







文章目录
前言
本文主要为了记录学习进度,亦可供相关人员参考。(我刚学有许多写的不对的地方大家见谅)
一、MPC是什么?
MPC全名模型预测控制(Model Predictive Control),是一种控制方法,其基本思想就是利用已有的模型、系统当前的状态和未来的控制量去预测系统未来的输出,通过在线滚动地求解带约束优化问题来实现控制目的,具有预测模型、滚动优化和反馈矫正三个特点。
1、预测模型
预测模型是模型预测控制的基础,能够根据历史信息和控制输入预测系统的未来输出。本次的模型由运动学推导得出。
2、滚动优化
模型预测控制通过使某项性能评价指标最优来得到最优控制量,这种优化是反复在线运行的。
假如存在一条期望轨迹,以时刻k作为当前时刻。
1)预测输出,控制器在当前的状态测量值和控制量测量值的基础上结合预测模型,预测系统未来一段时域内[k,k+Np]的输出。
2)求解目标函数,通过求解满足目标函数与一系列约束的优化问题,得出在控制时域内[k,k+Nc]一系列的控制序列,并将该控制序列的第一个元素作为受控对象的实际控制量。
3)滚动优化当来到k+1时刻时,循环往复以上步骤。
3、反馈矫正
为了抑制由于模型失配或环境干扰引起的控制偏差,在新的采样时刻,首先检测对象的实际输入,并利用这一实时信息对基于模型的预测进行修正,然后再进行新的优化。
二、理论推导
1.推导过程


2.核心思路
1、先建立车辆运动学微分方程。
2、引入参考路径与参考控制量,并与实际状态量与控制量做差,构造误差函数。
3、使用泰勒展开对误差函数线性化。
4、推导增量控制模型(往往我们要对输入量的增量做控制)
5、得到递推式
