






前言
注意力机制+时空特征融合,是一个创新拉满的高分思路!
近来更是取得了新突破,模型STA-DRN在面部视频识别任务中,误差直降43.34%;模型MFF-EINV2在定位任务中,参数狂减68.5%……不仅如此,其在CVPR24、AAAI24等顶会上也都有不少成果。
可见其热度!这主要得益于,该结合能显著提升模型对复杂数据的处理能力,为需要同时考虑时间和空间维度的任务提供了新思路,像是遥感、交通预测、金融、医学等。时空特征融合能整合来自不同时间和空间尺度的信息,为模型提供更丰富的特征输入。而注意力机制则能动态调整不同特征的权重,使模型更加关注任务相关的信息。
此外,想发论文的伙伴,可以多关注时空特征融合策略、模型鲁棒性和泛化性提升等。为让大家能获得更多idea启发,我给大家准备了15种前沿思路和源码!
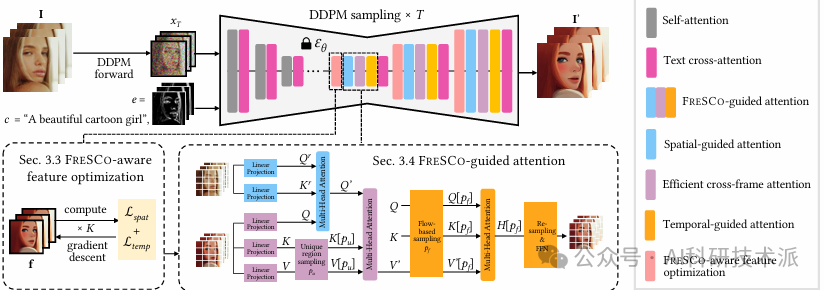
FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translatio
内容:论文介绍了FRESCO,这是一个用于零样本视频翻译的空间-时间对应框架。它通过结合帧内和帧间对应关系,提供了一种鲁棒的空间-时间约束,以确保在视频帧之间转换时保持语义相似内容的一致性。这种方法显著提高了视频翻译的视觉连贯性,并在多个实验中展示了其在生成高质量、连贯视频方面的有效性。
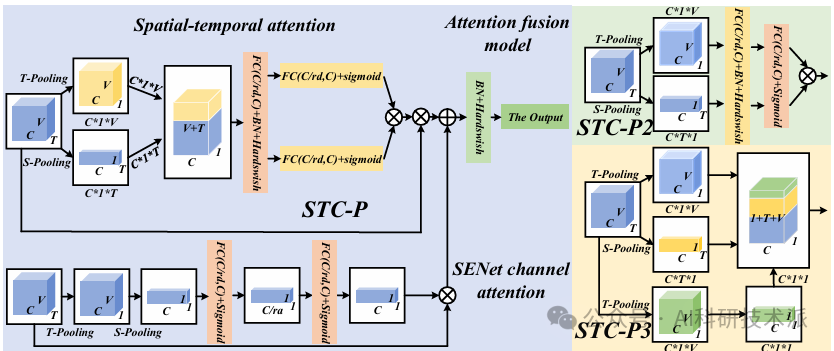
Behavioral Recognition of Skeletal Data Based on Targeted Dual Fusion Strategy
内容:文章介绍了一种基于目标导向的双融合策略的行为识别方法,通过提出前-后双融合图卷积网络(FRF-GCN)和空间-时间-通道并行注意力(STC-P)机制,旨在从骨骼数据中提取互补特征,提高识别准确性,同时降低模型复杂性和参数数量。该方法在NTU RGB+D、NTU RGB+D 120和Kinetics-Skeleton 400数据集上显示出与当前最先进方法相比具有显著的竞争力。
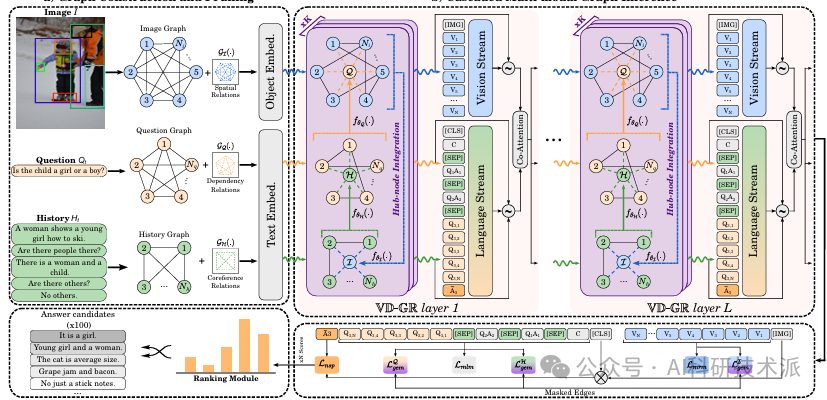
VD-GR: Boosting Visual Dialog with Cascaded Spatial-Temporal Multi-Modal GRaphs
