L(θ)=logP(Y;θ)=log∑zP(Y,Z;θ)=log∑zP(Y|Z;θ)P(Z;θ)(184)
(184)
L
(
θ
)
=
l
o
g
P
(
Y
;
θ
)
=
l
o
g
∑
z
P
(
Y
,
Z
;
θ
)
=
l
o
g
∑
z
P
(
Y
|
Z
;
θ
)
P
(
Z
;
θ
)
事实上,EM算法是通过迭代逐步极大化
L(θ)
L
(
θ
)
的。假设在第
i
i
次迭代后
θ
θ
的估计值是
θ(i)
θ
(
i
)
。我们希望新的估计值
θ
θ
能使
L(θ)
L
(
θ
)
增加,即
L(θ)>L(θ(i))
L
(
θ
)
>
L
(
θ
(
i
)
)
,并逐步达到极大值。为此考虑两者的差:
L(θ)−L(θ(i))=log(∑zP(Y|Z;θ)P(Z;θ))−logP(Y;θ(i))=log(∑zP(Z|Y;θ(i))P(Y|Z;θ)P(Z;θ)P(Z|Y;θ(i)))−logP(Y;θ(i))≥∑zP(Z|Y;θ(i))logP(Y|Z;θ)P(Z;θ)P(Z|Y;θ(i))−logP(Y;θ(i))=∑zP(Z|Y;θ(i))logP(Y|Z;θ)P(Z;θ)P(Z|Y;θ(i))P(Y;θ(i))(185)
(185)
L
(
θ
)
−
L
(
θ
(
i
)
)
=
l
o
g
(
∑
z
P
(
Y
|
Z
;
θ
)
P
(
Z
;
θ
)
)
−
l
o
g
P
(
Y
;
θ
(
i
)
)
=
l
o
g
(
∑
z
P
(
Z
|
Y
;
θ
(
i
)
)
P
(
Y
|
Z
;
θ
)
P
(
Z
;
θ
)
P
(
Z
|
Y
;
θ
(
i
)
)
)
−
l
o
g
P
(
Y
;
θ
(
i
)
)
≥
∑
z
P
(
Z
|
Y
;
θ
(
i
)
)
l
o
g
P
(
Y
|
Z
;
θ
)
P
(
Z
;
θ
)
P
(
Z
|
Y
;
θ
(
i
)
)
−
l
o
g
P
(
Y
;
θ
(
i
)
)
=
∑
z
P
(
Z
|
Y
;
θ
(
i
)
)
l
o
g
P
(
Y
|
Z
;
θ
)
P
(
Z
;
θ
)
P
(
Z
|
Y
;
θ
(
i
)
)
P
(
Y
;
θ
(
i
)
)
上式利用了Jensen不等式,在17-1式中, 令 φ
φ
为 log
l
o
g
, 且∑zP(Z|Y;θ(i))=1
∑
z
P
(
Z
|
Y
;
θ
(
i
)
)
=
1
,则可得上述推导。注意log
l
o
g
为凹函数,不等号要改变方向。
令
B(θ,θ(i))=L(θ(i))+∑zP(Y|Z;θ(i))logP(Y|Z;θ)P(Z;θ)P(Y|Z;θ(i))P(Y;θ(i)),(17−2)(186)
(186)
B
(
θ
,
θ
(
i
)
)
=
L
(
θ
(
i
)
)
+
∑
z
P
(
Y
|
Z
;
θ
(
i
)
)
l
o
g
P
(
Y
|
Z
;
θ
)
P
(
Z
;
θ
)
P
(
Y
|
Z
;
θ
(
i
)
)
P
(
Y
;
θ
(
i
)
)
,
(
17
−
2
)
则:
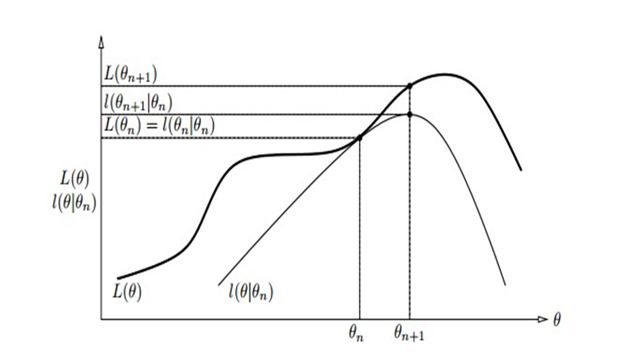
L(θ)≥B(θ,θ(i))(187)
(187)
L
(
θ
)
≥
B
(
θ
,
θ
(
i
)
)
那么,
B(θ,θ(i))
B
(
θ
,
θ
(
i
)
)
是
L(θ)
L
(
θ
)
的一个下界,由17-2知道:
L(θ(i))=B(θ(i),θ(i))(188)
(188)
L
(
θ
(
i
)
)
=
B
(
θ
(
i
)
,
θ
(
i
)
)
因此,任何可以使
B(θ,θ(i))
B
(
θ
,
θ
(
i
)
)
增大的
θ
θ
,都可使
L(θ)
L
(
θ
)
增大,选择
θ(i+1)
θ
(
i
+
1
)
使
B(θ,θ(i))
B
(
θ
,
θ
(
i
)
)
达到极大,即:
θ(i+1)=argmaxθB(θ,θ(i))(189)
(189)
θ
(
i
+
1
)
=
a
r
g
max
θ
B
(
θ
,
θ
(
i
)
)
现在求
θ(i+1)
θ
(
i
+
1
)
的表达式,省去对于
θ
θ
而言都是常数的项:
θ(i+1)=argmaxθ(L(θ(i))+∑zP(Y|Z;θ(i))logP(Y|Z;θ)P(Z;θ)P(Y|Z;θ(i))P(Y;θ(i)))=argmaxθ(∑zP(Y|Z;θ(i))logP(Y|Z;θ)P(Z;θ))=argmaxθ(∑zP(Y|Z;θ(i))logP(Y,Z;θ))=argmaxθQ(θ,θ(i))(190)
(190)
θ
(
i
+
1
)
=
a
r
g
max
θ
(
L
(
θ
(
i
)
)
+
∑
z
P
(
Y
|
Z
;
θ
(
i
)
)
l
o
g
P
(
Y
|
Z
;
θ
)
P
(
Z
;
θ
)
P
(
Y
|
Z
;
θ
(
i
)
)
P
(
Y
;
θ
(
i
)
)
)
=
a
r
g
max
θ
(
∑
z
P
(
Y
|
Z
;
θ
(
i
)
)
l
o
g
P
(
Y
|
Z
;
θ
)
P
(
Z
;
θ
)
)
=
a
r
g
max
θ
(
∑
z
P
(
Y
|
Z
;
θ
(
i
)
)
l
o
g
P
(
Y
,
Z
;
θ
)
)
=
a
r
g
max
θ
Q
(
θ
,
θ
(
i
)
)
























 2989
2989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









