







InternVL3,这是一款先进的多模态大型语言模型 (MLLM) 系列,展现出卓越的整体性能。与 InternVL 2.5 相比,InternVL3 展现出卓越的多模态感知和推理能力,同时进一步扩展了其多模态能力,涵盖工具使用、GUI 代理、工业图像分析、3D 视觉感知等。此外,得益于原生多模态预训练,InternVL3 系列的整体文本性能甚至优于 Qwen2.5 系列(后者是 InternVL3 中语言组件的初始化部分)。
开源地址:https://huggingface.co/collections/OpenGVLab/internvl3

相关博客:https://internvl.github.io/blog/
在线体验:https://internvl.opengvlab.com/
模型架构:
如以下图表所示,InternVL3 保持了与 InternVL 2.5 及其前身 InternVL 1.5 和 2.0 相同的模型架构,遵循“ViT-MLP-LLM”范式。在这个新版本中,集成了一个全新增量预训练的 InternViT 与各种预训练的语言模型(包括 InternLM 3 和 Qwen 2.5),使用随机初始化的 MLP 投影器。
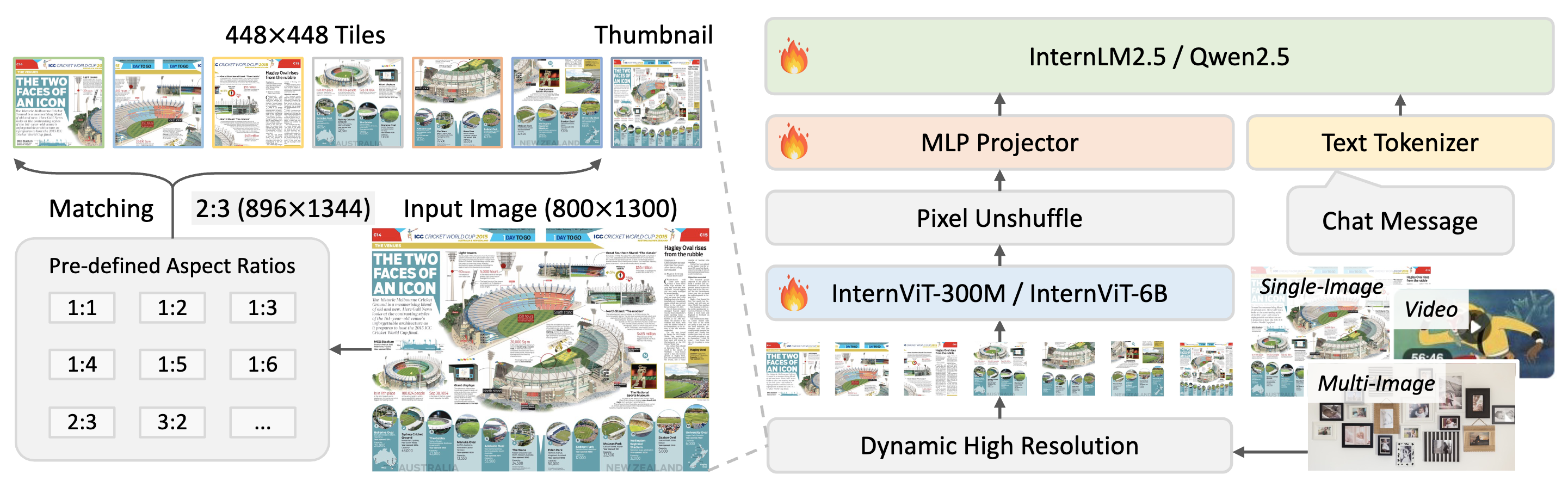