内容:这篇论文介绍了VD-GR,这是一个结合了预训练语言模型(如BERT)和图神经网络(GNNs)的新型视觉对话模型。VD-GR通过在多模态GNN和BERT层之间交替,利用GNNs处理图像、问题和对话历史的局部结构,然后通过BERT层进行全局注意力机制,并通过引入中心节点(hub-nodes)在不同模态图之间进行信息的级联传播,从而增强模型对多模态上下文的理解。
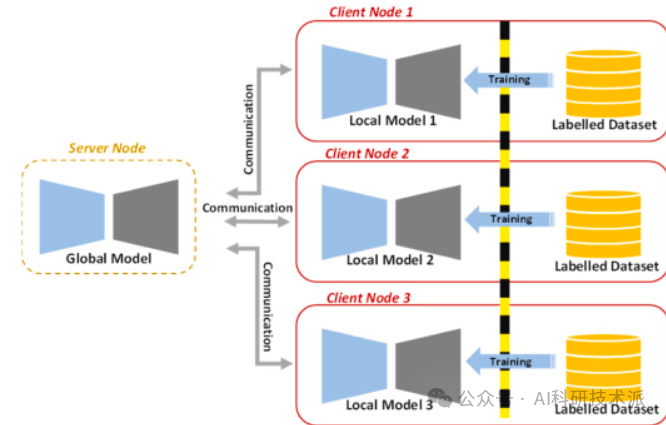
Self-supervised spatial–temporal transformer fusion based federated framework for 4D cardiovascular image segmentation
内容:文章介绍了一种基于联邦学习的自监督空间-时间变换器融合(SSFL)框架,用于4D心血管图像分割。该框架利用空间-时间Swin变换器从3D SAX多个阶段(心脏完整周期)提取特征,并通过一个包含25个编码器的高效自监督对比框架来建模时间特征。然后将空间和时间特征融合并传递给解码器,以使用电影MRI图像进行心脏分割。
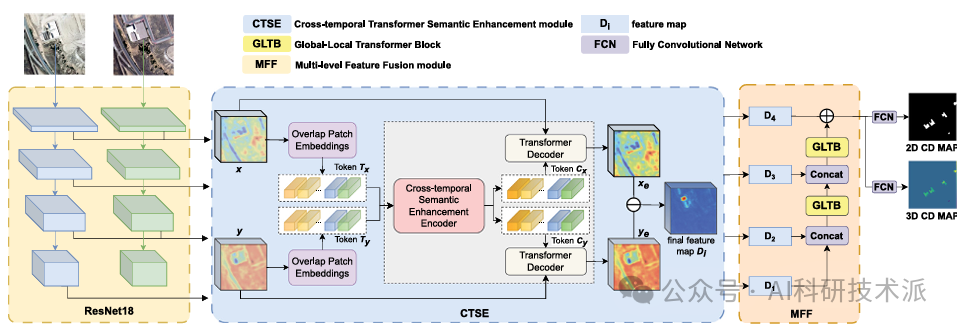
Cross-temporal andspatial information fusion for multi-task building change detection using multi-temporal optical imagery
内容:文章介绍了一种名为Cross-temporal and Spatial Context Learning Network (CSCLNet)的多任务建筑变化检测网络,它能够同时捕捉2D和3D变化,以提高从双时相光学图像中检测建筑变化的准确性。CSCLNet利用卷积神经网络提取多层语义特征,并通过两个模块——Cross-temporal Transformer Semantic Enhancement (CTSE)和Multi-layer Feature Fusion (MFF)——来优化特征表示,分别增强时间信息和融合多层特征以关注全局和局部空间上下文。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









