







前几天看到新闻openai将开始限制来自非支持国家和地区的API流量,目前OpenAI的API已向161个国家和地区开放,中国内地和中国香港未包含其中。这对于中国使用openai的用户来说算是彻底断了念想,好在国内大模型近些日来迅猛发展,前段时间刚开源的阿里Qwen2蝉联开源大模型榜首,已经和chatgpt不相上下,这篇文章主要介绍如何多方式体验Qwen2。
1.Qwen2介绍+在线使用
qwen2官网介绍:https://qwenlm.github.io/zh/blog/qwen2/
在线体验:
主要亮点:
- 5个尺寸的预训练和指令微调模型, 包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B;
- 在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据;
- 多个评测基准上的领先表现;
- 代码和数学能力显著提升;
- 增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。
在2个评估数据集上进行验证:
M-MMLU: 来自Okapi的多语言常识理解数据集
MGSM:包含德、英、西、法、日、俄、泰、中和孟在内的数学评测。
 结果均反映了Qwen2指令微调模型突出的多语言能力。
结果均反映了Qwen2指令微调模型突出的多语言能力。
优化点:
通义千问技术博客披露,在Qwen1.5系列中,只有32B和110B的模型使用了GQA。这一次,所有尺寸的模型都使用了GQA,以便让用户体验到GQA带来的推理加速和显存占用降低的优势。针对小模型,由于embedding参数量较大,研发团队使用了tie embedding的方法让输入和输出层共享参数,增加非embedding参数的占比。
