







在通过声学振动进行物体感知方面,尽管以往的研究已经取得了一些有希望的结果,但目前的解决方案仍然受限于几个方面。首先,大多数现有研究集中在只有少数(N < 5)基本物体的受限设置上。这些物体通常具有均质材料组成,而且研究通常只涉及单指测试。此外,训练和测试通常在同一物体的不同接触点上进行,但这些测试结果是否适用于嘈杂且控制度较低的条件尚不清楚。
此外,以前的计算算法主要使用小型机器学习模型,并且训练数据量有限,难以泛化到更广泛的场景。还有,收集物体声学数据的交互机制依赖于人为手动移动或通过预定义的固定机器人姿态进行重放,这使得扩展到大量物体变得困难。
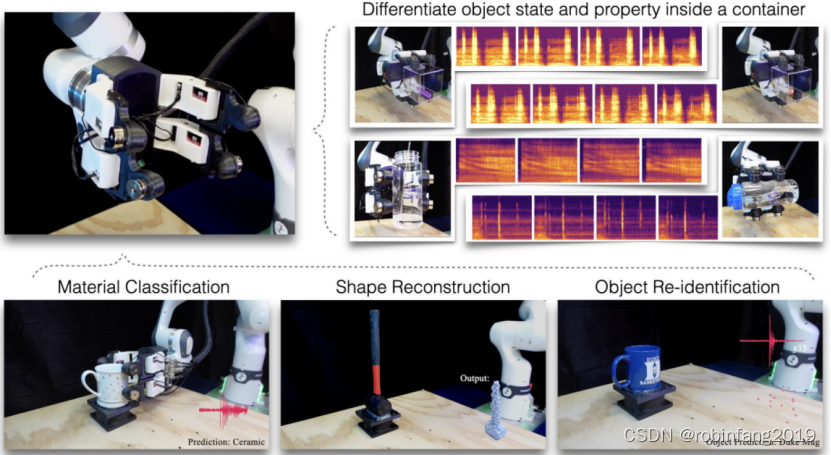
SonicSense,一套全面的硬件和软件设计,通过手持式声学振动传感技术,实现了丰富的机器人物体感知能力。SonicSense能够区分83种真实世界对象的容器库存状态,预测异质材料,重建3D形状,并从多样的物体中重新识别对象。系统采用了一种简单但有效的启发式探索策略与对象进行交互,以及端到端基于学习的算法,融合振动信号以推断物体属性。
源码:https://github.com/generalroboticslab/SonicSense
视频链接:https://www.youtube.com/watch?v=MvSYdLMsvx4
1 技术背景
1.1 触觉感知
触觉感知是指通过触觉传感器感知物体的属性,例如形状、材质和硬度等。现有的触觉传感器技术主要包括:
- 基于视觉的触觉传感器: 使用 RGB 摄像头和光源来检测机器人皮肤在接触时的变形。
- 基于气压的触觉传感器: 通过检测软弹性体和传感器之间空气或液体的压力变化来感知接触信息。
- 基于电容的触觉传感器: 监测静态和动态压力。
- 基于压阻的触觉传感器: 监测静态和动态压力。
- 基于磁场的触觉传感器: 通过磁场的变化来检测力。
- 基于热导率和温度的触觉传感器: 通过感知温度变化来识别材料和接触压力。
SonicSense 探索了使用声学振动作为另一种触觉感知模态。声学振动具有检测高频振动特征、低功耗、直观的机械和电气设计等优点。
1.2 声学感知
声学感知是指通过声学传感器感知物体的属性,例如液体高度、物体材质、物体类别、物体形状和姿态等。现有的声学感知技术主要包括:
- 空气麦克风: 主要捕捉通过空气传播的声音波,容易受到环境噪音的干扰。
- 接触麦克风: 只感知由物理接触产生的声学振动,能够获取更纯净的信号。
2 SonicSense 系统
2.1 工作原理
基于手部声学振动的对象感知是一种利用机器人手指上的接触麦克风捕捉物体与手指接触时产生的声波振动,从而获取物体属性的技术。SonicSense 系统是这一领域的代表,它通过分析声波振动信号,实现了对物体材质、形状和身份的识别和重建。
- 声波振动产生:当机器人手指敲击物体时,物体会产生声波振动。这些振动会传递到手指上的接触麦克风,并被转化为电信号。
