







文章目录
-
- WU-NET: A WEAKLY-SUPERVISED UNMIXING NETWORK FOR REMOTELY SENSED HYPERSPECTRAL IMAGERY
- Hyperspectral Unmixing Using a Neural Network Autoencoder
- Spectral-Spatial Hyperspectral Unmixing Using Multitask Learning
- NEURAL NETWORK HYPERSPECTRAL UNMIXING WITH SPECTRAL INFORMATION DIVERGENCE OBJECTIVE
- MULTITASK LEARNING FOR SPATIAL-SPECTRAL HYPERSPECTRAL UNMIXING
- Stacked Nonnegative Sparse Autoencoders for Robust Hyperspectral Unmixing
- NONNEGATIVE SPARSE AUTOENCODER FOR ROBUST ENDMEMBER EXTRACTION FROM REMOTELY SENSED HYPERSPECTRAL IMAGES
- DEEP AUTO-ENCODER NETWORK FOR HYPERSPECTRAL IMAGE UNMIXING
- DAEN: Deep Autoencoder Networks for Hyperspectral Unmixing
- DEEP SPECTRAL CONVOLUTION NETWORK FOR HYPERSPECTRAL UNMIXING
- EndNet: Sparse AutoEncoder Network for Endmember Extraction and Hyperspectral Unmixing
- Hyperspectral Unmixing via Deep Convolutional Neural Networks
- LOOK FOR SALIENCY IN HYPERSPECTRAL IMAGES
进阶论文中标!的论文
WU-NET: A WEAKLY-SUPERVISED UNMIXING NETWORK FOR REMOTELY SENSED HYPERSPECTRAL IMAGERY
近年来,人们在提高线性或非线性混合模型的高光谱解混合性能方面做了大量的努力,但它们处理光谱变异性和提取物理意义端元的能力仍然有限。基于深度学习强大的学习能力,我们提出了一种弱监督解混网络WU-Net来突破这一瓶颈。除了类似于自动编码器的体系结构之外,WU-Net从纯或近乎纯的端元学习额外的网络,以修正另一个分离网络的权值,使之朝着更准确、更可解释的分离解决方案发展,从而产生一个 双流深度网络。
光谱变异性(SV) 在HSI中是普遍存在的。一般来说,SV指的是由于光照和地形、大气条件以及材料的内在变异性的影响,在某种材料中光谱特征的各种变形。SV不可避免地将未预测的误差转移到LMM中,导致解混性能相对较差。
在实际应用中,由于盲HU中对真实端元缺乏有效的引导,这些方法往往会产生物理上无意义的端元。
动机:
为了解决上述限制,我们提出了一个弱监督分解网络,称为WU-Net。WU-Net以双流网络架构开始。人们学习从图像中提取的相对纯粹的端元与其相应的丰度之间的映射。另一种是类似自动编码器的网络,类似于之前提出的基于dl的解混方法。值得注意的是,我们迫使分离模块中的两个网络共享相同的权值,以便将端点成员潜在的内在属性转移到我们的网络系统中,从而产生一个更有物理意义的分离过程。此外,丰度非负约束(ANC)和丰度和对一约束(ASC)也通过附加层嵌入到网络中。