6、转化为二次规划问题
7、求解二次规划问题
三、CarSim-Simulink联合仿真
1、CarSim配置
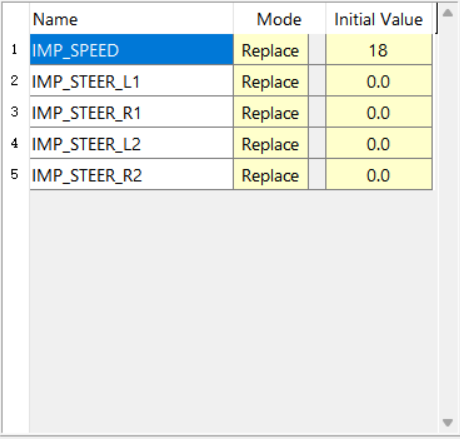
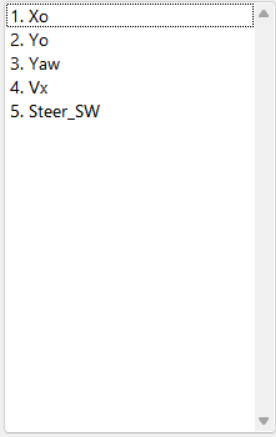
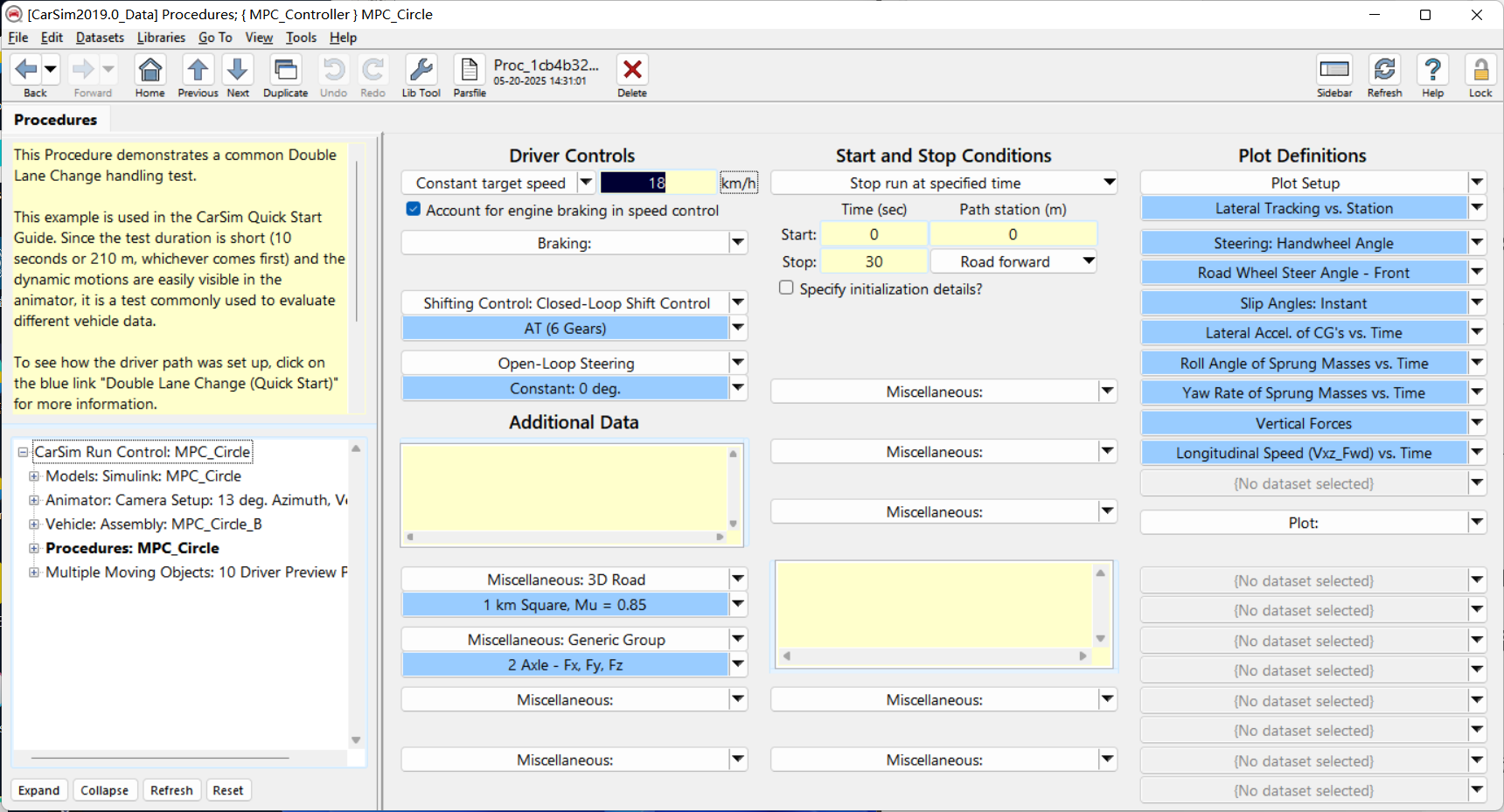
2、Simulink配置
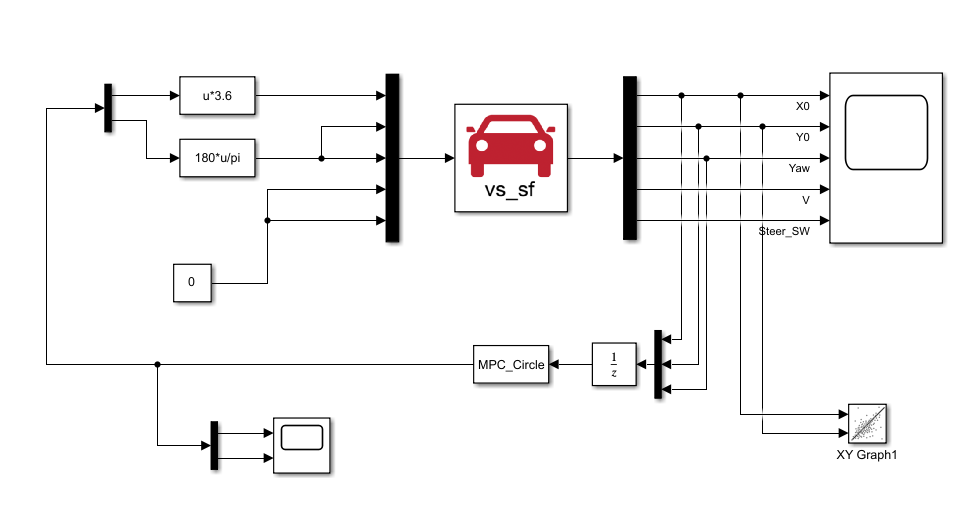
3、S-Function代码
function [sys,x0,str,ts] = MPC_Circle_RW(t,x,u,flag) %构建S-function函数,t为当前的仿真时间,x为状态变量,u是输入(simulink模块的输入),flag为仿真过程中的标志位
switch flag %sys输出根据flag的不同而不同
case 0
[sys,x0,str,ts] = mdlInitializeSizes; % Initialization初始化
case 2
sys = mdlUpdates(t,x,u); % Update discrete states 更新离散状态
case 3
sys = mdlOutputs(t,x,u); % Calculate outputs 计算输出
case {1,4,9} % Unused flags 滞空
sys = [];
otherwise
error(['unhandled flag = ',num2str(flag)]); % Error handling
end
% End of dsfunc.