- 声波振动捕捉:接触麦克风可以同步工作,以高采样率捕捉声波振动信号,并将其转化为数字信号。
- 声波振动分析:利用深度学习模型对声波振动信号进行分析,提取出能够表征物体属性的声学特征,例如频率、幅度、持续时间等。
- 物体属性识别:根据提取的声学特征,深度学习模型可以识别物体的材质、形状和身份等信息。
2.2 关键技术
- 接触麦克风:用于捕捉物体与手指接触时产生的声波振动信号。
- 深度学习模型:用于分析声波振动信号,提取声学特征,并识别物体属性。
- 启发式交互策略:用于指导机器人手与物体进行交互,以收集丰富的声波振动数据。
2.3 硬件设计
SonicSense系统中机器人机器人手有四个手指,每个手指有一个关节,一个自由度。直观的机械设计使手能够进行一系列用于物体感知的交互运动,包括敲击、抓取和摇晃动作。
在每个指尖,一个压电接触式麦克风嵌入在塑料外壳内部,而一个圆形的配重安装在外壳表面,以增加手指运动的动量。配重在敲击动作中发挥重要作用,能够使敲击振动最大化。接触式麦克风是同步的,能够以44,100赫兹的频率捕捉声学振动。
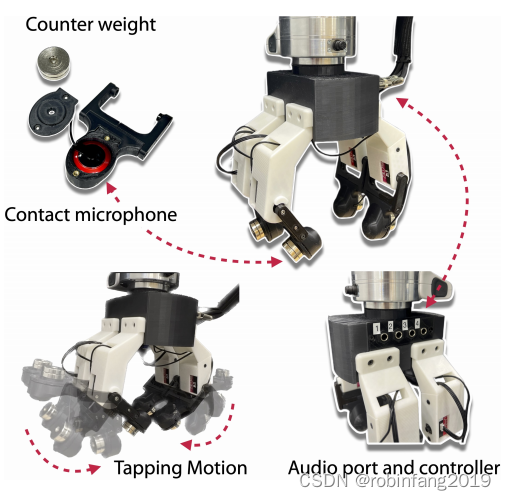
2.3.1 硬件配置详细信息
SonicSense 系统的机器人手部硬件配置简单且易于构建,主要包含以下几个部分:
2.3.1.1 机器手指
- 材料:使用聚乳酸 (PLA) 材料进行 3D 打印,具有较高的强度和韧性。
- 结构:每个手指由一个关节和一个自由度组成,可以完成敲击、抓取和摇动等动作。
- 尺寸:根据实际情况进行调整,以适应不同的物体尺寸和形状。
2.3.1.2 接触麦克风
- 类型:使用压电式接触麦克风,可以有效地捕捉物体与手指接触时产生的声波振动信号。
- 数量:每个手指配备一个接触麦克风,共四个麦克风。
- 安装:将接触麦克风嵌入手指的塑料外壳中,并与配重块配合使用,以提高敲击时的振动幅度。
2.3.1.3 配重块
- 材料:使用金属或其他重质材料制作。
- 重量:每个配重块约为 40 克。
- 作用:增加手指敲击时的动量,以产生更大的振动幅度。
2.3.1.4 电机
- 类型:使用 LX-224 伺服电机,具有高扭矩和准确的定位和电压反馈功能。
- 数量:每个手指配备一个电机,共四个电机。
- 作用:驱动手指进行运动,并检测手指与物体的接触事件。
2.3.1.5 控制器
- 类型:使用 TTL/USB 调试板作为电机控制器。
- 功能:控制电机运动,并接收电机电压反馈信号。
2.3.1.6 音频接口
- 类型:使用音频线连接接触麦克风和电脑。
- 功能:将声波振动信号传输到电脑进行后续处理。
2.3.1.7 3D 打印材料:
- 类型:使用 PLA 线材进行 3D 打印。
- 数量:根据手指的尺寸和数量进行调整。
2.3.2 CAD模型

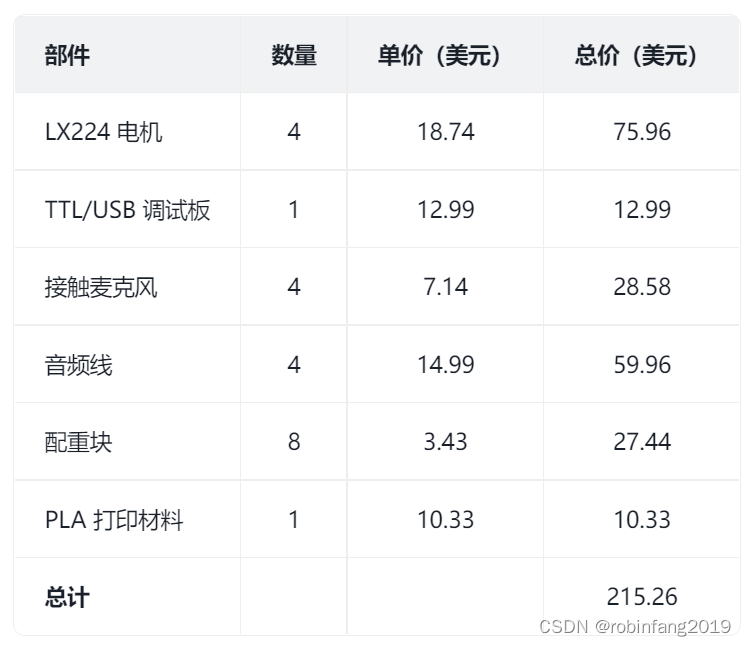
2.3.3 硬件成本
SonicSense 系统的硬件成本约为 215.26 美元,具体成本分配如下:
