







前言:
写这篇文章的目的很简单,之前在树莓派5上运行过yolo的算法,但是帧率都很低(5fps),最多只能用来抓拍检测,想实现视频流的检测几乎是不可能的,所以我在淘宝上发现了一款ai加速模块,还是树莓派官方和hailo出的,所以一开始觉得应该使用起来很简单。hailo-8模块如图:
但是实际使用起来并没有那么简单,相反官方的文档做的说实话不尽人意,很多细节的地方都没有说到,得到社区去摸索才行,加上这个模块出来没多久,国内也没有啥资料,像微雪,亚博这些都只有那种很简单的上手文档,根本没法正儿八经使用,所以我花了一些时间摸索出来了这个教程,一天可能更新不完,后面会陆陆续续更新。后续看到这篇的话,版本可能发生变化而导致冲突,但是本文的一些方法可以借鉴,有更新我有时间也会做相应的修改
ps.实现本文之前需要你有一定的基础,纯小白出门左转。
本文是翻阅了很多资料和论坛才写出来的,转载一定要说明出处,谢谢!
作者目前大三,没有时间回复私信,有事在评论区留言即可,看见会回复
先来简单介绍一下hailo-8模块的数据


目前hailo-8有两种模式,第一是左边的m2样式,一种是右边只能用于树莓派5的官方出品的样式
个人觉得m2样式的最好,因为可以用于像rk3588这种自带m2接口的主板,也可以用给电脑使用,但是m2格式的26tops的版本价格很贵,在1300左右才能买到,而树莓派专用的只需要900左右,13tops的两者价格都差不多600左右,根据自身情况选择合适的版本即可。
下面是详细数据
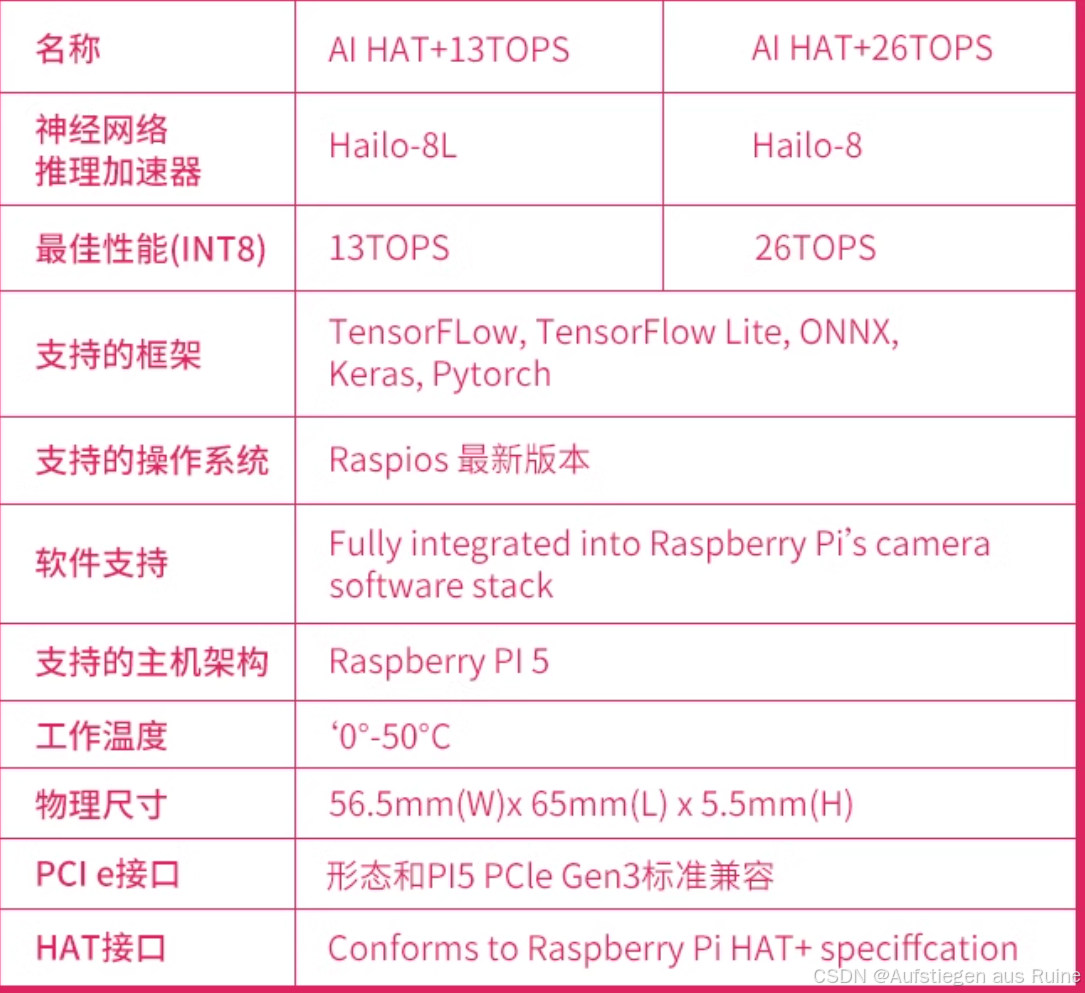
可以看见是支持目前市面上主流的框架的,所以到不需要为兼容性考虑(这里显示只支持树莓派的系统是因为这是那个官方套件,实际有m2接口的基本都可以,但是本文是基于官方套件hailo-8写的,其余开发板请自行查阅官方资料)
事前准备:
你需要一台满足以下要求的电脑(服务器也可以,wsl2环境下也可以,个人推荐在本地电脑使用wsl,因为模型转换是很常用的东西,而且和树莓派的运行环境是高度绑定的,服务器上每次配环境可能会更新,导致版本不匹配发生冲突)

ubuntu版本:只能20.04和22.04其余都不行
运行内存:低于16g在转换大的模型的时候可能会爆内存
python版本:22.04默认3.10.12
英伟达的GPU:cuda版本建议11.8,对应的cudnn版本为8.9,我不清楚更高版本的是否可以使用,请自行尝试。这两个很关键,cudnn版本不对或者不安装会报dnn库找不到的
硬件部分:
1:树莓派5(已经烧录好树莓派官方镜像,推荐桌面完全版,使用起来更方便)
2:hailo-8或者hailo-8l
3:摄像头(我使用的是微雪的imx477 16mm长焦镜头模组,可以使用树莓派官方的普通摄像头或者usb免驱动摄像头)
1.开始:
1.1:训练yolov8模型:
网上有关yolov8模型的训练有很多教程,我这里不过多赘述,给大家推荐一个视频进行学习使用b站视频,里面有详细的在服务器上训练yolov8模型的教程,大家自行观看,在训练结束后会得到一个以pt结尾的模型文件,我们需要执行以下命令(在训练的服务器上pt模型的文件路径下执行,使用终端)
yolo export model=./best.pt imgsz=640 fo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4455
4455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









