








 超级会员免费看
超级会员免费看

 本文介绍了如何解析KITTI数据集中的激光雷达点云,并将其投影到二维图像坐标上,类似于RGBD相机的效果。通过阅读标定文件并使用numpy处理点云bin文件,实现了点云的图像投影。源码和测试数据已开源在github仓库。
本文介绍了如何解析KITTI数据集中的激光雷达点云,并将其投影到二维图像坐标上,类似于RGBD相机的效果。通过阅读标定文件并使用numpy处理点云bin文件,实现了点云的图像投影。源码和测试数据已开源在github仓库。
介绍
KITTI作为广为人知的自动驾驶数据集,很多创业公司喜欢拿来做算法排名。
官网下载比较慢,这里参考文末博客给出百度云下载(27G)
链接:https://pan.baidu.com/s/1-4WchJlcZ2guwcfbHqrdFw
提取码:grys
解析
我的目的是解析三维激光点云并投影至二维图像坐标,得到类似RGBD相机的效果。
需要用到的文件包括:二进制Velodyne点云、双目RGB相机左眼cam2图像、激光到相机矩阵等标定文件
各传感器坐标在KIT的文章Vision meets Robotics: The KITTI Dataset中给出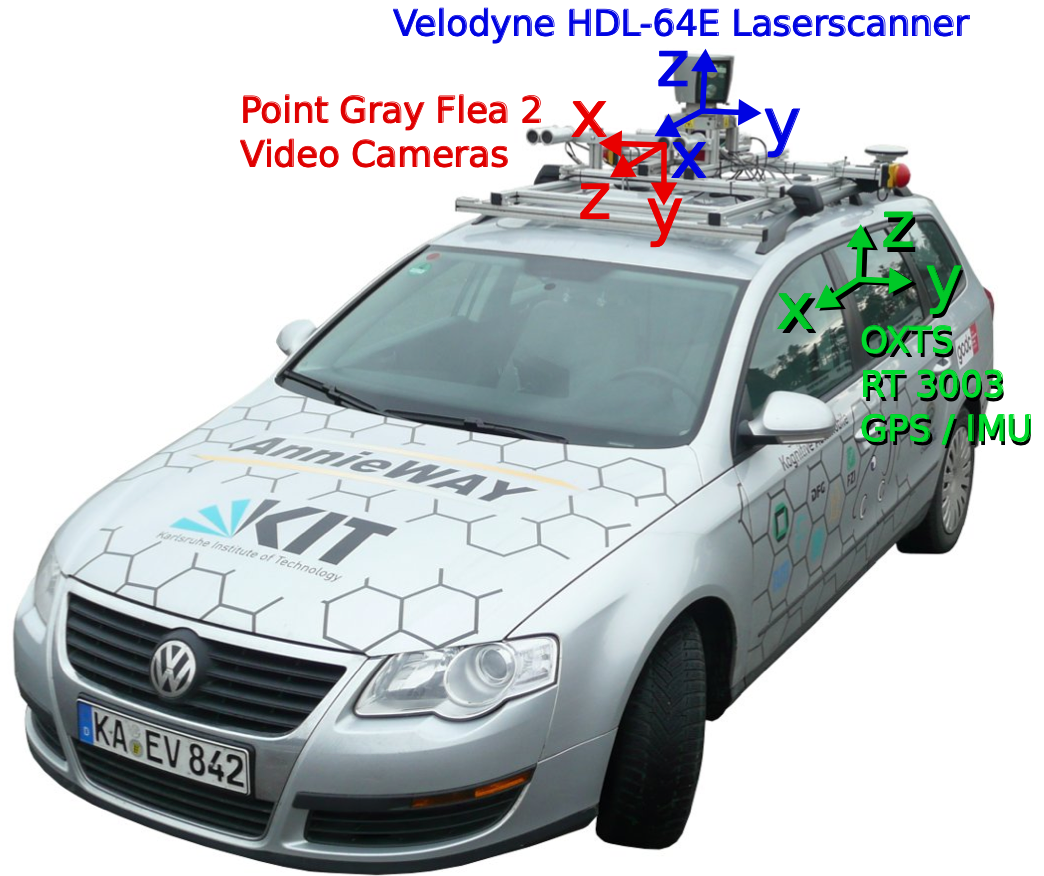
参考semantic-kitti-api的开源代码,使用numpy读取点云bin文件reshape为x,y,z,r(回波强度)格式
点云index从外圈到内圈顺时针存储
# read raw data from binary
scan = np.fromfile(binary, dtype=np.float32).reshape((-1,4))
points = scan[:, 0:3] # lidar xyz (front, left, up)
remissions = scan[:, 3]
标定文件calib/*.txt解读:
P0: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 0.000000000000e+00 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.875744000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 4.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03
P3: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.395242000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.199936000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.729905000000e-03
