈1.3𝐵参数的模型,在桩上训练。Mamba比所有其他无注意力模型都更好,是第一个匹配非常强大的“变压器++”配方的性能,该配方现在已经成为标准,特别是随着序列长度的增长。
3.效率对比
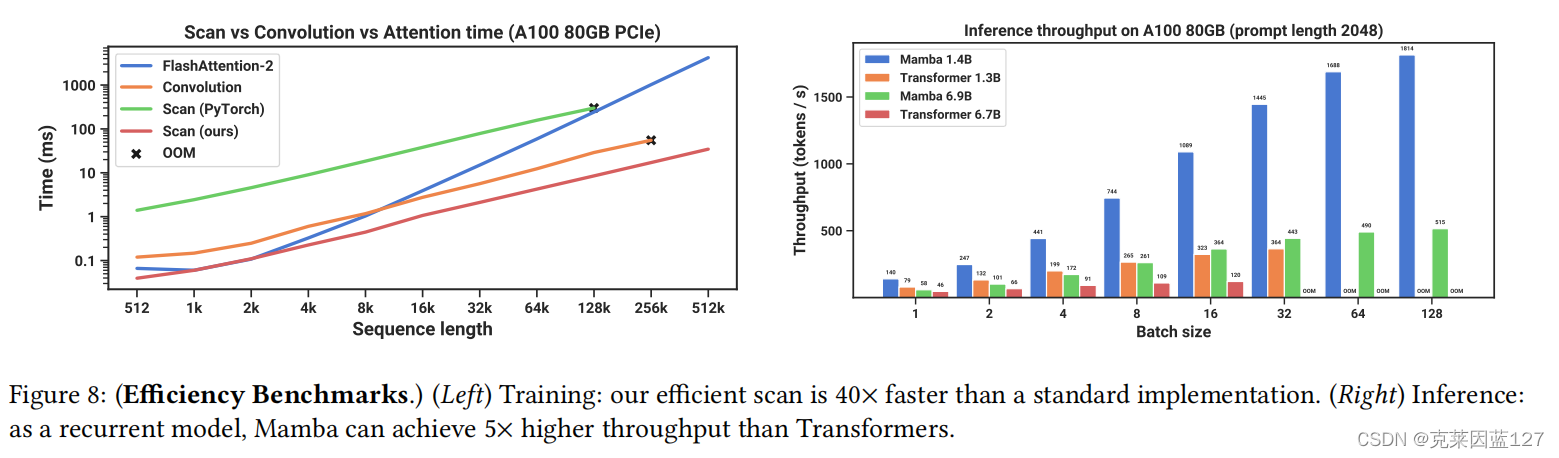
图8:(效率基准测试。)(左)训练:我们的高效扫描比标准实现快40×。(右)推断:作为一个循环模型,Mamba可以实现比变压器高5×的吞吐量。
更多的对比结果大家可以阅读原文,可以说是非常精彩。
2.第二部分 Mamba与Transformer的对比
总结到这里,我把这篇文章中提出的Mamba与Transformer进行了一个归纳对比,讨论一下Transformer与Mamba有什么相同之处和不同之处:
相同之处:
- 序列建模能力:两者都旨在对序列数据进行建模,能够捕捉序列中的依赖关系。
- 注意力机制:Transformer模型的核心是自注意力机制,它允许模型在序列的不同位置间建立联系。Mamba虽然不是直接基于注意力机制,但它通过选择性状态空间模型(Selective State Space Models)实现了类似的功能。
- 并行化能力:Transformer和Mamba都能够在一定程度上实现并行化计算,这对于处理长序列数据尤为重要。
不同之处:
-
架构:Transformer是基于自注意力和位置编码的架构,而Mamba是基于状态空间模型(SSMs),特别是选择性状态空间模型(Selective SSMs)。
-
计算复杂度:Transformer在序列长度上具有二次方的计算复杂度,因为它需要计算所有输入位置对的注意力分数。相比之下,Mamba通过SSMs实现线性时间复杂度的序列建模。
-
状态空间处理:Mamba通过选择性机制能够更有效地处理状态空间,允许模型在每个时间步选择性地关注或忽略输入,而Transformer则在每个时间步对所有输入进行处理。
-
效率:Mamba的设计目标之一是提高效率,特别是在长序列上。它通过硬件感知的算法优化了计算过程,而Transformer可能在长序列上面临效率挑战。
