






yolov11+luna16数据集
1.简单粗暴配环境(已经测试过,可以进行兼容)
1. 创建新的虚拟环境
使用 conda 创建一个新的虚拟环境,命名为 yolov11_env(你可以根据需要修改名称),并指定 Python 版本(推荐使用 Python 3.10):
conda create -n yolov11_env python=3.10
2. 激活虚拟环境
激活刚刚创建的环境:
conda activate yolov11_env
3. 安装 PyTorch
根据你的硬件(CPU 或 GPU)安装 PyTorch。以下是安装命令:
-
CPU 版本:
pip install torch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 --index-url https://download.pytorch.org/whl/cpu -
GPU 版本(CUDA 11.8):
pip install torch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 --index-url https://download.pytorch.org/whl/cu118 -
GPU 版本(CUDA 11.7):
pip install torch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 --index-url https://download.pytorch.org/whl/cu117 -
GPU 版本(CUDA 11.6):
pip install torch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 --index-url https://download.pytorch.org/whl/cu116
如果你不确定该安装哪个版本,可以参考 PyTorch 官方安装指南。
4. 安装 Ultralytics 和 YOLOv11 依赖
安装 ultralytics 库及其依赖:
pip install ultralytics
5. 安装其他必要库
安装一些常用的数据处理和可视化库:
pip install numpy pandas matplotlib opencv-python scipy
6. 验证安装
验证 PyTorch 和 Ultralytics 是否正确安装:
python -c "import torch; print(torch.__version__)"
python -c "import ultralytics; print(ultralytics.__version__)"
7. 运行 YOLOv11 训练
激活环境后,运行你的 YOLOv11 训练脚本:
python train.py --data your_dataset.yaml --weights yolov11s.pt --epochs 50 --batch 16
8. 清理旧环境(可选)
如果你不再需要旧的 yolov11 环境,可以将其删除:
conda remove -n yolov11 --all
2.对其luna16数据集的处理
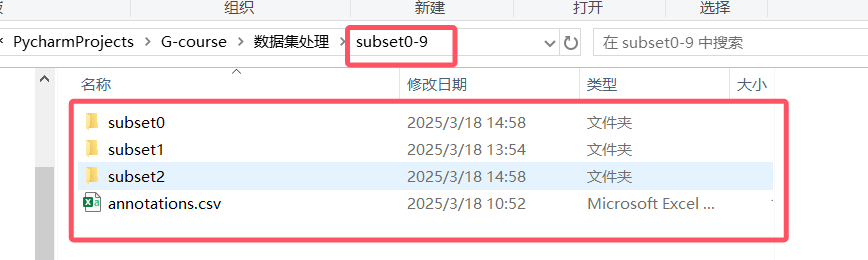
1.在官网上进行下载好数据集,下载annotations.csv和多个subset0-9以内几个都可以
2.直接运行以下代码,文件存储如图
import os
from glob import glob
import pandas as pd
import numpy as np
import SimpleITK as sitk
from tqdm import tqdm
from sklearn.cluster import KMeans
from skimage import morphology, measure
from xml.etree.ElementTree import Element, ElementTree, tostring
from PIL import Image
# 设置基础路径
luna_base_path = "subset0-9/"
annotation_path = "subset0-9/annotations.csv"
output_npy_base_path = "npy"
output_data_base_path = "data"
# 定义函数,将CT扫描中的像素值归一化
def normalizePlanes(npzarray):
maxHU = 400
minHU = -1000
npzarray = (npzarray - minHU) / (maxHU - minHU) # 像素直归一化处理
npzarray[npzarray > 1] = 1
npzarray[npzarray < 0] = 0
npzarray *= 255 # 所有归一的像素乘以255,即1-255范围
return npzarray.astype(int)
# 定义函数,创建结节在CT扫描中的掩膜
def make_mask(center, diam, z, width, height, spacing, origin):
mask = np.zeros([height, width]) # 匹配图像,生成一个确定高和宽的,元素全为0的掩码
# 定义结节所在的体素范围
v_center = (center - origin) / spacing # 将肺结节中心坐标从世界坐标系转换为体素坐标系
v_diam = int(diam / spacing[0] + 5) # 计算肺结节直径在体素坐标系中的大小
v_xmin = np.max([0, int(v_center[0] - v_diam) - 5]) # 计算肺结节所在的 x 方向上的最小体素坐标
v_xmax = np.min([width - 1, int(v_center[0] + v_diam) + 5]) # 计算肺结节所在的 x 方向上的最大体素坐标