2.4 软件设计
使用 Python 语言进行编程,并使用 TensorFlow 或 PyTorch 深度学习框架进行模型训练。
- 启发式交互策略:机器人手通过简单的启发式规则与物体进行交互,例如从不同方向和高度进行敲击,以收集物体的声波振动特征。
- 深度学习模型:利用收集到的声波振动数据,训练深度学习模型,实现对物体材质、形状和身份的识别和重建。
- 端到端学习:系统采用了端到端的学习方法,将声波振动信号和接触点位置信息融合起来,以更准确地感知物体属性。
2.4.1 训练深度学习模型
SonicSense 系统的训练过程主要包括三个部分:材料分类模型训练、形状重建模型训练和物体重新识别模型训练。
2.4.1.1 材料分类模型训练
- 数据集:使用 82 个物体的敲击数据,每个物体都包含多个敲击位置和对应的声波振动信号。
- 模型架构:使用卷积神经网络 (CNN) 模型,包含三个卷积层和两个全连接层。
- 损失函数:使用交叉熵损失函数。
- 训练过程:
(1)将声波振动信号转换为梅尔频谱图。
(2)将梅尔频谱图输入 CNN 模型进行训练。
(3)使用真实标签进行监督学习,并计算损失函数。
(4)使用梯度下降算法更新模型参数,以最小化损失函数。
- 迭代优化:为了提高模型的准确率,使用迭代优化算法对模型预测结果进行修正,例如:
(1)过滤掉出现次数较少的预测结果。
(2)将预测结果重新分配给出现次数最多的标签。
(3)使用 K 近邻算法对每个预测点进行投票,并选择出现次数最多的标签作为最终预测结果。
2.4.1.2 形状重建模型训练
- 数据集:使用 83 个物体的敲击数据,每个物体都包含多个敲击位置和对应的声波振动信号。
- 模型架构:使用点云补全网络 (PCN) 模型,包含编码器和解码器两部分。
- 损失函数:使用 Chamfer 距离损失函数。
- 训练过程:
(1)将敲击位置信息输入 PCN 编码器进行编码。
(2)将编码后的特征向量输入解码器进行解码,生成完整的点云模型。
(3)使用真实点云模型计算 Chamfer 距离损失函数。
(4)使用梯度下降算法更新模型参数,以最小化 Chamfer 距离损失函数。
- 数据增强:为了提高模型的泛化能力,使用仿真环境生成额外的敲击数据,并将其与真实数据进行混合训练。
2.4.1.3 物体重新识别模型训练
- 数据集:使用 82 个物体的敲击数据,每个物体都包含多个敲击位置和对应的声波振动信号。
- 模型架构:使用多模态神经网络,包含音频编码器、接触点编码器和多层感知机 (MLP) 层。
- 损失函数:使用交叉熵损失函数。
- 训练过程:
(1)将声波振动信号和接触点位置信息分别输入音频编码器和接触点编码器进行编码。
(2)将编码后的特征向量输入 MLP 层进行融合。
(3)使用真实标签进行监督学习,并计算损失函数。
(4)使用梯度下降算法更新模型参数,以最小化损失函数。
2.4.2 数据采集与交互策略