-
模型参数:Transformer模型通常需要大量的参数来捕捉序列的复杂性,而Mamba通过结构化的状态空间模型减少了模型参数的数量。
-
训练和推理速度:Mamba通过SSD(State Space Duality)框架和硬件高效的算法,提供了比Transformer更快的训练和推理速度。
-
系统优化:Mamba-2架构特别设计了以适应系统优化,如张量并行性和序列并行性,这有助于在大规模训练和推理中提高效率。
-
应用范围:虽然Transformer在多种NLP任务中表现出色,但Mamba的设计使其在需要处理长序列和高效率的场景下更具优势。
总结来说,Transformer和Mamba在序列建模的目标上是相似的,但它们在实现方式、计算效率、模型架构和系统优化方面有显著的不同。Mamba的设计考虑了Transformer的一些局限性,并尝试通过结构化状态空间模型来解决这些问题。
3.第三部分 Mamba-2的提出与原理
同样的两位作者,在此基础上又进行了一项经典研究工作,即:发表在机器学习顶会24年ICML上的 题目:Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality 论文链接:2405.21060 (arxiv.org)
3.1 摘要信息
首先来看摘要:
虽然Transformer是深度学习在语言建模方面成功背后的主要架构,但像Mamba这样的状态空间模型(ssm)最近被证明在中小型上与变形金刚匹配或优于Transformer。我们证明了这些模型家族实际上是非常密切相关的,并发展了ssm和注意变量之间丰富的理论联系框架,通过一个研究良好的结构半可矩阵的各种分解连接起来。我们的状态空间二象性(SSD)框架允许我们设计一个新的架构(Mamba-2),其核心层是对Mamba的选择性SSM的改进,速度快2-8×,同时继续在语言建模上与Transformer竞争。