v_ymin = np.max([0, int(v_center[1] - v_diam) - 5]) # 计算肺结节所在的 y 方向上的最小体素坐标
v_ymax = np.min([height - 1, int(v_center[1] + v_diam) + 5]) # 计算肺结节所在的 y 方向上的最大体素坐标
v_xrange = range(v_xmin, v_xmax + 1) # 表示 x 方向上的体素坐标范围
v_yrange = range(v_ymin, v_ymax + 1) # 表示 y 方向上的体素坐标范围
x_data = [x * spacing[0] + origin[0] for x in range(width)] # 通过列表推导式,创建一个列表 x_data,其中包含了图像每个像素点在 x 方向上的世界坐标
y_data = [x * spacing[1] + origin[1] for x in range(height)] # 通过列表推导式,创建一个列表 y_data,其中包含了图像每个像素点在 y 方向上的世界坐标
# 结节周围全都填充1,用于在图像中标记肺结节位置
for v_x in v_xrange:
for v_y in v_yrange:
p_x = spacing[0] * v_x + origin[0] # 计算了当前体素在世界坐标系中的 x 坐标
p_y = spacing[1] * v_y + origin[1] # 计算了当前体素在世界坐标系中的 y 坐标
if np.linalg.norm(center - np.array([p_x, p_y, z])) <= diam: # 如果体素在肺结节内部或边缘
mask[int((p_y - origin[1]) / spacing[1]), int((p_x - origin[0]) / spacing[0])] = 1.0
return mask
def beatau(e, level=0):
if len(e) > 0:
e.text = '\n' + '\t' * (level + 1)
for child in e:
beatau(child, level + 1)
child.tail = child.tail[:-1]
e.tail = '\n' + '\t' * level
def csvtoxml(name, x, y, w, h):
root = Element('annotation') # 根节点
erow1 = Element('folder') # 节点1
erow1.text = "VOC"
erow2 = Element('filename') # 节点2
erow2.text = str(name)
erow3 = Element('size') # 节点3
erow31 = Element('width')
erow31.text = "512"
erow32 = Element('height')
erow32.text = "512"
erow33 = Element('depth')
erow33.text = "3"
erow3.append(erow31)
erow3.append(erow32)
erow3.append(erow33)
erow4 = Element('object')
erow41 = Element('name')
erow41.text = 'nodule'
erow42 = Element('bndbox')
erow4.append(erow41)
erow4.append(erow42)
erow421 = Element('xmin')
erow421.text = str(x - np.round(w / 2).astype(int))
erow422 = Element('ymin')
erow422.text = str(y - np.round(h / 2).astype(int))
erow423 = Element('xmax')
erow423.text = str(x + np.round(w / 2).astype(int))
erow424 = Element('ymax')
erow424.text = str(y + np.round(h / 2).astype(int))
erow42.append(erow421)
erow42.append(erow422)
erow42.append(erow423)
erow42.append(erow424)
root.append(erow1)
root.append(erow2)
root.append(erow3)
root.append(erow4)
beatau(root)
return ElementTree(root)
# 定义主要处理函数
def process_subset(subset_path):
# 获取文件列表
file_list = glob(os.path.join(subset_path, "*.mhd"))
# 获取文件名与案例相关的路径
def get_filename(case):
nonlocal file_list
for f in file_list:
if case in f:
return f
# 读取包含结节注释的CSV文件
df_node = pd.read_csv(annotation_path)
df_node["file"] = df_node["seriesuid"].apply(get_filename) # 对于 "seriesuid" 中的每个值,找到对应的文件路径
df_node = df_node.dropna() # 从数据框中删除包含 NaN 的行,确保数据框中不包含缺失文件路径的记录
# 遍历图像文件
for fcount, img_file in enumerate(tqdm(file_list)):
print("获取图像文件 %s 的掩膜" % img_file.replace(subset_path, ""))
