







EM(Expectation-Maximum)算法也称期望最大化算法,曾入选“数据挖掘十大算法”中,可见EM算法在机器学习、数据挖掘中的影响力。EM算法是最常见的隐变量估计方法,在机器学习中有极为广泛的用途,例如常被用来学习高斯混合模型(Gaussian mixture model,简称GMM)的参数;隐式马尔科夫算法(HMM)、LDA主题模型的变分推断等等。EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法(Expectation-Maximization Algorithm)。
问题描述
我们目前有200个男生的身高,我们假设身高是按照高斯分布排序的,那么我们要如何求得这个高斯分布的以及
呢。
我们已知的条件有两个:样本服从的分布模型、随机抽取的样本。我们需要求解模型的参数。根据已知条件,我们一般是使用极大似然估计,求出未知参数。总的来说:极大似然估计就是用来估计模型参数的统计学方法。
高斯分布
带入样本值然后取对数似然
然后我们分别对于以及
求偏导。
最后得出
即为样本均值,
为样本标准差。
这就是极大似然估计。
那么现在我们有100个男生和100个女生的身高,但是我们不知道这200个数据中哪个是男生的身高,哪个是女生的身高,即抽取得到的每个样本都不知道是从哪个分布中抽取的。这个时候,对于每个样本,就有两个未知量需要估计:
(1)这个身高数据是来自于男生数据集合还是来自于女生?
(2)男生、女生身高数据集的正态分布的参数分别是多少?
这个时候似然估计就不能用了,我们得使用EM算法。
算法推导
给定的训练样本是![]() ,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:
,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:

第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求![]() 一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
EM是一种解决存在隐含变量优化问题的有效方法。这里不能够直接最大化![]() ,我们可以不断地建立
,我们可以不断地建立![]() 的下界(E步),然后优化下界(M步)。如下图:
的下界(E步),然后优化下界(M步)。如下图:

横坐标是参数,纵坐标是似然函数,首先我们初始化一个θ1,根据它求似然函数一个紧的下界,也就是图中第一条黑短线,黑短线上的值虽然都小于似然函数的值,但至少有一点可以满足等号(所以称为紧下界),最大化小黑短线我们就hit到至少与似然函数刚好相等的位置,对应的横坐标就是我们的新的θ2,如此进行,只要保证随着θ的更新,每次最大化的小黑短线值都比上次的更大,那么算法收敛,最后就能最大化到似然函数的极大值处。
这里我们回想一下高数的Jenson不等式:
如果f是凸函数,X是随机变量,那么
![]()
特别地,如果f是严格凸函数,那么![]() 当且仅当
当且仅当![]() ,也就是说X是常量。
,也就是说X是常量。
这里我们将![]() 简写为
简写为![]() 。
。
如图所示:

构造上面那个图的小黑短线,就要靠Jensen不等式。注意我们这里的log函数是个凹函数,所以我们使用的Jensen不等式的凹函数版本。根据Jensen函数,需要把log里面的东西写成一个数学期望的形式,注意到log里的和是关于隐变量Z的和,于是自然而然,这个数学期望一定是和Z有关,如果设Q(z)是Z的分布函数,那么可以这样构造:
![]()
构造好数学期望,下一步根据Jensen不等式进行放缩:

有了这一步,我们看一下整个式子:

也就是说我们找到了似然函数的一个下界,那么优化它是否就可以呢?不是的,上面说了必须保证这个下界是紧的,也就是至少有点能使等号成立。由Jensen不等式,等式成立的条件是随机变量是常数,具体到这里,就是:
![]()
又因为Q(z)是z的分布函数,所以:
![]()
把C乘过去,可得C就是p(xi,z)对z求和,所以我们终于知道了:

得到Q(z),就是p(zi|xi),代表第i个数据是来自zi的概率。这一步就是E步,建立![]() 的下界。接下来的M步,就是在给定
的下界。接下来的M步,就是在给定![]() 后,调整
后,调整![]() ,去极大化
,去极大化![]() 的下界。所以一般的EM算法的步骤如下:
的下界。所以一般的EM算法的步骤如下:
循环重复直到收敛 {
(E步)对于每一个i,计算
![]()
(M步)计算

}
带入高斯混合模型
我们已经知道了推导了em算法的过程,再次审视一下混合高斯模型
E步很简单,按照一般EM公式得到:
![]()
简单解释就是每个样例i的隐含类别![]() 为j的概率可以通过后验概率计算得到。
为j的概率可以通过后验概率计算得到。
在M步中,我们需要在固定![]() 后最大化最大似然估计,也就是
后最大化最大似然估计,也就是

这是将![]() 的k种情况展开后的样子,未知参数
的k种情况展开后的样子,未知参数![]() 和
和![]() 。
。
固定![]() 和
和![]() ,对
,对![]() 求导得
求导得

等于0时,得到
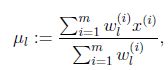
这就是我们之前模型中的![]() 的更新公式。
的更新公式。
然后推导![]() 的更新公式。看之前得到的
的更新公式。看之前得到的
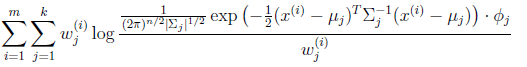
在![]() 和
和![]() 确定后,分子上面的一串都是常数了,实际上需要优化的公式是:
确定后,分子上面的一串都是常数了,实际上需要优化的公式是:
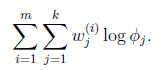
需要知道的是,![]() 还需要满足一定的约束条件就是
还需要满足一定的约束条件就是![]() 。
。
这个优化问题我们很熟悉了,直接构造拉格朗日乘子。
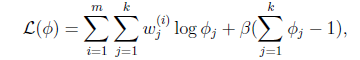
还有一点就是![]() ,但这一点会在得到的公式里自动满足。
,但这一点会在得到的公式里自动满足。
求导得,
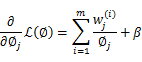
等于0,得到

也就是说![]() 再次使用
再次使用![]() ,得到
,得到
![]()
这样就神奇地得到了![]() 。
。
那么就顺势得到M步中![]() 的更新公式:
的更新公式:
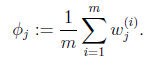
![]() 的推导也类似,结果为
的推导也类似,结果为
总结
如果将样本看作观察值,潜在类别看作是隐藏变量,那么聚类问题也就是参数估计问题,只不过聚类问题中参数分为隐含类别变量和其他参数,这犹如在x-y坐标系中找一个曲线的极值,然而曲线函数不能直接求导,因此什么梯度下降方法就不适用了。但固定一个变量后,另外一个可以通过求导得到,因此可以使用坐标上升法,一次固定一个变量,对另外的求极值,最后逐步逼近极值。
另外,EM的收敛性证明方法确实很牛,能够利用log的凹函数性质,还能够想到利用创造下界,拉平函数下界,优化下界的方法来逐步逼近极大值。而且每一步迭代都能保证是单调的。最重要的是证明的数学公式非常精妙,硬是分子分母都乘以z的概率变成期望来套上Jensen不等式。















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









