







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
一、设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0]
tf.config.experimental.set_memory_growth(gpu0, True)
tf.config.set_visible_devices([gpu0],"GPU")
from tensorflow import keras
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import warnings,os,PIL,pathlib
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
二、导入数据
1.导入数据
data_dir = "./your_destination_folder/48-data/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
输出
图片总数为: 1800
batch_size = 16
img_height = 336
img_width = 336
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
输出
Found 1800 files belonging to 17 classes.
Using 1440 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
输出
Found 1800 files belonging to 17 classes.
Using 360 files for validation.
class_names = train_ds.class_names
print(class_names)
输出
[‘Angelina Jolie’, ‘Brad Pitt’, ‘Denzel Washington’, ‘Hugh Jackman’, ‘Jennifer Lawrence’, ‘Johnny Depp’, ‘Kate Winslet’, ‘Leonardo DiCaprio’, ‘Megan Fox’, ‘Natalie Portman’, ‘Nicole Kidman’, ‘Robert Downey Jr’, ‘Sandra Bullock’, ‘Scarlett Johansson’, ‘Tom Cruise’, ‘Tom Hanks’, ‘Will Smith’]
2.检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
输出
(16, 336, 336, 3)
(16,)
Selection deleted
3.配置数据集
AUTOTUNE = tf.data.AUTOTUNE
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
.shuffle(1000)
.map(train_preprocessing)
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
.shuffle(1000)
.map(train_preprocessing)
.prefetch(buffer_size=AUTOTUNE)
)
4.数据可视化
plt.figure(figsize=(10, 8))
plt.suptitle("数据展示")
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(images[i])
plt.xlabel(class_names[labels[i]-1])
plt.show()
输出

三、构建模型
from tensorflow.keras.layers import Dropout,Dense,BatchNormalization
from tensorflow.keras.models import Model
def create_model(optimizer='adam'):
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
for layer in vgg16_base_model.layers:
layer.trainable = False
X = vgg16_base_model.output
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return vgg16_model
model1 = create_model(optimizer=tf.keras.optimizers.Adam())
model2 = create_model(optimizer=tf.keras.optimizers.SGD())
model2.summary()
输出

四、训练模型
NO_EPOCHS = 50
history_model1 = model1.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
history_model2 = model2.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
模型一输出
Epoch 1/50
90/90 [] - 24s 78ms/step - loss: 2.7856 -
accuracy: 0.1660 - val_loss: 2.7508 - val_accuracy: 0.0639 Epoch 2/50
90/90 [] - 6s 57ms/step - loss: 2.1150 -