mini_df = df_node[df_node["file"] == img_file] # mini_df 包含了与当前图像文件相关联的所有结节注释
if len(mini_df) > 0: # 跳过没有结节的文件
# 读取图像数据
itk_img = sitk.ReadImage(img_file)
img_array = sitk.GetArrayFromImage(itk_img) # 将SimpleITK图像对象转换为NumPy三维数组(z, y, x)
num_z, height, width = img_array.shape # 图像的深度(z方向上的切片数量)、高度和宽度
origin = np.array(itk_img.GetOrigin()) # 世界坐标系下的 x, y, z (mm)
spacing = np.array(itk_img.GetSpacing()) # 世界坐标中的体素间隔 (mm)
# 遍历所有结节的注释
for node_idx, cur_row in mini_df.iterrows():
node_x = cur_row["coordX"]
node_y = cur_row["coordY"]
node_z = cur_row["coordZ"]
diam = cur_row["diameter_mm"]
# 保留三个切片
imgs = np.ndarray([3, height, width], dtype=np.float32) # 创建一个形状为 (3, height, width) 的三维数组 imgs,用于存储图像数据
masks = np.ndarray([3, height, width], dtype=np.uint8) # 创建一个形状为 (3, height, width) 的三维数组 masks,用于存储掩膜数据
center = np.array([node_x, node_y, node_z]) # 表示结节在图像中的中心位置
v_center = np.rint((center - origin) / spacing) # 体素坐标系的结节中心 (x, y, z)
for i, i_z in enumerate(np.arange(int(v_center[2]) - 1, int(v_center[2]) + 2).clip(0, num_z - 1)): # 防止超出 z
name = "%04d_%04d.jpg" % (fcount, node_idx)
x = v_center[0]
y = v_center[1]
w = int(diam / spacing[0] + 5) # 计算肺结节直径在体素坐标系中的大小
h = int(diam / spacing[0] + 5) # 计算肺结节直径在体素坐标系中的大小
label = csvtoxml(name, x, y, w, h)
mask = make_mask(center, diam, i_z * spacing[2] + origin[2], width, height, spacing, origin) # 调用 make_mask 函数生成结节的掩膜
masks[i] = mask # 将生成的掩膜保存到 masks 数组的相应位置
imgs[i] = normalizePlanes(img_array[i_z]) # 将规范化后的数据保存到 imgs 数组的相应位置
# 拼接输出路径
output_npy_path = os.path.join(output_npy_base_path, os.path.basename(subset_path))
if not os.path.exists(output_npy_path):
os.makedirs(output_npy_path)
output_data_path = os.path.join(output_data_base_path, os.path.basename(subset_path), "labels")
if not os.path.exists(output_data_path):
os.makedirs(output_data_path)
np.save(os.path.join(output_npy_path, "images_%04d_%04d.npy" % (fcount, node_idx)), imgs) # 将处理后的图像数据 imgs 保存为一个 .npy 文件
np.save(os.path.join(output_npy_path, "masks_%04d_%04d.npy" % (fcount, node_idx)), masks) # 将处理后的结节掩膜 masks 保存为一个 .npy 文件
label.write(os.path.join(output_data_path, "%04d_%04d_1.xml" % (fcount, node_idx)))
label.write(os.path.join(output_data_path, "%04d_%04d_2.xml" % (fcount, node_idx)))
label.write(os.path.join(output_data_path, "%04d_%04d_3.xml" % (fcount, node_idx)))
# 获取肺实质
def get_lungmask(img_list):
for img_file in img_list:
# 加载图像数据
imgs_to_process = np.load(img_file).astype(np.float64)
print("处理图像", img_file)
# 处理每个切片
for i in range(len(imgs_to_process)):
# print(imgs_to_process.shape)
img = imgs_to_process[i]
# 标准化
mean = np.mean(img)
std = np.std(img)
img = (img - mean) / std
# 寻找肺部附近的平均像素,以重新调整过度曝光的图像
middle = img[100:400, 100:400]