%==============================================================
% Initialization
%==============================================================
function [sys,x0,str,ts] = mdlInitializeSizes
sizes = simsizes;
sizes.NumContStates = 0; %连续状态量
sizes.NumDiscStates = 3; %离散状态量
sizes.NumOutputs = 2; %输出的个数
sizes.NumInputs = 3; %输入量的个数
sizes.DirFeedthrough = 1; % Matrix D is non-empty.
sizes.NumSampleTimes = 1; %采样时间的个数
sys = simsizes(sizes); %设置完后赋值给sys输出
x0 =[0;0;0]; %状态量初始化,横纵坐标以及横摆角都为0
global U; %设定U为全局变量
U=[0;0]; %初始的控制量为0,0
% Initialize the discrete states.
str = []; % Set str to an empty matrix.str为保留参数,mathworks公司还没想好怎么用它,一般在初始化中将其滞空即可
ts = [0.1 0]; % ts为1*2维度的向量,采样周期+偏移量sample time: [period, offset],仿真开始0s后每0.1秒运行一次
%End of mdlInitializeSizes
%==============================================================
% Update the discrete states更新离散状态函数
%==============================================================
function sys = mdlUpdates(t,x,u) %flag=2表示此时要计算下一个离散状态,即x(k+1)
sys = x;
%End of mdlUpdate.
%==============================================================
% Calculate outputs输出子函数,控制的主体
%==============================================================
function sys = mdlOutputs(t,x,u) %flag=3表示此时要计算输出,如果sys=[],则表示没有输出
global a b u_piao;%a,b,u_piao均为全局矩阵,a为线性化状态矩阵,b为线性化控制矩阵,u_piao为控制误差的变化量
global U; %U全局控制量误差,2*1 维度矩阵
global kesi; %kesi为全局,新的状态向量,[k时刻的状态量误差;k-1时刻的控制量误差],5*1矩阵
tic
%参考路径
r(1)=25*sin(0.4*t);
r(2)=25+10-25*cos(0.4*t);
r(3)=0.4*t;
vd1=10;
vd2=0.104;%前轮偏角=tan(轴距/半径)
t_d = u(3)*pi/180;
t_d1 = r(3);
Nx = 3;%状态量个数
Nu = 2;%控制量个数
Nc = 30;%控制时域
Np = 60;%预测时域
Row=10;%松弛因子权重
T = 0.1;
L = 2.6;%轴距
%矩阵初始化
a = [1 0 -vd1*sin(t_d1)*T;
0 1 vd1*cos(t_d1)*T;
0 0 1];%3*3
b = [cos(t_d1)*T 0;
sin(t_d1)*T 0;
tan(vd2)*T/L vd1*T/(L*cos(vd2)^2)];%3*3
%增量控制的新的状态矩阵
kesi = zeros(Nx+Nu,1);%Size:5*1
kesi(1) = u(1)-r(1);
kesi(2) = u(2)-r(2);
kesi(3) = t_d-t_d1;
kesi(4) = U(1);%k-1时刻速度的误差
kesi(5) = U(2);%k-1时刻转角的误差
u_piao=zeros(Nu,1); %构造3*1维度的矩阵来存放控制量误差的变化量
Q=100*eye(Nx*Np,Nx*Np); %权重矩阵Q为180*180的单位矩阵,,,,不懂
R=10*eye(Nu*Nc); %权重矩阵R为60*60的单位矩阵,,,,不懂
A_Cell = cell(2,2);%构建2*2的元胞数组
B_Cell = cell(2,1);%构建2*1的元胞数组
A_Cell{1,1} = a;%Size:3*3
A_Cell{1,2} = b;%Size:3*2
A_Cell{2,1} = zeros(Nu,Nx);%Size:2*3