accuracy: 0.3389 - val_loss: 2.4923 - val_accuracy: 0.2278 Epoch 3/50
90/90 [] - 5s 58ms/step - loss: 1.7961 -
accuracy: 0.4104 - val_loss: 2.2895 - val_accuracy: 0.3500 Epoch 4/50
90/90 [] - 6s 61ms/step - loss: 1.5623 -
accuracy: 0.5153 - val_loss: 2.0401 - val_accuracy: 0.3694 Epoch 5/50
90/90 [] - 5s 58ms/step - loss: 1.3805 -
accuracy: 0.5736 - val_loss: 1.8080 - val_accuracy: 0.4333 Epoch 6/50
90/90 [] - 5s 57ms/step - loss: 1.3064 -
accuracy: 0.5965 - val_loss: 1.8183 - val_accuracy: 0.3861 Epoch 7/50
90/90 [] - 5s 59ms/step - loss: 1.1690 -
accuracy: 0.6333 - val_loss: 1.6658 - val_accuracy: 0.4639 Epoch 8/50
90/90 [] - 5s 60ms/step - loss: 1.0356 -
accuracy: 0.6924 - val_loss: 1.6668 - val_accuracy: 0.4833 Epoch 9/50
90/90 [] - 5s 59ms/step - loss: 1.0083 -
accuracy: 0.6944 - val_loss: 1.5115 - val_accuracy: 0.5278 Epoch 10/50
90/90 [] - 5s 59ms/step - loss: 0.8850 -
accuracy: 0.7396 - val_loss: 1.5643 - val_accuracy: 0.5083 Epoch 11/50
90/90 [] - 5s 58ms/step - loss: 0.8504 -
accuracy: 0.7403 - val_loss: 1.6751 - val_accuracy: 0.4806 Epoch 12/50
90/90 [] - 5s 59ms/step - loss: 0.7890 -
accuracy: 0.7569 - val_loss: 1.3592 - val_accuracy: 0.5778 Epoch 13/50
90/90 [] - 5s 59ms/step - loss: 0.7292 -
accuracy: 0.7896 - val_loss: 1.7843 - val_accuracy: 0.5222 Epoch 14/50
90/90 [] - 6s 60ms/step - loss: 0.6753 -
accuracy: 0.7965 - val_loss: 1.9054 - val_accuracy: 0.4528 Epoch 15/50
90/90 [] - 5s 59ms/step - loss: 0.6197 -
accuracy: 0.8167 - val_loss: 1.8496 - val_accuracy: 0.4806 Epoch 16/50
90/90 [] - 5s 58ms/step - loss: 0.5893 -
accuracy: 0.8215 - val_loss: 1.4938 - val_accuracy: 0.5333 Epoch 17/50
90/90 [] - 5s 57ms/step - loss: 0.5628 -
accuracy: 0.8285 - val_loss: 1.5424 - val_accuracy: 0.5417 Epoch 18/50
90/90 [] - 5s 56ms/step - loss: 0.4938 -
accuracy: 0.8604 - val_loss: 1.7571 - val_accuracy: 0.4917 Epoch 19/50
90/90 [] - 5s 58ms/step - loss: 0.4997 -
accuracy: 0.8514 - val_loss: 1.9083 - val_accuracy: 0.5083 Epoch 20/50
90/90 [] - 5s 58ms/step - loss: 0.4615 -
accuracy: 0.8681 - val_loss: 1.6543 - val_accuracy: 0.5389 Epoch 21/50
90/90 [] - 6s 62ms/step - loss: 0.4641 -
accuracy: 0.8611 - val_loss: 1.7919 - val_accuracy: 0.5333 Epoch 22/50
90/90 [] - 5s 56ms/step - loss: 0.4310 -
accuracy: 0.8681 - val_loss: 2.0384 - val_accuracy: 0.4833 Epoch 23/50
90/90 [] - 5s 57ms/step - loss: 0.4098 -
accuracy: 0.8764 - val_loss: 1.9465 - val_accuracy: 0.5194 Epoch 24/50
90/90 [] - 5s 56ms/step - loss: 0.3782 -
accuracy: 0.8826 - val_loss: 2.4274 - val_accuracy: 0.4917 Epoch 25/50
