






 文章讨论了数字孪生技术如何应用于故障预测与健康管理(PHM)领域。作者指出,健康状态评估应基于设备内部状态估计,而不仅仅是工作参数测量。提出了基于数字孪生的设备健康状态评估研究框架,包括多维度模型构建、数据映射、状态一致性度量和模型修正。此外,文章强调了模型误差管理和校准的重要性,以及模型需能反映工作过程和失效机理。
文章讨论了数字孪生技术如何应用于故障预测与健康管理(PHM)领域。作者指出,健康状态评估应基于设备内部状态估计,而不仅仅是工作参数测量。提出了基于数字孪生的设备健康状态评估研究框架,包括多维度模型构建、数据映射、状态一致性度量和模型修正。此外,文章强调了模型误差管理和校准的重要性,以及模型需能反映工作过程和失效机理。
4. 数字孪生与PHM
正好讲到PHM算法与模型这一块,我们简单交流一下数字孪生技术在PHM领域中的应用问题。近年来,数字孪生的概念和技术架构研究一直都非常火。数字孪生概念已经应用到了很多的领域里面,包括故障预测与健康管理领域。现在我们去查看各种指南,总能看到类似于“基于数字孪生的XXXX设备健康状态评估方法研究”之类的题目。但是如果仔细看指南的内容,又语焉不详,只有短短几句话,不知道指南到底要做什么。那问题来了,数字孪生到底能不能在PHM技术领域里面用,是炒作概念,还是说确确实实能解决一些特定的问题,这里我抛砖引玉,简单的讨论一下这个问题。
在正式讨论这个问题之前,我们先来看PHM技术中的一个基本问题,就是设备的健康状态应该如何评估?现在有很多种健康状态评估的方式,有使用健康状态分类的,就是把设备的健康状态分为:健康、亚健康、异常、故障。这样一来,健康状态评估就变成了分类问题。还有一种采用健康指数的方式来评估,类似于可靠度的方式,将设备的健康指数定义为0到1之间的一个数字。越接近1,设备越健康。
两种方法都具有各自的优缺点,它们分别从某一角度出发评估了设备的状态以及状态的变化趋势,但是如果评估结果仅仅给出健康或者不健康,多大程度健康,而不提供更多的信息,显然对于PHM应用来讲是不够的。实际上,判断一种健康状态评估方法好坏,我们应该看这种评估方法能给PHM技术带来什么。从前面的介绍中,我们已经看出来了,在整个PHM技术框架中,故障检测、故障诊断、健康状态评估、故障预测、维修决策是环环相扣的,所有的项目最终都服务于维修。健康状态评估也不例外,脱离了以维修为目的的状态评估,就变成了为了评估而评估的数字游戏。类比于可靠性评估,可靠性评估的结果最终服务于产品设计,无论是可靠性试验评估还是可靠性模型评估的结果都是为了发现系统设计中潜在的薄弱环节,通过有针对性的改进来提升系统的可靠性。健康状态评估的结果也需要为维修决策提供建议和指导。同样类比于医学上的健康评估,我们看一下医学上的健康评估是怎么评估的。这是一张人员健康评估报告。
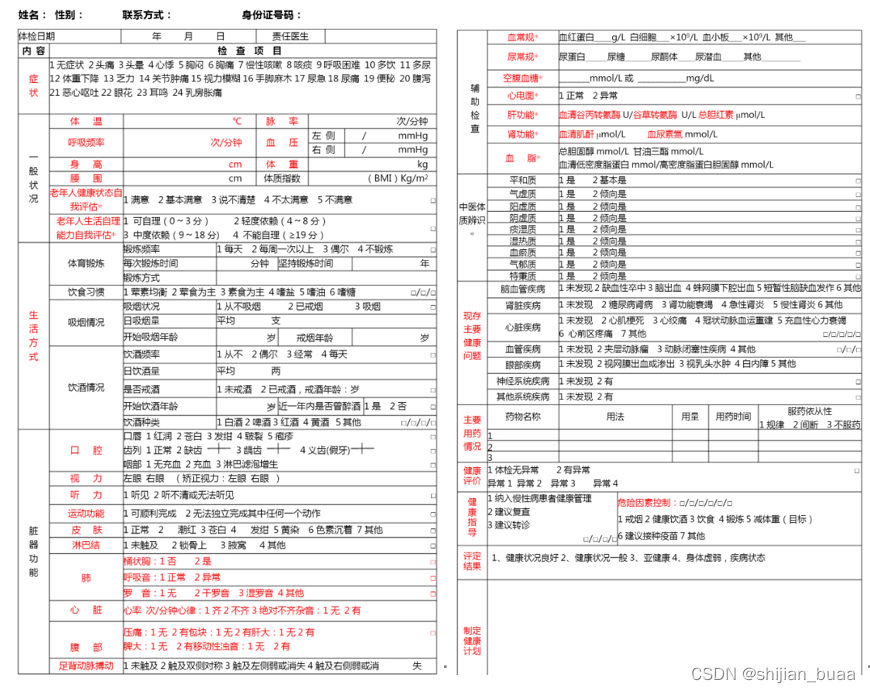
可以看到报告的前半部分是各种检测结果的记录,最后几项是“健康评价”、“评定结果”和“制定健康计划”。举个例子,健康评估结果为“整体健康状况良好,存在中度骨质疏松,建议避免对抗性激烈的运动,日常饮食中多食用含钙高的食物以及维生素高的食物……”。这翻译成设备的健康状态评估结果可以是“设备总体健康状况良好,传动轴丝杠和螺母配合面因磨损存在约70µm间隙,建议避免高负载运行,避免运行于五级以上的海况环境,每运行30小时须监测其轴向振动量,增加润滑,200 小时后建议更换传动轴”。这种健康状态评估有几个关键要素:它基于设备内部状态的估计(“因磨损存在约70µm间隙”),给出了维修决策信息(“每运行30小时须监测其轴向振动量,增加润滑”),同时给出了剩余寿命的基本预测结果(“200小时后建议更换传动轴”),另外还给出了任务计划的建议(“避免高负载运行,避免运行于五级以上的海况环境”)。所以说这样一个健康状态评估结果是PHM最为期望的结果。这样一个结果也表明:设备健康状态评估必须建立在对设备内部状态估计的基础上。
但是现在很多健康状态评估研究基本上都是建立在对工作参数测量基础上的评估。比如对于液压泵来说,测量液压泵的输出压力、壳体温度、壳体轴向和径向的振动能量谱。首先设定正常液压泵的输出压力、壳体温度、壳体轴向和径向的振动能量谱的标准特征。然后实际测量得到的压力、壳体温度、壳体轴向和径向的振动能量谱特征与标准值求距离,进行归一化,然后加权求和得到健康指数。