A_Cell{2,2} = eye(Nu);%Size:2*2
B_Cell{1,1} = b;%Size:3*2
B_Cell{2,1} = eye(Nu);%Size:2*2
A_piao = cell2mat(A_Cell);%Size:5*5
B_piao = cell2mat(B_Cell);%Size:5*2
C=[1 0 0 0 0;0 1 0 0 0;0 0 1 0 0];%输出选择矩阵Size:3*5
%给Phi_Cell,Theta_Cell赋值
Phi_Cell = cell(Np,1);%Size:60*1
Theta_Cell = cell(Np,Nc);
for i = 1:1:Np
Phi_Cell{i,1} = C*A_piao^i;%Size:(3*5)*(5*5) = 3*5
for j = 1:1:Nc
if j<=i
Theta_Cell{i,j} = C*A_piao^(i-j)*B_piao;%Size:3*2
else
Theta_Cell{i,j} = zeros(Nx,Nu);%Size3*2
end
end
end
Phi = cell2mat(Phi_Cell);%Size:180*5
Theta = cell2mat(Theta_Cell);%Size:180*60
H_Cell = cell(2,2);
f_Cell = cell(1,2);
H_Cell{1,1} = Theta'*Q*Theta + R;%Size:60*60
H_Cell{1,2}=zeros(Nu*Nc,1); %60*1维度
H_Cell{2,1}=zeros(1,Nu*Nc); %1*60维度
H_Cell{2,2} = Row * eye(1);
H = cell2mat(H_Cell);%Size:61*61
H = (H+H')/2;%将 H 强制转化为对称矩阵(Symmetric Matrix)
error=Phi*kesi;%这里的error就是我们所设的E矩阵%Size:180*1
f_Cell{1,1} = 2*error'*Q*Theta;%Size:1*60
f_Cell{1,2} = zeros(1,1);
f=cell2mat(f_Cell);%将元胞数组转化为矩阵%Size:1*61
%% 以下为约束生成区域
%不等式约束
A_t=zeros(Nc,Nc);%见falcone论文 P181
for p=1:1:Nc
for q=1:1:Nc
if q<=p
A_t(p,q)=1;
else
A_t(p,q)=0;
end
end
end
A_I=kron(A_t,eye(Nu));%对应于falcone论文约束处理的矩阵A,求克罗内克积
Ut=kron(ones(Nc,1),U);%此处感觉论文里的克罗内科积有问题,暂时交换顺序
umin=[-0.2;-0.436;];%维数与控制变量的个数相同,课本P81页
umax=[0.2;0.436;];
delta_umin=[-0.05;-0.0082;]; %源代码有错,速度下界没加负号
delta_umax=[0.05;0.0082];
Umin=kron(ones(Nc,1),umin);
Umax=kron(ones(Nc,1),umax);
%二次规划不等式约束
A_cons_cell={A_I zeros(Nu*Nc,1);-A_I zeros(Nu*Nc,1)};
b_cons_cell={Umax-Ut;-Umin+Ut};
A_cons=cell2mat(A_cons_cell);%(求解方程)状态量不等式约束增益矩阵,转换为绝对值的取值范围
b_cons=cell2mat(b_cons_cell);%(求解方程)状态量不等式约束的取值
% 二次规划上下限约束
M=10; %松弛因子上限
delta_Umin=kron(ones(Nc,1),delta_umin);
delta_Umax=kron(ones(Nc,1),delta_umax);
lb=[delta_Umin;0];%(求解方程)状态量下界,包含控制时域内控制增量和松弛因子下界
ub=[delta_Umax;M];%(求解方程)状态量上界,包含控制时域内控制增量和松弛因子上界M
%% 开始求解过程
options = optimset('Algorithm','interior-point-convex');
[X,fval,exitflag] = quadprog(H,f,A_cons,b_cons,[],[],lb,ub,[],options);
%% 计算输出
u_piao(1) = X(1);
u_piao(2) = X(2);
U(1) = kesi(4)+u_piao(1);%k-1时刻控制量的误差+求解出控制量误差的变化量 = 当前控制量的误差
U(2) = kesi(5)+u_piao(2);%k-1时刻控制量的误差+求解出控制量误差的变化量 = 当前控制量的误差
u_real(1) = vd1+U(1);
u_real(2) = vd2+U(2);
sys= u_real; %将算出来的真正的控制量输出输出
toc
% End of mdlOutputs.