R0_rect: 9.999239000000e-01 9.837760000000e-03 -7.445048000000e-03 -9.869795000000e-03 9.999421000000e-01 -4.278459000000e-03 7.402527000000e-03 4.351614000000e-03 9.999631000000e-01
Tr_velo_to_cam: 7.533745000000e-03 -9.999714000000e-01 -6.166020000000e-04 -4.069766000000e-03 1.480249000000e-02 7.280733000000e-04 -9.998902000000e-01 -7.631618000000e-02 9.998621000000e-01 7.523790000000e-03 1.480755000000e-02 -2.717806000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
P0-P3为3x4相机投影矩阵,0=gray_L 1=gray_R 2=rgb_L 3=rgb_R
R0_rect为3x3相机旋转矩阵
Tr_velo_to_cam为3x4激光到相机RT矩阵
点云对图像投影使用如下公式
Z[u v 1]T = P2 * R0_rect * Tr_velo_to_cam * [x y z 1]T
写为齐次形式,R0在右下角补1变为4x4,Tr最后一列补1变为4x4,大写Z为相机深度
代码
使用python实现,过滤了激光雷达背后深度为负的点云,保留图像宽高内点,深度以colormap表示
源码与测试数据已开源至github仓库azureology/kitti-velo2cam: project lidar point cloud to camera image
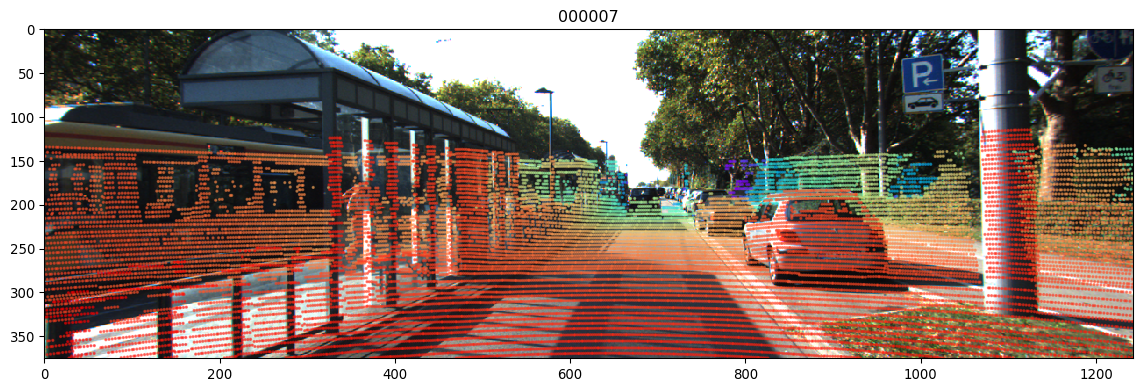
效果
参考
- KITTI数据集下载(百度云)_u013086672的博客-CSDN博客
- Vision meets Robotics: The KITTI Dataset
- PRBonn/semantic-kitti-api: SemanticKITTI API for visualizing dataset, processing data, and evaluating results
- numpy.logical_or — NumPy v1.19 Manual
- matplotlib - python 3 scatter plot gives "ValueError: Masked arrays must be 1-D" even though i am not using any masked array - Stack Overflow

















 1512
1512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









