







论文代码:https://github.com/basiralab/RegGNN
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用!
目录
2.3.3. Learning-based sample selection
2.4.1. Explainability and biomarker discovery
1. 省流版
1.1. 心得
(1)很数学
(2)所以那个半正定相关矩阵是怎么回事啊
1.2. 论文总结图

2. 论文逐段精读
2.1. Abstract
①⭐They think the relationship between intellegence and neural activity is useful for understanding the pathology of brain diseases(他这里的描述是人脑在健康和疾病下的工作机制,我认为更契合pathology而不是etiology,不过我对一来就是这个说法持保留意见...智力为什么会和脑疾病有关系?)
②Flattening the brain network might ignore its topological features
③Thus, they proposed a regression GNN model (RegGNN) to predict IQ from brain connectome
④“连接体(即它们的邻接矩阵)位于对称正定(SPD)矩阵锥”(我不是很认可呢!?我理解有问题吗??)

这哪里是正定的啊!!是吗??!还是说我数学不好。
文心给的说法:

(⭐之后讨论得来,功能连接矩阵并非天然正定,如果是
| 0 | 0.5 | -0.2 |
| 0.5 | 0 | -0.3 |
| -0.2 | -0.3 | 0 |
这样的矩阵,无论是丢弃负连接还是全取绝对值都不是正定矩阵。
大概,可能,唯有将自连接全设为1,因为其他所有皮尔逊相关不大于1,才可能是正定)
2.2. Introduction
①⭐Cognitive scores reflect the intellegence, education level, health and mortality(牛). Thus, many researchers focus on how brain structure influences the IQ. Then they find there is a positive relationship between cerebral volumn and cognitive ability, and the lateral prefrontal cortex is related to IQ
②The other researchers try to find the relationship between functional connectivities and cognitive scores
③Some traditional machine learning achieve success but do not consider the graph structure. And a lot of GNNs do good in disease classification as well. However, there is no deep learning graph neural network model specifically designed for predicting cognitive scores through brain regression
④They independently put forward a learning-based sample selection approach to identify those samples with the highest predictive power. It increases the predicted probability and decreases the running time
⑤⭐作者认为脑网络的邻接矩阵是对称且半正定的,在经过正则化之后可以变成对称的正定矩阵(emmm为什么呢?我不是特别能理解,而且文心说:
矩阵正则化并不保证矩阵会变成正定矩阵。矩阵正则化的目的是通过增加一些条件(如稀疏性或平滑性)来改善矩阵的性质,以提高模型的稳定性和泛化能力。正则化方法如奇异值分解(SVD)、主成分分析(PCA)和正则化线性回归等,可以通过最小化损失函数和增加正则化项来达到稳定模型和防止过拟合的效果。
然而,这些正则化方法并不保证将矩阵转换为正定矩阵。矩阵的正定性取决于其元素之间的关系和性质,而这些关系和性质在正则化过程中可能不会得到显著改善。因此,正则化后的矩阵是否为正定矩阵取决于具体的应用场景和数据特性。
总之,矩阵正则化并不保证矩阵会变成正定矩阵,其目的在于提高模型的稳定性和泛化能力。)。并且,作者说对称半正定矩阵的空间会形成非线性流形。“在其上使用黎曼几何结构,以获得两个连接体之间的距离的自然概念,以及编码实现该距离的路径的切矩阵”。
⑥Their contributions: propose a) sample selection method, b) new method of brain connectome similarity measurement, c) pipeline
mortality n. 死亡人数,死亡率;必死性,终有一死;死亡
2.3. Methods
Notations in this paper:

