







前段时间在做点云深度学习网络课题时,随手在博客“ModelNet40 中加入自己的数据集”中放了两串代码,目的是方便自己的存取(当时不会GIT的菜鸟)。结果成了所写博客中访问最多,提问最多的博文(瑟瑟发抖)。近段时间在恶补语言基础知识,索性换换脑,将这部分的知识进行一个相对完整的整理。希望对那些想快速入手点云深度学习,用来做课设、毕设的小朋友一点点帮助。以下都是个人的所学所思所想,不一定正确,仅做参考。也欢迎各路大神指出问题,将虚心改进。
一、组织架构
为了遵循博客简短干货原则,也为了更细致的描述及解决问题,我将该问题分成了3部分,分别如下:
二、数据集的分类
深度学习网络从二维扩展到三维是一个必然趋势。相较于二维图像,三维点云可以包含更多的信息。近几年来二维图像深度学习的发展似乎逐渐升级到一个瓶颈期,各种技术在短短几年内快速爆发,在各种图像问题上都达到了相当高的精度,因此突破性的想法也越来越难形成。导致很多研究者将目标对准了三维点云。在2017年PointNet提出之前,基于多视角,基于图像,基于体素的点云分类分割方法在缓慢的尝试和更新。2017年以后以PointNet为首的直接在点云上进行分类分割的深度学习网络迅速爆发。特别是在2019-2020,CVPR,ECCV等顶会上,3D出现的频次明显提高。

那说到深度学习,最让人头疼的其实就是数据集。好在许多科研机构,无私的贡献了相当多类型的三维数据集,为推动行业的发展默默贡献着。按照数据集在深度学习网络中使用方式的不同,我将这些数据集分成了两类:大型数据集和小型数据集
清新脱俗的名字,当然这里的大不是指数据集包含的点云个数的多少,而是每个点云的点数的多少。下面将列举一些常见的数据集进行说明。
三、大型数据集
大型数据集指一个点云中包含的对象或场景非常大,直观表现就是点数非常多的数据集。
1、Stanford Large-Scale 3D Indoor Spaces (S3IDS)
链接: http://buildingparser.stanford.edu/results.html

斯坦福室内数据集是由6个大型室内区域组成(如上图所示),每个区域又分为若干个房间,一共有271个房间,13个语义类别(例如:桌子,板凳,墙壁,沙发等)。
2、Virtual KITTI dataset(vKITTI)
链接:https://europe.naverlabs.com/Research/Computer-Vision/Proxy-Virtual-Worlds/

