







假设存在一个运动区域,规则要求只能进行特定的运动项目。 出于安全原因或因为业主不喜欢而禁止进行任何其他活动:)。 我们要解决的问题是:如果我们知道正确行为的列表,我们是否可以创建一个视频监控系统,在出现不常见的行为发出通知? 这无非是一个异常检测(anomaly detection)问题,即在我们生活或工作的环境中发现异常事件发生的地方,而正常情况下事情进展顺利。
解决异常检测任务的流行方法是通过无监督或半监督方法。 其原理很简单:我们通过过拟合正常发生的情况来训练模型,这通常意味着一切都会定期发生,没有或有非常罕见的异常事件。 例如,使用自编码器(autoencoder),我们能够重建原始源。 因此,查看重建误差,如果低于某个阈值,我们就观察到正常事件,否则,我们检测到异常。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包
这个帖子很有趣。 它旨在利用 LSTM 卷积自动编码器解决类似的问题。 一旦在非异常事件上从头开始训练模型,在推理时,它的目标是重建原始剪辑并直接在像素 (2+1) 维时空上计算重建误差。
在本文中我想描述另一种方法。 利用预训练的时空模型(space-time model)来解决动作分类任务,我提取剪辑视频的嵌入向量,并通过将其传递给自编码器,对完整模型进行微调以重建该向量。 这个想法是将重建阶段从像素(2+1)维空间转移到嵌入空间,将寻找视频帧之间所有可能的时空相关性的任务留给时空模型。
为了执行此练习,我将使用 UCF 运动动作数据集,其中总共包含 150 个分辨率为 720 x 480 的视频剪辑,分为 10 个不同的运动动作。 我将剪辑分成两组。 第一组有7个类别,包含允许的体育动作。 其余3个模拟非法异常行为,我将开发的系统必须能够识别为异常事件。
你可以在此 GitHub 存储库中找到本文的完整代码。
1、数据集属性
我已经在这篇文章中讨论了UCF数据集,其中我使用 PytorchVideo 分析了视频分类任务。
该数据集包括以下 10 个动作:跳水、高尔夫挥杆、踢腿、举重、骑马、跑步、滑板、秋千凳、侧秋千、行走。 上一篇文章详细讨论了许多预处理步骤。 这里,我只是列出了脚本 preprocess_dataset_ucf_action_sport.py 中执行的主要步骤
- 将 .avi 文件转换为 .mp4 格式
- 将 Golf-Swing-Back、Golf-Swing-Front 和 Golf-Swing-Side 分组为 Golf-Swing; 将Kicking-Front和Kicking-Side分组为Kicking
- 删除那些已损坏或持续时间为零的 .mp4 剪辑
- 将异常集中的前走、举重和前滑板动作分组。 将剩余的片段分为训练、验证和测试
- 将每个类别的训练和验证剪辑分别增加到 200 个和 10 个剪辑。 这样我就平衡了每个类的训练样本数量
- 为训练、验证、测试和异常的每个最终数据集生成相应的 .csv 数据框,以收集每个剪辑的路径和标签
- 执行预处理步骤后,剪辑视频在每个不同数据集上的分布如图1所示。
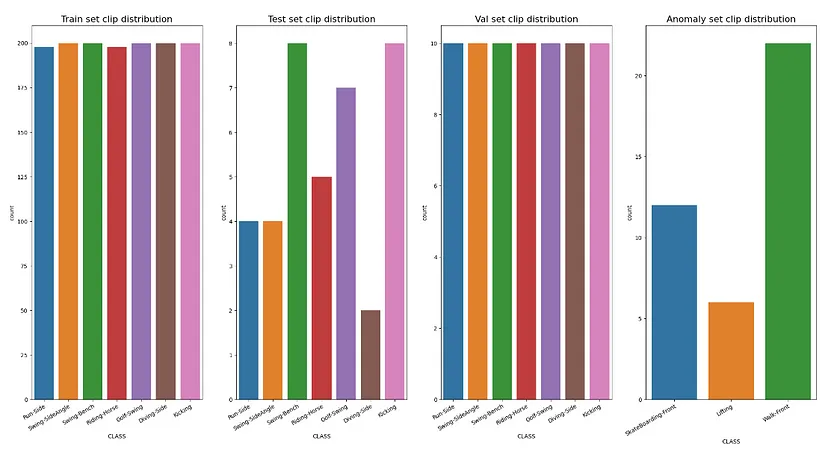
图 1:训练、测试、验证和异常数据集中按类别分组的剪辑数量分布
2、预训练时空模型
对于时空模型,我指的是那些针对动作识别任务进行预训练的模型。 近年来该领域取得了许多进展,因此,为了执行此练习,我选择了三种不同的架构,即 R(2+1)D、SlowFast 3D ResNet 和 TimeSformer,所有这些架构都在 Kinetics-400数据集进行了预训练。 如下面取自模型脚本的代码片段所示,我下载了架构及其相应的权重,并在分类器头之前剪切了每个模型。 这样,对于输入中的每个视频,前向函数提取其相应的嵌入向量。
class Identity(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
class TimeSformer(nn.Module):
def __init__(self):
super().__init__()