SonicSense 的数据采集过程是使用其独特的四指机械手,通过接触麦克风捕捉物体在手掌中产生的声波振动。为了收集不同物体的数据,SonicSense 采用了一种基于启发式的交互策略,可以自主地与物体进行交互,并收集丰富的声波振动特征。
2.4.2.1 交互策略主要步骤
2.4.2.1.1 初始探索
- 机器人首先尝试从顶部和侧面两个方向,以及从高到低的不同高度进行接触,直到从每个方向检测到第一次接触事件。
- 通过电机提供的电压反馈或声波信号变化来检测接触事件。
2.4.2.1.2 物体尺寸估计
- 从顶部方向检测到的第一次接触事件可以估计物体的高度。
- 从侧面方向检测到的第一次接触事件可以估计物体的半径。
2.4.2.1.3 网格采样
基于估计的物体高度和半径,机器人使用网格采样策略进行稀疏接触,以收集物体的声波振动响应。
2.4.2.2 交互策略的假设
- 物体的最大高度是已知的。
- 物体可以被机器人手握住进行敲击。
- 物体被固定在桌面上。
2.4.3 声学振动信号的记录和处理方法
2.4.3.1 记录
- 使用接触麦克风记录 5 秒的敲击声波振动信号。
- 将敲击声波振动信号保存在文本文件中,并附带接触点位置信息。
2.4.3.2 处理
2.4.3.2.1 信号提取
- 使用窗口滑动机制提取敲击声波振动信号。窗口大小为 1000 个声波波形单位,滑动步长为 1 个声波波形单位。
- 根据窗口内的平均绝对幅度,判断是否为有效的敲击信号。如果当前窗口的平均幅度大于前后窗口的平均幅度,则认为是一个有效的敲击信号,并提取该窗口周围的 20000 个声波波形单位作为敲击信号。
- 对于没有明显敲击信号的物体,例如泡沫物体,同样使用窗口滑动机制提取信号,但提取到的信号通常为电机噪声,这也被视为一种特征。
2.4.3.2.2 特征提取
- 将提取到的敲击声波振动信号转换为梅尔频谱图 (Mel-spectrogram) 表示,大小为 64 × 64。
- 使用快速傅里叶变换 (FFT) 将声波波形转换为频谱图,FFT 窗口大小为 2048,梅尔滤波器数量为 64,最高频率限制为 8192 Hz。
- 将连续的音频样本数量四舍五入到 64 的倍数,以保证梅尔频谱图在时间维度上的正确尺寸。
3 数据集
SonicSense 使用一个包含83个多样化真实世界对象的数据集。
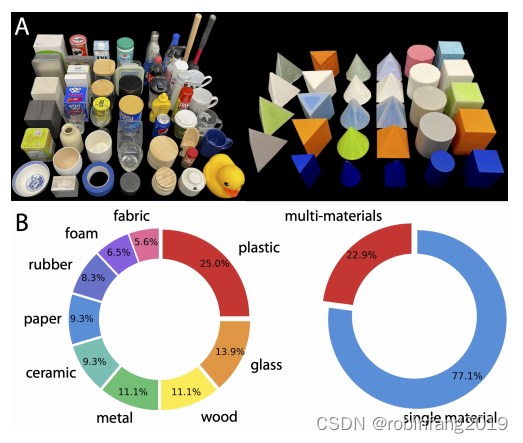
3.1 数据集的组成
- 对象:54个日常对象和29个3D打印的原始对象,它们的表面附着有不同的材料。
- 材料类别:包括塑料、玻璃、木头、金属、陶瓷、纸张、橡胶、泡沫和织物等九种材料。
- 材料多样性:数据集中22.9%的对象包含不止一种材料,这增加了感知任务的复杂性。
3.2 数据集内容
- 每个物体都提供了高质量的 3D 扫描网格和点云模型。
- 点云模型具有细粒度的材料类别逐点标注。
- 物体涵盖了各种几何形状,从简单的原始形状到复杂的形状,从小型物体到大型或长型物体。
- 数据集还包括了视觉传感器难以感知的物体,例如具有透明或反射表面的物体。