正如之前的版本,InternVL3应用了像素解混操作,将视觉标记的数量减少到原来的四分之一。此外,采用了与InternVL 1.5类似的动态分辨率策略,将图像分割成448×448像素的瓦片。从InternVL 2.0开始的关键区别在于,额外引入了对多图像和视频数据的支持。
值得注意的是,在InternVL3中,集成了可变视觉位置编码 (V2PE),它利用更小、更灵活的位置增量来处理视觉标记。得益于V2PE,InternVL3相比其前身在长上下文理解能力上表现得更好。
训练策略
原生多模态预训练
InternVL3提出了一种原生多模态预训练方法,将语言和视觉学习整合到一个单一的预训练阶段。 与先训练纯语言模型再适应以处理其他模态的标准范式不同,InternVL3的方法将多模态数据(例如,图像-文本、视频-文本或图像-文本交错序列)与大规模文本语料库交织在一起。这种统一的训练方案允许模型同时学习语言和多模态表示,最终增强其处理视觉-语言任务的能力,而无需单独的对齐或桥接模块。
监督微调
在这个阶段,InternVL2.5提出的随机JPEG压缩、平方损失重加权和多模态数据打包技术也在InternVL3系列中得到应用。 InternVL3的SFT阶段相比InternVL2.5的主要进步在于使用了更高质量和更多样化的训练数据。 具体来说,我们进一步扩展了用于工具使用、3D场景理解、GUI操作、长上下文任务、视频理解、科学图表、创意写作和多模态推理的训练样本。