self.base_model = TimesformerModel.from_pretrained("facebook/timesformer-base-finetuned-k400")
def forward(self, x):
x = self.base_model(x)
x = x.last_hidden_state
# the output of the timsformer is [B, T, E], with B the batch size, T the number of the sequence tokens and E the embedding dimensions
# take just the first component of the second dimension, namely the embedding tensor relative to the classification token for all the tensors in the batch
x = x[:, 0, :]
return x
class R2plus1d_18(nn.Module):
def __init__(self):
super().__init__()
self.base_model = models.video.r2plus1d_18(weights=R2Plus1D_18_Weights.DEFAULT)
self.base_model.fc = Identity()
def forward(self, x):
x = self.base_model(x)
return x
class R3D_slowfast(nn.Module):
def __init__(self):
super().__init__()
self.base_model = torch.hub.load("facebookresearch/pytorchvideo", "slowfast_r50", pretrained=True)
self.base_model.blocks[6].proj = Identity()
def forward(self, x):
x = self.base_model(x)
return x在继续之前,我想对三个预训练的时空模型进行简要描述。
3、R(2+1)D 残差网络
在论文“A Closer Look at Spatiotemporal Convolutions for Action Recognition”[4]中,作者评估了残差学习框架内用于动作识别的不同时空卷积架构。
乍一看,3D 卷积网络看起来像是处理视频剪辑的理想架构。 它们保存时间信息并通过网络各层传播它。 如图[2]所示,使用大小为 t × d × d 的滤波器进行全 3D 卷积,其中 t 表示时间范围,d 是空间宽度和高度,因此滤波器在时间和时间上都进行卷积。 空间维度。
另一种时空变体是“(2+1)D”卷积块,它将 3D 卷积显式分解为两个独立且连续的操作:2D 空间卷积和 1D 时间卷积。 如图2所示,第 i 个块中大小为 Ni−1 × t × d × d 的 N_i 3D 卷积滤波器被替换为由 M_i 2D 卷积滤波器组成的 (2+1)D 块 大小为 Ni−1 × 1 × d × d 和 N_i 个大小为 Mi × t × 1 × 1 的时间卷积滤波器。超参数 M_i 确定信号在空间和时间卷积之间投影的中间子空间的维数,及其 值是固定的,以便 (2+1)D 块中的参数数量与完整 3D 卷积块中的参数数量相匹配。
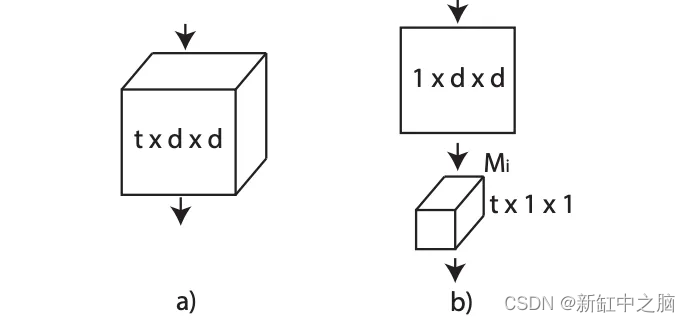
图2: 3D 与 (2+1)D 卷积
与全 3D 卷积相比,(2+1)D 分解具有两个优点。 首先,尽管没有改变参数的数量,但由于每个块中 2D 和 1D 卷积之间的额外 ReLU,它使网络中的非线性数量增加了一倍。 此外,相同层的训练误差更小。 图3对此进行了说明,其中显示了具有 18 层和 34 层的 R3D 和 R(2+1)D 的训练和测试误差。 可以看出,对于相同数量的层(和参数),与 R3D 相比,R(2+1)D 不仅产生更低的测试误差,而且产生更低的训练误差。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