上下文长度方面,所有的预训练模型均在32K tokens的数据上进行训练,研发团队发现其在128K tokens时依然能在PPL评测中取得不错的表现。然而,对指令微调模型而言,除PPL评测之外还需要进行大海捞针等长序列理解实验。在使用YARN这类方法时,Qwen2-7B-Instruct和Qwen2-72B-Instruct均实现了长达128K tokens上下文长度的支持。
目前在多项权威榜单和测评中,Qwen2-72B成为开源模型排行榜第一名。
2. 本地部署
- 本地部署:使用 llama.cpp 和 Ollama 等框架在 CPU 和 GPU 上本地运行 Qwen 模型的说明。
- Docker:预先构建的 Docker 镜像可用于简化部署。
- ModelScope:推荐中国大陆用户使用,支持下载检查点并高效运行模型。
- 推理框架:使用 vLLM 和 SGLang 部署 Qwen 模型进行大规模推理的示例。
2.1 Ollama 使用
Ollama下载:https://ollama.com/download
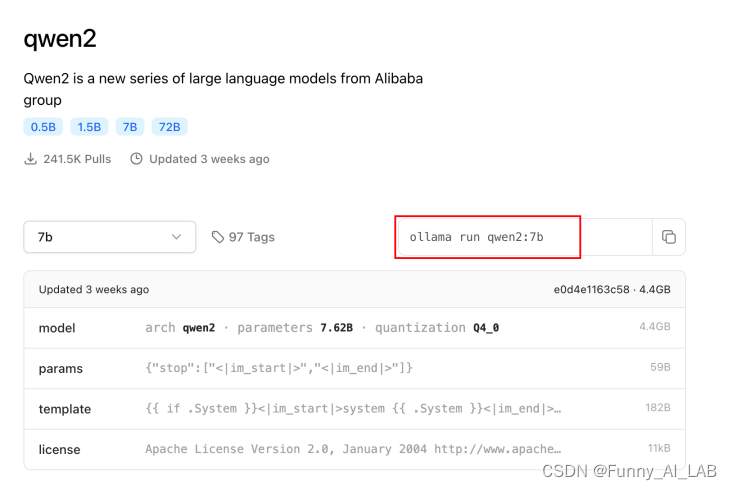
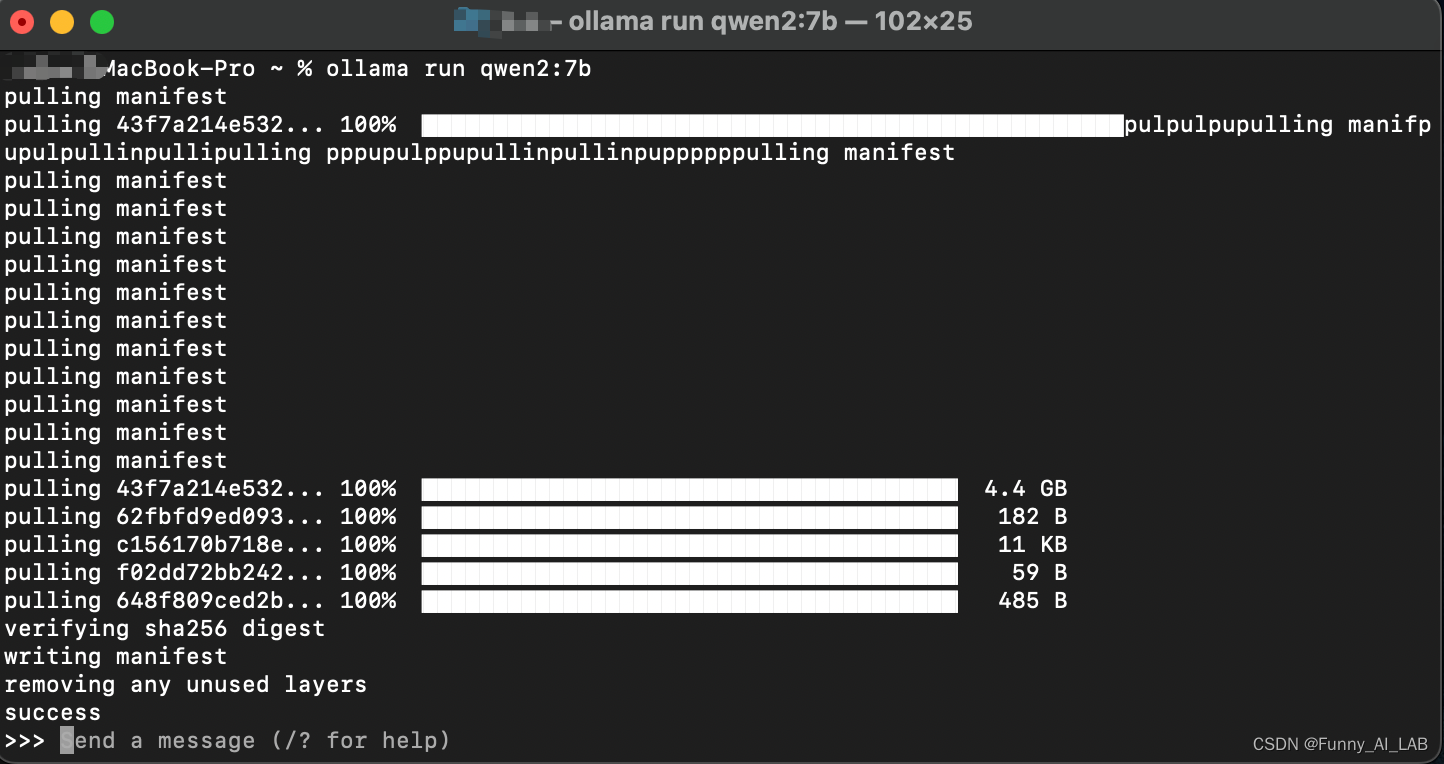
官网下载安装成功,打开终端安装:ollama run qwen2:7b
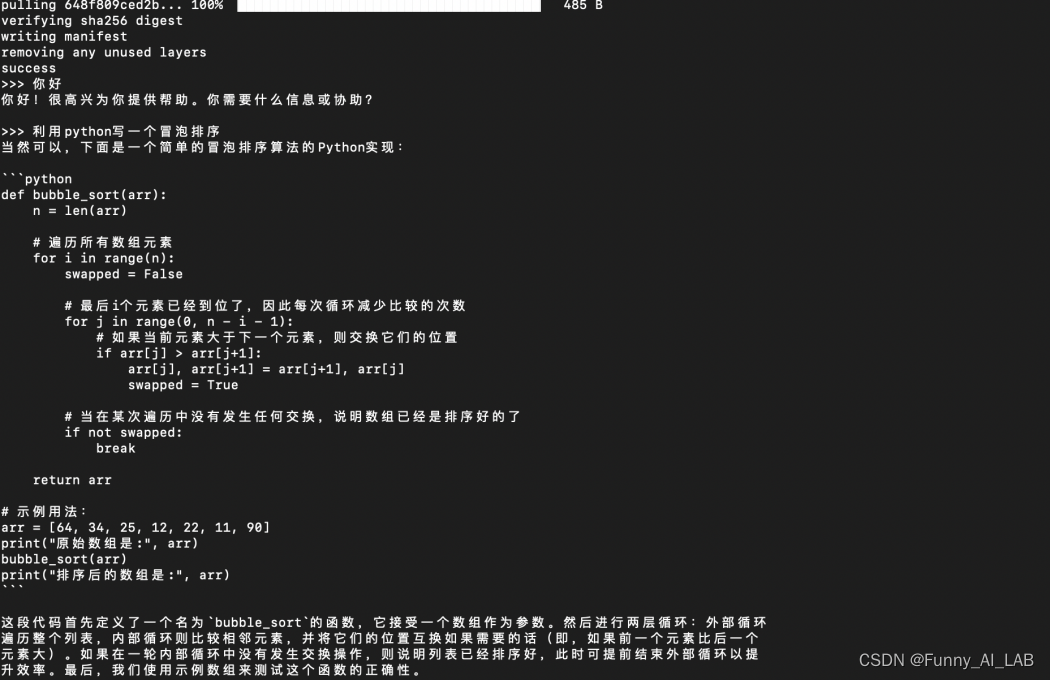
安装成功,测试使用,利用qwen2-7B写一个冒泡排序,速度感人
2.2 vllm部署
参考:deplo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