2.3.1. Preliminaries
①All the form a cone manifold space. Every point
has a tangent space
.
②They can calculate the angles between (and norms of) tangent matrices(鼠鼠不懂数学)
③The geodesics of
can be represented as the unique tanget matrix
(继续不懂)
④The SPD space in Riemannian maninfold:
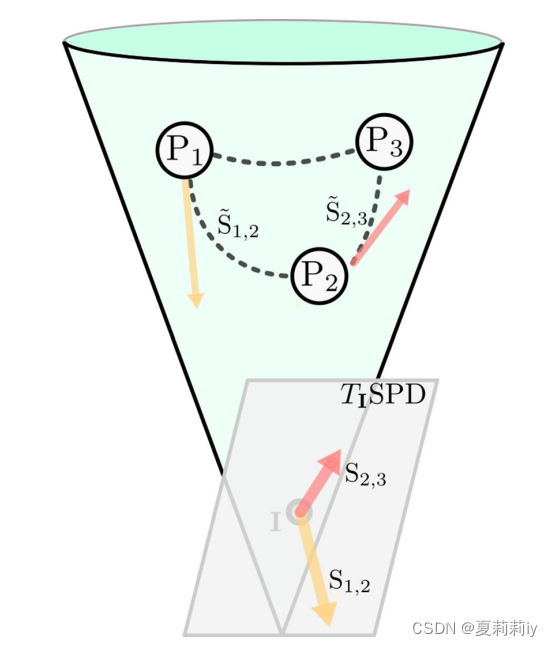
where the dashed lines are geodesics, arrows are tangent matrices;
different from in Euclidean domain, tangent matrices of can not directly be compared, but mapping them in the same point
by parallel translation
⑤They choose the Log-Euclidean metric for the in that it does not rely on path to
and exist only one minimum length geodesic line between two points
geodesic adj. 测地线的;测量的(等于 geodetic);[测]大地测量学的 n. [测]测地线
2.3.2. RegGNN
①RegGNN combined with 2 convolutional layers and a down stream fully connected layer
②The overall framework of RegGNN:

where denotes the number of ROIs;
denotes the correlation matrices(作者在这里又说关联矩阵可以有为0的特征值但是不能有为负的。这个关联矩阵是邻接矩阵吗?还是FC呢?但是感觉都没有不能为负吧?);
然后作者意思似乎B-i最右上试train-in set自己pairwise的切矩阵,下面那个是train-in到holdout set (validation set)的切矩阵
③Through multiplying a multipled identity matrix, the correlation matrix can be regularized to symmetric positive definite:
④For some small (?只针对这些咩?其他情况就不?), they change all the negative eigenvalue to 0(我不是很能理解他之前说压根没有负特征值啊)because the positive correlations are probably more important than negative
⑤The propagation rule is:
with and
;
where ,
is the diagonal degree matrix of
,
is a learnable weight matrix with
⑥Applying dropout layer after the first graph convolutional layer as regularization
⑦The final vectors contain features each (
)
2.3.3. Learning-based sample selection
①They divide the subjects in groups and then choose
samples which are closest to the center (nearest to the mean value)
②The authors hope the similar input, brain connectome, could obtain a series similar output, i.e. cognitive scores
③⭐Their goal is learning the difference between cognitive scores through connectome。 Then they can find "representatives". Through few representatives, they can predict scores as accurately as possible
④Adopting N fold cross-validation in sample selection
⑤The number of samples in train-in set is and in holdout set is
⑥The tangent matrix calculated by Riemannian:
⑦The number of pairwise train-in matrices are
. Its feature vector is
⑧Then get matrices between train-in sample
and holdout sample
. The number of them are
. Its feature vector is
⑨To reduce the dimension of tangent matrices, they apply topological features such as degree, closeness, and eigenvector centrality
⑩The model learns a linear mapping by training
to
. Then mapping
to
reductionist adj. 简化(法)的;分解成简单部分的 epigenetics n. [胚] 实验胚胎学,表观遗传学
2.3.4. Training process
①They split data into training set and test set
②Selecting the top representative samples
③Only train the model with the samples by cross-validation
2.3.5. Data and methodology
①The aim of this experiment is to predict the full scale intelligence quotient (FIQ) and verbal intelligence quotient (VIQ) from HC and ASD
(1)Dataset
①Dataset: Autism Brain Imaging Data Exchange (ABIDE)
②To alleviate the differences between different sites, they randomly select samples from HC group and ASD group. Finally, the choose 226 HC (they call it NT there, neurotypical) and 202 ASD
③Number of ROIs: 116
④FC: Pearson correlation(好了,为什么皮尔逊相关系数没有负特征值?为什么一定是半正定矩阵?)
(2)Parameter settings
①Optimizer: Adam
②Epochs: 100
③Learning rate: 0.001
④Weight decay: 0.0005
⑤Dropout rate: 0.1 after the first graph convolutional layer
⑥μ=1e-10
(3)Evaluation and comparison methods
①Cross-validation: 3-fold
②Measurements: mean absolute error (MAE) and root mean squared error (RMSE)
③They also apply grid search
④They choose CPM and PNA as baselines
(4)Evaluation of the sample selection
①They adopt vectorized upper triangular of tangent matrix (tm) in encoding and apply degree centrality (dc), eigenvector centrality (ec), and closeness centrality (cc) respectively
②Moreover, they test the unscaled concatenation (cnu) and scaled concatenation (cns) with the min-max scaling method:
③The report the p value of each methods
attenuation n.衰减;稀释;变薄
2.4. Results and Discussion
①Prediction on NT