# 使用 Kmeans 算法将前景(放射性不透明组织)和背景(放射性透明组织,即肺部)分离。
# 仅在图像中心进行此操作,以尽可能避免图像的非组织部分。
kmeans = KMeans(n_clusters=2, n_init=10).fit(np.reshape(middle, [np.prod(middle.shape), 1]))
centers = sorted(kmeans.cluster_centers_.flatten())
threshold = np.mean(centers)
thresh_img = np.where(img < threshold, 1.0, 0.0) # 阈值化图像,二值化处理
# 腐蚀和膨胀
eroded = morphology.erosion(thresh_img, np.ones([4, 4]))
dilation = morphology.dilation(eroded, np.ones([10, 10]))
# 对二值图像进行标记,标记连通区域
labels = measure.label(dilation)
label_vals = np.unique(labels)
regions = measure.regionprops(labels)
good_labels = []
for prop in regions:
B = prop.bbox # 边界框
if B[2] - B[0] < 475 and B[3] - B[1] < 475 and B[0] > 40 and B[2] < 472:
good_labels.append(prop.label)
# 创建肺部掩码lungmask
lungmask = np.zeros([512, 512], dtype=np.int8)
for N in good_labels:
lungmask = lungmask + np.where(labels == N, 1, 0)
# print(lungmask.shape)
lungmask = morphology.dilation(lungmask, np.ones([10, 10]))
imgs_to_process[i] = lungmask
# 将处理后的 lungmask 保存
# print(imgs_to_process.shape)
np.save(img_file.replace("images", "lungmasks"), imgs_to_process)
def npytojpg(img_list):
for i in range(len(img_list)):
# 加载原始图像和肺部 mask
origin_img = np.load(img_list[i])
lung_mask = np.load(img_list[i].replace("images", "lungmasks"))
# 使用os.path.basename()获取文件名
file_name_npy = os.path.basename(img_list[i])
# 使用os.path.splitext()分割文件名和后缀
file_name, file_extension = os.path.splitext(file_name_npy)
for j in range(len(origin_img)):
# 获取当前切片的原始图像和肺部 mask
img = origin_img[j]
lung_img = lung_mask[j]
# 对原始图像进行肺部分割
segment = img * lung_img
# 将分割结果转为 PIL Image,并保存为 JPEG 文件
segment = Image.fromarray(segment)
segment = segment.convert('RGB')
new_file_name = file_name.replace("images_", "")
new_file_path = os.path.join(save_path, f"{new_file_name}_{j + 1}.jpg")
segment.save(new_file_path)
# 遍历所有子集,生成images*.npy、masks*.npy和*.xml文件
for subset_number in range(10):
subset_path = os.path.join(luna_base_path, f"subset{subset_number}")
process_subset(subset_path)
# 遍历所有子集,生成lungmasks*.npy文件
for i in range(10):
img_list = glob(os.path.join(output_npy_base_path, f"subset{i}/", "images*.npy"))
get_lungmask(img_list)
# 历遍所有子集,生成*.jpg文件
for subset_num in range(10):
# 获取文件列表
img_list = glob(os.path.join(output_npy_base_path, "subset{}".format(subset_num), "images*.npy"))
print(img_list)
# 指定保存路径
save_path = os.path.join(output_data_base_path, "subset{}/".format(subset_num), "images")
# 如果保存路径不存在,则创建
if not os.path.exists(save_path):
os.makedirs(save_path)
npytojpg(img_list)
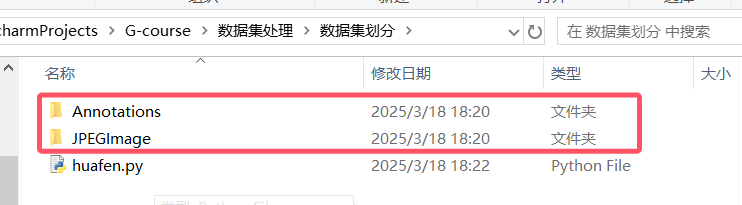
3。得到图片和xml格式对应
可以将subset0下的images和lables都放在一个文件夹当中例如

4.将xml格式转为yolo格式
①找出xml的类别有多少个