3.2 关键文章内容总结
从摘要上我们已经能清晰了解这篇文章的重点工作,整个论文内容也可归为以下几个重要的点:
-
引言:
论文讨论了Transformer模型在处理序列数据时的效率问题,并介绍了SSMs作为解决这些问题的替代模型。SSMs在序列长度上具有线性扩展性,并且在生成过程中状态大小恒定。 -
理论框架:
论文提出了一个名为结构化状态空间对偶(Structured State Space Duality, SSD)的理论框架。该框架通过结构化矩阵的概念将SSMs与注意力机制的不同变体联系起来。 -
技术贡献:
展示了SSMs与结构化矩阵(特别是半可分矩阵)之间的等价性。改进了线性注意力理论,并引入了结构化掩码注意力(Structured Masked Attention, SMA)。证明了SSMs和SMA之间存在大量交集,并且它们互为对偶。 -
算法设计:
提出了一种新的SSD算法,该算法基于半可分矩阵的块分解,能够在不同的效率轴上(如训练和推理计算、内存使用等)获得最优的权衡。 -
架构设计:
论文介绍了Mamba-2架构,这是基于SSD框架的新架构,其核心层是对Mamba模型的选择性SSM的改进,速度提升了2-8倍。 -
系统优化:
SSD框架允许利用为Transformer开发的系统优化工作,如张量并行性(Tensor Parallelism)和序列并行性(Sequence Parallelism)。 -
实验验证:
论文在语言建模、训练效率和多查询关联记忆任务上验证了Mamba-2模型的性能。
3.3 Mamba-2结构
这里展示一下Mamba-2的模型结构:
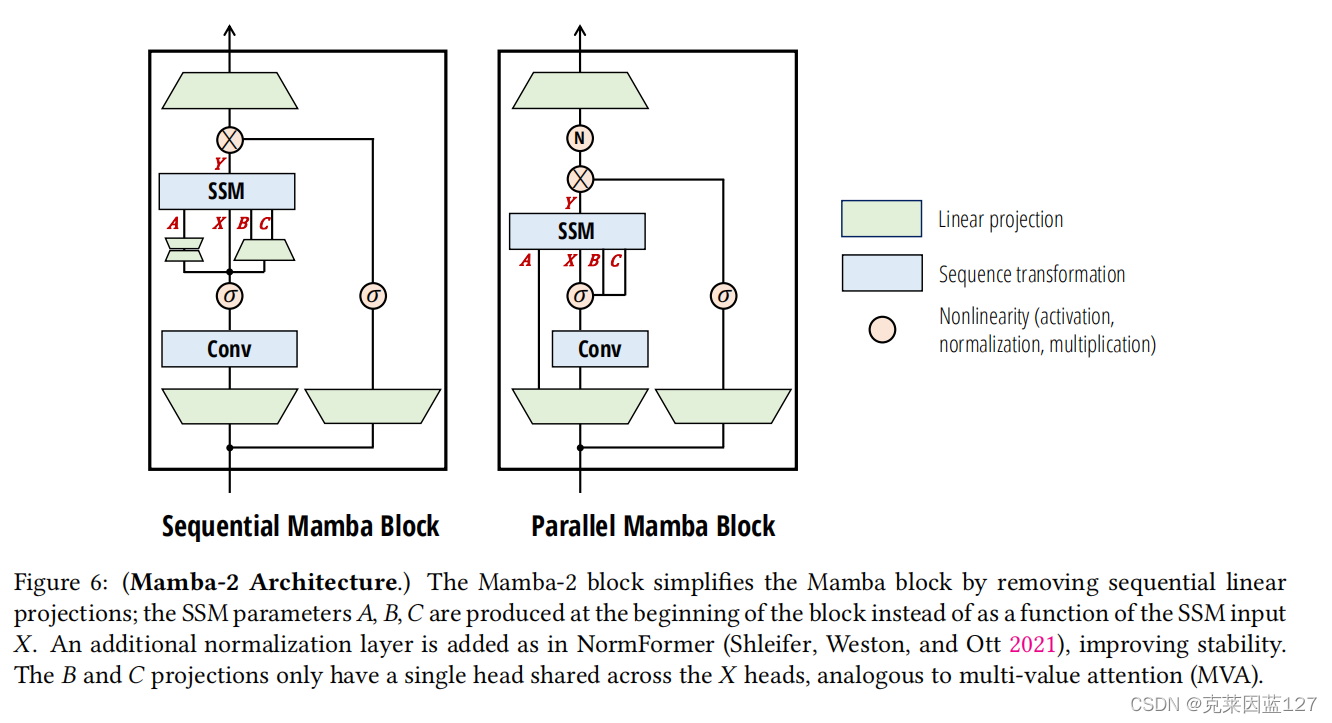
图6:(Mamba-2体系结构。)Mamba-2块通过删除顺序线性投影简化了Mamba块;SSM parameters𝐴,𝐵,𝐶是在块的开始处产生的,而不是作为SSM输入𝑋的函数。增加了一个额外的标准化层,如在标准化层(施莱弗,Weston,和Ott 2021),提高了稳定性。𝐵和𝐶投影只有一个头部共享在𝑋头部,类似于多值注意力(MVA)。