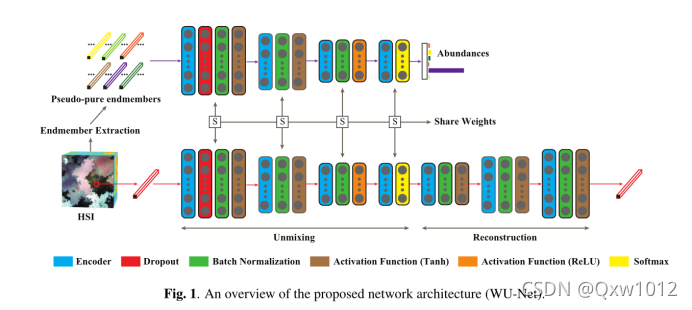
Dropout layer :有效去除SV
ReLU activation function:满足abundance non-negative constraint(ANC)非负
Softmax layer :满足abundance sum-to-one constraint (ASC) 丰度和为一
在本文中,我们提出了一种弱监督解混网络WU-Net,它是一种设计良好的用于高光谱解混的双流深度网络。与之前提出的类似自动编码器的模型不同,WU-Net还从纯或接近纯的端成员中学习端成员网络,并将其参数转移到基于自动编码器的解混网络中,从而产生更合理和更优的解混。值得注意的是,WU-Net在一定程度上受到端元提取的限制。在我们未来的工作中,我们希望在多模态数据(如多光谱数据[22,22])的帮助下,开发一个更通用的基于网络的框架,以更有效地解决这一问题。
上述论文是EGU-Net的一个子网络结构,在论文泛读(一)中
Endmember-Guided Unmixing Network (EGU-Net): A General Deep Learning Framework for Self-Supervised Hyperspectral Unmixing
Hyperspectral Unmixing Using a Neural Network Autoencoder
论文
ABSTRACT
本文提出了一种基于深度学习的神经网络自编码器形式的盲高光谱解混方法(盲分离,同时估计端元和丰度)。结果表明,线性混合模型隐式地对网络施加了一定的结构约束,有效地实现了高光谱盲解混。对浅编码器和深编码器的几种不同架构配置进行了评估。此外,深度编码器使用不同的激活功能进行测试。此外,我们研究了使用三个不同的目标函数的方法的性能。将该方法与其他基于真实数据和已建立的几种常用数据集的地面真值基准方法进行了比较。实验结果表明,该方法优于其他常用的高光谱分解方法,对噪声具有较强的鲁棒性。当使用光谱角距离作为网络的目标函数时,尤其如此。最后,结果表明,一个更深和更复杂的编码器不一定会给出更好的结果。
在本文中,我们将深度学习应用于具有深度编码器的自动编码器的HSU问题,其中丰度和一个约束(ASC)和非负丰度约束(ANC)都使用自定义层和权重约束执行。此外,该方法还利用了丰度向量的稀疏性,采用了一种自适应阈值形式,并根据网络的目标函数进行了优化。
本工作是对[29]工作的扩展,[29]研究了一种更简单的自动编码器体系结构的性能,并且 没有使用光谱角距离(SAD) 目标函数。该方法与传统方法的一个重要区别是,除了估计端元谱的数量外,没有调谐参数,而且该方法框架的实现使得使用任意复杂度的自定义目标函数非常容易。该方法不估计一个HSI中的端成员的数量,因此 必须给出端成员的数量。
几乎所有基于深度学习的HSU方法都不进行盲分解,即同时估计端元光谱及其丰度。据作者所知,进行盲分解的深度学习方法只有[26-29]中的方法。该方法与上述方法的主要不同之处在于,它不仅具有深度编码器,而且能够使用自定义激活函数(而不是显式稀疏正则化)通过一层来利用丰度的稀疏性。因此,它没有为编码器和解码器使用绑定权值的对称架构。此外,我们对自动编码器的编码部分测试了许多不同的激活函数,并使用三个不同的目标函数,而大多数使用自动编码器分解的工作使用均方误差(MSE)目标函数。
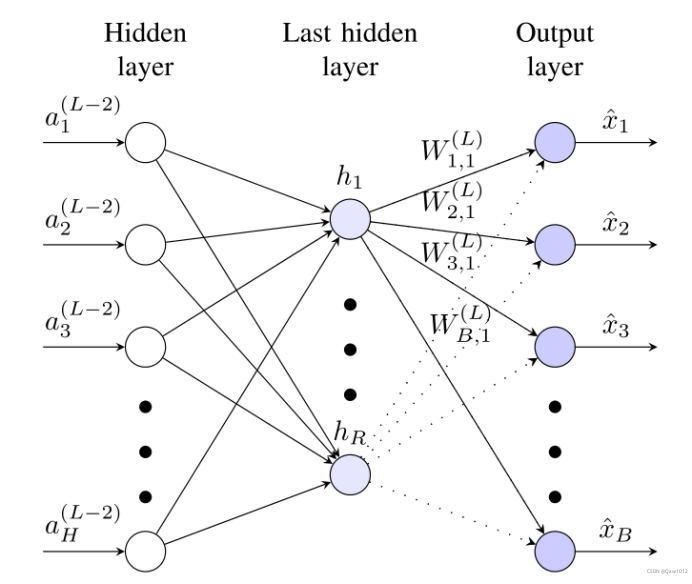
自动编码器的示意图,显示编码器的最后两层和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3280
3280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