90/90 [] - 5s 57ms/step - loss: 0.3812 -
accuracy: 0.8764 - val_loss: 2.1823 - val_accuracy: 0.4361 Epoch 26/50
90/90 [] - 5s 58ms/step - loss: 0.3566 -
accuracy: 0.8924 - val_loss: 2.1411 - val_accuracy: 0.4750 Epoch 27/50
90/90 [] - 5s 56ms/step - loss: 0.3283 -
accuracy: 0.8993 - val_loss: 1.8001 - val_accuracy: 0.5556 Epoch 28/50
90/90 [] - 5s 59ms/step - loss: 0.3526 -
accuracy: 0.8882 - val_loss: 2.1273 - val_accuracy: 0.4806 Epoch 29/50
90/90 [] - 5s 58ms/step - loss: 0.3519 -
accuracy: 0.8917 - val_loss: 2.0265 - val_accuracy: 0.4583 Epoch 30/50
90/90 [] - 5s 56ms/step - loss: 0.3037 -
accuracy: 0.9111 - val_loss: 2.0515 - val_accuracy: 0.4944 Epoch 31/50
90/90 [] - 6s 61ms/step - loss: 0.2959 -
accuracy: 0.9083 - val_loss: 2.1837 - val_accuracy: 0.5056 Epoch 32/50
90/90 [] - 5s 59ms/step - loss: 0.2994 -
accuracy: 0.9083 - val_loss: 2.0027 - val_accuracy: 0.5056 Epoch 33/50
90/90 [] - 5s 57ms/step - loss: 0.2769 -
accuracy: 0.9118 - val_loss: 2.3034 - val_accuracy: 0.4861 Epoch 34/50
90/90 [] - 5s 58ms/step - loss: 0.2822 -
accuracy: 0.9181 - val_loss: 2.0137 - val_accuracy: 0.5250 Epoch 35/50
90/90 [] - 5s 58ms/step - loss: 0.2659 -
accuracy: 0.9236 - val_loss: 1.8804 - val_accuracy: 0.5333 Epoch 36/50
90/90 [] - 5s 58ms/step - loss: 0.2696 -
accuracy: 0.9104 - val_loss: 1.8322 - val_accuracy: 0.5722 Epoch 37/50
90/90 [] - 5s 58ms/step - loss: 0.2549 -
accuracy: 0.9194 - val_loss: 2.1090 - val_accuracy: 0.5194 Epoch 38/50
90/90 [] - 5s 57ms/step - loss: 0.2343 -
accuracy: 0.9229 - val_loss: 2.1668 - val_accuracy: 0.4861 Epoch 39/50
90/90 [] - 5s 58ms/step - loss: 0.2410 -
accuracy: 0.9174 - val_loss: 1.9706 - val_accuracy: 0.5556 Epoch 40/50
90/90 [] - 5s 59ms/step - loss: 0.2318 -
accuracy: 0.9306 - val_loss: 2.1206 - val_accuracy: 0.5528 Epoch 41/50
90/90 [] - 5s 57ms/step - loss: 0.2270 -
accuracy: 0.9312 - val_loss: 1.7432 - val_accuracy: 0.5694 Epoch 42/50
90/90 [] - 5s 58ms/step - loss: 0.2215 -
accuracy: 0.9312 - val_loss: 2.0854 - val_accuracy: 0.5778 Epoch 43/50
90/90 [] - 5s 58ms/step - loss: 0.2027 -
accuracy: 0.9347 - val_loss: 1.9420 - val_accuracy: 0.6000 Epoch 44/50
90/90 [] - 5s 57ms/step - loss: 0.2294 -
accuracy: 0.9222 - val_loss: 1.9545 - val_accuracy: 0.5917 Epoch 45/50
90/90 [] - 5s 56ms/step - loss: 0.2120 -
accuracy: 0.9326 - val_loss: 2.0864 - val_accuracy: 0.5250 Epoch 46/50
90/90 [] - 5s 56ms/step - loss: 0.1977 -
accuracy: 0.9410 - val_loss: 2.2968 - val_accuracy: 0.5500 Epoch 47/50
90/90 [] - 5s 57ms/step - loss: 0.2447 -
accuracy: 0.9201 - val_loss: 2.6941 - val_accuracy: 0.4639 Epoch 48/50
