









经验时代:人工智能的下一个前沿 —— 解读 David Silver 与 Richard S. Sutton 的新作
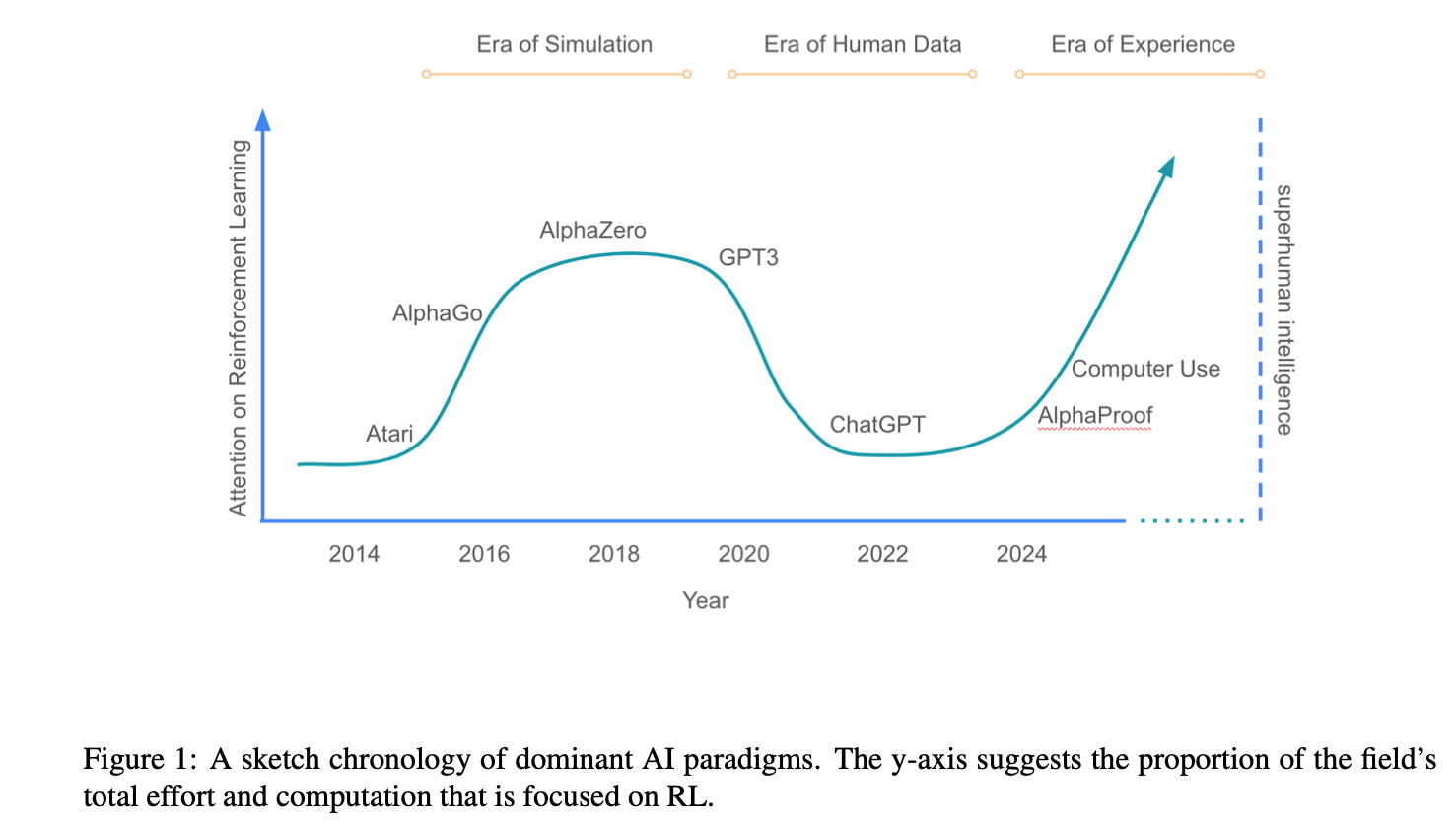
人工智能(AI)的快速发展正在将我们带入一个全新的时代——“经验时代”(The Era of Experience)。在 David Silver 和 Richard S. Sutton 合著的论文《Welcome to the Era of Experience》中,两位强化学习(Reinforcement Learning, RL)领域的巨擘深入探讨了 AI 从依赖人类数据向通过自身经验学习转型的趋势。这篇论文不仅总结了当前 AI 发展的瓶颈,还为未来的技术突破指明了方向。本文将详细介绍这篇论文的核心思想,分析其洞见,并简要介绍两位作者的背景及其在 RL 领域的贡献。
paper链接:Welcome to the Era of Experience
论文背景与核心问题
从人类数据时代到经验时代的转变
论文开篇指出,当前 AI 的成功主要依赖于大规模的人类生成数据。例如,大型语言模型(LLMs)通过海量文本数据和人类专家的反馈(例如 RLHF,Reinforcement Learning from Human Feedback)实现了广泛的通用能力,从写诗到解决物理问题,再到法律文档摘要,LLMs 几乎无所不能。然而,这种依赖人类数据的模式正在触及其天花板:
- 数据瓶颈:高质量的人类数据(例如数学证明、代码、科学文献)正在被迅速消耗殆尽。论文提到,诸如数学、编程和科学等领域,人类数据的知识边界正在限制 AI 的进一步提升。
- 创新局限:仅依靠模仿人类数据,AI 无法突破人类知识的边界,无法创造全新的定理、技术或科学突破。
- 进步放缓:完全依赖监督学习(Supervised Learning)的进步速度正在减慢,表明需要一种新的方法来推动 AI 迈向超人类智能。
为此,论文提出了“经验时代”的概念:AI 需要从自身的交互经验中学习,而不是仅仅依赖人类数据。通过与环境的持续交互,AI 能够生成动态的数据流,从而突破人类知识的限制,实现超人类的性能。
经验时代的定义
经验时代的核心在于,AI 代理(Agent)通过与环境的交互生成数据,并从中学习。这种学习方式具有以下特点:
- 动态数据生成:与静态的人类数据不同,经验数据是动态的,随着代理能力的增强而不断改进。
- 持续学习:代理在长期的经验流(Streams of Experience)中持续适应和优化,而不是局限于短期的交互片段。
- 自主性:代理通过丰富的动作和观察与环境互动,而不仅仅依赖人类语言或预判断的反馈。