3.3 数据集的创建
数据集的创建涉及到收集、扫描和注释83个真实世界对象。这些对象被选中以确保它们在材料和形状上的多样性,以及它们对现有感知技术的挑战性。数据集的创建过程包括:
- 选择对象:选择具有代表性的日常对象和3D打印对象。
- 3D扫描:使用高精度3D扫描技术捕捉对象的形状。
- 点云生成:从3D扫描数据生成点云模型。
- 材料注释:对点云模型上的每个点进行材料类别注释。
- 数据整理:将数据组织成适合机器学习模型训练的格式。
3.4 数据集的应用
数据集用于训练 SonicSense 的三个模型:
- 材料分类模型:根据敲击声波振动信号预测接触位置的材质类别。
- 形状重建模型:根据稀疏的接触点生成物体的完整和完整的 3D 形状。
- 物体重新识别模型:根据新的敲击声波振动信号和接触点位置预测物体的类别。
4 实验结果
SonicSense 在三个主要的物体感知任务上进行了实验,并取得了不错的成果:
4.1 基本感知能力表征
- 抗环境噪声: 与外部空气麦克风相比,对环境噪声具有很强的抵抗力,可以有效地捕捉通过物理接触产生的声波振动信号。
- 容器内物体状态区分:可以通过声波振动信号区分容器内固体和液体物体的状态,例如数量、形状和液位。
4.2 材料分类
- 准确率:材料分类模型在测试集上达到了 0.763 的平均 F1 分数,显著优于随机搜索和最近邻基线方法。
- 可解释性: 通过 t-SNE 可视化,可以看出 SonicSense 可以将不同材料的声波振动特征区分开来,即使是难以区分的泡沫和织物材料。
- 局限性: 在预测塑料材料时存在一定的挑战,因为塑料材料的厚度和刚度差异较大。
4.3 形状重建
- 准确率: 形状重建模型可以从稀疏的接触点生成物体的完整和完整的 3D 形状,平均 Chamfer-L1 距离为 0.00876 米,显著优于随机搜索和最近邻基线方法。
- 泛化能力: 形状重建模型可以很好地泛化到未见过的物体形状,包括具有凹形几何形状的物体。
- 局限性: 在预测具有复杂形状的物体时可能存在一定的挑战,例如喷雾瓶的喷嘴和瓶盖。
4.4 物体重新识别
- 准确率: SonicSense 的物体重新识别模型可以准确地识别之前交互过的物体,测试集准确率为 92.52%,显著优于随机搜索和最近邻基线方法。
- 多模态信息融合: 实验表明,声波振动信息和接触点位置信息都对物体重新识别任务至关重要,融合两种信息可以进一步提高模型的性能。
4.5 实验结果的优势
- 在多种物体感知任务上取得了优异的性能,证明了其有效性。
- 设计具有鲁棒性,可以抵抗环境噪声的影响。
- 交互策略可以自主地与物体进行交互,无需人工干预。
4.6 实验结果的局限性
- 模型训练依赖于大量数据,可能存在过拟合的风险。
- 交互策略基于启发式方法,可能无法适应所有类型的物体和场景。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









