







发表时间:CORL 2024 (Best paper)
论文链接:https://readpaper.com/pdf-annotate/note?pdfId=2476642985732261376¬eId=2480092969164874752
作者单位:Stanford University(Li Fei-Fei)
Motivation:将机器人操作任务表示为关联机器人和环境的约束,是编码所需机器人行为的一种有前途的方法。然而,目前尚不清楚如何制定约束,使它们 1) 适用于不同的任务,2) 无需手动标记,以及 3) 由现成的求解器可实时生成机器人动作。
解决方法:具体来说,ReKep 表示为 Python 函数,将环境中的一组 3D 关键点映射到数值成本。我们证明了通过将操作任务表示为一系列关系关键点约束,我们可以使用分层优化过程来解决机器人动作(由 SE(3) 中的末端执行器姿势序列表示),并以实时频率感知-动作循环。
在机器人学中,SE(3) 常用于描述机器人的末端执行器(如机械臂的末端)的运动。末端执行器的姿势序列可以由一系列 SE(3) 变换矩阵表示,这些变换矩阵描述了末端执行器在不同时间点的位置和方向。(即SE3是末端位姿)
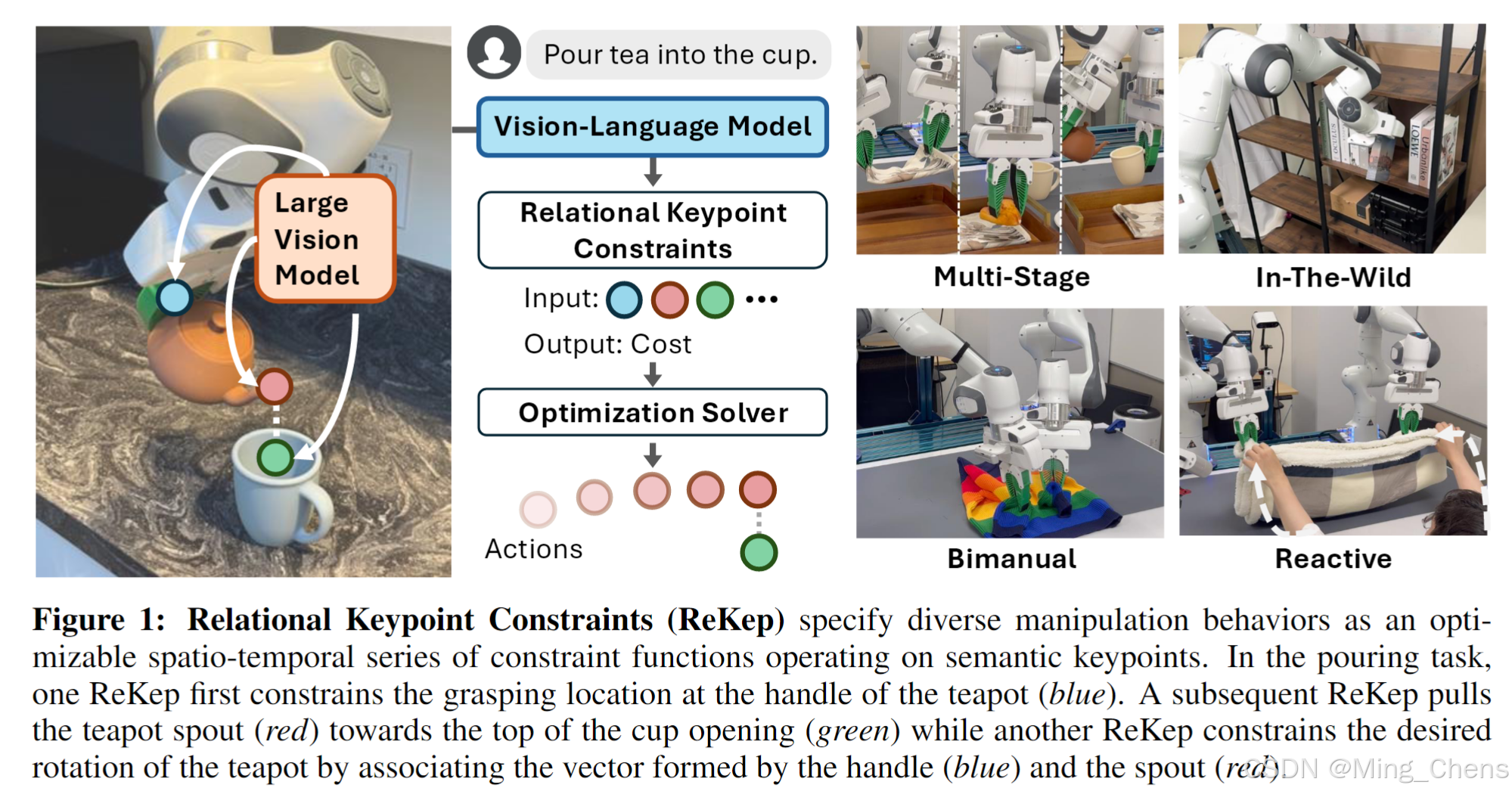 我们的贡献总结如下:
我们的贡献总结如下:
1)我们将操作任务制定为具有关系关键点约束的分层优化问题;
2)我们设计了一个管道,使用大型视觉模型和视觉语言模型自动指定关键点和约束;
3)我们在两个真实机器人平台上展示了系统实现,该平台将语言指令和 RGB-D 观察作为输入,并为各种操作任务生成多阶段、野外、双手动和反应行为,所有这些都没有特定于任务的数据或环境模型。
实现方式:结构如下: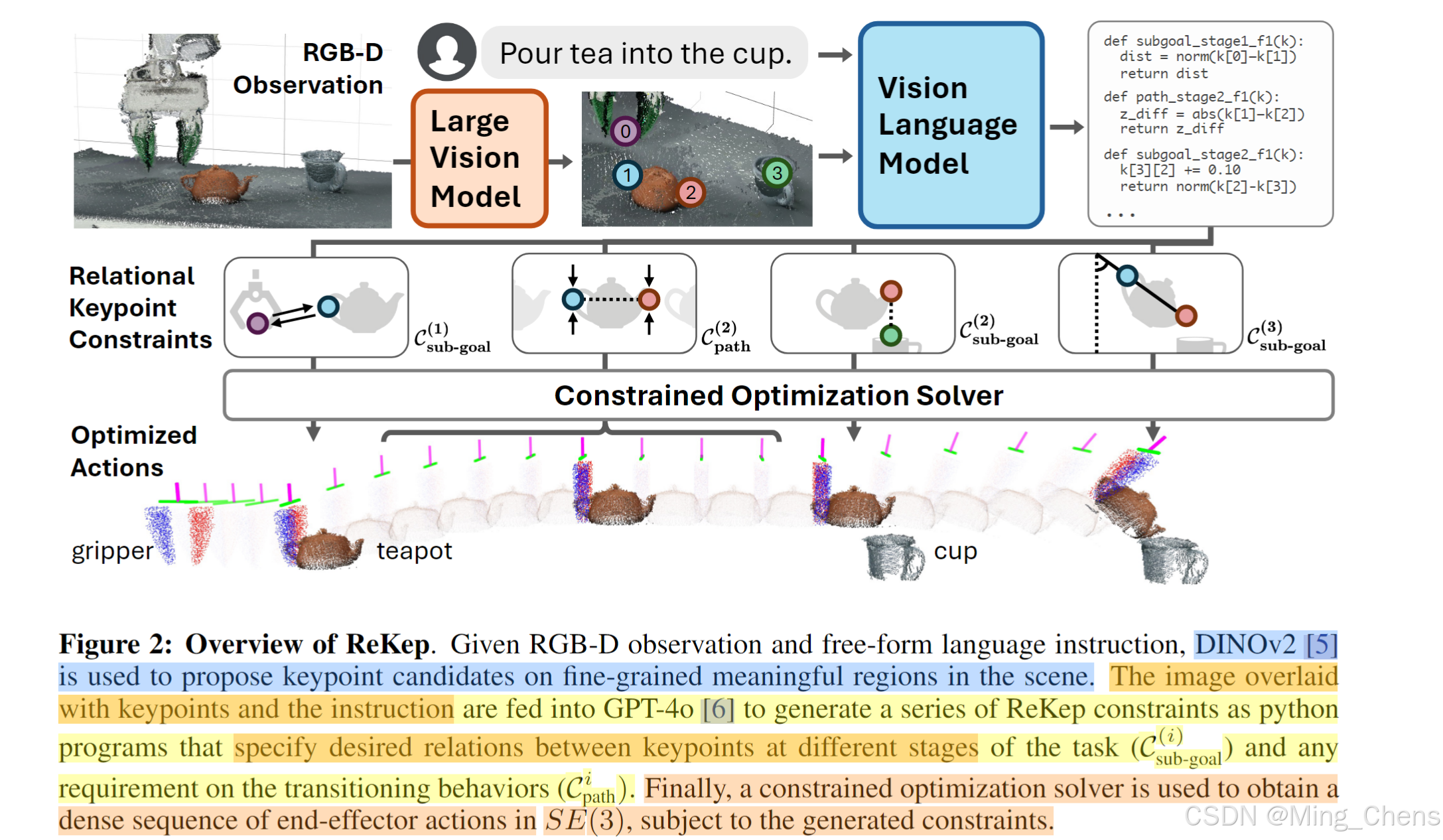
输入图像是RGB-D,Dinov2 用于提出场景中细粒度有意义区域的关键点候选对象。将覆盖关键点和指令的图像输入GPT-4o,生成一系列ReKep约束作为python程序,指定任务不同阶段的关键点之间的期望关系(C(i)子目标),以及对过渡行为的任何要求(Cipath)。最后,约束优化求解器用于在 SE(3) 中获得密集的末端执行器动作序列,受生成的约束。
实验:各种各样真实场景的任务(包括单臂和双臂,包括具有常识知识的野外规范、具有时空依赖性的多阶段任务、与几何意识的双手动协调以及与人类和干扰下的反应性)。
结论:展示了 ReKep 的独特优势,因为它可以由大型视觉模型和视觉语言模型自动合成。


















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