- 环境奖励:代理的奖励信号直接来源于环境(Grounded Rewards),例如健康指标、考试成绩或科学实验结果,而不是人类的主观评价。
论文以 AlphaProof 为例,展示了经验学习的潜力。AlphaProof 在国际数学奥林匹克竞赛中获得银牌,其成功得益于通过强化学习生成数亿条数学证明,远超初始的人类提供的十万条证明。这种自主探索使 AlphaProof 能够解决超出人类已有知识的复杂问题。
经验时代的四大关键维度
论文详细阐述了经验时代 AI 代理的四个关键特征,这些特征共同定义了这一新时代的范式:
1. 经验流(Streams of Experience)
与当前基于短交互片段(例如用户提问-模型回答)的 AI 不同,经验时代的代理将生活在长期的经验流中。这种模式类似于人类或动物的持续学习过程:
- 长期目标:代理能够为远期目标(例如改善健康、学习语言、科学突破)采取行动,而不仅仅局限于即时响应。
- 持续适应:代理通过长期的经验积累信息,调整行为以适应环境变化。例如,一个健康助手可以根据用户数月内的睡眠、活动和饮食数据,提供个性化的建议。
- 示例应用:教育代理可以跟踪学生数年的学习进度,动态调整教学方法;科学代理可以通过长期实验和模拟,探索新材料或减少碳排放。
这种长期经验流使 AI 能够超越短视的即时优化,追求更复杂、更有远见的任务。
2. 丰富的动作与观察(Actions and Observations)
经验时代的代理将通过丰富的动作和观察与环境交互,而不仅仅依赖语言对话:
- 自主性增强:代理可以直接操作数字世界(例如调用 API、运行代码)或物理世界(例如控制机器人手臂、操作望远镜)。例如,论文提到一些原型代理已经开始通过人类界面(如键盘和屏幕)操作计算机。
- 探索与发现:通过自主交互,代理能够发现人类未曾想到的策略。例如,一个科学代理可以通过实验探索未知领域,而无需依赖人类的预设假设。
- 人机协作:代理既可以使用“人类友好”的界面与用户沟通,也可以通过“机器友好”的动作(如执行代码)自主行动。
这种丰富的交互方式使代理能够更深入地理解和控制环境,从而实现更高效的任务执行。
3. 环境奖励(Grounded Rewards)
当前的人类中心 AI 依赖人类预判断的奖励(例如专家对模型输出的评分),这限制了 AI 的创新能力。经验时代的代理将使用直接来源于环境的奖励信号:
- 奖励来源:环境提供了丰富的信号,例如健康指标(心率、睡眠时长)、教育成果(考试成绩)、科学测量(材料强度、碳排放水平)等。
- 超越人类知识:环境奖励使代理能够发现超越人类评判的策略。例如,一个健康助手可以根据用户的实际健康数据优化建议,而不是依赖医生的主观评价。
