







 超级会员免费看
超级会员免费看
目前文字检测算法可以大致分为两类:基于回归的方法和基于分割的方法。一般基于分割的方法流程是下图蓝色箭头所示:先通过网络输出图片的文本分割结果(概率图,每个像素为是否是正样本的概率),使用预设的阈值将分割结果图转换为二值图,最后使用一些聚合的操作例如连通域将像素级的结果转换成检测结果。
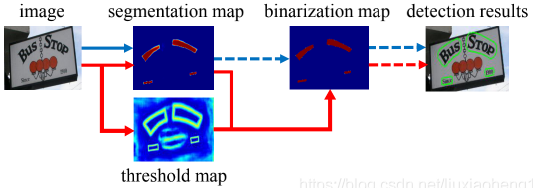
因为有一个使用阈值来判定前景和背景的操作,这个操作是不可微的,所以无法使用网络将该部分流程放入到网络中训练,本文通过学习threshmap和使用可微的操作来将阈值转换放入到网络中训练。流程如上图中的红色箭头所示。
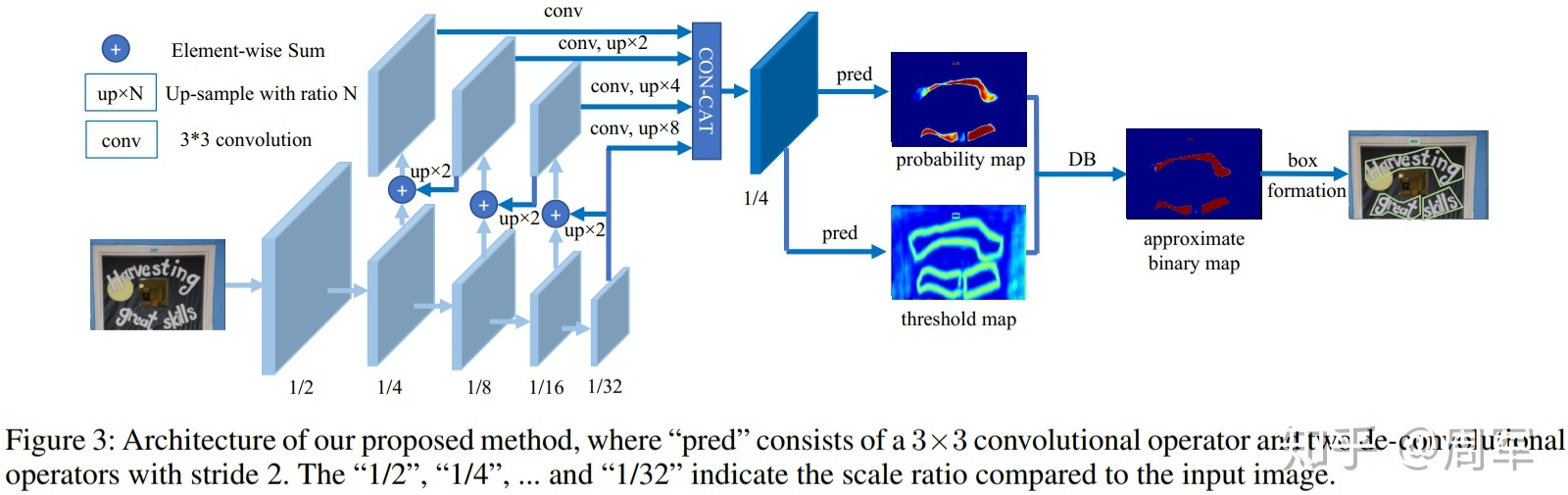
算法的整体架构:
- 图像输入特征提取主干,提取特征;
- 特征金字塔上采样到相同的尺寸,并进行特征级联得到特征F;
- 特征F用于预测概率图(probability map P)和阈值图(threshold map T)
- 通过P和F计算近似二值图(approximate binary map B)

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