这里就存在一个问题,测量得到的工作参数是一个因变量,不是一个自变量。测量得到的工作参数受到设备内部的状态、环境条件共同影响。差异度量的结果同时反映设备内部状态的差异和设备运行工况的差异,并且这两方面的差异究竟哪方面占主导地位具有不确定性,所以这种健康度评估结果的有效性存在一定的疑问。
另一方面,即便是健康度评估结果主要反映设备的内部状态差异。由于液压泵内部的磨损、疲劳和老化同时反映在泵的输出压力、壳体温度、壳体轴向和径向的振动能量谱上。仅仅得到差异度量的结果也没有办法估计得到泵内部真实的状态。实际上,“泵内部磨损严重,轻度疲劳和老化”与“泵内部轻度磨损,重度疲劳和老化”,两种情况都可能得到同样的健康度评估结果,比如都为0.85。但是这两种情况分别对应两种不同的维护策略和两种不同的后续工作计划。因此,采用这种评估方式很难提供有效的维修决策信息。
基于上面我们讲到的健康状态评估的问题,我们还是回到健康状态评估最基本的问题上来,也就是健康状态评估必须建立在对设备内部状态估计的基础上,也就是说如何通过测量得到的信息,估计得到系统内部的状态信息,基于这种内部状态信息的估计结果评估设备的健康状态。

设备状态估计,需要有估计模型,并且该模型的输入是测量得到的各种参数特征,以及环境参数,输出为内部状态的估计结果,比如:表征磨损状态的间隙、表征疲劳状态的刚度系数、裂纹长度,表征老化状态的永久变形量、磁链之类的值。
要能够做到这种状态估计,就需要有相应的能够表征内部状态、环境条件与系统工作参数之间关系的多维度模型。

上面构建这些模型是出于对系统内部状态评估的需要。我们看一下PHM应用的另一个场景。我们看前面的健康状态评估的例子,“……,200小时后建议更换传动轴”。这里有一个关于内部状态在未来变化趋势的预测问题。也就是说我们构建的这种多维度模型必须要保证状态信息跟随工况信息动态的演化。基于这种演化过程,我们预测设备的剩余使用寿命,并动态调整任务规划。要真正达到这一效果,必须要实现真实工况到模型运行环境的多物理场映射,模型的运行结果要和实际设备的输出结果进行一致性度量,误差可控。否则通过模型估计得到的状态不能反映设备的真实状态,由此得到的预计结果不具有参考意义。
还有一个问题我们要思考一下,只要有参考模型,必然存在着三种误差,也就是建模误差、解算误差、实际物理信息转为模型信息的测量和转换误差。由于存在模型演化过程,这些误差随着模型的运行会不断的累积,导致一开始比较精确的模型,运行一段时间误差会越来越大,甚至误差大到无法反映设备真实状态的程度,这个时候必须要进行模型校准和参数优化。我们把上述这几部分内容合在一起,构成了这样一个技术体系。

这基本上就构成了基于数字孪生的设备健康状态评估的研究框架。总结一下,其中的核心内容包括四块:(1) 基于第一性原理的多维数字孪生模型构建;(2) 虚实空间的多维数据映射;(3) 孪生体技术状态一致性度量与模型的高效迭代修正;(4) 基于多域特征的系统健康评估、预测与维护决策。
真正要实现这样一个架构,对模型提出的要求是什么?模型是要能够反映工作过程和失效机理的多维度模型。也就是意味着使用机器学习的方式构建起来的拟合模型存在一定的局限性。比如神经网络模型中的权值没有实际的物理意义,即便是权值可调整,也很难将权值与系统内部状态变量联系在一起。
关于数字孪生技术在PHM领域中的应用问题我们大概先讲这么多。为什么讲完模型和算法之后讲数字孪生呢,因为从上面我们分析的过程也可以直观的看出来,基于数字孪生的健康状态评估本身属于基于模型的预测方法的范畴。这里只是抛砖引玉,以后我们可以进行更深层次的讨论。

















 1380
1380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