- 用户引导的奖励:论文提出了一种灵活的奖励函数设计,通过神经网络结合用户目标和环境信号生成奖励。例如,用户指定“提高健身水平”,奖励函数可以综合心率、步数等数据生成奖励信号。
这种基于环境的奖励机制使 AI 能够突破人类知识的限制,追求真正的创新。
4. 规划与推理(Planning and Reasoning)
经验时代的代理将发展出超越人类语言的推理方式:
- 非人类推理:当前 LLM 的推理模仿人类思维(例如链式推理,Chain-of-Thought),但论文认为更高效的推理方式可能基于符号、分布式或可微计算。AlphaProof 的数学证明过程便展示了非人类推理的潜力。
- 世界模型:代理可以通过构建世界模型预测其动作对环境的影响。例如,一个健康助手可以预测推荐健身房对用户心率的影响。这种模型通过持续的经验更新,修正预测误差。
- 现实反馈:通过与环境的交互,代理可以检验假设、发现错误并更新推理方式。这种基于现实的反馈循环类似于人类科学的进步过程,避免了仅依赖人类数据的“回音室”效应。
这些特性共同使代理能够在复杂环境中进行高效的规划和推理,超越人类的认知局限。
经验时代的意义与挑战
潜在影响
经验时代的到来将带来深远的变革:
- 个性化服务:AI 助手将通过长期经验流为用户提供高度个性化的健康、教育或职业建议。例如,一个教育代理可以根据学生的学习风格和进度,持续优化教学内容。
- 科学加速:科学代理将自主设计和执行实验,加速材料科学、医学和硬件设计等领域的发展。例如,AI 可以在短时间内探索新型药物或材料,显著缩短研发周期。
- 任务通用性:经验时代将结合人类数据时代的任务广度与模拟时代(Era of Simulation)的自主发现能力,创造出既通用又创新的 AI 系统。
挑战与风险
尽管前景光明,经验时代也带来了新的挑战:
- 就业冲击:自动化能力的提升可能导致某些行业的就业岗位减少。
- 可解释性:偏离人类思维模式的 AI 系统可能更难理解和控制。
- 安全风险:自主代理的长期交互可能减少人类的干预机会,增加误操作或目标偏差的风险。例如,一个优化单一目标的代理可能引发类似“回形针问题”(Paperclip Problem)的不良后果。
- 伦理问题:如何确保代理的行为符合人类价值观,以及如何平衡自主性与可控性,是亟待解决的问题。
安全优势
论文也提到了一些潜在的安全优势:
- 环境适应性:经验代理能够感知环境变化并调整行为。例如,面对硬件故障或社会变革,代理可以动态适应。
- 奖励修正:通过用户反馈和环境信号,奖励函数可以逐步修正偏差,避免灾难性后果。
- 物理限制:基于物理经验的 AI 受限于现实世界的时间和资源约束,这可能为人类干预提供缓冲时间。
为什么现在是经验时代的起点?