混合偏好优化
在预训练和监督微调期间,模型被训练为根据先前的真实标记预测下一个标记。 然而,在推理过程中,模型基于自身的先前输出预测每个标记。 这种真实标记与模型预测标记之间的差异引入了分布偏移,这可能会损害模型的链式思维(CoT)推理能力。 为了解决这个问题,我们采用了MPO,通过正负样本提供的额外监督来使模型响应分布与真实分布对齐,从而提高推理性能。 具体来说,MPO的训练目标是 偏好损失 (\mathcal{L}{\text{p}})、 质量损失 (\mathcal{L}{\text{q}}) 和 生成损失 (\mathcal{L}{\text{g}}) 的组合, 可以表示如下:
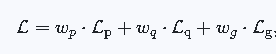
其中 (w{*}) 表示分配给每个损失组件的权重。
测试时间缩放
测试时间缩放已被证明是提升 LLM 和 MLLM 推理能力的有效方法。在本研究中,采用 Best-of-N 评估策略,并使用VisualPRM-8B作为评估模型,以选出最佳答案进行推理和数学评估。
多模态能力评估
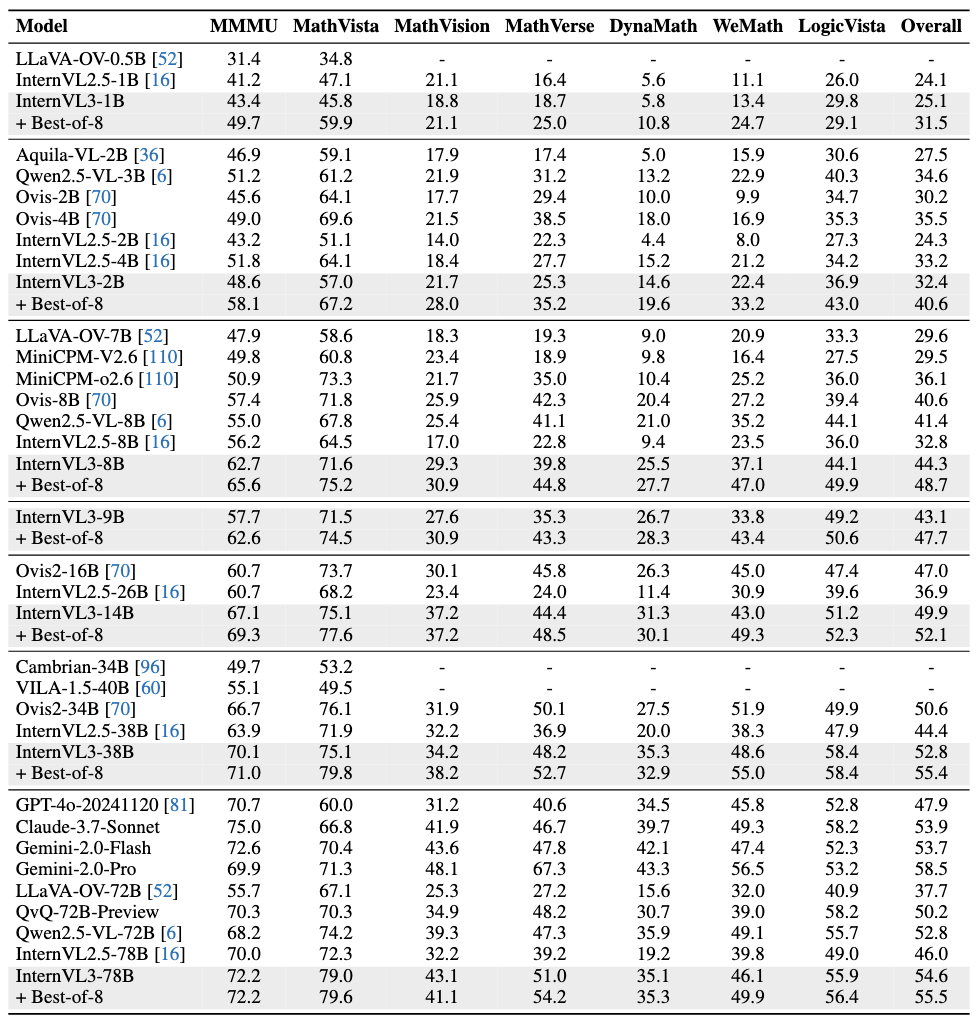
多模态推理与数学
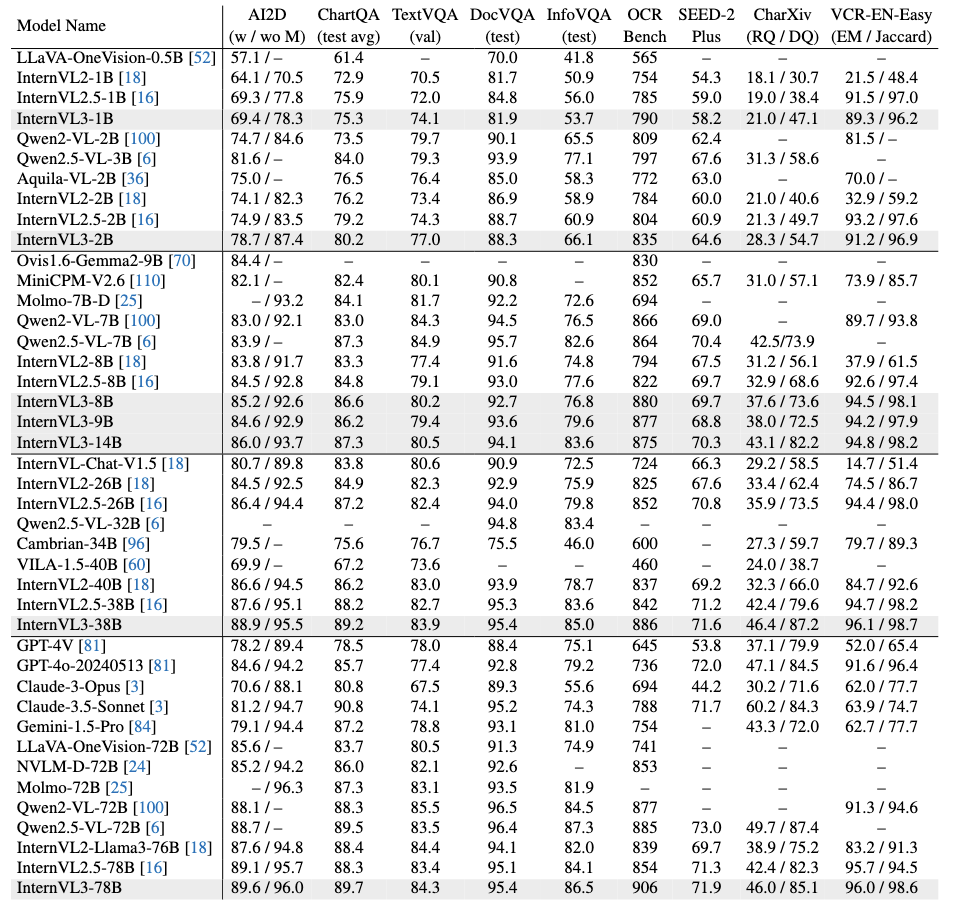
