






源自:指挥与控制学报
作者: 陈晓轩,冯旸赫,黄金才等
注:若出现显示不完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习
摘 要
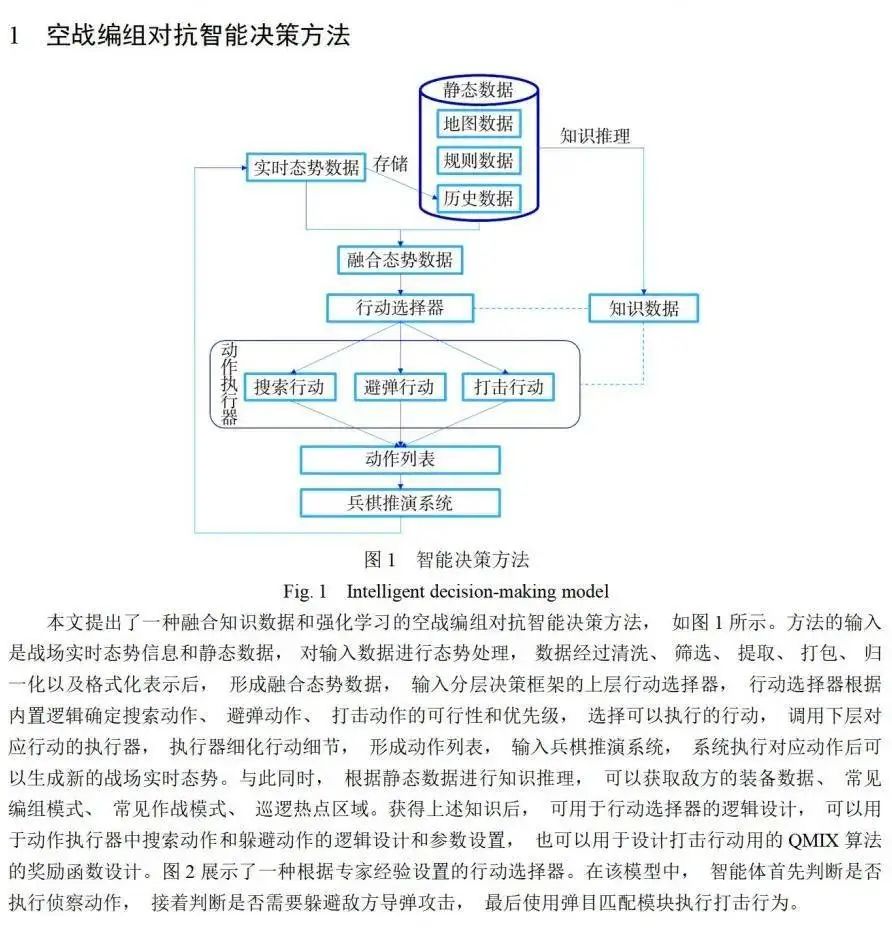
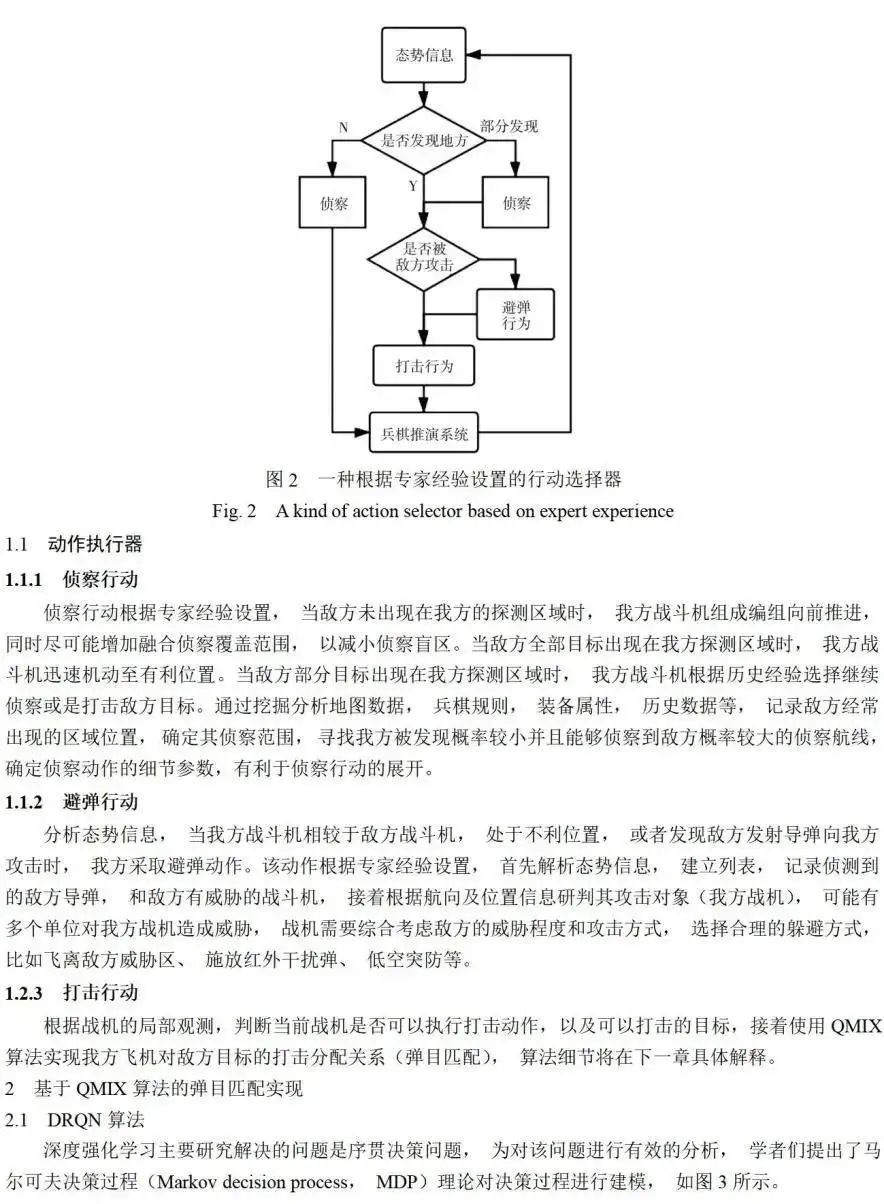
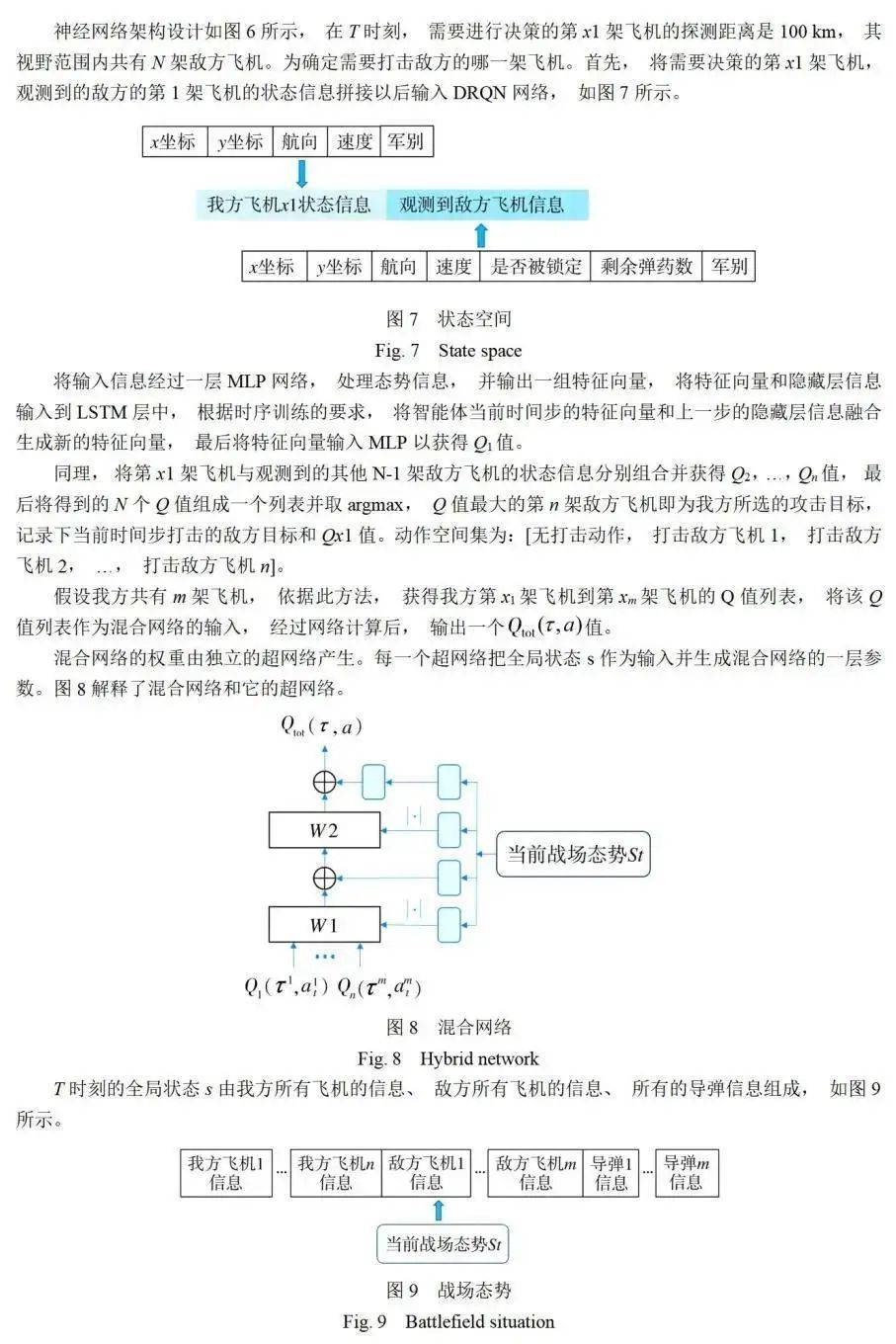