②Prediction on ASD


2.4.1. Explainability and biomarker discovery
①They visualize the highest learnable weights (average of all the ):

②They drew a conclusion that IQ mostly influenced by the left hemisphere of brain
2.5. Conclusion
Through few selected samples, they can achieve good results in RegGNN
3. 知识补充
3.1. Matrix cone
(1)我在百度和bing都没有找到很官方的定义
(2)文心:
"Matrix cone" 是一个数学概念,通常在优化理论和线性代数中出现。它通常表示一个特定的集合或矩阵集合,具有某种特定的性质或约束条件。
在优化理论中,一个“cone”是一个凸集,它关于原点是闭集和凸集,并且对于任何正标量k,都有k倍的集合元素仍在集合中。例如,一个典型的cone是所有非负实数的集合,即所有满足x ≥ 0的实数x的集合。
"Matrix cone" 可能是指一个由特定类型的矩阵构成的集合,这些矩阵满足某些约束条件或性质,例如非负性、半正定性等。
在某些情况下,"matrix cone" 可能指的是一个特定的矩阵集合,这些矩阵具有某种特定的结构或性质,例如特定的秩、特定的特征值等。
因此,"matrix cone" 的具体含义取决于上下文和所讨论的数学领域。如果您能提供更多的上下文或背景信息,我可能能够给出更具体的解释。
(3)由文心的来看,文中的矩阵锥表示了脑网络的邻接矩阵都是属于对称正定集合中
3.2. Few-shot learning
Few-shot Learning(少样本学习)是一种机器学习方法,旨在使用较少的训练数据来构建准确的机器学习模型。这种方法在计算机视觉领域尤其重要,因为它使机器能够处理物体识别、手势识别和对象跟踪等任务。
少样本学习与传统的监督学习的主要区别在于训练数据的使用方式。在传统的监督学习中,训练数据被分为训练集和测试集,模型在训练集上训练,然后在测试集上评估。而在少样本学习中,数据被分为训练集、支持集和查询集。训练集用于训练模型,使其具备区分不同样本异同的能力。支持集为模型提供更多信息,以帮助模型预测查询集中的样本的类别。
少样本学习的目标是使机器能够从极少量的样本中快速学习新类别。例如,小孩子只需要看几张图片就能识别出什么是“斑马”,什么是“犀牛”。少样本学习的目标就是让机器具备这种快速学习能力。
此外,少样本学习还可以用于解决罕见情况的问题。例如,在对动物图像进行分类时,使用少样本学习技术训练的机器学习模型可以在接触少量先验信息后正确分类稀有物种的图像。
少样本学习可以显著减少数据收集工作和计算成本。由于少样本学习需要较少的训练数据,因此可以避免与大量数据收集和标记相关的高成本。同时,由于训练数据量较少,训练数据集中的维数较低,可以显著降低计算成本。
总的来说,少样本学习是一种非常有前途的机器学习方法,它可以提高机器的自主学习能力,使其能够快速适应新任务和新环境。
4. Reference List
Hanik M. et al. (2022) 'Predicting cognitive scores with graph neural networks through
sample selection learning', Brain Imaging and Behavior, 16 doi: Predicting cognitive scores with graph neural networks through sample selection learning | Brain Imaging and Behavior















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