OCR、图表和文档理解
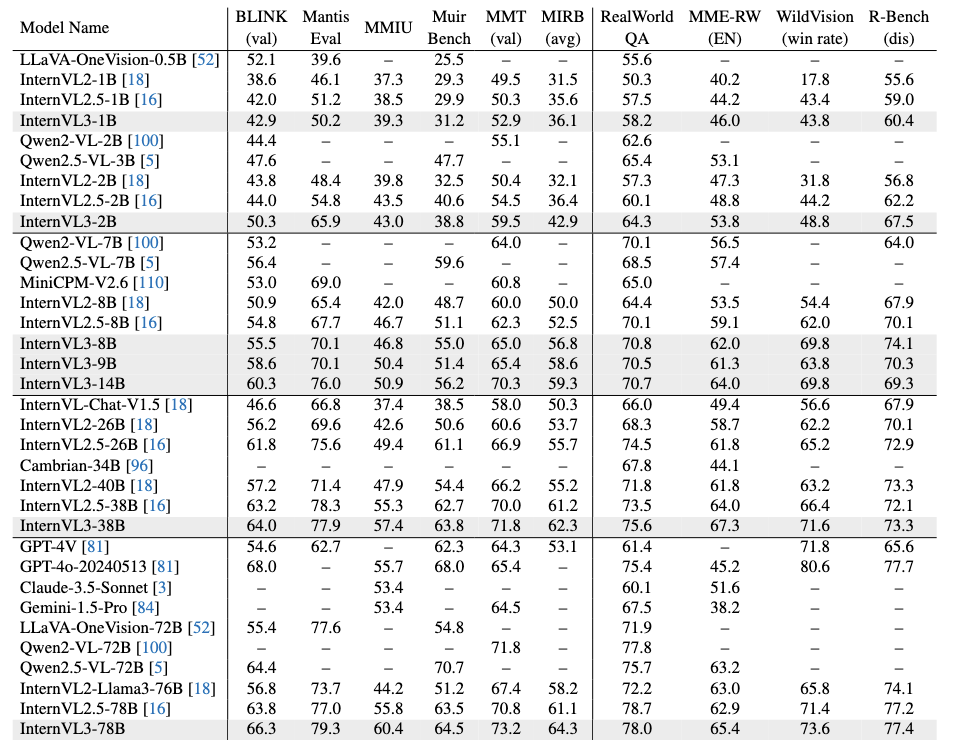
多图像与真实世界理解
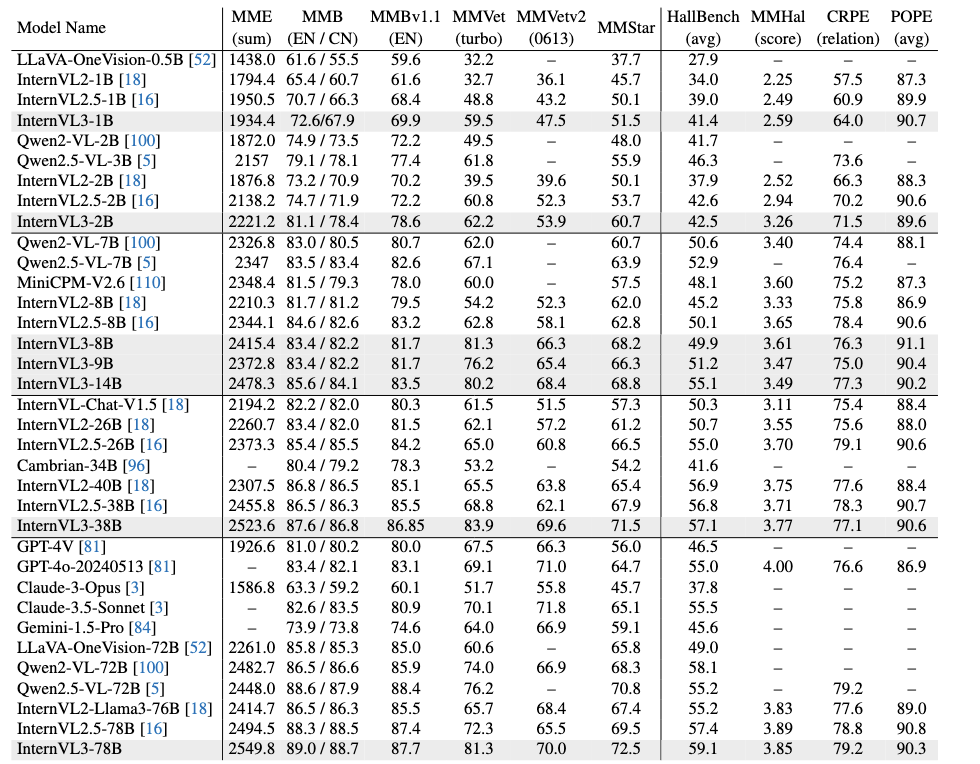
综合多模式和幻觉评估
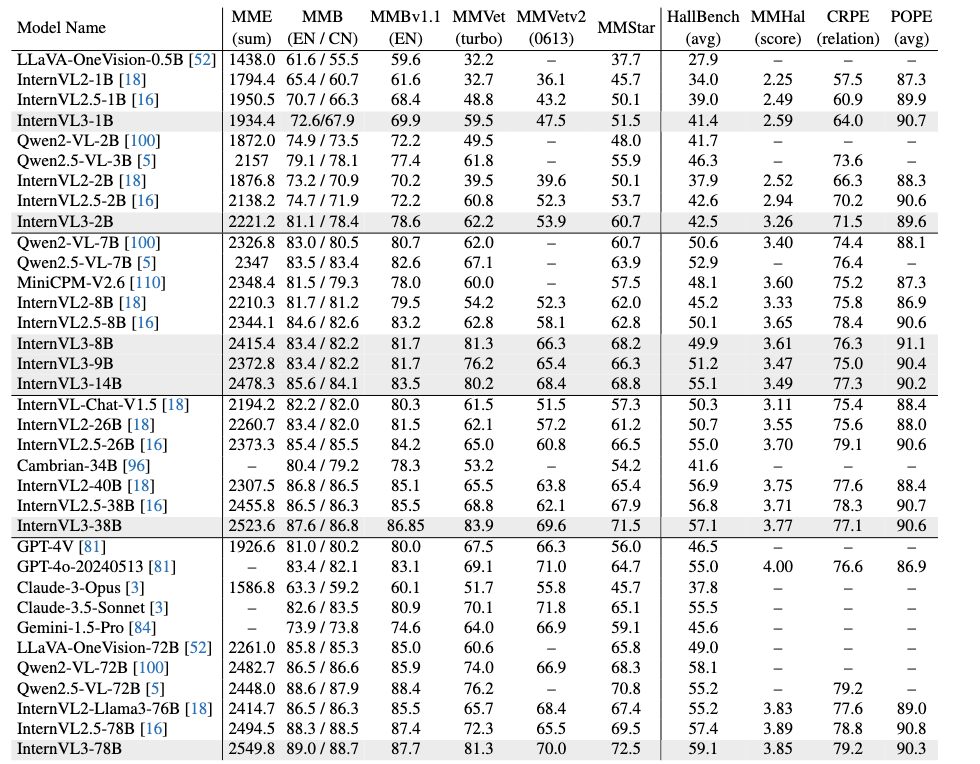
多模态多语言理解
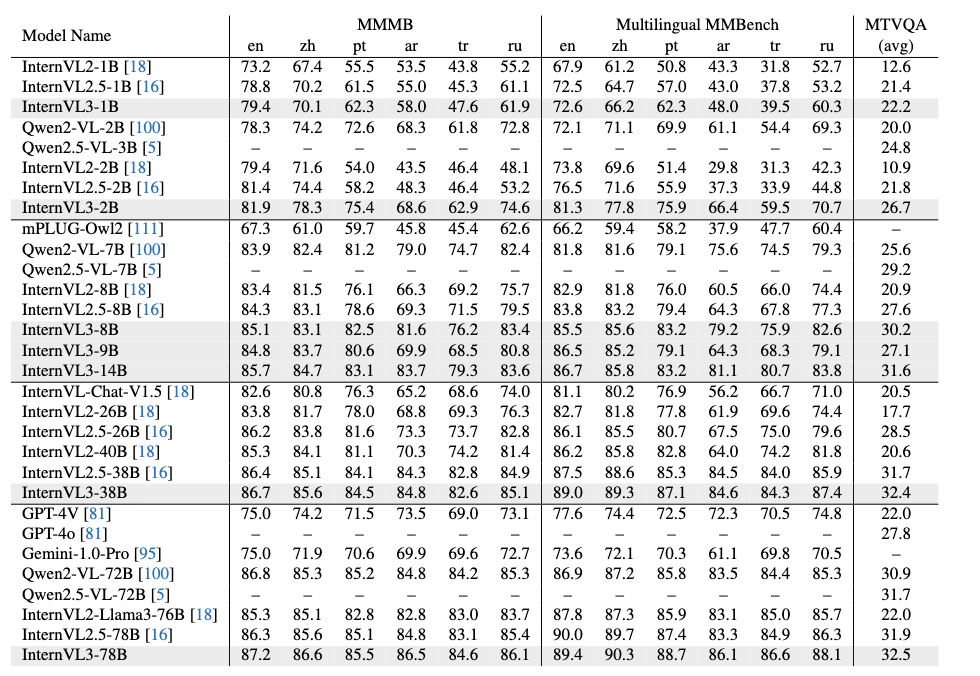
视频理解
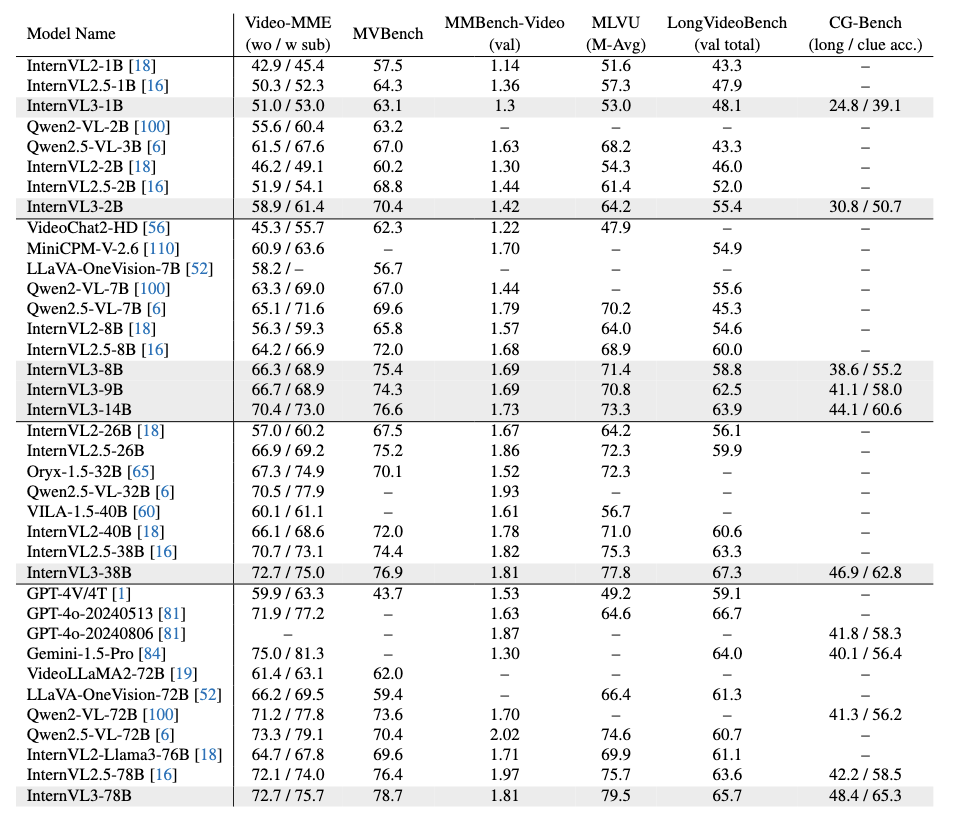
语言能力评估
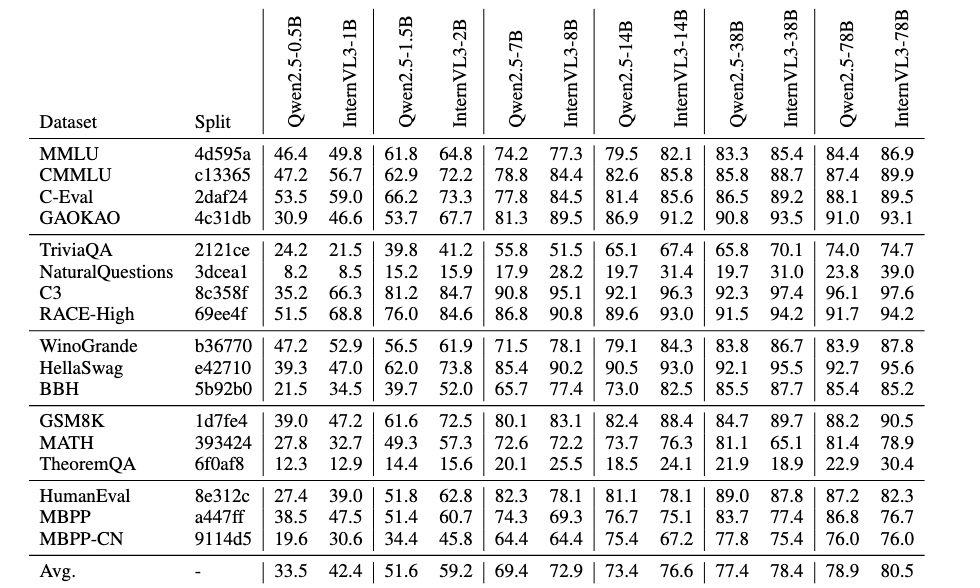