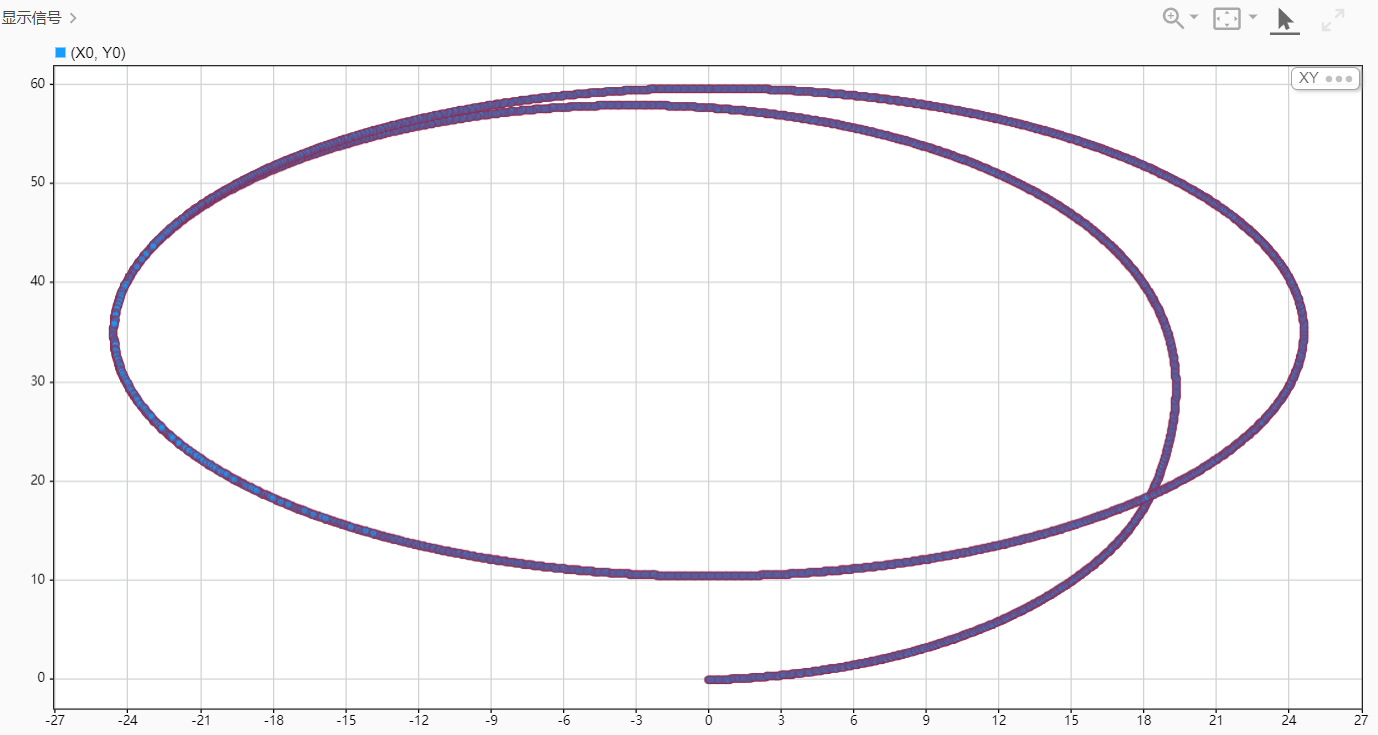
4、仿真结果
总结
本文对模型预测控制(Model Predictive Control, MPC)进行了简要介绍,包括其基本原理、三大核心特性(预测模型、滚动优化、反馈矫正),并从理论角度推导了控制器设计方法,最终通过 CarSim 与 Simulink 的联合仿真验证了控制效果。
在控制器设计过程中,我们引入了车辆运动学模型,使用泰勒展开线性化系统,并将控制问题转化为一个带约束的二次规划问题。通过 MATLAB S-Function 编写仿真模块,实现了路径跟踪控制目标。
仿真结果表明:该 MPC 控制器具有较好的跟踪性能和稳定性,能有效控制车辆按照期望轨迹运行。
由于本人初学,文中可能存在不严谨或错误之处,欢迎大家批评指正与交流学习。

















 5315
5315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