90/90 [] - 5s 58ms/step - loss: 0.2202 -
accuracy: 0.9229 - val_loss: 2.4699 - val_accuracy: 0.5361 Epoch 49/50
90/90 [] - 5s 57ms/step - loss: 0.1962 -
accuracy: 0.9396 - val_loss: 2.1505 - val_accuracy: 0.5528 Epoch 50/50
90/90 [] - 5s 58ms/step - loss: 0.2030 -
accuracy: 0.9326 - val_loss: 2.1061 - val_accuracy: 0.5583模型二输出
Epoch 1/50
90/90 [] - 6s 59ms/step - loss: 3.1041 -
accuracy: 0.1125 - val_loss: 2.7769 - val_accuracy: 0.0694 Epoch 2/50
90/90 [] - 5s 58ms/step - loss: 2.5121 -
accuracy: 0.2215 - val_loss: 2.6077 - val_accuracy: 0.2222 Epoch 3/50
90/90 [] - 5s 58ms/step - loss: 2.2546 -
accuracy: 0.2847 - val_loss: 2.4059 - val_accuracy: 0.2972 Epoch 4/50
90/90 [] - 5s 57ms/step - loss: 2.0651 -
accuracy: 0.3347 - val_loss: 2.2405 - val_accuracy: 0.2639 Epoch 5/50
90/90 [] - 5s 57ms/step - loss: 1.9176 -
accuracy: 0.3854 - val_loss: 2.0221 - val_accuracy: 0.3556 Epoch 6/50
90/90 [] - 5s 57ms/step - loss: 1.8190 -
accuracy: 0.4035 - val_loss: 1.9543 - val_accuracy: 0.3694 Epoch 7/50
90/90 [] - 5s 56ms/step - loss: 1.7365 -
accuracy: 0.4444 - val_loss: 1.8517 - val_accuracy: 0.4028 Epoch 8/50
90/90 [] - 5s 59ms/step - loss: 1.6375 -
accuracy: 0.4729 - val_loss: 1.7418 - val_accuracy: 0.4417 Epoch 9/50
90/90 [] - 5s 58ms/step - loss: 1.5626 -
accuracy: 0.4889 - val_loss: 1.8753 - val_accuracy: 0.4194 Epoch 10/50
90/90 [] - 5s 56ms/step - loss: 1.5276 -
accuracy: 0.5097 - val_loss: 1.6878 - val_accuracy: 0.4361 Epoch 11/50
90/90 [] - 5s 56ms/step - loss: 1.4268 -
accuracy: 0.5528 - val_loss: 1.6401 - val_accuracy: 0.4722 Epoch 12/50
90/90 [] - 5s 56ms/step - loss: 1.3737 -
accuracy: 0.5667 - val_loss: 1.6301 - val_accuracy: 0.4667 Epoch 13/50
90/90 [] - 5s 57ms/step - loss: 1.3213 -
accuracy: 0.5840 - val_loss: 1.5930 - val_accuracy: 0.4778 Epoch 14/50
90/90 [] - 5s 55ms/step - loss: 1.2938 -
accuracy: 0.5965 - val_loss: 1.4937 - val_accuracy: 0.5056 Epoch 15/50
90/90 [] - 5s 58ms/step - loss: 1.2676 -
accuracy: 0.5938 - val_loss: 1.4787 - val_accuracy: 0.5111 Epoch 16/50
90/90 [] - 5s 56ms/step - loss: 1.1868 -
accuracy: 0.6299 - val_loss: 1.5260 - val_accuracy: 0.4889 Epoch 17/50
90/90 [] - 5s 58ms/step - loss: 1.1583 -
accuracy: 0.6403 - val_loss: 1.5469 - val_accuracy: 0.5028 Epoch 18/50
90/90 [] - 5s 57ms/step - loss: 1.1384 -
accuracy: 0.6382 - val_loss: 1.4275 - val_accuracy: 0.5167 Epoch 19/50
90/90 [] - 5s 57ms/step - loss: 1.1009 -
accuracy: 0.6556 - val_loss: 1.4587 - val_accuracy: 0.5389 Epoch 20/50
90/90 [] - 5s 57ms/step - loss: 1.0574 -