论文指出,当前的 RL 技术已经为经验时代奠定了基础。例如,AlphaZero 在棋类游戏中通过自我博弈发现了全新策略,展示了 RL 的自主发现能力。此外,新的 RL 方法(例如 AlphaProof 和 DeepSeek 的工作)证明了在开放性问题和复杂推理空间中 RL 的潜力。
与此同时,人类数据时代的局限性正在显现,而自主代理(例如通过人类界面操作计算机的原型系统)的兴起为经验时代的到来提供了技术支持。论文认为,AI 社区的持续创新将进一步推动这一转型。
对论文的洞见与思考
洞见 1:数据生成方式决定 AI 的天花板
论文的核心洞见在于,AI 的能力上限由其数据生成方式决定。人类数据的静态性和有限性限制了 AI 的创新能力,而动态的经验数据则为突破这一限制提供了可能。这种观点挑战了当前以数据量为核心的 AI 发展范式,强调了数据质量和生成方式的重要性。
洞见 2:环境是最好的老师
通过与环境的直接交互,AI 能够获得最真实的反馈。这种基于环境的反馈循环类似于人类的科学方法论:提出假设、实验验证、更新知识。论文提出的世界模型和环境奖励机制,为 AI 提供了一种“科学化”的学习方式,使其能够超越人类的预设知识。
洞见 3:自主性与通用性的平衡
经验时代的 AI 既需要自主性(以发现新知识),又需要通用性(以处理多样化任务)。论文提出的用户引导奖励机制和灵活的奖励函数设计,为这一平衡提供了一种可能的解决方案。这种方法允许 AI 在自主探索的同时,保持与人类目标的对齐。
洞见 4:RL 的复兴
论文标志着 RL 在 AI 领域的复兴。在人类数据时代,RL 被监督学习和预训练模型的光芒所掩盖。然而,经验时代的到来重新凸显了 RL 的价值,特别是在长期交互、自主探索和环境建模方面的独特优势。
作者介绍
David Silver
David Silver 是谷歌 DeepMind 的首席研究员,也是 RL 领域的领军人物之一。他最为人熟知的贡献是领导了 AlphaGo 项目,该项目在 2016 年击败了世界围棋冠军李世乭,标志着 AI 在复杂博弈任务中的里程碑。Silver 的研究聚焦于 RL 的理论与应用,特别是在自我博弈(Self-Play)和规划算法方面。他的工作还包括 AlphaZero 和 AlphaProof 等突破性项目,展示了 RL 在无需人类知识的情况下发现新策略的能力。
Richard S. Sutton
Richard S. Sutton 被誉为“强化学习之父”,是 RL 领域的奠基人之一。他的经典著作《Reinforcement Learning: An Introduction》(与 Andrew Barto 合著)是 RL 领域的标准教材。Sutton 提出了许多 RL 的核心概念,例如时序差分学习(Temporal Difference Learning)和 Dyna 算法,这些概念至今仍是 RL 研究的基础。他目前是阿尔伯塔大学的教授,致力于推动 RL 在通用人工智能(AGI)中的应用。
两位作者的合作体现了 RL 理论与实践的完美结合。Silver 的工程创新与 Sutton 的理论洞见相辅相成,为经验时代的到来提供了坚实的学术和实践基础。
总结
《Welcome to the Era of Experience》是一篇具有前瞻性的论文,它不仅指出了人类数据时代的局限性,还为 AI 的未来发展勾勒出一条清晰的路径:通过经验学习,AI 能够在与环境的交互中突破人类知识的边界,实现超人类的智能。经验时代的四大维度——经验流、丰富交互、环境奖励和非人类推理——为这一愿景提供了具体的实现框架。
对于 AI 研究者和从业者而言,这篇论文是一声号角,呼吁重新审视 RL 的潜力,并探索基于经验的学习范式。对于普通读者,这篇论文揭示了 AI 发展的下一个前沿:一个由自主、适应性和创新驱动的智能时代。尽管挑战与风险并存,但经验时代的潜力无疑令人振奋,它可能重新定义我们与技术的关系,并加速人类的科学与社会进步。
后记
2025年4月21日于上海,在grok 3大模型辅助下完成。

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









