







RidgeCV是一个用于回归问题的模型,它继承自_BaseRidgeCV类和RegressorMixin类。它在实际应用中非常有用,因为它结合了岭回归(Ridge Regression)和交叉验证(Cross Validation)的特性,以提高模型的性能。
RidgeCV的优势和作用
RidgeCV的主要优势在于处理线性回归问题时的过拟合问题。过拟合可能会导致模型在新数据上的表现不佳。为了应对这个问题,RidgeCV使用了L2正则化(岭回归),通过限制模型参数的大小,降低模型复杂度,从而减少过拟合的可能性。
使用交叉验证选择最佳的正则化参数
与传统的岭回归不同,RidgeCV能够自动选择最佳的正则化参数,而不需要手动指定。这是通过交叉验证来实现的。它将数据集划分为多个子集,然后在不同的子集上进行训练和验证,最终选取表现最佳的正则化参数。
当观察正则化程度变化对结果的影响时,可以通过绘制不同正则化参数下模型的性能指标来进行可视化分析。在这个例子中,使用RidgeCV模型,并根据不同的正则化参数绘制模型的R-squared得分。
以下展示如何进行可视化分析:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import RidgeCV
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
# 生成示例数据
X, y = make_regression(n_samples=100, n_features=10, noise=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建不同的正则化参数
alphas = np.logspace(-6, 6, 13) # 从10的-6次方到10的6次方,共13个参数
# 初始化用于存储R-squared得分的列表
scores = []
# 在不同正则化参数下训练模型并计算得分
for alpha in alphas:
ridge_cv = RidgeCV(alphas=[alpha], cv=5)
ridge_cv.fit(X_train, y_train)
score = ridge_cv.score(X_test, y_test)
scores.append(score)
# 绘制正则化参数与R-squared得分的关系
plt.figure(figsize=(10, 6))
plt.semilogx(alphas, scores, marker='o')
plt.xlabel('Regularization Parameter (alpha)')
plt.ylabel('R-squared Score')
plt.title('Impact of Regularization on RidgeCV Performance')
plt.grid(True)
plt.show()
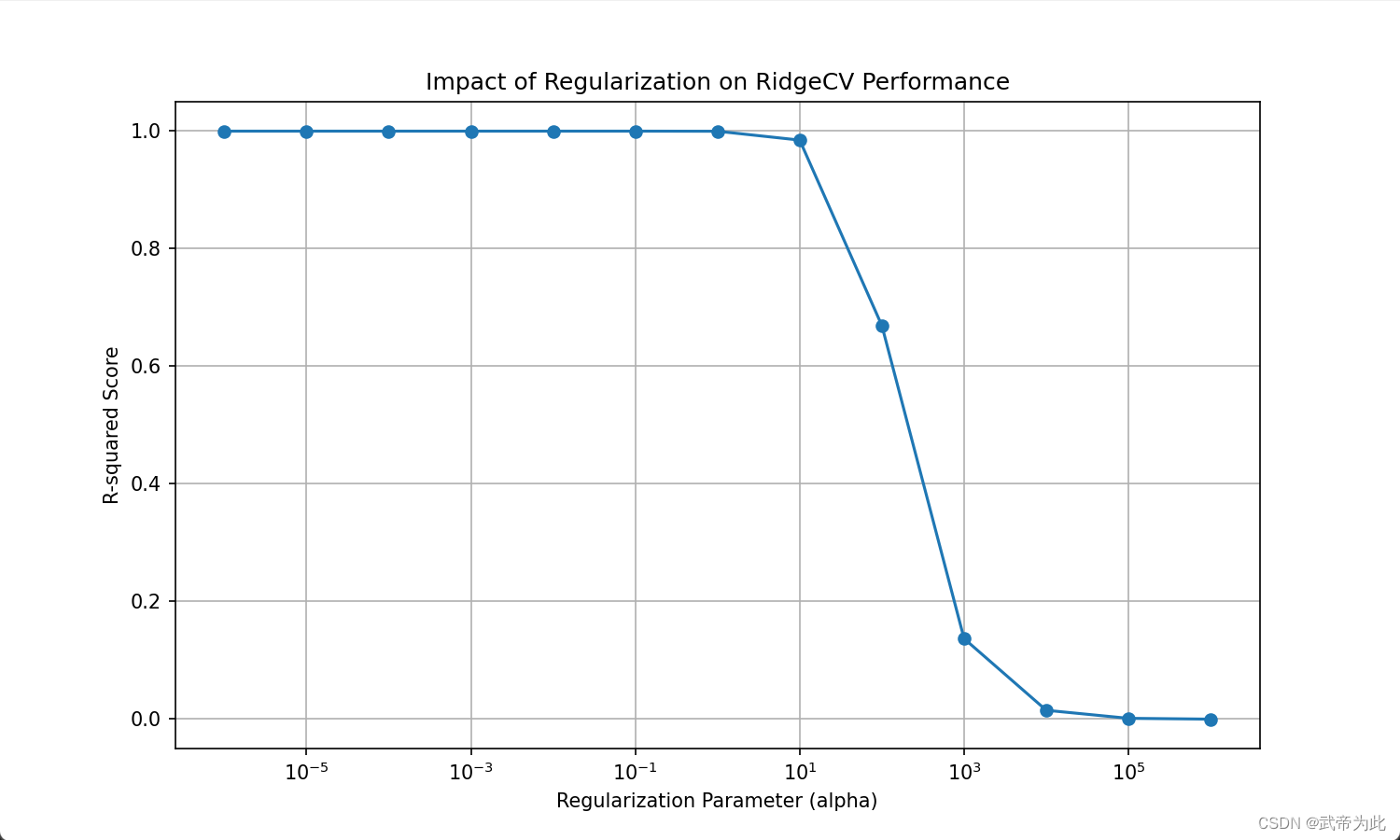

我们使用了不同的正则化参数(alpha)进行了训练,并绘制了正则化参数与模型R-squared得分的关系图。从图中可以看出,随着正则化参数的增加,模型的性能逐渐降低,这是因为较强的正则化限制了模型的复杂度,减少了过拟合的可能性。



















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