accuracy: 0.6708 - val_loss: 1.5024 - val_accuracy: 0.5028 Epoch 21/50
90/90 [] - 5s 58ms/step - loss: 1.0593 -
accuracy: 0.6674 - val_loss: 1.4781 - val_accuracy: 0.5278 Epoch 22/50
90/90 [] - 5s 57ms/step - loss: 1.0196 -
accuracy: 0.6826 - val_loss: 1.3585 - val_accuracy: 0.5222 Epoch 23/50
90/90 [] - 5s 57ms/step - loss: 0.9827 -
accuracy: 0.6875 - val_loss: 1.4102 - val_accuracy: 0.5278 Epoch 24/50
90/90 [] - 5s 58ms/step - loss: 0.9575 -
accuracy: 0.6889 - val_loss: 1.4669 - val_accuracy: 0.5083 Epoch 25/50
90/90 [] - 5s 58ms/step - loss: 0.9507 -
accuracy: 0.6958 - val_loss: 1.3680 - val_accuracy: 0.5139 Epoch 26/50
90/90 [] - 5s 56ms/step - loss: 0.9030 -
accuracy: 0.7035 - val_loss: 1.3000 - val_accuracy: 0.5333 Epoch 27/50
90/90 [] - 5s 57ms/step - loss: 0.8837 -
accuracy: 0.7250 - val_loss: 1.3623 - val_accuracy: 0.5361 Epoch 28/50
90/90 [] - 5s 56ms/step - loss: 0.8505 -
accuracy: 0.7285 - val_loss: 1.4210 - val_accuracy: 0.5472 Epoch 29/50
90/90 [] - 5s 56ms/step - loss: 0.8733 -
accuracy: 0.7208 - val_loss: 1.4673 - val_accuracy: 0.5389 Epoch 30/50
90/90 [] - 5s 57ms/step - loss: 0.8252 -
accuracy: 0.7583 - val_loss: 1.4986 - val_accuracy: 0.5194 Epoch 31/50
90/90 [] - 5s 58ms/step - loss: 0.8437 -
accuracy: 0.7319 - val_loss: 1.3379 - val_accuracy: 0.5611 Epoch 32/50
90/90 [] - 5s 56ms/step - loss: 0.8071 -
accuracy: 0.7396 - val_loss: 1.4895 - val_accuracy: 0.5472 Epoch 33/50
90/90 [] - 5s 56ms/step - loss: 0.7653 -
accuracy: 0.7729 - val_loss: 1.4544 - val_accuracy: 0.5639 Epoch 34/50
90/90 [] - 5s 56ms/step - loss: 0.7818 -
accuracy: 0.7660 - val_loss: 1.5019 - val_accuracy: 0.5167 Epoch 35/50
90/90 [] - 5s 57ms/step - loss: 0.7729 -
accuracy: 0.7646 - val_loss: 1.3545 - val_accuracy: 0.5111 Epoch 36/50
90/90 [] - 5s 56ms/step - loss: 0.7680 -
accuracy: 0.7493 - val_loss: 1.4063 - val_accuracy: 0.5361 Epoch 37/50
90/90 [] - 5s 57ms/step - loss: 0.7019 -
accuracy: 0.7778 - val_loss: 1.5746 - val_accuracy: 0.5111 Epoch 38/50
90/90 [] - 5s 57ms/step - loss: 0.6869 -
accuracy: 0.7896 - val_loss: 1.4777 - val_accuracy: 0.5611 Epoch 39/50
90/90 [] - 5s 57ms/step - loss: 0.6672 -
accuracy: 0.7986 - val_loss: 1.6254 - val_accuracy: 0.5111 Epoch 40/50
90/90 [] - 5s 56ms/step - loss: 0.6871 -
accuracy: 0.7688 - val_loss: 1.7054 - val_accuracy: 0.4917 Epoch 41/50
90/90 [] - 5s 57ms/step - loss: 0.6942 -
accuracy: 0.7757 - val_loss: 1.5495 - val_accuracy: 0.5444 Epoch 42/50
90/90 [] - 5s 58ms/step - loss: 0.6465 -
accuracy: 0.8007 - val_loss: 1.5489 - val_accuracy: 0.5417 Epoch 43/50
90/90 [] - 5s 57ms/step - loss: 0.6423 -