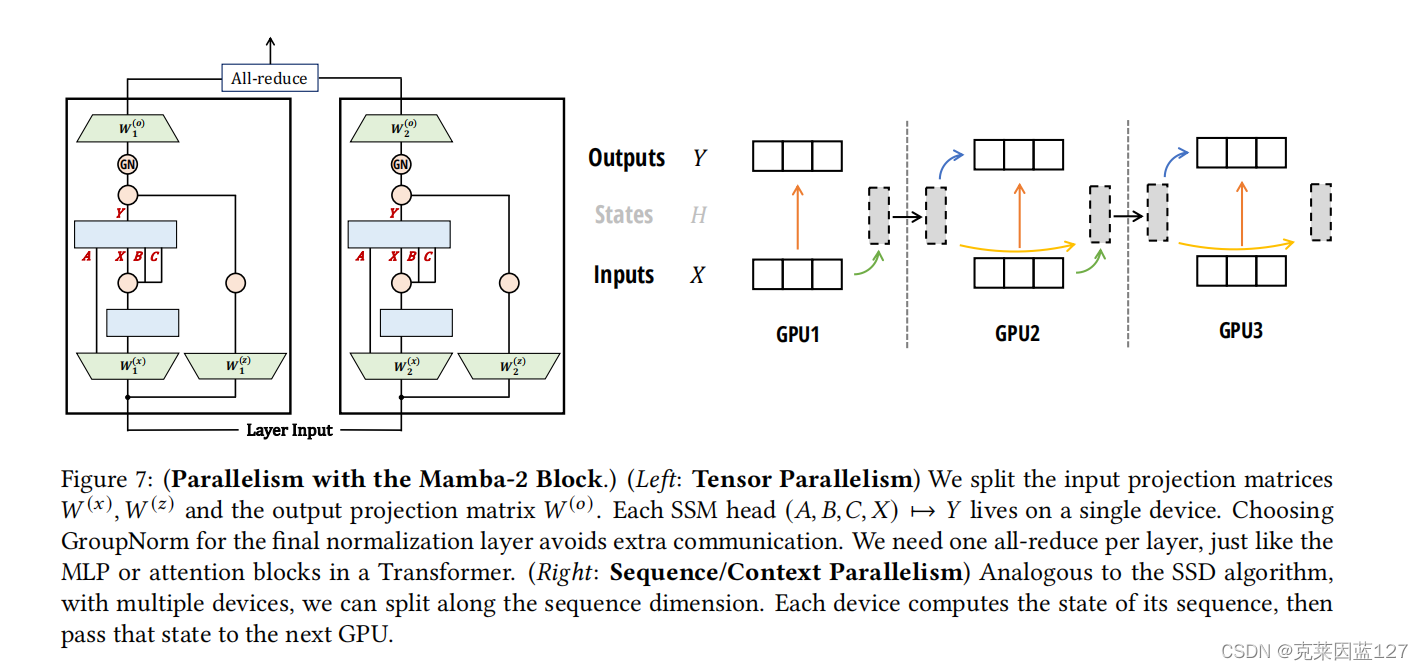
图7:(与Mamba-2块的并行性。)(左:张量平行度)我们将输入投影矩阵𝑊(𝑥)、𝑊(𝑧)和输出投影矩阵𝑊(𝑜)进行分割。每个SSM头(𝐴,𝐵,𝐶,𝑋)↦→𝑌都生活在一个设备上。为最终的规范化层选择组规范可以避免额外的通信。我们需要一个全减少每层,就像MLP或注意块在一个变压器。(右图:序列/上下文并行性)类似于SSD算法,如果有多个设备,我们可以沿着序列维度进行分割。每个设备计算其序列的状态,然后将该状态传递给下一个GPU。
另外,这篇论文的附录也提供了很多实验细节,推荐大家整篇原文阅读。
整体来看,这篇论文的核心贡献在于提出了一个将SSMs与Transformer模型联系起来的框架,并通过这个框架设计了新的算法和架构,以提高序列模型的效率和性能。
4. 第四部分 学习心得
从目前网上已发表或者预印版本上和mamaba相关的cv类文章的数量上看,mamba已经被广泛推广和应用到各种视觉处理方面了。曾经的Transformer也是非常火热,到目前来看,依然有很多图像处理在应用,而且很多轻量化的ViT也已经开源。每一种技术的兴起,都是对图像处理结果质量上的提升,当然,也是指标上的提升,这对于我们每个人而言,是一种机会,也是一种挑战,如果能利用好前人的经典工作,对我们自己本身也是提升。
另外,github上已经开源了mamba的代码GitHub - mamba-org/mamba: The Fast Cross-Platform Package Manager,目前已经有6.5k star,推荐大家学习并阅读原文。
以上总结内容如果有误,欢迎指出,共同学习。
希望能给屏幕前的你带来帮助,祝你前程似锦!

















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