总结
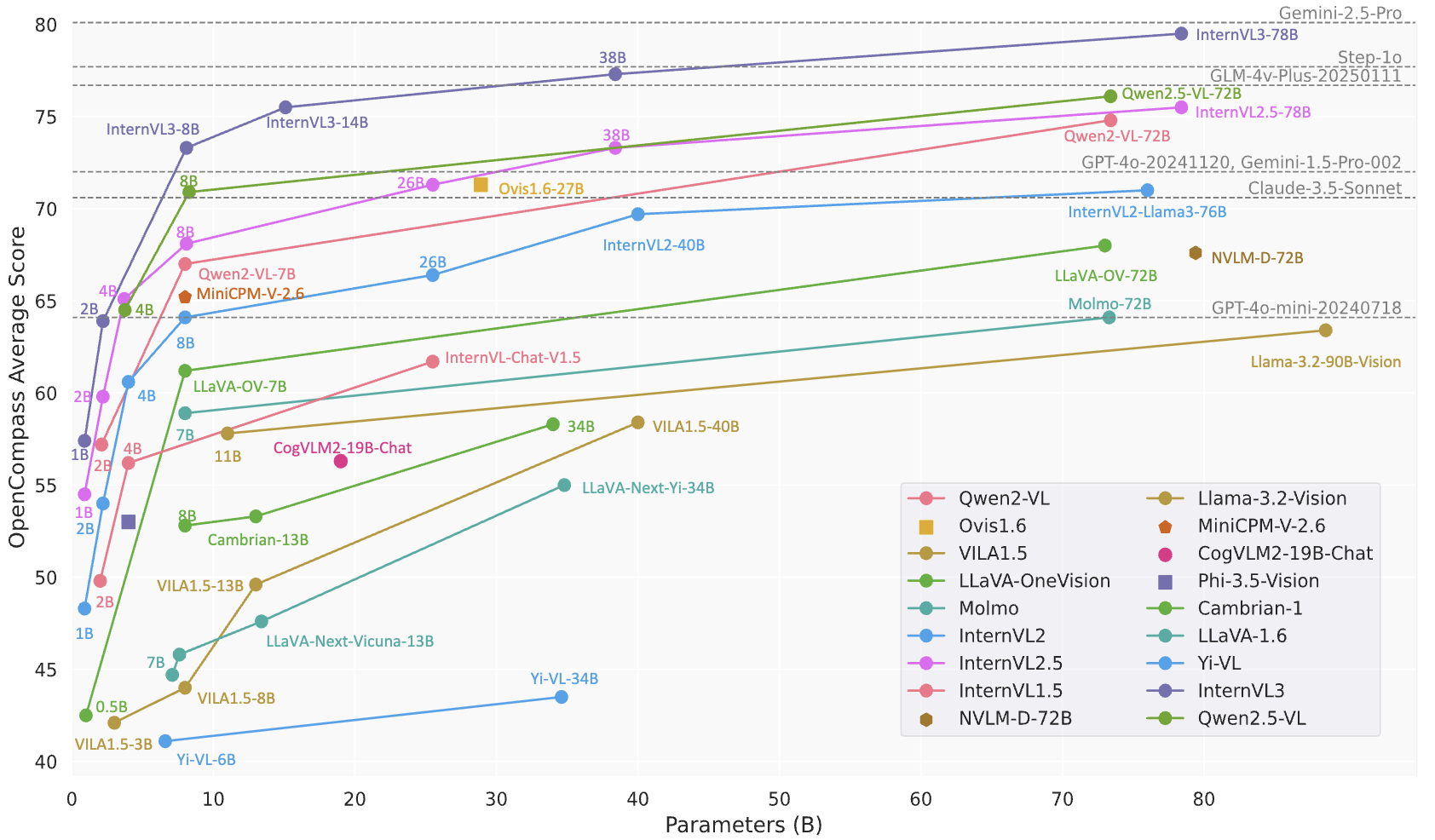
InternVL3-78B预计是InternVL系列的高阶版本,通过更大参数量、更优训练策略和扩展的模态支持,进一步提升多模态理解的通用性与专业性。其开源特性与高效部署能力,使其在学术研究与工业落地中具有重要价值。具体性能需参考官方发布的评测数据,但基于系列前代表现,可预期其在多模态任务中接近或超越主流商业模型。

















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