import os
import xml.etree.ElementTree as ET
def convert_xml_to_yolo(xml_file, output_dir, class_mapping):
"""
将单个 XML 文件转换为 YOLO 格式的标注文件。
:param xml_file: XML 文件路径
:param output_dir: YOLO 格式标注文件的输出目录
:param class_mapping: 类别名称到类别索引的映射字典
"""
try:
# 解析 XML 文件
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像尺寸
size = root.find("size")
if size is None:
print(f"跳过 {xml_file},原因:缺少 <size> 标签")
return
img_width = int(size.find("width").text)
img_height = int(size.find("height").text)
# 创建 YOLO 格式的标注文件
yolo_file = os.path.join(output_dir, os.path.splitext(os.path.basename(xml_file))[0] + ".txt")
with open(yolo_file, "w") as f:
# 遍历每个目标
for obj in root.findall("object"):
class_name = obj.find("name").text
if class_name not in class_mapping:
print(f"警告:{class_name} 未在类别映射中定义,跳过")
continue # 忽略未映射的类别
# 获取类别索引
class_id = class_mapping[class_name]
# 获取边界框坐标
bbox = obj.find("bndbox")
if bbox is None:
print(f"警告:{xml_file} 缺少 <bndbox>,跳过此对象")
continue
xmin = float(bbox.find("xmin").text)
ymin = float(bbox.find("ymin").text)
xmax = float(bbox.find("xmax").text)
ymax = float(bbox.find("ymax").text)
# 边界框数值检查
if xmin < 0 or ymin < 0 or xmax > img_width or ymax > img_height:
print(f"警告:{xml_file} 边界框超出范围,跳过")
continue
# 计算归一化坐标(YOLO 格式)
x_center = (xmin + xmax) / 2 / img_width
y_center = (ymin + ymax) / 2 / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
# 写入 YOLO 格式的标注文件
f.write(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n")
print(f"已转换:{xml_file} -> {yolo_file}")
except Exception as e:
print(f"错误处理 {xml_file}:{str(e)}")
def convert_folder_xml_to_yolo(xml_dir, output_dir, class_mapping):
"""
将指定目录下的所有 XML 文件转换为 YOLO 格式的标注文件。
:param xml_dir: 包含 XML 文件的目录
:param output_dir: YOLO 格式标注文件的输出目录
:param class_mapping: 类别名称到类别索引的映射字典
"""
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 遍历 XML 目录下的所有文件
xml_files = [f for f in os.listdir(xml_dir) if f.endswith(".xml")]
if not xml_files:
print("警告:未找到 XML 文件!")
return
for xml_file in xml_files:
xml_path = os.path.join(xml_dir, xml_file)
convert_xml_to_yolo(xml_path, output_dir, class_mapping)
print(f"转换完成!YOLO 格式标注已保存至 {output_dir}")
# 示例用法
if __name__ == "__main__":
# 定义类别映射(根据你的数据集修改)
class_mapping = {
"nodule": 0,
}
# 输入目录(包含 XML 文件的目录)
xml_directory = 'D:/jetbrains/PycharmProjects/G-course/数据集处理/data/subset0/labels' # 你的 XML 标注文件夹路径
# 输出目录(保存 YOLO 格式标注文件的目录)
output_directory = "D:/jetbrains/PycharmProjects/G-course/数据集处理/data/subset0/Ann" # 你的 YOLO 标注输出文件夹
# 转换 XML 文件为 YOLO 格式
convert_folder_xml_to_yolo(xml_directory, output_directory, class_mapping)
②xml转yolo代码
import os
import xml.etree.ElementTree as ET
def convert_xml_to_yolo(xml_file, output_dir, class_mapping):