虚拟激光雷达点云是一个大型的室外道路点云,也包含了13个类别(例如:汽车,道路,树木等)。
上述两个数据集就是列举的大型数据集,当然还有很多其他的。我们的目的不是为了详细介绍这些数据集的来源等,就是为了让大家知道何为“大”。上述数据集的每个房间或者每个场景点云都包含几万到几十万甚至上百万的点。对点云深度学习网络有一定了解的小伙伴一定都知道目前网络输入的点受限于设备计算能力等一般输入点数为(1024,2048,4096最多到了8192)。因此直接将每个点云输入到网络中明显是不可行的。而数据的预处理,对于网络的性能影响是非常大的,因此接下来介绍下对此类大型点云,一般的深度学习网络是如何进行预处理的。
三、大型数据集的预处理
其实想法非常简单两个字足以说明一切“切和降”,切指将每个大型点云切分成一定规格的Blocks。降指降采样手段,将每个block的点数进一步的降低或者规范到固定的数量,作为网络的输入。下面就两篇论文介绍其数据预处理方式:
1、PointNet系列的数据预处理方式
对于S3DIS数据集,PointNet直接将每个房间切割成为 1m x 1m x h 大小的Blocks,这些Blocks没有重叠部分。其中,h指房间的高度,1m x 1m指水平方向沿x和y方向大小为1平方米的正方形区域。然后对每个区域进行随机采样(以网络输入为2048个点为例),如果该block中点数大于2048则随机采样2048个点,如果点数小于2048,则随机复制区域中的点到2048。
对于vKTTI数据集,由于该数据集相较于S3DIS稀疏很多,因此PointNet可以直接将每个房间切割成为 3m x 3m x h 大小的Blocks,其中,h指场景的高度,3m x 3m指水平方向沿x和y方向大小为9平方米的正方形区域。然后对每个区域进行随机采样(以网络输入为256个点为例),如果该block中点数大于256则随机采样256个点,如果点数小于256,则随机复制区域中的点到256。
优缺点分析,上述的预处理方式优点就是处理方便,编程也简单易操作。那缺点就值得我们好好分析一波,毕竟发现问题才能更好的解决问题。
- 切分方式简单粗暴。采用横竖直切的方式,其实会得到很多不完整的类别进行训练。例如一张椅子,恰巧被一分为二,那椅子的一半被送进网络是会有积极作用还是消极作用。当然,我们直观的考虑,类似于图像中旋转形变等操作,这样好像能够刚好的提高网络的鲁棒性。但是,我认为这里是自我安慰。
- 数据损失大,体现在两个方面。宏观来说,正如1中描述,切分方式难以得到大量的完整的种类形态。微观来说,后续的随机降采样方式,扔掉了大量的数据点。一个大几十万的房间,可能最终进网络进行训练的也就小几万,这对数据集是极大地浪费。
那上述方法有没有可能进行改进?在读完PointNet之后,我想过一段时间,并没有较好的想法。直到读了一篇论文“PointCNN”,令人眼前一亮。
2、PointCNN的数据预处理方式
这里我就不再单独分开S3DIS和vKITTI。万变不离其宗,再怎么样也还是要切,也还是要降。PointCNN引入了两种策略,以下分别介绍:
怎样切?在保留PointNet切法的同时,加入另一种切法,即在第一种切法的情况下,朝x或y方向一次移动0.5m再进行切分。那这样做有什么好处?可能在第一种切法下只保留一半的椅子,在第二种移动0.5m的情况下就能得到完整的椅子。因此能够比原始方法得到更多的完整种类形态,其次能够进一步的扩大对数据的利用,即扩增数据。
怎样降?原始的方式是需要2048个点,我就提前全部降成2048个点进行输入。而在PointCNN网络中(以输入2048个点为例),用同样的随机采样方式将所有的blocks规定到8192个点,然后再在每个epch训练过程中,从8192中再随机采样2048个点。明显的这样进一步的扩大对数据的利用率,同时进一步的扩增了数据。
不得不说,PointCNN取得了相当好的分割效果,一方面该网络的结构确实有独到之处,另一方面我认为与这种数据的预处理方式有着密切的关系。当然这里我并没有去做原始处理方式和他这种改进方式的定量对比。有兴趣的小伙伴可以试试,看看增加了多少。(本来想多放点图上去,帮助大家理解,但是又要写代码,又要可视化,我懒了。)
那还有没有缺陷?当然是有的,当然也是有改进的办法。我们是不是可以在降采样的方式上再做做文章嘞?这里就不再进一步描述了,也欢迎大家讨论交流。
四、小型数据集
小型数据集指一个点云中包含的对象或场景非常小,直观表现就是点数非常少的数据集。
1、ShapeNet
链接:https://www.shapenet.org/
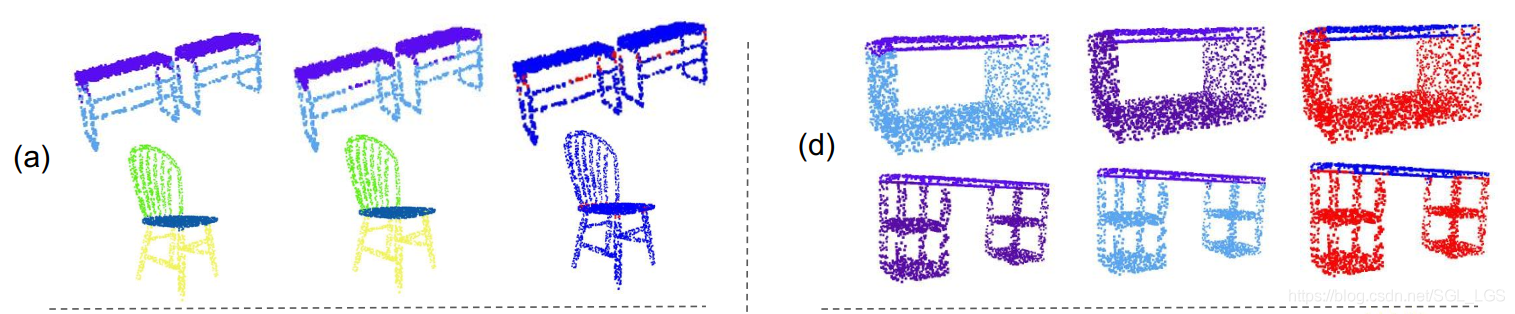
该数据集有16个类别(飞机,椅子,汽车等),共16,881个形状。每个类别又进一步的标注了组件结构(例如飞机分为机翼,机身和机尾)用作part segmentation,16个类别一共分成了50个part。每种类别形状规则无杂点,点数少,因此为小型数据集。如下图为pointnet所展示的部分形状分割结果。
2、ModelNet40
链接:http://modelnet.cs.princeton.edu/


之前傻傻分不清ModelNet40和ShapeNet,看上去都是规则的CAD模型。ModelNet40顾名思义包含有40种类别比ShapeNet大。但ShapeNet数据集有实例标签,后者好像没有。上图为PointNet中展示的几种类型示例。
五、小型数据集的预处理
相较于大型数据集,小型数据集处理就简单许多,由于结构相对简单,2048个点足以表示出类别的基本形状。因此都是直接随机采样将一个点云作为一个整体输入到网络中去,避免了由于裁剪导致的现状结构不完整的情况。此处不再赘述。
六、下篇预告
一般来说,需求使用较大的应该是小型数据集。一方面关注与这些数据集有什么特点,从而仿照生成自己的数据集。另一方面,在 自己数据集大小较小的情况下,希望能融合现有的 小型数据集达到充分训练网络的目的。无论是哪一种需求,下面的介绍都会有一定帮助。因此下文首先会从宏观角度以shapenet数据集为例,了解该数据集存在的一些特性。其次会具体介绍如何生成自己的数据集应用于点云深度学习网络。
参考文献:
[1] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 652–660, 2017.
[2] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” Advances in neural information processing systems, pp. 5099–5108, 2017.
[3] Y. Li, R. Bu, M. Sun, W. Wu, X. Di, and B. Chen, “Pointcnn: Convolution on X-transformed points,” Advances in Neural Information Processing Systems, 2018.
[4] F. Engelmann, T. Kontogianni, A. Hermans, and B. Leibe, “Exploring spatial context for 3d semantic segmentation of point clouds,” Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 716–724, 2017.
[5] I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M. Fischer, and S. Savarese, “3d semantic parsing of large-scale indoor spaces,” pp. 1534–1543, 2016.
[6] A. Gaidon, Q. Wang, Y. Cabon, and E. Vig, “Virtual worlds as proxy for multi-object tracking analysis,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[7] L. Yi, V. G. Kim, D. Ceylan, I. Shen, M. Yan, H. Su, C. Lu, Q. Huang, A. Sheffer, and L. J. Guibas, “A scalable active framework for region annotation in 3d shape collections,” Acm Transactions on Graphics, vol. 35, no. 6, p. 210, 2016.














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