accuracy: 0.8035 - val_loss: 1.3965 - val_accuracy: 0.5750 Epoch 44/50
90/90 [] - 5s 57ms/step - loss: 0.5986 -
accuracy: 0.8229 - val_loss: 1.3720 - val_accuracy: 0.5778 Epoch 45/50
90/90 [] - 5s 57ms/step - loss: 0.6216 -
accuracy: 0.8104 - val_loss: 1.4035 - val_accuracy: 0.5528 Epoch 46/50
90/90 [] - 5s 58ms/step - loss: 0.6074 -
accuracy: 0.8118 - val_loss: 1.5912 - val_accuracy: 0.5472 Epoch 47/50
90/90 [] - 5s 56ms/step - loss: 0.5494 -
accuracy: 0.8292 - val_loss: 1.4795 - val_accuracy: 0.5444 Epoch 48/50
90/90 [] - 5s 57ms/step - loss: 0.5568 -
accuracy: 0.8319 - val_loss: 1.5495 - val_accuracy: 0.5306 Epoch 49/50
90/90 [] - 5s 57ms/step - loss: 0.5651 -
accuracy: 0.8229 - val_loss: 1.3749 - val_accuracy: 0.5611 Epoch 50/50
90/90 [] - 5s 58ms/step - loss: 0.5561 -
accuracy: 0.8285 - val_loss: 1.5736 - val_accuracy: 0.5278
五、评估模型
1.Accuracy和Loss图
from matplotlib.ticker import MultipleLocator
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['figure.dpi'] = 300
acc1 = history_model1.history['accuracy']
acc2 = history_model2.history['accuracy']
val_acc1 = history_model1.history['val_accuracy']
val_acc2 = history_model2.history['val_accuracy']
loss1 = history_model1.history['loss']
loss2 = history_model2.history['loss']
val_loss1 = history_model1.history['val_loss']
val_loss2 = history_model2.history['val_loss']
epochs_range = range(len(acc1))
plt.figure(figsize=(16, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc1, label='Training Accuracy-Adam')
plt.plot(epochs_range, acc2, label='Training Accuracy-SGD')
plt.plot(epochs_range, val_acc1, label='Validation Accuracy-Adam')
plt.plot(epochs_range, val_acc2, label='Validation Accuracy-SGD')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss1, label='Training Loss-Adam')
plt.plot(epochs_range, loss2, label='Training Loss-SGD')
plt.plot(epochs_range, val_loss1, label='Validation Loss-Adam')
plt.plot(epochs_range, val_loss2, label='Validation Loss-SGD')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.show()
输出
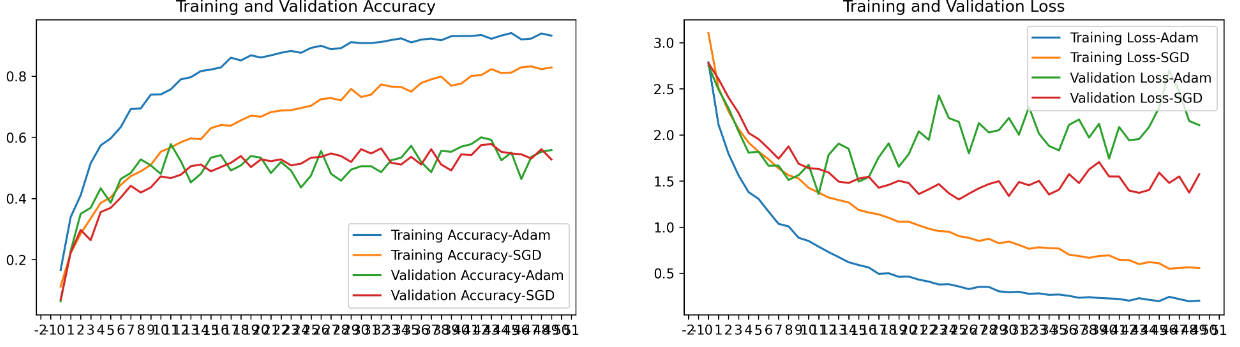
**这个图我们可以直观的看出来使用Adam和SGD两种优化器对训练数据的影响,也直观的看出为什么一般用Adam就是比较好的选择,SGD随机性太强,震荡过于严重,得出的结果数据不好,容易陷入局部最优解;而Adam作为动量法的精华,使得参数比较平稳。但是根本的原则还是根据实际情况选择,SGD也有比较好的应用场景。凡事不能绝对。 **
2.模型评估
def test_accuracy_report(model):
score = model.evaluate(val_ds, verbose=0)
print('Loss function: %s, accuracy:' % score[0], score[1])
test_accuracy_report(model2)
输出
Loss function: 1.5736452341079712, accuracy: 0.5277777910232544















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