"""
将单个 XML 文件转换为 YOLO 格式的标注文件。
:param xml_file: XML 文件路径
:param output_dir: YOLO 格式标注文件的输出目录
:param class_mapping: 类别名称到类别索引的映射字典
"""
try:
# 解析 XML 文件
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像尺寸
size = root.find("size")
if size is None:
print(f"跳过 {xml_file},原因:缺少 <size> 标签")
return
img_width = int(size.find("width").text)
img_height = int(size.find("height").text)
# 创建 YOLO 格式的标注文件
yolo_file = os.path.join(output_dir, os.path.splitext(os.path.basename(xml_file))[0] + ".txt")
with open(yolo_file, "w") as f:
# 遍历每个目标
for obj in root.findall("object"):
class_name = obj.find("name").text
if class_name not in class_mapping:
print(f"警告:{class_name} 未在类别映射中定义,跳过")
continue # 忽略未映射的类别
# 获取类别索引
class_id = class_mapping[class_name]
# 获取边界框坐标
bbox = obj.find("bndbox")
if bbox is None:
print(f"警告:{xml_file} 缺少 <bndbox>,跳过此对象")
continue
xmin = float(bbox.find("xmin").text)
ymin = float(bbox.find("ymin").text)
xmax = float(bbox.find("xmax").text)
ymax = float(bbox.find("ymax").text)
# 边界框数值检查
if xmin < 0 or ymin < 0 or xmax > img_width or ymax > img_height:
print(f"警告:{xml_file} 边界框超出范围,跳过")
continue
# 计算归一化坐标(YOLO 格式)
x_center = (xmin + xmax) / 2 / img_width
y_center = (ymin + ymax) / 2 / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
# 写入 YOLO 格式的标注文件
f.write(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n")
print(f"已转换:{xml_file} -> {yolo_file}")
except Exception as e:
print(f"错误处理 {xml_file}:{str(e)}")
def convert_folder_xml_to_yolo(xml_dir, output_dir, class_mapping):
"""
将指定目录下的所有 XML 文件转换为 YOLO 格式的标注文件。
:param xml_dir: 包含 XML 文件的目录
:param output_dir: YOLO 格式标注文件的输出目录
:param class_mapping: 类别名称到类别索引的映射字典
"""
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 遍历 XML 目录下的所有文件
xml_files = [f for f in os.listdir(xml_dir) if f.endswith(".xml")]
if not xml_files:
print("警告:未找到 XML 文件!")
return
for xml_file in xml_files:
xml_path = os.path.join(xml_dir, xml_file)
convert_xml_to_yolo(xml_path, output_dir, class_mapping)
print(f"转换完成!YOLO 格式标注已保存至 {output_dir}")
# 示例用法
if __name__ == "__main__":
# 定义类别映射(根据你的数据集修改)
class_mapping = {
"nodule": 0,
}
# 输入目录(包含 XML 文件的目录)
xml_directory = "data/annotations" # 你的 XML 标注文件夹路径
# 输出目录(保存 YOLO 格式标注文件的目录)
output_directory = "data/yolo_labels" # 你的 YOLO 标注输出文件夹
# 转换 XML 文件为 YOLO 格式
convert_folder_xml_to_yolo(xml_directory, output_directory, class_mapping)
将其进行存储成这样
③划分好数据集
import os
import shutil
import random
from tqdm import tqdm
"""
标注文件是yolo格式(txt文件)
训练集:验证集:测试集 (7:2:1)
"""
def split_img(img_path, label_path, split_list):
try:
Data = './Maskdata'
# 创建需要的文件夹
train_img_dir = os.path.join(Data, 'train', 'images')