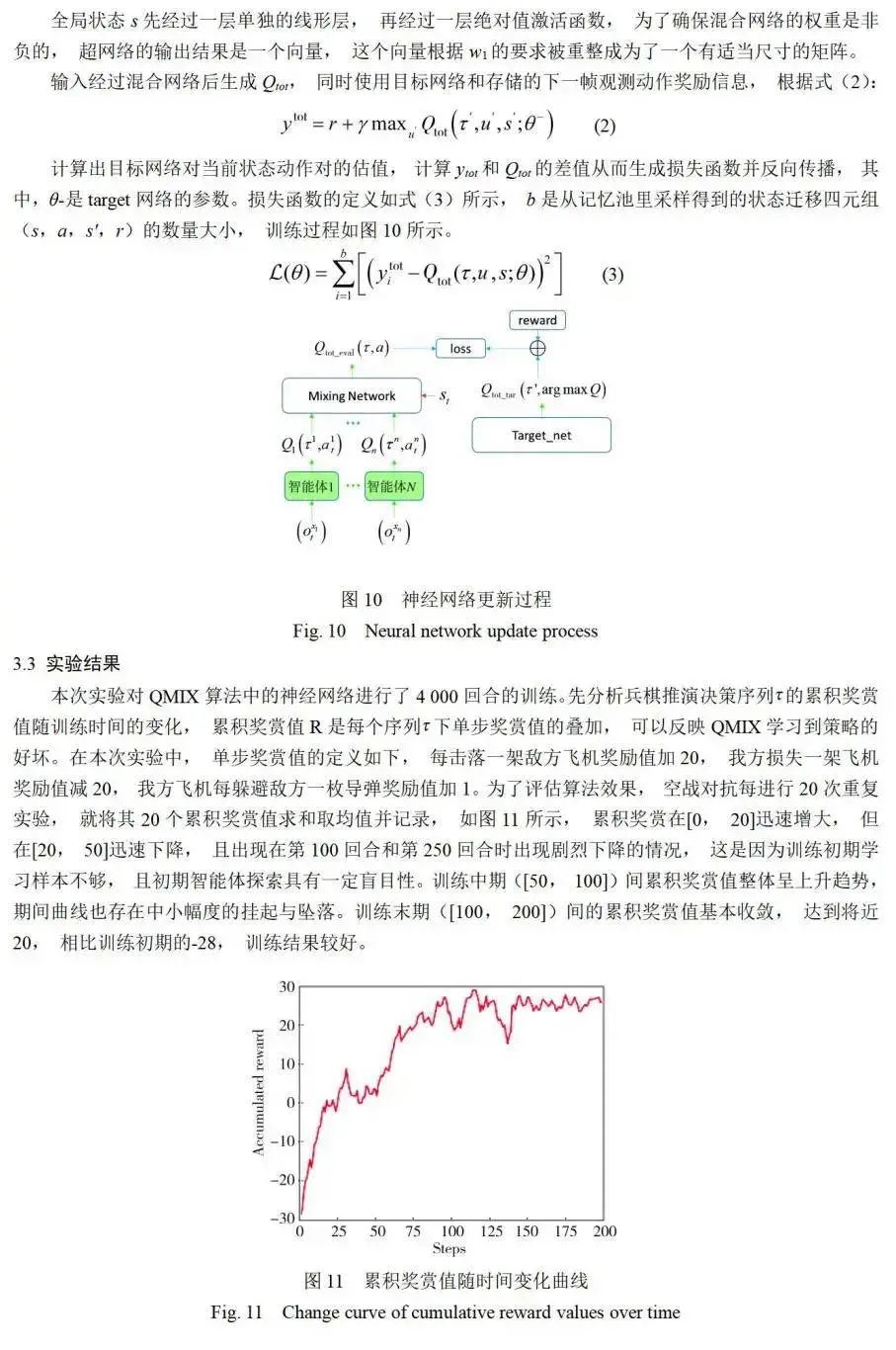
基于兵棋研究的空战编组对抗方法主要使用规则或运筹等手段,存在假设不够合理、建模不准确、应变性差等缺陷。强化学习算法可以根据作战数据自主学习编组对抗策略,以应对复杂的战场情况,但现有强化学习对作战数据要求高,当动作空间过大时,算法收敛慢,且对仿真平台有较高的要求。针对上述问题,提出了一种融合知识数据和强化学习的空战编组对抗智能决策方法,该决策方法的输入是战场融合态势,使用分层决策框架控制算子选择并执行任务,上层包含使用专家知识驱动的动作选择器,下层包含使用专家知识和作战规则细化的避弹动作执行器、侦察动作执行器和使用强化学习算法控制的打击动作执行器。最后基于典型作战场景进行实验,验证了该方法的可行性和实用性,且具有建模准确、训练高效的优点。





声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
注:若出现显示不完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