val_img_dir = os.path.join(Data, 'val', 'images')
test_img_dir = os.path.join(Data, 'test', 'images')
train_label_dir = os.path.join(Data, 'train', 'labels')
val_label_dir = os.path.join(Data, 'val', 'labels')
test_label_dir = os.path.join(Data, 'test', 'labels')
# 创建文件夹
os.makedirs(train_img_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(val_img_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
os.makedirs(test_img_dir, exist_ok=True)
os.makedirs(test_label_dir, exist_ok=True)
except Exception as e:
print(f'文件目录已存在: {e}')
train, val, test = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
for img in train_img:
all_img_path.remove(img)
val_img = random.sample(all_img_path, int(val / (val + test) * len(all_img_path)))
for img in val_img:
all_img_path.remove(img)
test_img = all_img_path
# 将图片和标签文件复制到相应的目录
copy_files(train_img, label_path, train_img_dir, train_label_dir, 'train')
copy_files(val_img, label_path, val_img_dir, val_label_dir, 'val')
copy_files(test_img, label_path, test_img_dir, test_label_dir, 'test')
def copy_files(img_list, label_path, img_dir, label_dir, desc):
for img in tqdm(img_list, desc=f'{desc} ', ncols=80, unit='img'):
img_name = os.path.basename(img)
label_name = os.path.splitext(img_name)[0] + '.txt'
shutil.copy(img, img_dir)
shutil.copy(os.path.join(label_path, label_name), label_dir)
if __name__ == '__main__':
img_path = 'JPEGImage' # 你的图片存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
label_path = 'Annotations' # 你的txt文件存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
split_list = [0.7, 0.3, 0.1] # 数据集划分比例[train:val:test]
split_img(img_path, label_path, split_list)
3.开始yolov11的训练
1.写data.yaml
train: ../Maskdata/train/images
val: ../Maskdata/val/images
test: ../Maskdata/test/images
nc: 1
names:
0: nodule
2.在ultralytics/models/11下重写自己配置
只改自己的类别
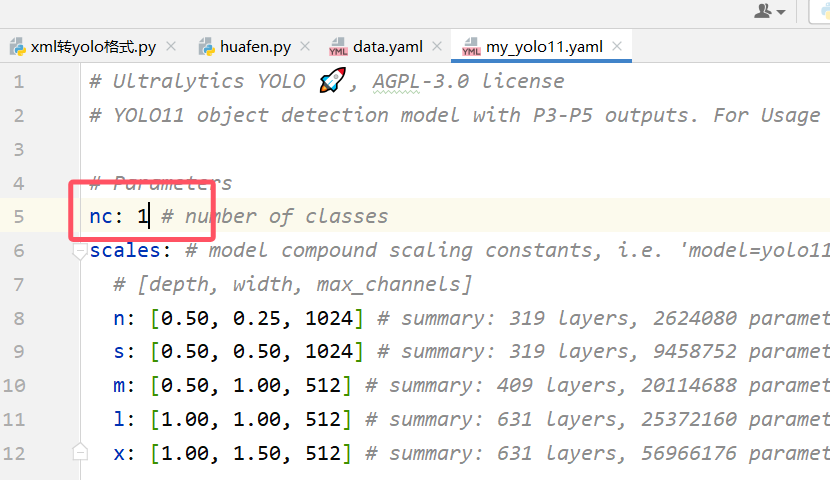
3.写一个train.py
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/my_yolo11.yaml') # 指定YOLO模型对象,并加载指定配置文件中的模型配置
#model.load('yolov11s.pt') #加载预训练的权重文件'yolov11s.pt',加速训练并提升模型性能
model.train(data='D:/jetbrains/PycharmProjects/G-course/ultralytics-8.3.39/Maskdata/data.yaml', # 指定训练数据集的配置文件路径,这个.yaml文件包含了数据集的路径和类别信息
cache=False, # 是否缓存数据集以加快后续训练速度,False表示不缓存
imgsz=640, # 指定训练时使用的图像尺寸,640表示将输入图像调整为640x640像素
epochs=5, # 设置训练的总轮数为200轮
batch=2, # 设置每个训练批次的大小为16,即每次更新模型时使用16张图片
close_mosaic=10, # 设置在训练结束前多少轮关闭 Mosaic 数据增强,10 表示在训练的最后 10 轮中关闭 Mosaic
workers=8, # 设置用于数据加载的线程数为8,更多线程可以加快数据加载速度
patience=50, # 在训练时,如果经过50轮性能没有提升,则停止训练(早停机制)
device='cpu', # 指定使用的设备,'0'表示使用第一块GPU进行训练
optimizer='SGD', # 设置优化器为SGD(随机梯度下降),用于模型参数更新
)

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









